
Neste documento, mostramos como acelerar o carregamento dos pesos de modelos de IA grandes do Cloud Storage usando o Run:ai Model Streamer com o servidor de inferência vLLM no Google Kubernetes Engine (GKE).
A solução neste documento pressupõe que você já tenha carregado seu modelo e pesos de IA no formato safetensors em um bucket do Cloud Storage.
Ao adicionar a flag --load-format=runai_streamer à implantação do vLLM, é possível usar o Run:ai Model Streamer para melhorar a eficiência do download de modelos para suas cargas de trabalho de IA no GKE.
Este documento é destinado aos seguintes usuários:
- Engenheiros de machine learning (ML) que precisam carregar modelos grandes de IA do armazenamento de objetos para nós de GPU/TPU o mais rápido possível.
- Administradores e operadores de plataforma que automatizam e otimizam a infraestrutura de disponibilização de modelos no GKE.
- Arquitetos de nuvem que avaliam ferramentas especializadas de carregamento de dados para cargas de trabalho de IA/ML.
Para saber mais sobre papéis comuns e exemplos de tarefas referenciados no conteúdo do Google Cloud , consulte Funções e tarefas comuns do usuário do GKE.
Visão geral
A solução descrita neste documento usa três componentes principais: Run:ai Model Streamer, vLLM e o formato de arquivo safetensors para acelerar o processo de carregamento de pesos de modelo do Cloud Storage para nós de GPU.
Run:ai Model Streamer
O Run:ai Model Streamer é um SDK Python de código aberto que acelera o carregamento de modelos de IA grandes em GPUs. Ele transmite pesos do modelo diretamente do armazenamento, como buckets do Cloud Storage, para a memória da GPU. O streamer de modelo é especialmente adequado para acessar arquivos safetensors localizados no Cloud Storage.
safetensors
O safetensors é um formato de arquivo para armazenar tensores, as estruturas de dados principais em modelos de IA, de uma forma que melhora a segurança e a velocidade. O safetensors foi projetado como uma alternativa ao formato pickle do Python e permite tempos de carregamento rápidos com uma abordagem de cópia zero. Com essa abordagem, os tensores ficam acessíveis diretamente da origem sem precisar carregar todo o arquivo na memória local primeiro.
vLLM
O vLLM é uma biblioteca de código aberto para inferência e disponibilização de LLMs. É um servidor de inferência de alto desempenho otimizado para carregar rapidamente modelos grandes de IA. Neste documento, o vLLM é o mecanismo principal que executa seu modelo de IA no GKE e processa as solicitações de inferência recebidas. O suporte integrado de autenticação do Run:ai Model Streamer para o Cloud Storage requer a versão 0.11.1 ou mais recente do vLLM.
Como o Run:ai Model Streamer acelera o carregamento de modelos
Quando você inicia um aplicativo de IA baseado em LLM para inferência, geralmente ocorre um atraso significativo antes que o modelo esteja pronto para uso. Esse atraso, conhecido como inicialização a frio, acontece porque todo o arquivo do modelo de vários gigabytes precisa ser baixado de um local de armazenamento, como um bucket do Cloud Storage, para o disco local da sua máquina. Em seguida, o arquivo é carregado na memória da GPU. Durante esse período de carregamento, a GPU cara fica ociosa, o que é ineficiente e caro.
Em vez do processo de download e carregamento, o streamer de modelo transmite o modelo diretamente do Cloud Storage para a memória da GPU. O streamer usa um back-end de alta performance para ler várias partes do modelo, chamadas de tensores, em paralelo. Ler tensores simultaneamente é muito mais rápido do que carregar o arquivo de forma sequencial.
Informações gerais da arquitetura
O Run:ai Model Streamer se integra ao vLLM no GKE para acelerar o carregamento de modelos transmitindo pesos de modelos diretamente do Cloud Storage para a memória da GPU, sem passar pelo disco local.
