
Ce document explique comment accélérer le chargement des pondérations de grands modèles d'IA à partir de Cloud Storage à l'aide de Run:ai Model Streamer avec le serveur d'inférence vLLM sur Google Kubernetes Engine (GKE).
La solution présentée dans ce document suppose que votre modèle d'IA et vos pondérations au format safetensors sont déjà chargés dans un bucket Cloud Storage.
En ajoutant l'indicateur --load-format=runai_streamer à votre déploiement vLLM, vous pouvez utiliser Run:ai Model Streamer pour améliorer l'efficacité du téléchargement de modèles pour vos charges de travail d'IA sur GKE.
Ce document est destiné aux utilisateurs suivants :
- Ingénieurs en machine learning (ML) qui doivent charger de grands modèles d'IA depuis le stockage d'objets vers des nœuds GPU/TPU le plus rapidement possible.
- Administrateurs et opérateurs de plate-forme qui automatisent et optimisent l'infrastructure de diffusion de modèles sur GKE.
- Architectes cloud qui évaluent des outils de chargement de données spécialisés pour les charges de travail d'IA/de ML.
Pour en savoir plus sur les rôles courants et les exemples de tâches cités dans le contenu Google Cloud , consultez Rôles utilisateur et tâches courantes de GKE.
Présentation
La solution décrite dans ce document utilise trois composants principaux (Run:ai Model Streamer, vLLM et le format de fichier safetensors) pour accélérer le processus de chargement des pondérations de modèle depuis Cloud Storage vers les nœuds GPU.
Run:ai Model Streamer
Run:ai Model Streamer est un SDK Python Open Source qui accélère le chargement de grands modèles d'IA sur les GPU. Il diffuse les pondérations du modèle directement depuis le stockage, comme les buckets Cloud Storage, vers la mémoire de votre GPU. Le flux de modèle est particulièrement adapté à l'accès aux fichiers safetensors situés dans Cloud Storage.
safetensors
safetensors est un format de fichier permettant de stocker des Tensors, les structures de données de base des modèles d'IA, de manière à améliorer à la fois la sécurité et la vitesse. safetensors est conçu comme une alternative au format pickle de Python. Il permet des temps de chargement rapides grâce à une approche sans copie. Cette approche permet d'accéder directement aux Tensors à partir de la source, sans avoir à charger d'abord l'intégralité du fichier dans la mémoire locale.
vLLM
vLLM est une bibliothèque Open Source pour l'inférence et la diffusion de LLM. Il s'agit d'un serveur d'inférence hautes performances optimisé pour charger rapidement de grands modèles d'IA. Dans ce document, vLLM est le moteur principal qui exécute votre modèle d'IA sur GKE et gère les demandes d'inférence entrantes. L'authentification intégrée de Run:ai Model Streamer pour Cloud Storage nécessite vLLM version 0.11.1 ou ultérieure.
Comment Run:ai Model Streamer accélère le chargement des modèles
Lorsque vous démarrez une application d'IA basée sur un LLM pour l'inférence, un délai important se produit souvent avant que le modèle ne soit prêt à être utilisé. Ce délai, appelé démarrage à froid, se produit parce que l'intégralité du fichier de modèle de plusieurs gigaoctets doit être téléchargée depuis un emplacement de stockage, comme un bucket Cloud Storage, vers le disque local de votre machine. Le fichier est ensuite chargé dans la mémoire de votre GPU. Pendant cette période de chargement, le GPU coûteux reste inactif, ce qui est inefficace et coûteux.
Au lieu du processus de téléchargement puis de chargement, le flux de modèle diffuse le modèle directement depuis votre Cloud Storage vers la mémoire du GPU. Le flux utilise un backend hautes performances pour lire plusieurs parties du modèle, appelées tenseurs, en parallèle. La lecture simultanée des Tensors est beaucoup plus rapide que le chargement séquentiel du fichier.
Présentation de l'architecture
Run:ai Model Streamer s'intègre à vLLM sur GKE pour accélérer le chargement des modèles en diffusant les pondérations des modèles directement depuis Cloud Storage vers la mémoire GPU, en contournant le disque local.
