
Questo tutorial mostra come pubblicare modelli linguistici di grandi dimensioni (LLM) utilizzando le unità di elaborazione tensoriale (TPU) su Google Kubernetes Engine (GKE) con il framework di pubblicazione vLLM. In questo tutorial utilizzerai Llama 3.1 70b, TPU Trillium e configurerai la scalabilità automatica orizzontale dei pod utilizzando le metriche del server vLLM.
Questo documento è un buon punto di partenza se hai bisogno del controllo granulare, della scalabilità, della resilienza, della portabilità e della convenienza di Kubernetes gestito quando esegui il deployment e il servizio dei tuoi carichi di lavoro AI/ML.
Sfondo
Utilizzando TPU Trillium su GKE, puoi implementare una soluzione di serving affidabile e pronta per la produzione con tutti i vantaggi di Kubernetes gestito, tra cui scalabilità efficiente e maggiore disponibilità. Questa sezione descrive le tecnologie chiave utilizzate in questa guida.
TPU Trillium
Le TPU sono circuiti integrati specifici per le applicazioni (ASIC) sviluppati da Google. Le TPU vengono utilizzate per accelerare i modelli di machine learning e AI creati utilizzando framework come TensorFlow, PyTorch e JAX. Questo tutorial utilizza TPU Trillium, la TPU di sesta generazione di Google.
Prima di utilizzare le TPU in GKE, ti consigliamo di completare il seguente percorso di apprendimento:
- Scopri di più sull'architettura di sistema di TPU Trillium.
- Scopri di più sulle TPU in GKE.
vLLM
vLLM è un framework open source altamente ottimizzato per l'erogazione di LLM. vLLM può aumentare il throughput di erogazione sulle TPU, con funzionalità come le seguenti:
- Implementazione ottimizzata del transformer con PagedAttention.
- Batching continuo per migliorare la velocità effettiva complessiva della pubblicazione.
- Parallelismo dei tensori e servizio distribuito su più TPU.
Per saperne di più, consulta la documentazione di vLLM.
Modelli e funzionalità supportati
Prima di eseguire il deployment di LLM con vLLM sulle TPU, ti consigliamo di verificare la compatibilità del modello e le funzionalità supportate per evitare problemi di deployment. La
vllm-project/tpu-inference
fornisce il backend necessario per l'esecuzione di vLLM sulle TPU.
Per un elenco completo dei modelli e delle funzionalità supportati, consulta la documentazione ufficiale:
Cloud Storage FUSE
Cloud Storage FUSE fornisce l'accesso dal cluster GKE a Cloud Storage per i pesi del modello che si trovano nei bucket di archiviazione di oggetti. In questo tutorial, il bucket Cloud Storage creato inizialmente sarà vuoto. All'avvio di vLLM, GKE scarica il modello da Hugging Face e memorizza nella cache i pesi nel bucket Cloud Storage. Al riavvio del pod o all'aumento delle dimensioni del deployment, i carichi successivi del modello scaricheranno i dati memorizzati nella cache dal bucket Cloud Storage, sfruttando i download paralleli per prestazioni ottimali.
Per saperne di più, consulta la documentazione del driver CSI di Cloud Storage FUSE.
Obiettivi
Questo tutorial è rivolto a ingegneri MLOps o DevOps o amministratori di piattaforme che vogliono utilizzare le funzionalità di orchestrazione di GKE per pubblicare LLM.
Questo tutorial illustra i seguenti passaggi:
- Crea un cluster GKE con la topologia TPU Trillium consigliata in base alle caratteristiche del modello.
- Esegui il deployment del framework vLLM in un pool di nodi del cluster.
- Utilizza il framework vLLM per erogare Llama 3.1 70b utilizzando un bilanciatore del carico.
- Configura la scalabilità automatica orizzontale dei pod utilizzando le metriche del server vLLM.
- Eroga il modello.
Prima di iniziare
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Assicurati di disporre dei seguenti ruoli nel progetto:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminControlla i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
-
Nella colonna Entità, trova tutte le righe che identificano te o un gruppo di cui fai parte. Per scoprire a quali gruppi appartieni, contatta il tuo amministratore.
- Per tutte le righe che ti specificano o ti includono, controlla la colonna Ruolo per verificare se l'elenco dei ruoli include i ruoli richiesti.
Concedi i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Fai clic su Seleziona un ruolo, quindi cerca il ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo successivo.
- Fai clic su Salva.
-
- Crea un account Hugging Face, se non ne hai già uno.
- Assicurati che il tuo progetto disponga di una quota sufficiente per Cloud TPU in GKE.
Prepara l'ambiente
In questa sezione, esegui il provisioning delle risorse necessarie per il deployment di vLLM e del modello.
