
Ce tutoriel explique comment diffuser des grands modèles de langage (LLM) à l'aide des TPU (Tensor Processing Units) sur Google Kubernetes Engine (GKE) avec le framework de diffusion vLLM. Dans ce tutoriel, vous allez diffuser Llama 3.1 70b, utiliser TPU Trillium et configurer l'autoscaling horizontal des pods à l'aide des métriques du serveur vLLM.
Ce document est un bon point de départ si vous avez besoin du contrôle précis, de l'évolutivité, de la résilience, de la portabilité et de la rentabilité des services Kubernetes gérés lors du déploiement et de la diffusion de vos charges de travail d'IA/de ML.
Arrière-plan
En utilisant TPU Trillium sur GKE, vous pouvez mettre en œuvre une solution de diffusion robuste et prête pour la production avec tous les avantages de Kubernetes géré, y compris une évolutivité efficace et une meilleure disponibilité. Cette section décrit les principales technologies utilisées dans ce guide.
TPU Trillium
Les TPU sont des circuits intégrés propres à une application (ASIC) développés spécifiquement par Google. Les TPU permettent d'accélérer le machine learning et les modèles d'IA créés à l'aide de frameworks tels que TensorFlow, PyTorch et JAX. Ce tutoriel utilise le TPU Trillium, qui est la sixième génération de TPU de Google.
Avant d'utiliser des TPU dans GKE, nous vous recommandons de suivre le parcours de formation suivant :
- Découvrez l'architecture système de TPU Trillium.
- Apprenez-en plus sur les TPU dans GKE.
vLLM
vLLM est un framework Open Source hautement optimisé pour la diffusion de LLM. vLLM peut augmenter le débit de diffusion sur les TPU, avec des fonctionnalités telles que les suivantes :
- Implémentation optimisée du transformateur avec PagedAttention.
- Traitement par lots continu pour améliorer le débit global de diffusion.
- Parallélisme Tensor et diffusion distribuée sur plusieurs TPU.
Pour en savoir plus, consultez la documentation vLLM.
Modèles et fonctionnalités compatibles
Avant de déployer des LLM avec vLLM sur des TPU, nous vous recommandons de vérifier la compatibilité des modèles et les fonctionnalités prises en charge pour éviter les problèmes de déploiement. La bibliothèque vllm-project/tpu-inference fournit le backend nécessaire pour que vLLM s'exécute sur les TPU.
Pour obtenir la liste complète des modèles et des fonctionnalités compatibles, consultez la documentation officielle :
Cloud Storage FUSE
Cloud Storage FUSE permet à votre cluster GKE d'accéder à Cloud Storage pour les pondérations de modèle résidant dans des buckets de stockage d'objets. Dans ce tutoriel, le bucket Cloud Storage créé sera initialement vide. Lorsque vLLM démarre, GKE télécharge le modèle depuis Hugging Face et met en cache les pondérations dans le bucket Cloud Storage. Lors du redémarrage du pod ou de l'augmentation de l'échelle du déploiement, les chargements de modèles suivants téléchargeront les données mises en cache à partir du bucket Cloud Storage, en tirant parti des téléchargements parallèles pour des performances optimales.
Pour en savoir plus, consultez la documentation du pilote CSI Cloud Storage FUSE.
Objectifs
Ce tutoriel est destiné aux ingénieurs MLOps ou DevOps ou aux administrateurs de plate-forme qui souhaitent utiliser les fonctionnalités d'orchestration GKE pour diffuser des LLM.
Ce tutoriel couvre les étapes suivantes :
- Créez un cluster GKE avec la topologie TPU Trillium recommandée en fonction des caractéristiques du modèle.
- Déployez le framework vLLM sur un pool de nœuds de votre cluster.
- Utilisez le framework vLLM pour diffuser Llama 3.1 70b à l'aide d'un équilibreur de charge.
- Configurez l'autoscaling horizontal des pods à l'aide des métriques du serveur vLLM.
