
Présentation
Ce guide vous explique comment diffuser des grands modèles de langage (LLM) de pointe tels que DeepSeek-R1 671B ou Llama 3.1 405B sur Google Kubernetes Engine (GKE) à l'aide de processeurs graphiques (GPU) sur plusieurs nœuds.
Ce guide explique comment utiliser des technologies Open Source portables (Kubernetes, vLLM et l'API LeaderWorkerSet (LWS)) pour déployer et diffuser des charges de travail d'IA/ML sur GKE, en tirant parti du contrôle précis, de l'évolutivité, de la résilience, de la portabilité et de la rentabilité de GKE.
Avant de lire cette page, assurez-vous de connaître les éléments suivants :
Arrière-plan
Cette section décrit les principales technologies utilisées dans ce guide, y compris les deux LLM utilisés comme exemples dans ce guide : DeepSeek-R1 et Llama 3.1 405B.
DeepSeek-R1
DeepSeek-R1, un grand modèle de langage de 671 milliards de paramètres développé par DeepSeek, est conçu pour l'inférence logique, le raisonnement mathématique et la résolution de problèmes en temps réel dans diverses tâches textuelles. GKE gère les exigences de calcul de DeepSeek-R1, en prenant en charge ses capacités avec des ressources évolutives, le calcul distribué et une mise en réseau efficace.
Pour en savoir plus, consultez la documentation DeepSeek.
Llama 3.1 405B
Llama 3.1 405B est un grand modèle de langage de Meta conçu pour un large éventail de tâches de traitement du langage naturel, y compris la génération de texte, la traduction et les systèmes de questions-réponses. GKE offre l'infrastructure robuste requise pour répondre aux besoins d'entraînement et de diffusion distribués des modèles de cette envergure.
Pour en savoir plus, consultez la documentation Llama.
Service Kubernetes géré GKE
Google Cloud propose une large gamme de services, y compris GKE, qui est bien adapté au déploiement et à la gestion des charges de travail d'IA/de ML. GKE est un service Kubernetes géré qui simplifie le déploiement, le scaling et la gestion des applications conteneurisées. GKE fournit l'infrastructure nécessaire, y compris des ressources évolutives, le calcul distribué et une mise en réseau efficace, pour répondre aux exigences de calcul des LLM.
Pour en savoir plus sur les concepts clés de Kubernetes, consultez Commencer à découvrir Kubernetes. Pour en savoir plus sur GKE et sur la façon dont il vous aide à faire évoluer, automatiser et gérer Kubernetes, consultez la présentation de GKE.
GPU
Les processeurs graphiques (GPU) vous permettent d'accélérer des charges de travail spécifiques, telles que le machine learning et le traitement de données. GKE propose des nœuds équipés de ces puissants GPU, ce qui vous permet de configurer votre cluster pour des performances optimales dans les tâches de machine learning et de traitement des données. GKE fournit toute une gamme d'options de types de machines pour la configuration des nœuds, y compris les types de machines avec des GPU NVIDIA H100, L4 et A100.
Pour en savoir plus, consultez À propos des GPU dans GKE.
LeaderWorkerSet (LWS)
LeaderWorkerSet (LWS) est une API de déploiement Kubernetes qui traite les modèles de déploiement courants des charges de travail d'inférence multinœuds d'IA/ML. Le service multinoeuds utilise plusieurs pods, chacun pouvant s'exécuter sur un nœud différent, pour gérer la charge de travail d'inférence distribuée. LWS permet de traiter plusieurs pods comme un groupe, ce qui simplifie la gestion de la mise en service de modèles distribuée.
vLLM et mise en service multihôte
Lorsque vous diffusez des LLM intensifs en calcul, nous vous recommandons d'utiliser vLLM et d'exécuter les charges de travail sur des GPU.
vLLM est un framework de diffusion LLM Open Source hautement optimisé qui peut augmenter le débit de diffusion sur les GPU, avec des fonctionnalités telles que les suivantes :
- Implémentation optimisée du transformateur avec PagedAttention
- Traitement par lots continu pour améliorer le débit global de diffusion
- Diffusion distribuée sur plusieurs GPU
Avec les LLM particulièrement gourmands en ressources de calcul qui ne peuvent pas tenir sur un seul nœud GPU, vous pouvez utiliser plusieurs nœuds GPU pour diffuser le modèle. vLLM permet d'exécuter des charges de travail sur plusieurs GPU avec deux stratégies :
Le parallélisme Tensor divise les multiplications matricielles dans la couche Transformer sur plusieurs GPU. Toutefois, cette stratégie nécessite un réseau rapide en raison de la communication nécessaire entre les GPU, ce qui la rend moins adaptée à l'exécution de charges de travail sur plusieurs nœuds.