Ottenere l'accesso al modello
Per utilizzare Llama 3.1 70b nel repository Hugging Face, devi firmare il contratto di consenso.
Generare un token di accesso
Se non ne hai già uno, genera un nuovo token Hugging Face:
- Fai clic su Il tuo profilo > Impostazioni > Token di accesso.
- Seleziona Nuovo token.
- Specifica un nome a tua scelta e un ruolo di almeno
Read. - Seleziona Genera un token.
Avvia Cloud Shell
In questo tutorial utilizzerai Cloud Shell per gestire le risorse ospitate su
Google Cloud. Cloud Shell include il software necessario per questo tutorial, tra cui
kubectl e
gcloud CLI.
Per configurare l'ambiente con Cloud Shell:
Nella console Google Cloud , avvia una sessione di Cloud Shell facendo clic su
 Attiva Cloud Shell nella Google Cloud console. Viene avviata una sessione nel riquadro inferiore della console Google Cloud .
Attiva Cloud Shell nella Google Cloud console. Viene avviata una sessione nel riquadro inferiore della console Google Cloud .Imposta le variabili di ambiente predefinite:
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACESostituisci i seguenti valori:
- PROJECT_ID : il tuo Google Cloud ID progetto.
- CLUSTER_NAME : il nome del tuo cluster GKE.
- CONTROL_PLANE_LOCATION: la regione di Compute Engine del control plane del tuo cluster. Fornisci una regione che supporti TPU Trillium (v6e).
- ZONE : una zona che supporta TPU Trillium (v6e).
- CLUSTER_VERSION : una versione di GKE che supporta TPU Trillium (v6e). Per maggiori informazioni, consulta Verificare la disponibilità delle TPU in GKE.
- GSBUCKET : il nome del bucket Cloud Storage da utilizzare per Cloud Storage FUSE.
- KSA_NAME : il nome del service account Kubernetes utilizzato per accedere ai bucket Cloud Storage. Per il funzionamento di Cloud Storage FUSE è necessario l'accesso al bucket.
- NAMESPACE : lo spazio dei nomi Kubernetes in cui vuoi eseguire il deployment degli asset vLLM.
Crea un cluster GKE
Puoi gestire LLM su TPU in un cluster GKE Autopilot o Standard. Ti consigliamo di utilizzare un cluster Autopilot per un'esperienza Kubernetes completamente gestita. Per scegliere la modalità operativa GKE più adatta ai tuoi workload, consulta Scegliere una modalità operativa GKE.
Autopilot
Crea un cluster GKE Autopilot:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
Crea un cluster GKE Standard:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver
Questo comando crea un cluster GKE Standard e abilita la federazione delle identità per i workload e il driver CSI di Cloud Storage FUSE. Se utilizzi un cluster esistente, assicurati che il driver CSI di Cloud Storage FUSE sia abilitato.
Crea un pool di nodi di sezione TPU:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE crea le seguenti risorse per l'LLM:
- Un cluster GKE Standard che utilizza Workload Identity Federation for GKE e in cui è abilitato il driver CSI di Cloud Storage FUSE.
- Un pool di nodi TPU Trillium con un tipo di macchina
ct6e-standard-8t. Questo pool di nodi ha un nodo, otto chip TPU e la scalabilità automatica abilitata.
Configura kubectl per comunicare con il cluster
Per configurare kubectl in modo che comunichi con il tuo cluster, esegui questo comando:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Crea un secret Kubernetes per le credenziali di Hugging Face
Crea uno spazio dei nomi. Puoi saltare questo passaggio se utilizzi lo spazio dei nomi
default:kubectl create namespace ${NAMESPACE}Crea un secret Kubernetes che contenga il token Hugging Face eseguendo il seguente comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Crea un bucket Cloud Storage
In Cloud Shell, esegui questo comando:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
In questo modo viene creato un bucket Cloud Storage per archiviare i file del modello che scarichi da Hugging Face.
Configura un service account Kubernetes per accedere al bucket
Crea il ServiceAccount Kubernetes:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Concedi l'accesso in lettura/scrittura al service account Kubernetes per accedere al bucket Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"In alternativa, puoi concedere l'accesso in lettura/scrittura a tutti i bucket Cloud Storage nel progetto:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE crea le seguenti risorse per l'LLM:
- Un bucket Cloud Storage per archiviare il modello scaricato e la cache di compilazione. Un driver CSI di Cloud Storage FUSE legge il contenuto del bucket.
- Volumi con la memorizzazione nella cache dei file abilitata e la funzionalità di download parallelo di Cloud Storage FUSE.
Best practice: Utilizza una cache di file supportata da
tmpfsoHyperdisk / Persistent Diska seconda delle dimensioni previste dei contenuti del modello, ad esempio i file di peso. In questo tutorial, utilizzi la cache dei file Cloud Storage FUSE supportata dalla RAM.