- Diffuser le modèle
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Assurez-vous de disposer du ou des rôles suivants sur le projet :
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminVérifier les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
-
Dans la colonne Compte principal, recherchez toutes les lignes qui vous identifient ou identifient un groupe dont vous faites partie. Pour savoir à quels groupes vous appartenez, contactez votre administrateur.
- Pour toutes les lignes qui vous spécifient ou vous incluent, consultez la colonne Rôle pour vous assurer que la liste inclut les rôles requis.
Attribuer les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Cliquez sur Sélectionner un rôle, puis recherchez le rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
-
- Créez un compte Hugging Face si vous n'en possédez pas.
- Assurez-vous que votre projet dispose d'un quota suffisant pour Cloud TPU dans GKE.
Préparer l'environnement
Dans cette section, vous allez provisionner les ressources dont vous avez besoin pour déployer vLLM et le modèle.
Accéder au modèle
Vous devez signer le contrat de consentement pour utiliser Llama3.1 70b dans le dépôt Hugging Face.
Générer un jeton d'accès
Si vous n'en avez pas déjà un, générez un nouveau jeton Hugging Face :
- Cliquez sur Your Profile > Settings > Access Tokens (Votre profil > Paramètres > Jetons d'accès).
- Sélectionnez New Token (Nouveau jeton).
- Spécifiez le nom de votre choix et un rôle d'au moins
Read. - Sélectionnez Générer un jeton.
Lancer Cloud Shell
Dans ce tutoriel, vous utilisez Cloud Shell pour gérer les ressources hébergées surGoogle Cloud. Les logiciels dont vous avez besoin pour ce tutoriel sont préinstallés sur Cloud Shell, y compris kubectl et la gcloud CLI.
Pour configurer votre environnement avec Cloud Shell, procédez comme suit :
Dans la console Google Cloud , lancez une session Cloud Shell en cliquant sur
 Activer Cloud Shell dans la consoleGoogle Cloud . Une session s'ouvre dans le volet inférieur de la console Google Cloud .
Activer Cloud Shell dans la consoleGoogle Cloud . Une session s'ouvre dans le volet inférieur de la console Google Cloud .Définissez les variables d'environnement par défaut :
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACERemplacez les valeurs suivantes :
- PROJECT_ID : ID de votre projet Google Cloud .
- CLUSTER_NAME : nom de votre cluster GKE.
- CONTROL_PLANE_LOCATION : région Compute Engine du plan de contrôle de votre cluster. Indiquez une région compatible avec les TPU Trillium (v6e).
- ZONE : zone compatible avec les TPU Trillium (v6e).
- CLUSTER_VERSION : version de GKE compatible avec les TPU Trillium (v6e). Pour en savoir plus, consultez Valider la disponibilité des TPU dans GKE.
- GSBUCKET : nom du bucket Cloud Storage à utiliser pour Cloud Storage FUSE.
- KSA_NAME : nom du compte de service Kubernetes utilisé pour accéder aux buckets Cloud Storage. L'accès au bucket est nécessaire pour que Cloud Storage FUSE fonctionne.
- NAMESPACE : espace de noms Kubernetes dans lequel vous souhaitez déployer les composants vLLM.
Créer un cluster GKE
Vous pouvez diffuser les LLM sur des TPU dans un cluster GKE Autopilot ou GKE Standard. Nous vous recommandons d'utiliser un cluster GKE Autopilot pour une expérience Kubernetes entièrement gérée. Pour choisir le mode de fonctionnement GKE le mieux adapté à vos charges de travail, consultez Choisir un mode de fonctionnement GKE.
Autopilot
Créez un cluster GKE Autopilot :
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
Créez un cluster GKE Standard :
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver
Cette commande crée un cluster GKE Standard et active la fédération d'identité de charge de travail et le pilote CSI Cloud Storage FUSE. Si vous utilisez un cluster existant, assurez-vous que le pilote CSI Cloud Storage FUSE est activé.