Le schéma suivant illustre cette architecture :
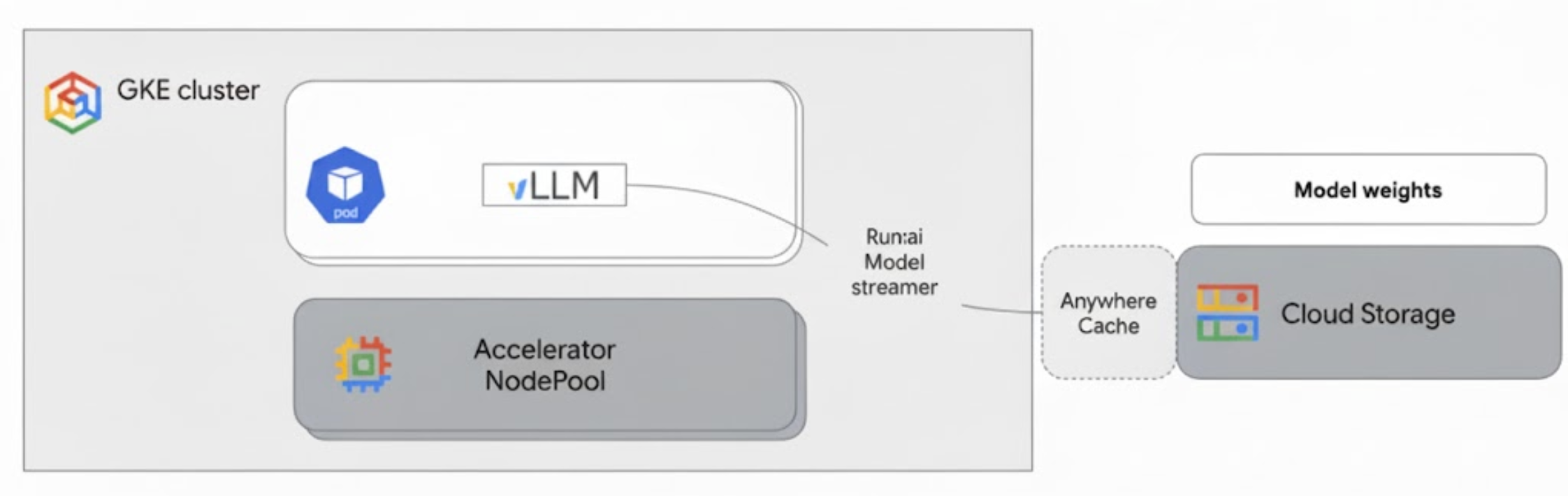
Cette architecture comprend les composants et le workflow suivants :
- Bucket Cloud Storage : stocke les pondérations du modèle d'IA au format
safetensors. - Pod GKE avec GPU : exécute le serveur d'inférence vLLM.
- Serveur d'inférence vLLM : configuré avec l'indicateur
--load-format=runai_streamer, qui active la fonctionnalité de flux de modèle. - Run:ai Model Streamer : lorsque vLLM démarre, le flux de modèle lit les pondérations du modèle à partir du chemin d'accès
gs://spécifié dans le bucket Cloud Storage. Au lieu de télécharger des fichiers sur le disque, il diffuse les données de Tensor directement dans la mémoire GPU du pod GKE, où elles sont immédiatement disponibles pour l'inférence vLLM. - Cache Anywhere Cloud Storage (facultatif) : si cette option est activée, Anywhere Cache met en cache les données du bucket dans la même zone que les nœuds GKE, ce qui accélère encore l'accès aux données pour le flux.
Avantages
- Réduction des temps de démarrage à froid : le flux de modèles réduit considérablement le temps nécessaire au démarrage des modèles. Il charge les pondérations du modèle jusqu'à six fois plus rapidement que les méthodes classiques. Pour en savoir plus, consultez Benchmarks Run:ai Model Streamer.
- Utilisation améliorée du GPU : en minimisant les délais de chargement des modèles, les GPU peuvent consacrer plus de temps aux tâches d'inférence proprement dites, ce qui améliore l'efficacité globale et la capacité de traitement.
- Workflow simplifié : la solution décrite dans ce document s'intègre à GKE, ce qui permet aux serveurs d'inférence tels que vLLM ou SGLang d'accéder directement aux modèles dans les buckets Cloud Storage.
Avant de commencer
Assurez-vous de remplir les conditions préalables suivantes.
Sélectionner ou créer un projet et activer les API
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Configurer Cloud Shell
Ce document utilise les commandes Google Cloud CLI et kubectl pour créer et gérer les ressources requises pour cette solution. Vous pouvez exécuter ces commandes dans Cloud Shell en cliquant sur Activer Cloud Shell en haut de la console Google Cloud .
In the Google Cloud console, activate Cloud Shell.
Vous pouvez également installer et initialiser gcloud CLI dans votre environnement de shell local pour exécuter les commandes. Si vous souhaitez utiliser un terminal shell local, exécutez la commande gcloud auth login pour vous authentifier auprès de Google Cloud.
Attribuer des rôles IAM
Assurez-vous que votre compte Google Cloud dispose des rôles IAM suivants sur votre projet afin de pouvoir créer un cluster GKE et gérer Cloud Storage :
roles/container.adminroles/storage.admin
Pour attribuer ces rôles, exécutez les commandes suivantes :
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Remplacez PROJECT_ID par l'ID du projet.
Préparer votre environnement
Cette section vous explique comment configurer votre cluster GKE et les autorisations d'accès à votre modèle dans Cloud Storage.
