
このチュートリアルでは、vLLM サービング フレームワークを使用して、Google Kubernetes Engine(GKE)で Tensor Processing Unit(TPU)を使用して大規模言語モデル(LLM)をサービングする方法について説明します。このチュートリアルでは、Llama 3.1 70b をサービングし、TPU Trillium を使用します。また、vLLM サーバー指標を使用して水平 Pod 自動スケーリングを設定します。
このドキュメントは、AI / ML ワークロードをデプロイしてサービングする際に、マネージド Kubernetes での詳細な制御、スケーラビリティ、復元力、ポータビリティ、費用対効果が求められる場合の出発点として適しています。
背景
GKE で TPU Trillium を使用すると、効率的なスケーラビリティや高可用性をはじめとするマネージド Kubernetes のメリットをすべて活用し、プロダクション レディで堅牢なサービング ソリューションを実装できます。このセクションでは、このガイドで使用されている重要なテクノロジーについて説明します。
TPU Trillium
TPU は、Google が独自に開発した特定用途向け集積回路(ASIC)です。TPU は、TensorFlow、PyTorch、JAX などのフレームワークを使用して構築された AI / ML モデルを高速化するために使用されます。このチュートリアルでは、Google の第 6 世代 TPU である TPU Trillium を使用します。
GKE で TPU を使用する前に、次の学習プログラムを完了することをおすすめします。
- TPU Trillium のシステム アーキテクチャについて学習する。
- GKE の TPU についてを確認する。
vLLM
vLLM は、LLM のサービング用に高度に最適化されたオープンソース フレームワークです。vLLM は、次のような機能により TPU でのサービング スループットを向上させることができます。
- PagedAttention による Transformer の実装の最適化
- サービング スループットを全体的に向上させる連続的なバッチ処理
- 複数の TPU でのテンソル並列処理と分散サービング
詳細については、vLLM のドキュメントをご覧ください。
サポートされているモデルと機能
TPU で vLLM を使用して LLM
をデプロイする前に、デプロイの問題を回避するために、モデルの互換性とサポートされている機能を確認することをおすすめします。
vllm-project/tpu-inference
ライブラリは、TPU で vLLM を実行するために必要なバックエンドを提供します。
サポートされているモデルと機能の包括的なリストについては、公式ドキュメントをご覧ください。
Cloud Storage FUSE
Cloud Storage FUSE は、オブジェクト ストレージ バケットに存在するモデルの重み付けで、GKE クラスタから Cloud Storage にアクセスできるようにします。このチュートリアルで作成された Cloud Storage バケットは最初は空になります。vLLM が起動すると、GKE は Hugging Face からモデルをダウンロードし、重みを Cloud Storage バケットのキャッシュに保存します。Pod の再起動またはデプロイのスケールアップ時に、後続のモデル読み込みでキャッシュに保存されたデータが Cloud Storage バケットからダウンロードされ、並列ダウンロードを利用してパフォーマンスが最適化されます。
詳細については、Cloud Storage FUSE CSI ドライバのドキュメントをご覧ください。
目標
このチュートリアルは、LLM を提供するために GKE オーケストレーション機能を使用する MLOps または DevOps エンジニア、またはプラットフォーム管理者を対象としています。
このチュートリアルでは、次の手順について説明します。
- モデルの特性に基づいて推奨される TPU Trillium トポロジを持つ GKE クラスタを作成します。
- クラスタ内のノードプールに vLLM フレームワークをデプロイします。
- vLLM フレームワークを利用し、ロードバランサを使用して Llama 3.1 70b をサービングします。
- vLLM サーバー指標を使用して水平 Pod 自動スケーリングを設定します。
- モデルをサービングします。
始める前に
- アカウントにログインします。 Google Cloud を初めて使用する場合は、 アカウントを作成して、実際のシナリオで Google プロダクトのパフォーマンスを評価してください。 Google Cloud新規のお客様には、ワークロードの実行、テスト、デプロイに利用できる $300 相当の無料クレジットも提供されます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
