
Questo documento mostra come accelerare il caricamento dei pesi dei modelli di AI di grandi dimensioni da Cloud Storage utilizzando Run:ai Model Streamer con il server di inferenza vLLM su Google Kubernetes Engine (GKE).
La soluzione descritta in questo documento presuppone che tu abbia già caricato il modello di AI e i relativi pesi in formato safetensors in un bucket Cloud Storage.
Aggiungendo il flag --load-format=runai_streamer al deployment di vLLM, puoi utilizzare Run:ai Model Streamer per migliorare l'efficienza del download dei modelli per i carichi di lavoro di AI su GKE.
Questo documento è rivolto ai seguenti utenti:
- Ingegneri di machine learning (ML) che devono caricare modelli di AI di grandi dimensioni dall'object storage nei nodi GPU/TPU il più rapidamente possibile.
- Amministratori e operatori di piattaforme che automatizzano e ottimizzano l'erogazione del modello su GKE.
- Architetti cloud che valutano strumenti di caricamento dei dati specializzati per i carichi di lavoro di AI/ML.
Per saperne di più sui ruoli comuni e sulle attività di esempio a cui si fa riferimento nel Google Cloud contenuto, consulta Ruoli e attività utente GKE comuni.
Panoramica
La soluzione descritta in questo documento utilizza tre componenti principali: Run:ai Model Streamer, vLLM e il formato di file safetensors, per accelerare il processo di caricamento dei pesi dei modelli da Cloud Storage nei nodi GPU o TPU.
Run:ai Model Streamer
Run:ai Model Streamer
è un SDK Python open source che velocizza il caricamento di modelli di AI di grandi dimensioni sugli
acceleratori. Trasmette i pesi dei modelli direttamente dallo spazio di archiviazione, come i bucket Cloud Storage, alla memoria GPU o TPU. Il model streamer è particolarmente adatto per accedere ai file safetensors che si trovano in Cloud Storage.
safetensors
safetensors è un formato di file per archiviare i tensori, le strutture di dati principali nei modelli di AI, in modo da migliorare sia la sicurezza che la velocità. safetensors è progettato come alternativa al formato pickle di Python e consente tempi di caricamento rapidi grazie a un approccio zero-copy. Questo approccio consente di accedere direttamente ai tensori dall'origine senza dover prima caricare l'intero file nella memoria locale.
vLLM
vLLM è una libreria open source per l' inferenza e la pubblicazione di LLM. È un server di inferenza ad alte prestazioni ottimizzato per il caricamento rapido di modelli di AI di grandi dimensioni. In questo documento, vLLM è il motore principale che esegue il modello di AI su GKE e gestisce le richieste di inferenza in entrata. Il supporto di autenticazione integrato di Run:ai Model Streamer per Cloud Storage richiede vLLM versione 0.11.1 o successive per le GPU e 0.18.0 o successive per le TPU.
In che modo Run:ai Model Streamer accelera il caricamento dei modelli
Quando avvii un'applicazione di AI basata su LLM per l'inferenza, spesso si verifica un ritardo significativo prima che il modello sia pronto per l'uso. Questo ritardo, noto come avvio a freddo, si verifica perché l'intero file del modello di più gigabyte deve essere scaricato da una località di archiviazione, come un bucket Cloud Storage, sul disco locale della macchina. Il file viene quindi caricato nella memoria dell'acceleratore. Durante questo periodo di caricamento, l'acceleratore costoso rimane inattivo, il che è inefficiente e costoso.
Anziché il processo di download e caricamento, il model streamer trasmette il modello direttamente da Cloud Storage alla memoria GPU o TPU. Lo streamer utilizza un backend ad alte prestazioni per leggere in parallelo più parti del modello, chiamate tensori. La lettura simultanea dei tensori è notevolmente più veloce rispetto al caricamento sequenziale del file.
Panoramica dell'architettura
Run:ai Model Streamer si integra con vLLM su GKE per accelerare il caricamento dei modelli trasmettendo i pesi dei modelli direttamente da Cloud Storage alla memoria dell'acceleratore, bypassando il disco locale.