Le parallélisme de pipeline divise le modèle par couche, ou verticalement. Cette stratégie ne nécessite pas de communication constante entre les GPU, ce qui en fait une meilleure option pour exécuter des modèles sur plusieurs nœuds.
Vous pouvez utiliser les deux stratégies dans le service multinoeud. Par exemple, lorsque vous utilisez deux nœuds avec huit GPU H100 chacun, vous pouvez utiliser les deux stratégies :
- Parallélisme de pipeline bidirectionnel pour partitionner le modèle sur les deux nœuds
- Parallélisme Tensor à huit voies pour partitionner le modèle sur les huit GPU de chaque nœud
Pour en savoir plus, consultez la documentation de vLLM.
Objectifs
- Préparez votre environnement avec un cluster GKE en mode Autopilot ou Standard.
- Déployez vLLM sur plusieurs nœuds de votre cluster.
- Utilisez vLLM pour diffuser le modèle via
curl.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Assurez-vous de disposer des rôles suivants sur le projet : roles/container.admin, roles/iam.serviceAccountAdmin, roles/iam.securityAdmin
Vérifier les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
-
Dans la colonne Compte principal, recherchez toutes les lignes qui vous identifient ou identifient un groupe dont vous faites partie. Pour savoir à quels groupes vous appartenez, contactez votre administrateur.
- Pour toutes les lignes qui vous spécifient ou vous incluent, consultez la colonne Rôle pour vous assurer que la liste inclut les rôles requis.
Attribuer les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Cliquez sur Sélectionner un rôle, puis recherchez le rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
-
- Créez un compte Hugging Face si vous n'en possédez pas.
- Consultez les modèles de GPU et les types de machines disponibles pour déterminer le type de machine et la région qui répondent à vos besoins.
- Vérifiez que votre projet dispose d'un quota suffisant pour
NVIDIA_H100_MEGA. Ce tutoriel utilise le type de machinea3-highgpu-8g, qui est équipé de huitNVIDIA H100 80GB GPUs. Pour en savoir plus sur les GPU et la gestion des quotas, consultez Planifier le quota de GPU et Quota de GPU.
Accéder au modèle
Vous pouvez utiliser les modèles Llama 3.1 405B ou DeepSeek-R1.
DeepSeek-R1
.Générer un jeton d'accès
Si vous n'en avez pas déjà un, générez un nouveau jeton Hugging Face :
- Cliquez sur Your Profile > Settings > Access Tokens (Votre profil > Paramètres > Jetons d'accès).
- Sélectionnez New Token (Nouveau jeton).
- Spécifiez le nom de votre choix et un rôle d'au moins
Read. - Sélectionnez Générer un jeton.
Llama 3.1 405B
.Générer un jeton d'accès
Si vous n'en avez pas déjà un, générez un nouveau jeton Hugging Face :
- Cliquez sur Your Profile > Settings > Access Tokens (Votre profil > Paramètres > Jetons d'accès).
- Sélectionnez New Token (Nouveau jeton).
- Spécifiez le nom de votre choix et un rôle d'au moins
Read. - Sélectionnez Générer un jeton.
Préparer l'environnement
Dans ce tutoriel, vous utilisez Cloud Shell pour gérer les ressources hébergées surGoogle Cloud. Cloud Shell est préinstallé avec les logiciels dont vous avez besoin pour ce tutoriel, y compris kubectl et
gcloud CLI.
Pour configurer votre environnement avec Cloud Shell, procédez comme suit :
Dans la console Google Cloud , lancez une session Cloud Shell en cliquant sur
 Activer Cloud Shell dans la consoleGoogle Cloud . Une session s'ouvre dans le volet inférieur de la console Google Cloud .
Activer Cloud Shell dans la consoleGoogle Cloud . Une session s'ouvre dans le volet inférieur de la console Google Cloud .Définissez les variables d'environnement par défaut :
gcloud config set project PROJECT_ID gcloud config set billing/quota_project PROJECT_ID export PROJECT_ID=$(gcloud config get project) export CLUSTER_NAME=CLUSTER_NAME export REGION=REGION export ZONE=ZONE export HF_TOKEN=HUGGING_FACE_TOKEN export CLUSTER_VERSION=CLUSTER_VERSIONRemplacez les valeurs suivantes :
- PROJECT_ID : ID de votre projet Google Cloud .