プロジェクトに次のロールがあることを確認します:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminロールを確認する
-
コンソールで、[IAM] ページに移動します。 Google Cloud
IAM に移動 - プロジェクトを選択します。
-
[Principal] 列で、自分または自分が含まれているグループを識別するすべての行を見つけます。自分が含まれているグループを確認するには、管理者にお問い合わせください。
- 自分を指定または含んでいるすべての行について、[ロール] 列で、 ロールのリストに必要なロールが含まれているかどうかを確認します。
ロールを付与する
-
コンソールで、[IAM] ページに移動します。 Google Cloud
IAM に移動 - プロジェクトを選択します。
- [**アクセスを許可**] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [**ロールを選択**] をクリックして、ロールを検索します。
- 追加のロールを付与するには、 [Add another role] をクリックして各ロールを追加します。
- [保存] をクリックします。
-
- Hugging Face アカウントを作成します(まだ作成していない場合)。
- GKE の Cloud TPU 用にプロジェクトに十分な割り当てがあることを確認します。
環境を準備する
このセクションでは、vLLM とモデルのデプロイに必要なリソースをプロビジョニングします。
モデルへのアクセス権を取得する
Hugging Face リポジトリの Llama 3.1 70b を使用するには、同意契約に署名する必要があります。
アクセス トークンを生成する
Hugging Face トークンをまだ生成していない場合は、新しいトークンを生成します。
- [Your Profile] > [Settings] > [Access Tokens] の順にクリックします。
- [New Token] を選択します。
- 任意の名前と、少なくとも
Readロールを指定します。 - [Generate a token] を選択します。
Cloud Shell を起動する
このチュートリアルでは、Cloud Shell を使用してGoogle Cloudでホストされているリソースを管理します。Cloud Shell には、このチュートリアルに必要な kubectl や gcloud CLI などのソフトウェアがプリインストールされています。
Cloud Shell を使用して環境を設定するには、次の操作を行います。
Google Cloud コンソールで
 (Cloud Shell をアクティブにする)をクリックして、 Google Cloud コンソールで Cloud Shell セッションを起動します。これにより、 Google Cloud コンソールの下部ペインでセッションが起動します。
(Cloud Shell をアクティブにする)をクリックして、 Google Cloud コンソールで Cloud Shell セッションを起動します。これにより、 Google Cloud コンソールの下部ペインでセッションが起動します。デフォルトの環境変数を設定します。
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACE次の値を置き換えます。
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。
- CLUSTER_NAME: GKE クラスタの名前。
- CONTROL_PLANE_LOCATION: クラスタのコントロール プレーンの Compute Engine のリージョン。TPU Trillium(v6e)をサポートするリージョンを指定します。
- ZONE:TPU Trillium(v6e)をサポートするゾーン。
- CLUSTER_VERSION : TPU Trillium(v6e)を サポートする GKE バージョン。詳細については、 GKE での TPU の可用性を検証するをご覧ください。
- GSBUCKET : Cloud Storage FUSE に使用する Cloud Storage バケットの名前 。
- KSA_NAME: Cloud Storage バケットへのアクセスに使用される Kubernetes ServiceAccount の名前。Cloud Storage FUSE を機能させるには、バケットへのアクセス権が必要です。
- NAMESPACE: vLLM アセットをデプロイする Kubernetes Namespace。
GKE クラスタを作成する