Il seguente diagramma mostra questa architettura:
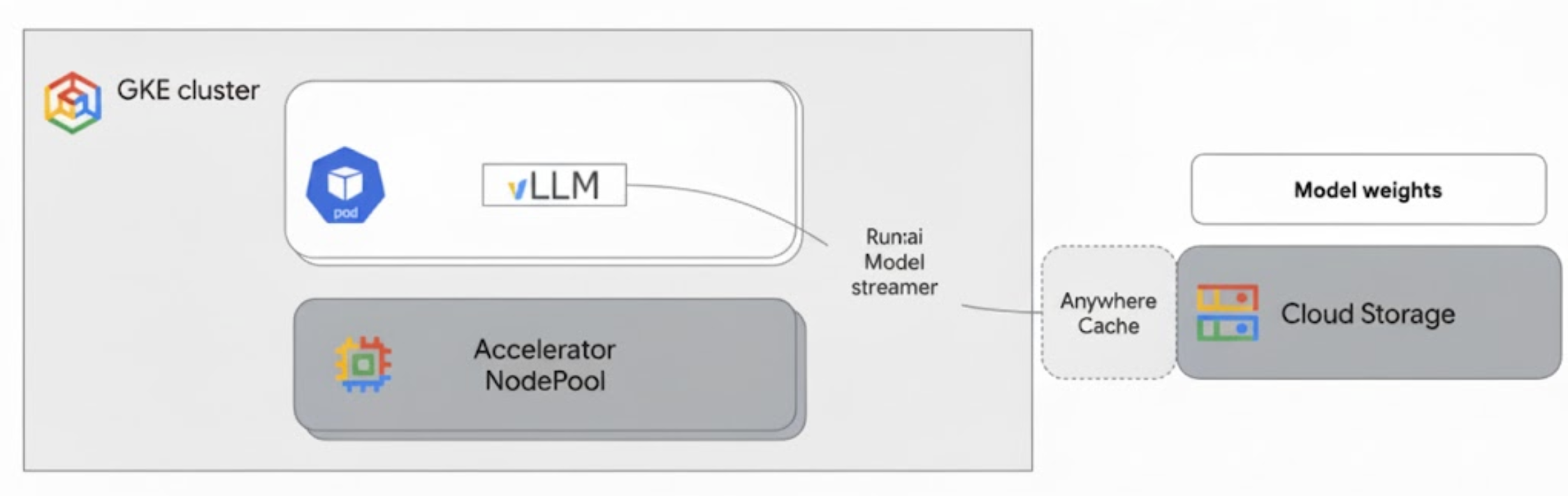
Questa architettura include i seguenti componenti e workflow:
- Bucket Cloud Storage: archivia i pesi dei modelli di AI in formato
safetensors. - Pod GKE con GPU o TPU: esegue il server di inferenza vLLM.
- Server di inferenza vLLM: configurato con il flag
--load-format=runai_streamer, che abilita la funzionalità di model streamer. - Run:ai Model Streamer: quando vLLM si avvia, il model streamer legge i pesi dei modelli dal percorso
gs://specificato nel bucket Cloud Storage. Anziché scaricare i file sul disco, trasmette i dati dei tensori direttamente nella memoria dell'acceleratore del pod GKE, dove sono immediatamente disponibili per l'inferenza di vLLM. - Cloud Storage Rapid Cache (facoltativo): se abilitata, Rapid Cache memorizza nella cache i dati del bucket nella stessa zona dei nodi GKE, accelerando ulteriormente l'accesso ai dati per lo streamer.
Vantaggi
- Tempi di avvio a freddo ridotti: il model streamer riduce significativamente il tempo necessario per l'avvio dei modelli. Carica i pesi dei modelli fino a sei volte più velocemente rispetto ai metodi convenzionali. Per saperne di più, consulta i benchmark di Run:ai Model Streamer
- Utilizzo migliorato dell'acceleratore: riducendo al minimo i ritardi nel caricamento dei modelli, gli acceleratori come GPU e TPU possono dedicare più tempo alle attività di inferenza effettive, aumentando l'efficienza complessiva e la capacità di elaborazione.