Créez un pool de nœuds de tranche TPU :
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE crée les ressources suivantes pour le LLM :
- Un cluster GKE Standard qui utilise Workload Identity Federation for GKE et sur lequel le pilote CSI Cloud Storage FUSE est activé.
- Un pool de nœuds TPU Trillium avec un type de machine
ct6e-standard-8t. Ce pool de nœuds comporte un nœud, huit puces TPU et l'autoscaling est activé.
Configurer kubectl pour communiquer avec votre cluster
Pour configurer kubectl de manière à communiquer avec votre cluster, exécutez la commande suivante :
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Créer un secret Kubernetes pour les identifiants Hugging Face
Créez un espace de noms. Vous pouvez ignorer cette étape si vous utilisez l'espace de noms
default:kubectl create namespace ${NAMESPACE}Créez un secret Kubernetes contenant le jeton Hugging Face en exécutant la commande suivante :
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Créer un bucket Cloud Storage
Dans Cloud Shell, exécutez la commande suivante :
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
Cette opération crée un bucket Cloud Storage pour stocker les fichiers de modèle que vous téléchargez depuis Hugging Face.
Configurer un compte de service Kubernetes pour accéder au bucket
Créez le compte de service Kubernetes :
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Accordez l'accès en lecture et en écriture au compte de service Kubernetes pour accéder au bucket Cloud Storage :
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Vous pouvez également accorder un accès en lecture/écriture à tous les buckets Cloud Storage du projet :
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE crée les ressources suivantes pour le LLM :
- Un bucket Cloud Storage pour stocker le modèle téléchargé et le cache de compilation. Un pilote CSI Cloud Storage FUSE lit le contenu du bucket.
- Volumes avec la mise en cache des fichiers activée et la fonctionnalité de téléchargement parallèle de Cloud Storage FUSE.
Bonne pratique : Utilisez un cache de fichiers basé sur
tmpfsouHyperdisk / Persistent Disken fonction de la taille attendue du contenu du modèle (fichiers de pondération, par exemple). Dans ce tutoriel, vous allez utiliser le cache de fichiers Cloud Storage FUSE basé sur la RAM.
Déployer un serveur de modèles vLLM
Pour déployer le serveur de modèle vLLM, ce tutoriel utilise un déploiement Kubernetes. Un déploiement est un objet de l'API Kubernetes qui vous permet d'exécuter plusieurs instances dupliquées de pods répartis entre les nœuds d'un cluster.
Examinez le fichier manifeste de déploiement suivant enregistré sous le nom
vllm-llama3-70b.yaml, qui utilise une seule réplique :Si vous augmentez le nombre de répliques du déploiement, les écritures simultanées dans
VLLM_XLA_CACHE_PATHprovoqueront l'erreurRuntimeError: filesystem error: cannot create directories. Pour éviter cette erreur, deux options s'offrent à vous :Supprimez l'emplacement du cache XLA en supprimant le bloc suivant du fichier YAML de déploiement. Cela signifie que toutes les répliques recompileront le cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Mettez à l'échelle le déploiement sur
1et attendez que le premier réplica soit prêt et écrive dans le cache XLA. Effectuez ensuite un scaling vers des instances répliquées supplémentaires. Cela permet au reste des répliques de lire le cache sans tenter de l'écrire.
Appliquez le fichier manifeste en exécutant la commande suivante :
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Affichez les journaux du serveur de modèles en cours d'exécution :
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}Le résultat doit ressembler à ce qui suit :
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Diffuser le modèle
Pour obtenir l'adresse IP externe du service VLLM, exécutez la commande suivante :
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interagissez avec le modèle à l'aide de
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'La sortie devrait ressembler à ce qui suit :
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configurer l'autoscaler personnalisé
Dans cette section, vous allez configurer l'autoscaling horizontal des pods à l'aide de métriques Prometheus personnalisées. Vous utilisez les métriques Google Cloud Managed Service pour Prometheus du serveur vLLM.
Pour en savoir plus, consultez Google Cloud Managed Service pour Prometheus. Cette option doit être activée par défaut sur le cluster GKE.