O diagrama a seguir mostra essa arquitetura:
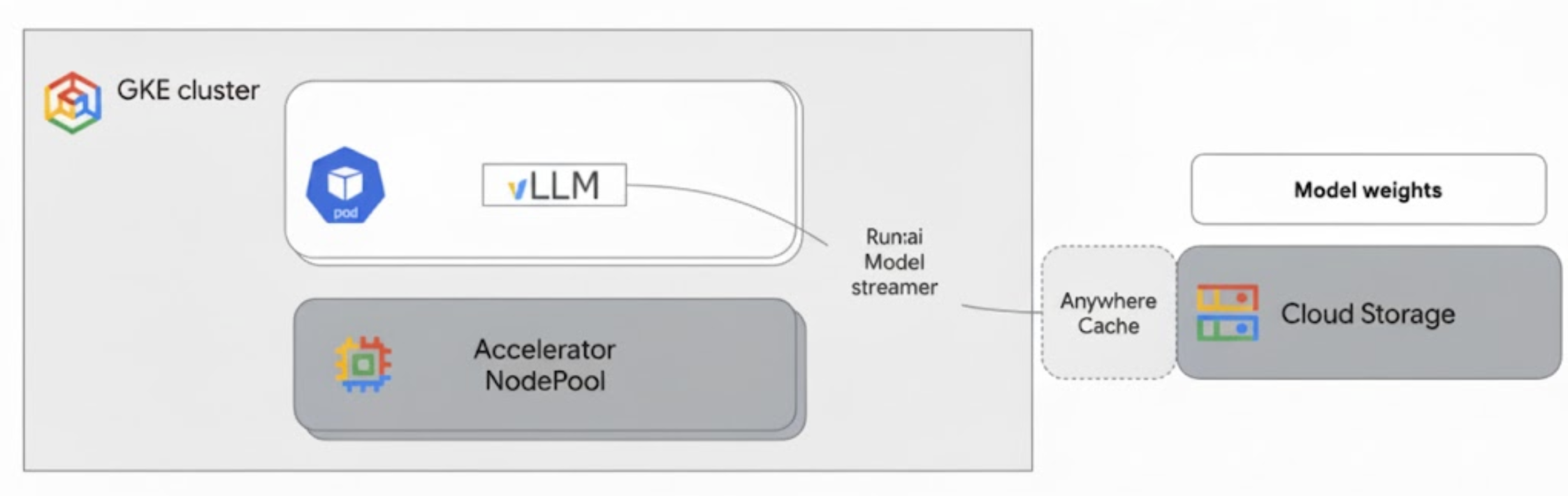
Essa arquitetura inclui os seguintes componentes e fluxo de trabalho:
- Bucket do Cloud Storage: armazena os pesos do modelo de IA no formato
safetensors. - Pod do GKE com GPU: executa o servidor de inferência do vLLM.
- Servidor de inferência vLLM: configurado com a flag
--load-format=runai_streamer, que ativa a funcionalidade de streamer de modelos. - Run:ai Model Streamer: quando o vLLM é iniciado, o streamer de modelo lê os pesos do modelo do caminho
gs://especificado no bucket do Cloud Storage. Em vez de baixar arquivos para o disco, ele transmite dados de tensor diretamente para a memória da GPU do pod do GKE, onde ficam imediatamente disponíveis para o vLLM para inferência. - Cache em qualquer lugar do Cloud Storage (opcional): se ativado, o Cache em qualquer lugar armazena em cache os dados do bucket na mesma zona que os nós do GKE, acelerando ainda mais o acesso aos dados para o streamer.
Vantagens
- Tempos de inicialização a frio reduzidos:o streamer de modelo reduz significativamente o tempo necessário para que os modelos sejam iniciados. Ele carrega os pesos do modelo até seis vezes mais rápido em comparação com os métodos convencionais. Para mais informações, consulte Comparativos de performance do Run:ai Model Streamer.
- Utilização aprimorada da GPU:ao minimizar os atrasos no carregamento do modelo, as GPUs podem dedicar mais tempo às tarefas de inferência reais, aumentando a eficiência geral e a capacidade de processamento.
- Fluxo de trabalho simplificado:a solução descrita neste documento se integra ao GKE, permitindo que servidores de inferência como vLLM ou SGLang acessem diretamente modelos em buckets do Cloud Storage.
Antes de começar
Siga os seguintes pré-requisitos:
Selecionar ou criar um projeto e ativar as APIs
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Configurar o Cloud Shell
Este documento usa os comandos da Google Cloud CLI e do kubectl para criar e gerenciar os recursos necessários para essa solução. Para executar esses comandos no Cloud Shell, clique em Ativar o Cloud Shell na parte de cima do console Google Cloud .
In the Google Cloud console, activate Cloud Shell.
Como alternativa, instale e inicialize a CLI gcloud no ambiente shell local para executar os comandos. Se você quiser usar um terminal de shell local, execute o comando gcloud auth login para fazer a autenticação com Google Cloud.