- Workflow semplificato: la soluzione descritta in questo documento si integra con GKE, consentendo ai server di inferenza come vLLM o SGLang di accedere direttamente ai modelli nei bucket Cloud Storage.
Prima di iniziare
Assicurati di completare i seguenti prerequisiti.
Seleziona o crea un progetto e abilita le API
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Configura Cloud Shell
Questo documento utilizza i comandi Google Cloud CLI e kubectl per creare e gestire le risorse richieste per questa soluzione. Puoi eseguire questi
comandi in Cloud Shell facendo clic su Attiva Cloud Shell nella parte superiore de
lla Google Cloud console.
Nella Google Cloud console, attiva Cloud Shell.
In alternativa, puoi installare e inizializzare gcloud CLI nel tuo ambiente shell locale per eseguire i comandi. Se vuoi utilizzare un terminale shell locale, esegui il comando gcloud auth login per eseguire l'autenticazione con Google Cloud.
Concedi ruoli IAM
Assicurati che il tuo Google Cloud account disponga dei seguenti ruoli IAM nel progetto in modo da poter creare un cluster GKE e gestire Cloud Storage:
roles/container.adminroles/storage.admin
Per concedere questi ruoli, esegui i seguenti comandi:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Sostituisci PROJECT_ID con l'ID progetto.
Prepara l'ambiente
Questa sezione ti guida nella configurazione del cluster GKE e delle autorizzazioni per accedere al modello in Cloud Storage.
Crea un cluster GKE
Run:ai Model Streamer può essere utilizzato sia con i cluster GKE Autopilot che con quelli standard. Scegli la modalità cluster più adatta alle tue esigenze.
Imposta le variabili per il progetto e il nome del cluster:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMESostituisci quanto segue:
PROJECT_ID: l' Google Cloud ID progetto. Puoi trovare l'ID progetto eseguendo il comandogcloud config get-value project.CLUSTER_NAME: il nome del cluster. Ad esempio,run-ai-test.
Crea un cluster Autopilot o Standard:
Autopilot
Per creare un cluster GKE Autopilot:
Imposta la regione del cluster:
export REGION=REGIONSostituisci
REGIONcon la regione in cui vuoi creare il cluster. Per prestazioni ottimali, utilizza la stessa regione del bucket Cloud Storage.Crea il cluster:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
I cluster Autopilot eseguono automaticamente il provisioning dei nodi in base ai requisiti del carico di lavoro. Quando esegui il deployment del server vLLM in un passaggio successivo, Autopilot eseguirà il provisioning dei nodi GPU o TPU, se necessario. Per saperne di più, consulta Informazioni sulla creazione automatica dei pool di nodi.
Standard
Per creare un cluster GKE Standard:
Imposta la zona del cluster:
export ZONE=ZONESostituisci
ZONEcon la zona in cui vuoi creare il cluster. Per prestazioni ottimali, utilizza una zona nella stessa regione del bucket Cloud Storage.Crea il cluster:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1
Crea un pool di nodi
Se hai creato un cluster standard, devi creare un pool di nodi con GPU o TPU. I cluster Autopilot eseguono automaticamente il provisioning dei nodi in base ai requisiti del carico di lavoro. Crea un pool di nodi in base all'acceleratore che vuoi utilizzare:
* {GPU}
Create a node pool with one G2 machine (NVIDIA L4 GPU):
```sh
gcloud container node-pools create g2-gpu-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=g2-standard-16 \
--num-nodes=1 \
--accelerator=type=nvidia-l4
```
* {TPU}
Create a node pool with TPU v7x nodes:
```sh
gcloud container node-pools create tpu7x-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=tpu7x-standard-4t \
--num-nodes=1
```
Configura Workload Identity Federation for GKE
Configura Workload Identity Federation for GKE per consentire ai carichi di lavoro GKE di accedere in modo sicuro al modello nel bucket Cloud Storage.