Esegui il deployment del server del modello vLLM
Per eseguire il deployment del server di modelli vLLM, questo tutorial utilizza un deployment Kubernetes. Un deployment è un oggetto API Kubernetes che consente di eseguire più repliche di pod distribuite tra i nodi di un cluster.
Esamina il seguente manifest di Deployment salvato come
vllm-llama3-70b.yaml, che utilizza una singola replica:Se aumenti lo scale up del deployment a più repliche, le scritture simultanee in
VLLM_XLA_CACHE_PATHcauseranno l'errore:RuntimeError: filesystem error: cannot create directories. Per evitare questo errore, hai due opzioni:Rimuovi la posizione della cache XLA rimuovendo il seguente blocco dal file YAML di deployment. Ciò significa che tutte le repliche ricompileranno la cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Scala il deployment a
1e attendi che la prima replica diventi pronta e scriva nella cache XLA. poi esegui lo scale up ad altre repliche. In questo modo, le repliche rimanenti possono leggere la cache senza tentare di scriverla.
Applica il manifest eseguendo questo comando:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Visualizza i log del server del modello in esecuzione:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}L'output dovrebbe essere simile al seguente:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Eroga il modello
Per ottenere l'indirizzo IP esterno del servizio VLLM, esegui questo comando:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interagisci con il modello utilizzando
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'L'output dovrebbe essere simile al seguente:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configura lo scalatore automatico personalizzato
In questa sezione configurerai la scalabilità automatica orizzontale dei pod utilizzando metriche Prometheus personalizzate. Utilizzi le metriche di Google Cloud Managed Service per Prometheus dal server vLLM.
Per saperne di più, consulta Google Cloud Managed Service per Prometheus. Questa opzione dovrebbe essere abilitata per impostazione predefinita sul cluster GKE.
Configura l'adattatore Stackdriver delle metriche personalizzate sul tuo cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAggiungi il ruolo Visualizzatore Monitoring al account di servizio utilizzato dall'adattatore Stackdriver per le metriche personalizzate:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSalva il seguente manifest come
vllm_pod_monitor.yaml:Applica il file al cluster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Crea carico sull'endpoint vLLM
Crea un carico sul server vLLM per testare la scalabilità automatica di GKE con una metrica vLLM personalizzata.
Esegui uno script bash (
load.sh) per inviareNrichieste parallele all'endpoint vLLM:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitSostituisci PARALLEL_PROCESSES con il numero di processi paralleli che vuoi eseguire.
Esegui lo script bash:
chmod +x load.sh nohup ./load.sh &
Verifica che Google Cloud Managed Service per Prometheus acquisisca le metriche
Dopo che Google Cloud Managed Service per Prometheus ha eseguito lo scraping delle metriche e stai aggiungendo carico all'endpoint vLLM, puoi visualizzare le metriche in Cloud Monitoring.
Nella console Google Cloud , vai alla pagina Esplora metriche.
Vai a Esplora metriche
Fai clic su < > PromQL.
Inserisci la seguente query per osservare le metriche sul traffico:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
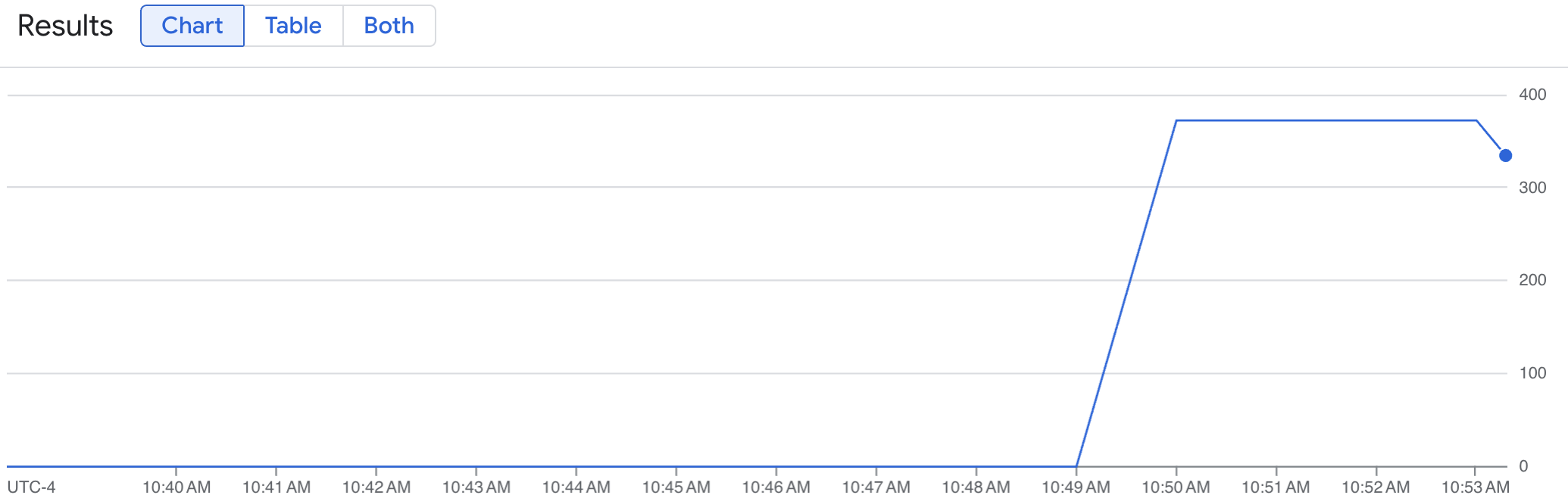
Un grafico a linee mostra la metrica vLLM (num_requests_waiting) misurata nel tempo. La metrica vLLM aumenta da 0 (precaricamento) a un valore (post-caricamento). Questo grafico conferma che le metriche vLLM vengono importate in Google Cloud Managed Service per Prometheus. Il seguente grafico di esempio mostra un valore di precaricamento iniziale pari a 0, che raggiunge un valore massimo post-caricamento di quasi 400 entro un minuto.