Conceder papéis do IAM
Verifique se sua conta do Google Cloud tem os seguintes papéis do IAM no projeto para que você possa criar um cluster do GKE e gerenciar o Cloud Storage:
roles/container.adminroles/storage.admin
Para conceder esses papéis, execute os seguintes comandos:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Substitua PROJECT_ID pela ID do seu projeto.
Preparar o ambiente
Esta seção mostra como configurar o cluster do GKE e as permissões para acessar seu modelo no Cloud Storage.
Criar um cluster do GKE com GPUs
O Run:ai Model Streamer pode ser usado com clusters do GKE Autopilot e Standard. Escolha o modo de cluster que melhor atende às suas necessidades.
Defina variáveis para o nome do projeto e do cluster:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMESubstitua:
PROJECT_ID: o ID do projeto Google Cloud . Para encontrar o ID do projeto, execute o comandogcloud config get-value project.CLUSTER_NAME: o nome do cluster. Por exemplo,run-ai-test.
Crie um cluster do Autopilot ou Standard:
Piloto automático
Siga estas etapas para criar um cluster do GKE Autopilot:
Defina a região do cluster:
export REGION=REGIONSubstitua
REGIONpela região em que você quer criar o cluster. Para ter um desempenho ideal, use a mesma região do bucket do Cloud Storage.Crie o cluster:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Os clusters do Autopilot provisionam nós automaticamente com base nos requisitos da carga de trabalho. Quando você implanta o servidor vLLM em uma etapa posterior, o Autopilot provisiona os nós de GPU, se necessário. Para mais informações, consulte Sobre a criação automática de pools de nós.
Padrão
Siga estas etapas para criar um cluster do GKE Standard:
Defina a zona do cluster:
export ZONE=ZONESubstitua
ZONEpela zona em que você quer criar o cluster. Para ter um desempenho ideal, use uma zona na mesma região do seu bucket do Cloud Storage.Crie o cluster:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1Crie um pool de nós com uma máquina G2 (GPU NVIDIA L4):
gcloud container node-pools create g2-gpu-pool \ --cluster=$CLUSTER_NAME \ --zone=$ZONE \ --machine-type=g2-standard-16 \ --num-nodes=1 \ --accelerator=type=nvidia-l4
Configurar a Federação de Identidade da Carga de Trabalho para GKE
Configure a federação de identidade da carga de trabalho para GKE e permita que suas cargas de trabalho do GKE acessem o modelo no bucket do Cloud Storage com segurança.
Defina variáveis para sua conta de serviço e namespace do Kubernetes:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACESubstitua:
NAMESPACE: o namespace em que você quer que as cargas de trabalho sejam executadas. Use o mesmo namespace para criar todos os recursos neste documento.KSA_NAME: o nome da conta de serviço do Kubernetes que seu pod pode usar para autenticar nas APIs do Google Cloud .
Crie um namespace do Kubernetes:
kubectl create namespace $NAMESPACECrie uma conta de serviço do Kubernetes (KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEConceda ao KSA as permissões necessárias:
Defina as variáveis de ambiente:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Substitua:
BUCKET_NAME: o nome do bucket do Cloud Storage que contém seus arquivossafetensors.PROJECT_ID: o ID do projeto Google Cloud .
Os
PROJECT_NUMBER,PROJECT_ID,NAMESPACEeKSA_NAMEserão usados para construir o identificador principal da federação de identidade da carga de trabalho para o GKE do seu projeto nas etapas a seguir.Conceda o papel
roles/storage.bucketViewerà sua KSA para visualizar objetos no bucket do Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Conceda o papel
roles/storage.objectUserà sua KSA para ler, gravar e excluir objetos no bucket do Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Agora você configurou um cluster do GKE com GPUs e configurou a Federação de Identidade da Carga de Trabalho para GKE, concedendo a uma conta de serviço do Kubernetes as permissões necessárias para acessar seu modelo de IA no Cloud Storage. Com o cluster e as permissões definidos, você está pronto para implantar o servidor de inferência vLLM, que vai usar essa conta de serviço para transmitir pesos de modelo com o Run:ai Model Streamer.
Implantar o vLLM com o Run:ai Model Streamer
Implante um pod que execute o servidor compatível com vLLM OpenAI e esteja configurado com a flag --load-format=runai_streamer para usar o Model Streamer da Run:ai. A versão do vLLM precisa ser 0.11.1 ou mais recente.