Imposta le variabili per il account di servizio e lo spazio dei nomi Kubernetes:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACESostituisci quanto segue:
NAMESPACE: lo spazio dei nomi in cui vuoi eseguire i carichi di lavoro. Assicurati di utilizzare lo stesso spazio dei nomi per creare tutte le risorse in questo documento.KSA_NAME: il nome del account di servizio Kubernetes che il pod può utilizzare per l'autenticazione alle Google Cloud API.
Crea uno spazio dei nomi Kubernetes:
kubectl create namespace $NAMESPACECrea un account di servizio Kubernetes (KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEConcedi al KSA le autorizzazioni necessarie:
Imposta le variabili di ambiente:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Sostituisci quanto segue:
BUCKET_NAME: il nome del bucket Cloud Storage che contiene i filesafetensors.PROJECT_ID: l' Google Cloud ID progetto.
PROJECT_NUMBER,PROJECT_ID,NAMESPACEeKSA_NAMEverranno utilizzati per creare l'identificatore principale di Workload Identity Federation for GKE per il tuo progetto nei passaggi seguenti.Concedi il ruolo
roles/storage.bucketVieweral KSA per visualizzare gli oggetti nel bucket Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Concedi il ruolo
roles/storage.objectUseral KSA per leggere, scrivere ed eliminare gli oggetti nel bucket Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Ora hai configurato un cluster GKE con GPU o TPU e Workload Identity Federation for GKE, concedendo a un service account Kubernetes le autorizzazioni necessarie per accedere al modello di AI in Cloud Storage. Con il cluster e le autorizzazioni in vigore, puoi eseguire il deployment del server di inferenza vLLM, che utilizzerà questo account di servizio per trasmettere i pesi dei modelli con Run:ai Model Streamer.
Esegui il deployment di vLLM con Run:ai Model Streamer
Esegui il deployment di un pod che esegue il server compatibile con vLLM OpenAI e configurato con il flag --load-format=runai_streamer per utilizzare Run:ai Model Streamer. La versione di vLLM deve essere 0.11.1 o successive per le GPU e 0.18.0 o successive per le TPU.
I seguenti manifest di esempio mostrano come configurare vLLM con il model streamer abilitato per un modello di piccole dimensioni, come gemma-2-9b-it.
Il flag --model-loader-extra-config={"distributed":true} abilita
il caricamento distribuito dei pesi dei modelli ed è un'impostazione consigliata per
migliorare le prestazioni di caricamento dei modelli dall'object storage.
Per saperne di più, consulta Parallelismo dei tensori e Parametri regolabili.
Seleziona il manifest di esempio in base all'acceleratore che vuoi utilizzare:
GPU
Il seguente manifest di esempio utilizza una singola GPU NVIDIA L4. Se utilizzi un modello di grandi dimensioni che richiede più GPU, aumenta il valore
--tensor-parallel-sizeal numero di GPU richiesto.Salva il seguente manifest come
vllm-deployment.yaml. Il manifest è progettato per la flessibilità sia nei cluster Autopilot che in quelli standard.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmSostituisci quanto segue:
NAMESPACE: il tuo spazio dei nomi Kubernetes.KSA_NAME: il nome del tuo account di servizio Kubernetes.BUCKET_NAME: il nome del tuo bucket Cloud Storage.PATH_TO_MODEL: il percorso della directory del modello all'interno del bucket, ad esempiomodels/my-llama.
TPU
Il seguente manifest di esempio utilizza i nodi TPU v7x.
Salva il seguente manifest come
vllm-deployment.yaml.apiVersion: apps/v1 kind: Deployment metadata: name: tpu-vllm namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: tpu-vllm template: metadata: labels: app: tpu-vllm spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-tpu:v0.18.0 resources: limits: google.com/tpu: "4" command: ["sh", "-c"] args: - >- python3 -m vllm.entrypoints.openai.api_server --model=gs://BUCKET_NAME/PATH_TO_MODEL --load-format=runai_streamer --tensor-parallel-size=8 --port=8000 ports: - containerPort: 8000 env: - name: VLLM_XLA_CACHE_PATH value: "gs://BUCKET_NAME/PATH_TO_CACHE" nodeSelector: cloud.google.com/gke-tpu-accelerator: tpu7x cloud.google.com/gke-tpu-topology: 2x2x1Sostituisci quanto segue:
NAMESPACE: il tuo spazio dei nomi Kubernetes.KSA_NAME: il nome del tuo account di servizio Kubernetes.BUCKET_NAME: il nome del tuo bucket Cloud Storage.PATH_TO_MODEL: il percorso della directory del modello all'interno del bucket, ad esempiomodels/my-llama.PATH_TO_CACHE: il percorso della directory della cache di compilazione XLA all'interno del bucket, ad esempiomodels/xla-cache.