GKE Autopilot クラスタまたは GKE Standard クラスタの TPU で LLM を提供できます。フルマネージドの Kubernetes エクスペリエンスを実現するには、Autopilot クラスタを使用することをおすすめします。ワークロードに最適な GKE の運用モードを選択するには、GKE の運用モードを選択するをご覧ください。
Autopilot
GKE Autopilot クラスタを作成します。
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
GKE Standard クラスタを作成します。
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver
このコマンドは、GKE Standard クラスタを作成し、 Workload Identity 連携 と Cloud Storage FUSE CSI ドライバを有効にします。既存のクラスタを使用している場合は、Cloud Storage FUSE CSI ドライバが有効になっていることを確認してください。
TPU スライス ノードプールを作成します。
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE は、LLM 用に次のリソースを作成します。
- Workload Identity Federation for GKE を使用し、Cloud Storage FUSE CSI ドライバが有効になっている GKE Standard クラスタ。
ct6e-standard-8tマシンタイプの TPU Trillium ノードプール。このノードプールには 1 つのノードと 8 個の TPU チップがあり、自動スケーリングが有効になっています。
クラスタと通信するように kubectl を構成する
クラスタと通信するように kubectl を構成するには、次のコマンドを実行します。
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Hugging Face の認証情報用の Kubernetes Secret を作成する
Namespace を作成します。
defaultNamespace を使用している場合は、この手順をスキップできます。kubectl create namespace ${NAMESPACE}Hugging Face トークンを含む Kubernetes Secret を作成するには、次のコマンドを実行します。
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Cloud Storage バケットを作成する
Cloud Shell で、次のコマンドを実行します。
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
これにより、Hugging Face からダウンロードしたモデルファイルを格納する Cloud Storage バケットが作成されます。
バケットにアクセスする Kubernetes ServiceAccount を設定する
Kubernetes ServiceAccount を作成します。
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Cloud Storage バケットにアクセスできるように、Kubernetes ServiceAccount に読み取り / 書き込みアクセス権を付与します。
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"また、プロジェクト内のすべての Cloud Storage バケットに対する読み取り / 書き込みアクセス権を付与することもできます。
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE は、LLM 用に次のリソースを作成します。
- ダウンロードしたモデルとコンパイル キャッシュを保存する Cloud Storage バケット。Cloud Storage FUSE CSI ドライバがバケットのコンテンツを読み取ります。
- ファイル キャッシュが有効になっているボリュームと、Cloud Storage FUSE の並列ダウンロード機能。
ベスト プラクティス: モデル コンテンツ(重み付けファイルなど)の予想サイズに応じて、
tmpfsまたはHyperdisk / Persistent Diskを基盤とするファイル キャッシュを使用します。このチュートリアルでは、RAM を基盤とする Cloud Storage FUSE ファイル キャッシュを使用します。
vLLM モデルサーバーをデプロイする
このチュートリアルでは、vLLM モデルサーバーをデプロイするために Kubernetes Deployment を使用します。Deployment は、クラスタ内のノードに分散された Pod の複数のレプリカを実行できる Kubernetes API オブジェクトです。