Configurez l'adaptateur de métriques personnalisées Stackdriver sur votre cluster :
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAjoutez le rôle Lecteur Monitoring au compte de service utilisé par l'adaptateur de métriques personnalisées Stackdriver :
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterEnregistrez le manifeste suivant sous le nom
vllm_pod_monitor.yaml:Appliquez-le au cluster :
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Générer une charge sur le point de terminaison vLLM
Générez de la charge sur le serveur vLLM pour tester la façon dont GKE effectue l'autoscaling avec une métrique vLLM personnalisée.
Exécutez un script bash (
load.sh) pour envoyerNrequêtes parallèles au point de terminaison vLLM :#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitRemplacez PARALLEL_PROCESSES par le nombre de processus parallèles que vous souhaitez exécuter.
Exécutez le script bash :
chmod +x load.sh nohup ./load.sh &
Vérifier que Google Cloud Managed Service pour Prometheus ingère les métriques
Une fois que Google Cloud Managed Service pour Prometheus a récupéré les métriques et que vous ajoutez de la charge au point de terminaison vLLM, vous pouvez afficher les métriques dans Cloud Monitoring.
Dans la console Google Cloud , accédez à la page Explorateur de métriques.
Cliquez sur < > PromQL.
Saisissez la requête suivante pour observer les métriques de trafic :
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
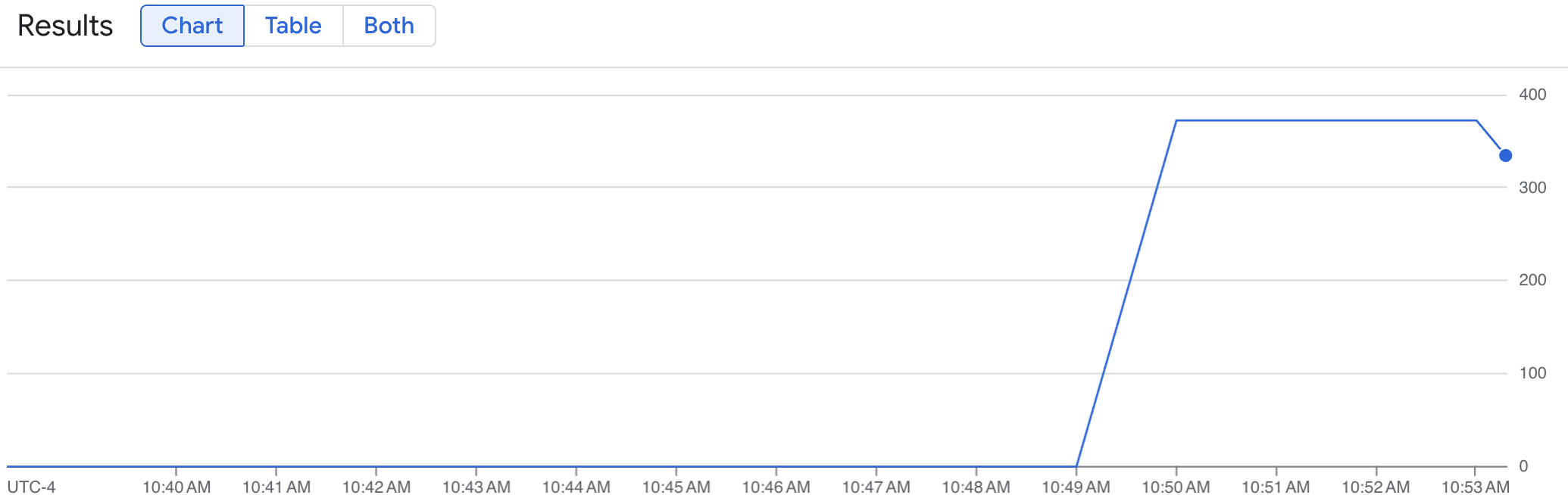
Un graphique en courbes affiche votre métrique vLLM (num_requests_waiting) mesurée au fil du temps. La métrique vLLM passe de 0 (préchargement) à une valeur (post-chargement). Ce graphique confirme que vos métriques vLLM sont ingérées dans Google Cloud Managed Service pour Prometheus. L'exemple de graphique suivant montre une valeur de préchargement initiale de 0, qui atteint une valeur de post-chargement maximale de près de 400 en une minute.