Applica il manifest per creare il deployment:
kubectl create -f vllm-deployment.yaml
Puoi generare altri manifest vLLM utilizzando lo strumento GKE Inference Quickstart.
Verifica il deployment
Verifica lo stato del deployment:
kubectl get deployments -n NAMESPACERecupera il nome del pod:
kubectl get pods -n NAMESPACE | grep vllm-streamerPrendi nota del nome del pod che inizia con
vllm-streamer-deployment.Per verificare se il model streamer scarica il modello e i pesi, visualizza i log del pod:
kubectl logs -f POD_NAME -n NAMESPACESostituisci
POD_NAMEcon il nome del pod del passaggio precedente. I log di streaming riusciti sono simili ai seguenti:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Facoltativo: migliora le prestazioni con Rapid Cache
Cloud Storage Rapid Cache può accelerare ulteriormente il caricamento dei modelli memorizzando nella cache i dati più vicini ai nodi GKE. La memorizzazione nella cache è particolarmente utile quando si esegue lo scale out di più nodi nella stessa zona.
Puoi abilitare Rapid Cache per un bucket Cloud Storage specifico in una zona specifica Google Cloud . Per migliorare le prestazioni, la zona della cache deve corrispondere alla zona in cui vengono eseguiti i pod di inferenza GKE. Il tuo approccio dipende dal fatto che i pod vengano eseguiti in zone prevedibili.
Per i cluster di zona GKE Standard, in cui sai in quale zona verranno eseguiti i pod, abilita Rapid Cache per quella zona specifica.
Per i cluster GKE regionali (sia Autopilot che Standard), in cui i pod possono essere pianificati in più zone, hai le seguenti opzioni:
- Abilita la memorizzazione nella cache in tutte le zone: abilita Rapid Cache in ogni zona all'interno della regione del cluster. In questo modo, una cache è disponibile indipendentemente dalla posizione in cui GKE pianifica i pod. Tieni presente che ti verranno addebitati costi per ogni zona in cui è abilitata la memorizzazione nella cache. Per saperne di più, consulta i prezzi di Rapid Cache.
- Posiziona i pod in una zona specifica: utilizza una regola
nodeSelectoronodeAffinitynel manifest del carico di lavoro per limitare i pod a una singola zona. Puoi quindi abilitare Rapid Cache solo in quella zona. Questo è un approccio più conveniente se il carico di lavoro tollera di essere limitato a una singola zona.
Per abilitare Rapid Cache per la zona in cui si trova il cluster GKE, esegui i seguenti comandi:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Libera spazio
Per evitare che al tuo Google Cloud account vengano addebitati costi relativi alle risorse utilizzate in questo documento, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Per eliminare le singole risorse, segui questi passaggi:
Elimina il cluster GKE. Questa azione rimuove tutti i nodi e i carichi di lavoro.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONSostituisci quanto segue:
CLUSTER_NAME: il nome del cluster.ZONE_OR_REGION: la zona o la regione del cluster.
Disabilita Rapid Cache, se l'hai abilitata, per evitare costi continui. Per saperne di più, consulta Disabilitare una cache.
Passaggi successivi
- Scopri come caricare i modelli Hugging Face in Cloud Storage (sperimentale)
- Scopri come erogare un LLM con più GPU in GKE.
- Scopri di più sulle GPU disponibili su GKE.
- Scopri di più sulle TPU disponibili su GKE.
- Leggi la panoramica dell'archiviazione GKE.
- Scopri come configurare la federazione delle identità per i workload.