O manifesto de exemplo a seguir mostra uma configuração do vLLM com o streamer de modelo ativado para um modelo pequeno, como gemma-2-9b-it, usando uma única GPU NVIDIA L4.
- Se você estiver usando um modelo grande que exige várias GPUs, aumente o valor de
--tensor-parallel-sizepara o número necessário de GPUs. - A flag
--model-loader-extra-config={"distributed":true}ativa o carregamento distribuído de pesos de modelo e é uma configuração recomendada para melhorar o desempenho do carregamento de modelos do armazenamento de objetos.
Para mais informações, consulte Paralelismo de tensores e Parâmetros ajustáveis.
Salve o seguinte manifesto
vllm-deployment.yamlcomo : O manifesto foi projetado para flexibilidade em clusters do Autopilot e Standard.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmSubstitua:
NAMESPACE: o namespace do Kubernetes.KSA_NAME: o nome da sua conta de serviço do Kubernetes.BUCKET_NAME: seu nome do bucket do Cloud StoragePATH_TO_MODEL: o caminho para o diretório do modelo no bucket, por exemplo,models/my-llama.
Aplique o manifesto para criar a implantação:
kubectl create -f vllm-deployment.yaml
É possível gerar mais manifestos do vLLM usando a ferramenta Guia de início rápido do GKE Inference.
Verificar a implantação
Verifique o status da implantação:
kubectl get deployments -n NAMESPACEConsiga o nome do pod:
kubectl get pods -n NAMESPACE | grep vllm-streamerAnote o nome do pod que começa com
vllm-streamer-deployment.Para verificar se o streamer de modelo faz o download do modelo e dos pesos, confira os registros do pod:
kubectl logs -f POD_NAME -n NAMESPACESubstitua
POD_NAMEpelo nome do pod da etapa anterior. Os registros de streaming bem-sucedidos são semelhantes a este:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Opcional: melhorar a performance com o Anywhere Cache
O Anywhere Cache do Cloud Storage pode acelerar ainda mais o carregamento de modelos armazenando dados em cache mais perto dos nós do GKE. O armazenamento em cache é especialmente benéfico ao escalonar vários nós na mesma zona.
Você ativa o Anywhere Cache para um bucket específico do Cloud Storage em uma Google Cloud zona específica. Para melhorar o desempenho, a zona do cache precisa corresponder à zona em que os pods de inferência do GKE são executados. Sua abordagem depende de os pods serem executados em zonas previsíveis.
Para clusters zonais do GKE Standard, em que você sabe em qual zona os pods serão executados, ative o Anywhere Cache para essa zona específica.
Para clusters regionais do GKE (Autopilot e Standard), em que os pods podem ser programados em várias zonas, você tem as seguintes opções:
- Ativar o armazenamento em cache em todas as zonas: ative o Anywhere Cache em todas as zonas da região do cluster. Isso garante que um cache esteja disponível, não importa onde o GKE programe seus pods. Você vai incorrer em custos para cada zona em que o armazenamento em cache estiver ativado. Para mais informações, consulte Preços do Anywhere Cache.
- Colocar pods em uma zona específica: use uma regra
nodeSelectorounodeAffinityno manifesto da carga de trabalho para restringir os pods a uma única zona. Em seguida, ative o Anywhere Cache apenas nessa zona. Essa é uma abordagem mais econômica se a carga de trabalho tolerar a restrição a uma única zona.
Para ativar o Anywhere Cache na zona em que o cluster do GKE está localizado, execute os seguintes comandos:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste documento, exclua o projeto que contém os recursos ou mantenha o projeto e exclua os recursos individuais.
Para excluir os recursos individuais, siga estas etapas:
Exclua o cluster do GKE. Essa ação remove todos os nós e cargas de trabalho.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONSubstitua:
CLUSTER_NAME: o nome do cluster.ZONE_OR_REGION: a zona ou região do cluster.
Desative o Anywhere Cache, se ele estiver ativado, para evitar custos contínuos. Para mais informações, consulte Desativar um cache.
A seguir
- Saiba como carregar modelos do Hugging Face no Cloud Storage (experimental)
- Saiba como disponibilizar LLMs no GKE usando GPUs.
- Saiba mais sobre as GPUs disponíveis no GKE.
- Leia a visão geral do armazenamento do GKE.
- Saiba como configurar a federação de identidade da carga de trabalho.