Esegui il deployment della configurazione di Horizontal Pod Autoscaler
Quando decidi su quale metrica eseguire la scalabilità automatica, ti consigliamo le seguenti metriche per vLLM TPU:
num_requests_waiting: questa metrica si riferisce al numero di richieste in attesa nella coda del server del modello. Questo numero inizia a crescere in modo significativo quando la cache KV è piena.gpu_cache_usage_perc: questa metrica si riferisce all'utilizzo della cache KV, che è direttamente correlato al numero di richieste elaborate per un determinato ciclo di inferenza sul server del modello. Tieni presente che questa metrica funziona allo stesso modo su GPU e TPU, anche se è legata allo schema di denominazione delle GPU.
Ti consigliamo di utilizzare num_requests_waiting quando esegui l'ottimizzazione in base a velocità effettiva e costi e quando i target di latenza sono raggiungibili con la velocità effettiva massima del server del modello.
Ti consigliamo di utilizzare gpu_cache_usage_perc quando hai carichi di lavoro sensibili alla latenza in cui lo scaling basato sulla coda non è abbastanza veloce per soddisfare i tuoi requisiti.
Per ulteriori spiegazioni, consulta Best practice per la scalabilità automatica dei workload di inferenza dei modelli linguistici di grandi dimensioni (LLM) con le TPU.
Quando selezioni un target averageValue per la configurazione HPA, devi determinarlo in modo sperimentale. Consulta il post del blog Risparmia sulle GPU: scalabilità automatica più intelligente per i carichi di lavoro di inferenza GKE per ulteriori idee su come ottimizzare questa parte. profile-generator utilizzato in questo post del blog funziona anche per vLLM TPU.
Nelle istruzioni riportate di seguito, esegui il deployment della configurazione HPA utilizzando la metrica num_requests_waiting. A scopo dimostrativo, imposta la metrica su un valore basso in modo che la configurazione HPA aumenti le repliche vLLM a due. Per eseguire il deployment della configurazione di Horizontal Pod Autoscaler utilizzando num_requests_waiting, segui questi passaggi:
Salva il seguente manifest come
vllm-hpa.yaml:Le metriche vLLM in Google Cloud Managed Service per Prometheus seguono il formato
vllm:metric_name.Best practice: Utilizza
num_requests_waitingper scalare la velocità effettiva. Utilizzagpu_cache_usage_percper i casi d'uso della TPU sensibili alla latenza.Esegui il deployment della configurazione di Horizontal Pod Autoscaler:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE pianifica il deployment di un altro pod, il che attiva il gestore della scalabilità automatica pool di nodi per aggiungere un secondo nodo prima di eseguire il deployment della seconda replica vLLM.
Osserva l'avanzamento della scalabilità automatica dei pod:
kubectl get hpa --watch -n ${NAMESPACE}L'output è simile al seguente:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sAttendi 10 minuti e ripeti i passaggi della sezione Verifica che Google Cloud Managed Service per Prometheus importi le metriche. Google Cloud Managed Service per Prometheus ora acquisisce le metriche da entrambi gli endpoint vLLM.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina le risorse di cui è stato eseguito il deployment
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse che hai creato in questa guida, esegui i seguenti comandi:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CONTROL_PLANE_LOCATION}
Passaggi successivi
- Scopri di più sulle TPU in GKE.
- Scopri di più sulle metriche disponibili per configurare il gestore della scalabilità automatica orizzontale dei pod.
- Esplora il repository GitHub e la documentazione di vLLM.