Déployer la configuration de l'autoscaler horizontal de pods
Lorsque vous choisissez la métrique sur laquelle baser l'autoscaling, nous vous recommandons les métriques suivantes pour vLLM TPU :
num_requests_waiting: cette métrique concerne le nombre de requêtes en attente dans la file d'attente du serveur de modèle. Ce nombre commence à augmenter de manière notable lorsque le cache KV est plein.gpu_cache_usage_perc: cette métrique est liée à l'utilisation du cache KV, qui est directement corrélée au nombre de requêtes traitées pour un cycle d'inférence donné sur le serveur de modèle. Notez que cette métrique fonctionne de la même manière sur les GPU et les TPU, bien qu'elle soit liée au schéma de dénomination des GPU.
Nous vous recommandons d'utiliser num_requests_waiting lorsque vous optimisez le débit et les coûts, et lorsque vos objectifs de latence sont réalisables avec le débit maximal de votre serveur de modèles.
Nous vous recommandons d'utiliser gpu_cache_usage_perc si vous avez des charges de travail sensibles à la latence où le scaling basé sur la file d'attente n'est pas assez rapide pour répondre à vos besoins.
Pour en savoir plus, consultez Bonnes pratiques pour l'autoscaling des charges de travail d'inférence de grands modèles de langage (LLM) avec des TPU.
Lorsque vous sélectionnez une cible averageValue pour votre configuration AHP, vous devez la déterminer de manière expérimentale. Consultez l'article de blog Économisez sur les GPU : autoscaling plus intelligent pour vos charges de travail d'inférence GKE pour obtenir d'autres idées sur la façon d'optimiser cette partie. Le générateur de profils utilisé dans cet article de blog fonctionne également pour vLLM TPU.
Dans les instructions suivantes, vous déployez votre configuration AHP à l'aide de la métrique num_requests_waiting. À des fins de démonstration, vous définissez la métrique sur une valeur faible afin que la configuration AHP ajuste vos répliques vLLM à deux. Pour déployer la configuration de l'autoscaler horizontal de pods à l'aide de num_requests_waiting, procédez comme suit :
Enregistrez le manifeste suivant sous le nom
vllm-hpa.yaml:Les métriques vLLM dans Google Cloud Managed Service pour Prometheus suivent le format
vllm:metric_name.Bonne pratique : Utilisez
num_requests_waitingpour faire évoluer le débit. Utilisezgpu_cache_usage_percpour les cas d'utilisation de TPU sensibles à la latence.Déployez la configuration de l'autoscaler horizontal de pods :
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE planifie le déploiement d'un autre pod, ce qui déclenche l'autoscaler du pool de nœuds pour ajouter un deuxième nœud avant de déployer la deuxième réplique vLLM.
Observez la progression de l'autoscaling des pods :
kubectl get hpa --watch -n ${NAMESPACE}Le résultat ressemble à ce qui suit :
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sPatientez 10 minutes, puis répétez les étapes de la section Vérifier que Google Cloud Managed Service pour Prometheus ingère les métriques. Google Cloud Managed Service pour Prometheus ingère désormais les métriques des deux points de terminaison vLLM.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer les ressources déployées
Pour éviter que les ressources que vous avez créées dans ce guide soient facturées sur votre compte Google Cloud , exécutez les commandes suivantes :
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CONTROL_PLANE_LOCATION}
Étapes suivantes
- Apprenez-en plus sur les TPU dans GKE.
- En savoir plus sur les métriques disponibles pour configurer votre autoscaler horizontal de pods
- Explorez le dépôt GitHub et la documentation de vLLM.