- CLUSTER_NAME : nom de votre cluster GKE.
- CLUSTER_VERSION : version de GKE. Pour la compatibilité avec Autopilot, utilisez la version 1.33 ou ultérieure.
- REGION : région de votre cluster GKE.
- ZONE : zone compatible avec les GPU NVIDIA H100 Tensor Core.
Créer un cluster GKE
Vous pouvez diffuser des modèles à l'aide de vLLM sur plusieurs nœuds GPU dans un cluster GKE Autopilot ou Standard. Nous vous recommandons d'utiliser un cluster Autopilot pour une expérience Kubernetes entièrement gérée. Pour choisir le mode de fonctionnement GKE le mieux adapté à vos charges de travail, consultez la section Choisir un mode de fonctionnement GKE.
Autopilot
Dans Cloud Shell, exécutez la commande suivante :
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
Standard
Créez un cluster GKE Standard avec deux nœuds de processeur :
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-16Créez un pool de nœuds A3 avec deux nœuds, chacun doté de huit GPU H100 :
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
Configurer kubectl pour communiquer avec votre cluster
Configurez kubectl pour communiquer avec votre cluster à l'aide de la commande suivante :
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
Créer un secret Kubernetes pour les identifiants Hugging Face
Créez un secret Kubernetes contenant le jeton Hugging Face à l'aide de la commande suivante :
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
Installer LeaderWorkerSet
Pour installer LWS, exécutez la commande suivante :
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
Validez que le contrôleur LeaderWorkerSet s'exécute dans l'espace de noms lws-system à l'aide de la commande suivante :
kubectl get pod -n lws-system
Le résultat ressemble à ce qui suit :
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
Déployer le serveur de modèles vLLM
Pour déployer le serveur de modèle vLLM, procédez comme suit :
Appliquez le fichier manifeste en fonction du LLM que vous souhaitez déployer.
DeepSeek-R1
Inspectez le fichier manifeste
vllm-deepseek-r1-A3.yaml.Appliquez le fichier manifeste en exécutant la commande suivante :
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
Inspectez le fichier manifeste
vllm-llama3-405b-A3.yaml.Appliquez le fichier manifeste en exécutant la commande suivante :
kubectl apply -f vllm-llama3-405b-A3.yaml
Attendez que le point de contrôle du modèle ait fini d'être téléchargé. Cette opération peut prendre plusieurs minutes.
Affichez les journaux du serveur de modèle en cours d'exécution à l'aide de la commande suivante :
kubectl logs vllm-0 -c vllm-leaderLe résultat doit ressembler à ce qui suit :
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Diffuser le modèle
Configurez le transfert de port vers le modèle en exécutant la commande suivante :
kubectl port-forward svc/vllm-leader 8080:8080
Interagir avec le modèle à l'aide de curl
Pour interagir avec le modèle à l'aide de curl, suivez ces instructions :
DeepSeek-R1
Dans un nouveau terminal, envoyez une requête au serveur :
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
La sortie devrait ressembler à ce qui suit :
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
Dans un nouveau terminal, envoyez une requête au serveur :
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
La sortie devrait ressembler à ce qui suit :
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configurer l'autoscaler personnalisé
Dans cette section, vous allez configurer l'autoscaling horizontal de pods pour utiliser des métriques Prometheus personnalisées. Vous utilisez les métriques Google Cloud Managed Service pour Prometheus du serveur vLLM.
Pour en savoir plus, consultez Google Cloud Managed Service pour Prometheus. Cette option doit être activée par défaut sur le cluster GKE.
Configurez l'adaptateur de métriques personnalisées Stackdriver sur votre cluster :
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAjoutez le rôle Lecteur Monitoring au compte de service utilisé par l'adaptateur de métriques personnalisées Stackdriver :
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterEnregistrez le manifeste suivant sous le nom
vllm_pod_monitor.yaml:Appliquez le fichier manifeste au cluster :
kubectl apply -f vllm_pod_monitor.yaml
Générer une charge sur le point de terminaison vLLM
Générez de la charge sur le serveur vLLM pour tester la façon dont GKE effectue l'autoscaling avec une métrique vLLM personnalisée.
Configurez le transfert de port vers le modèle :
kubectl port-forward svc/vllm-leader 8080:8080Exécutez un script bash (
load.sh) pour envoyerNrequêtes parallèles au point de terminaison vLLM :#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitRemplacez PARALLEL_PROCESSES par le nombre de processus parallèles que vous souhaitez exécuter.