単一のレプリカを使用する次の Deployment マニフェスト(
vllm-llama3-70b.yamlとして保存)を調べます。Deployment を複数のレプリカにスケールアップすると、
VLLM_XLA_CACHE_PATHへの同時書き込みにより、RuntimeError: filesystem error: cannot create directoriesエラーが発生します。このエラーを防止するには、次の 2 つの方法があります。Deployment YAML から次のブロックを削除して、XLA キャッシュの場所を削除します。つまり、すべてのレプリカでキャッシュが再コンパイルされます。
- name: VLLM_XLA_CACHE_PATH value: "/data"Deployment を
1にスケーリングし、最初のレプリカの準備が整って XLA キャッシュに書き込まれるまで待ちます。次に、追加のレプリカにスケーリングします。これにより、残りのレプリカはキャッシュの読み取りが可能になり、書き込みは試行されません。
次のコマンドを実行してマニフェストを適用します。
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}実行中のモデルサーバーのログを表示します。
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}出力は次のようになります。
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
モデルをサービングする
VLLM サービスの外部 IP アドレスを取得するには、次のコマンドを実行します。
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})curlを使用してモデルを操作します。curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'出力例を以下に示します。
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
カスタム オートスケーラーを設定する
このセクションでは、カスタム Prometheus 指標を使用して水平 Pod 自動スケーリングを設定します。vLLM サーバーから Google Cloud Managed Service for Prometheus の指標を使用します。
詳細については、Google Cloud Managed Service for Prometheus をご覧ください。これは GKE クラスタでデフォルトで有効になっています。
クラスタにカスタム指標の Stackdriver アダプタを設定します。
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlカスタム指標の Stackdriver アダプタが使用するサービス アカウントに Monitoring 閲覧者のロールを追加します。
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapter次のマニフェストを
vllm_pod_monitor.yamlとして保存します。クラスタに適用します。
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
vLLM エンドポイントに負荷を生成する
vLLM サーバーに負荷をかけて、GKE がカスタム vLLM 指標で自動スケーリングする方法を確認します。
bash スクリプト(
load.sh)を実行して、N個の並列リクエストを vLLM エンドポイントに送信します。#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitPARALLEL_PROCESSES は、実行する並列プロセスの数に置き換えます。
bash スクリプトを実行します。
chmod +x load.sh nohup ./load.sh &
Google Cloud Managed Service for Prometheus が指標を取り込むことを確認する
Google Cloud Managed Service for Prometheus が指標をスクレイピングし、vLLM エンドポイントに負荷をかけると、Cloud Monitoring で指標を表示できます。
Google Cloud コンソールで、Metrics Explorer のページに移動します。
[< > PromQL] をクリックします。
次のクエリを入力して、トラフィック指標を確認します。
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
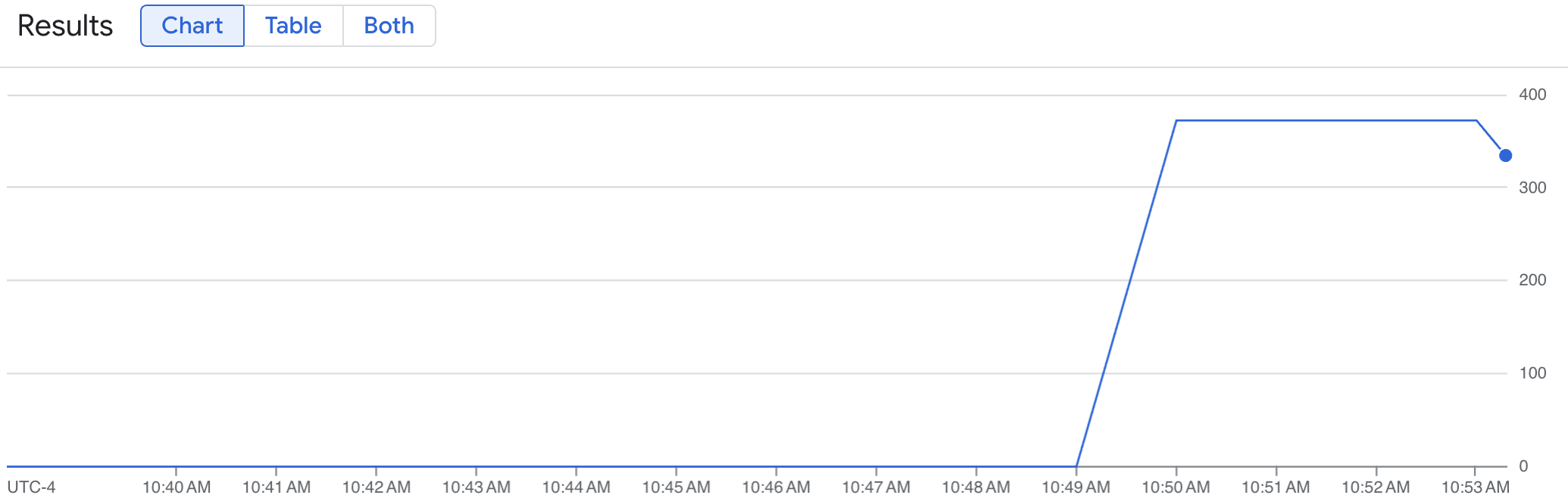
折れ線グラフに、時間の経過に伴う vLLM 指標(num_requests_waiting)が表示されます。vLLM 指標は、0(プリロード)から値(ポストロード)にスケールアップします。このグラフでは、vLLM 指標が Google Cloud Managed Service for Prometheus に取り込まれていることがわかります。次のグラフの例は、プリロード開始時の値が 0 で、1 分以内に最大の負荷に達した後、値が 400 近くに達していることを示しています。
HorizontalPodAutoscaler 構成をデプロイする
自動スケーリングする指標を決定する場合は、vLLM TPU に次の指標を使用することをおすすめします。
num_requests_waiting: この指標は、モデルサーバーのキューで待機しているリクエストの数に関連しています。この数は、kv キャッシュがいっぱいになると著しく増加します。gpu_cache_usage_perc: この指標は kv キャッシュの使用率に関連しており、モデルサーバーで特定の推論サイクルで処理されるリクエスト数に直接関連しています。この指標は GPU と TPU で同じように機能しますが、GPU の命名スキーマに関連付けられています。
スループットと費用を最適化する場合、また、モデルサーバーの最大スループットでレイテンシ目標を達成できる場合は、num_requests_waiting を使用することをおすすめします。
キューベースのスケーリングでは要件を満たせない、レイテンシの影響を受けやすいワークロードがある場合は、gpu_cache_usage_perc を使用することをおすすめします。
詳細については、TPU を使用して大規模言語モデル(LLM)推論ワークロードを自動スケーリングするためのベスト プラクティスをご覧ください。
HPA 構成の averageValue ターゲットを選択する場合は、テストで決定する必要があります。この部分を最適化する方法については、GPU のコストを削減: GKE の推論ワークロード向けのスマートな自動スケーリングのブログ投稿をご覧ください。このブログ投稿で使用した profile-generator は vLLM TPU でも機能します。
次の手順では、num_requests_waiting 指標を使用して HPA 構成をデプロイします。デモ用に指標を低い値に設定し、HPA 構成で vLLM レプリカを 2 にスケーリングします。num_requests_waiting を使用して Horizontal Pod Autoscaler 構成をデプロイする手順は次のとおりです。
次のマニフェストを
vllm-hpa.yamlとして保存します。Google Cloud Managed Service for Prometheus の vLLM 指標は
vllm:metric_name形式に従います。ベスト プラクティス: スループットをスケーリングするには
num_requests_waitingを使用します。レイテンシの影響を受けやすい TPU のユースケースにはgpu_cache_usage_percを使用します。HorizontalPodAutoscaler 構成をデプロイします。
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE は、デプロイする別の Pod をスケジュールします。これにより、ノードプール オートスケーラーがトリガーされ、2 番目の vLLM レプリカをデプロイする前に 2 番目のノードを追加します。
Pod の自動スケーリングの進行状況を確認します。
kubectl get hpa --watch -n ${NAMESPACE}出力は次のようになります。
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77s10 分待ってから、Google Cloud Managed Service for Prometheus が指標を取り込んでいることを確認するの手順を繰り返します。Google Cloud Managed Service for Prometheus は、両方の vLLM エンドポイントから指標を取り込みます。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
デプロイされたリソースを削除する
このガイドで作成したリソースについて Google Cloud アカウントに課金されないようにするには、次のコマンドを実行します。
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CONTROL_PLANE_LOCATION}
次のステップ
- GKE の TPU の詳細を確認する。
- Horizontal Pod Autoscaler の設定に使用できる指標の詳細を確認する。
- vLLM の GitHub リポジトリとドキュメントを確認する。