Exécutez le script bash :
nohup ./load.sh &
Vérifier que Google Cloud Managed Service pour Prometheus ingère les métriques
Une fois que Google Cloud Managed Service pour Prometheus a récupéré les métriques et que vous ajoutez de la charge au point de terminaison vLLM, vous pouvez afficher les métriques dans Cloud Monitoring.
Dans la console Google Cloud , accédez à la page Explorateur de métriques.
Cliquez sur < > PromQL.
Saisissez la requête suivante pour observer les métriques de trafic :
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
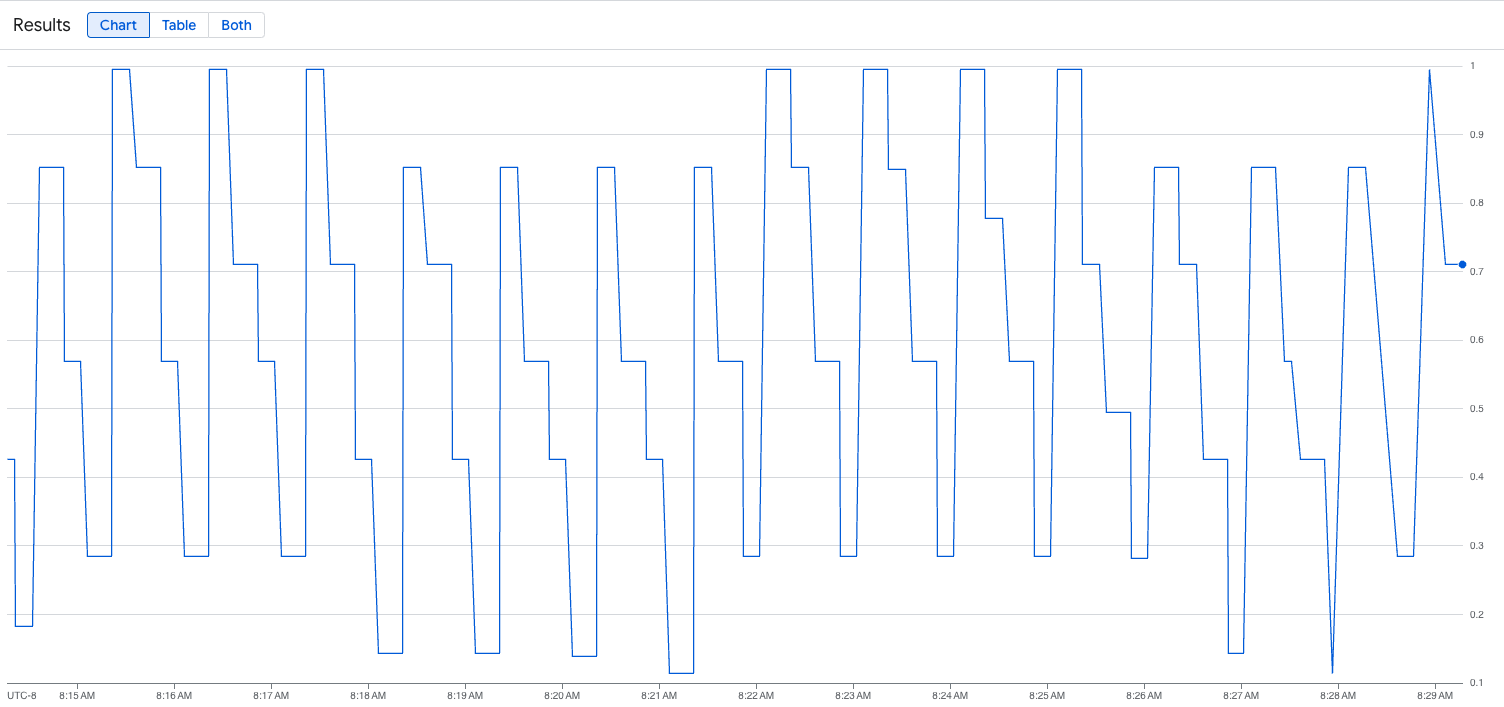
L'image suivante est un exemple de graphique après l'exécution du script de chargement. Ce graphique montre que Google Cloud Managed Service pour Prometheus ingère les métriques de trafic en réponse à la charge ajoutée au point de terminaison vLLM :
Déployer la configuration de l'autoscaler horizontal de pods
Lorsque vous choisissez la métrique sur laquelle baser l'autoscaling, nous vous recommandons les métriques suivantes pour vLLM :
num_requests_waiting: cette métrique concerne le nombre de requêtes en attente dans la file d'attente du serveur de modèle. Ce nombre commence à augmenter de manière notable lorsque le cache KV est plein.gpu_cache_usage_perc: cette métrique est liée à l'utilisation du cache KV, qui est directement corrélée au nombre de requêtes traitées pour un cycle d'inférence donné sur le serveur de modèles.
Nous vous recommandons d'utiliser num_requests_waiting lorsque vous optimisez le débit et les coûts, et lorsque vos objectifs de latence sont réalisables avec le débit maximal de votre serveur de modèles.
Nous vous recommandons d'utiliser gpu_cache_usage_perc lorsque vous avez des charges de travail sensibles à la latence où le scaling basé sur la file d'attente n'est pas assez rapide pour répondre à vos besoins.
Pour en savoir plus, consultez Bonnes pratiques pour l'autoscaling des charges de travail d'inférence de grands modèles de langage (LLM) avec des GPU.
Lorsque vous sélectionnez une cible averageValue pour votre configuration AHP, vous devez déterminer de manière expérimentale la métrique sur laquelle effectuer l'autoscaling. Pour obtenir d'autres idées sur l'optimisation de vos expériences, consultez le blog Économiser sur les GPU : un autoscaling plus intelligent pour vos charges de travail d'inférence GKE. Le générateur de profils utilisé dans cet article de blog fonctionne également pour vLLM.
Pour déployer la configuration de l'autoscaler horizontal de pods à l'aide de num_requests_waiting, procédez comme suit :
Enregistrez le manifeste suivant sous le nom
vllm-hpa.yaml:Les métriques vLLM dans Google Cloud Managed Service pour Prometheus suivent le format
vllm:metric_name.Bonne pratique : Utilisez
num_requests_waitingpour faire évoluer le débit. Utilisezgpu_cache_usage_percpour les cas d'utilisation de GPU sensibles à la latence.Déployez la configuration de l'autoscaler horizontal de pods :
kubectl apply -f vllm-hpa.yamlGKE planifie le déploiement d'un autre pod, ce qui déclenche l'autoscaler du pool de nœuds pour ajouter un deuxième nœud avant de déployer la deuxième réplique vLLM.
Observez la progression de l'autoscaling des pods :
kubectl get hpa --watchLe résultat ressemble à ce qui suit :
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
Accélérer les temps de chargement des modèles avec Google Cloud Hyperdisk ML
Avec ces types de LLM, vLLM peut prendre beaucoup de temps pour télécharger, charger et réchauffer chaque nouveau réplica. Par exemple, ce processus peut prendre environ 90 minutes avec Llama 3.1 405B. Vous pouvez réduire ce temps (à 20 minutes avec Llama 3.1 405B) en téléchargeant le modèle directement sur un volume Hyperdisk ML et en associant ce volume à chaque pod. Pour effectuer cette opération, ce tutoriel utilise un volume Hyperdisk ML et un job Kubernetes. Dans Kubernetes, un contrôleur de job crée un ou plusieurs pods et s'assure qu'ils exécutent correctement une tâche spécifique.
Pour accélérer les temps de chargement des modèles, procédez comme suit :
Enregistrez l'exemple de fichier manifeste suivant sous le nom
producer-pvc.yaml:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800GiEnregistrez l'exemple de fichier manifeste suivant sous le nom
producer-job.yaml:DeepSeek-R1
Llama 3.1 405B
Suivez les instructions de la section Accélérer le chargement des données d'IA/ML avec Hyperdisk ML, en utilisant les deux fichiers que vous avez créés lors des étapes précédentes.
À l'issue de cette étape, vous aurez créé et rempli le volume Hyperdisk ML avec les données du modèle.
Déployez le déploiement du serveur GPU multinœud vLLM, qui utilisera le volume Hyperdisk ML nouvellement créé pour les données du modèle.
DeepSeek-R1
Llama 3.1 405B
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer les ressources déployées
Pour éviter que les ressources que vous avez créées dans ce guide soient facturées sur votre compte Google Cloud , exécutez la commande suivante :
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete CLUSTER_NAME \
--location=ZONE
Étapes suivantes
- Apprenez-en plus sur les GPU dans GKE.
- Explorez le dépôt GitHub et la documentation de vLLM.
- Explorez le dépôt GitHub LWS.