Créer un cluster GKE avec des GPU
Run:ai Model Streamer peut être utilisé avec les clusters GKE Autopilot et Standard. Choisissez le mode de cluster qui répond le mieux à vos besoins.
Définissez des variables pour le nom de votre projet et de votre cluster :
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMERemplacez les éléments suivants :
PROJECT_ID: ID de votre projet Google Cloud . Vous pouvez trouver l'ID de votre projet en exécutant la commandegcloud config get-value project.CLUSTER_NAME: le nom du cluster Exemple :run-ai-test
Créez un cluster Autopilot ou Standard :
Autopilot
Pour créer un cluster GKE Autopilot :
Définissez la région de votre cluster :
export REGION=REGIONRemplacez
REGIONpar la région dans laquelle vous souhaitez créer votre cluster. Pour des performances optimales, utilisez la même région que votre bucket Cloud Storage.Créez le cluster :
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Les clusters Autopilot provisionnent automatiquement les nœuds en fonction des exigences de la charge de travail. Lorsque vous déploierez le serveur vLLM à une étape ultérieure, Autopilot provisionnera les nœuds GPU si nécessaire. Pour en savoir plus, consultez À propos de la création automatique de pools de nœuds.
Standard
Pour créer un cluster GKE Standard, procédez comme suit :
Définissez la zone de votre cluster :
export ZONE=ZONERemplacez
ZONEpar la zone dans laquelle vous souhaitez créer votre cluster. Pour des performances optimales, utilisez une zone située dans la même région que votre bucket Cloud Storage.Créez le cluster :
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1Créez un pool de nœuds avec une machine G2 (GPU NVIDIA L4) :
gcloud container node-pools create g2-gpu-pool \ --cluster=$CLUSTER_NAME \ --zone=$ZONE \ --machine-type=g2-standard-16 \ --num-nodes=1 \ --accelerator=type=nvidia-l4
Configurer Workload Identity Federation for GKE
Configurez la fédération d'identité de charge de travail pour GKE afin de permettre à vos charges de travail GKE d'accéder de manière sécurisée au modèle dans votre bucket Cloud Storage.
Définissez des variables pour votre compte de service et votre espace de noms Kubernetes :
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACERemplacez les éléments suivants :
NAMESPACE: espace de noms sur lequel vous souhaitez exécuter vos charges de travail. Veillez à utiliser le même espace de noms pour créer toutes les ressources de ce document.KSA_NAME: nom du compte de service Kubernetes que votre pod peut utiliser pour s'authentifier auprès des API Google Cloud .
Créez un espace de noms Kubernetes :
kubectl create namespace $NAMESPACECréez un compte de service Kubernetes (KSA) :
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEAccordez les autorisations nécessaires à votre KSA :
Définissez les variables d'environnement :
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Remplacez les éléments suivants :
BUCKET_NAME: nom du bucket Cloud Storage contenant vos fichierssafetensors.PROJECT_ID: ID de votre projet Google Cloud .
Les valeurs
PROJECT_NUMBER,PROJECT_ID,NAMESPACEetKSA_NAMEseront utilisées pour construire l'identifiant principal de la fédération d'identité de charge de travail pour GKE pour votre projet lors des étapes suivantes.Attribuez le rôle
roles/storage.bucketViewerà votre KSA pour afficher les objets dans votre bucket Cloud Storage :gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Attribuez le rôle
roles/storage.objectUserà votre clé de compte de service pour l'autoriser à lire, écrire et supprimer des objets dans votre bucket Cloud Storage :gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Vous avez maintenant configuré un cluster GKE avec des GPU et la fédération d'identité de charge de travail pour GKE, en accordant à un compte de service Kubernetes les autorisations nécessaires pour accéder à votre modèle d'IA dans Cloud Storage. Une fois le cluster et les autorisations en place, vous êtes prêt à déployer le serveur d'inférence vLLM, qui utilisera ce compte de service pour diffuser les pondérations du modèle avec Run:ai Model Streamer.
Déployer vLLM avec Run:ai Model Streamer
Déployez un pod qui exécute le serveur compatible vLLM OpenAI et qui est configuré avec l'indicateur --load-format=runai_streamer pour utiliser Run:ai Model Streamer. La version de vLLM doit être 0.11.1 ou ultérieure.
L'exemple de fichier manifeste suivant montre une configuration vLLM avec le flux de modèle activé pour un modèle de petite taille, comme gemma-2-9b-it, à l'aide d'un seul GPU NVIDIA L4.
- Si vous utilisez un grand modèle qui nécessite plusieurs GPU, augmentez la valeur
--tensor-parallel-sizeau nombre de GPU requis. - L'indicateur
--model-loader-extra-config={"distributed":true}permet le chargement distribué des pondérations de modèle. Il s'agit d'un paramètre recommandé pour améliorer les performances de chargement de modèle à partir du stockage d'objets.
Pour en savoir plus, consultez Parallélisme tensoriel et Paramètres ajustables.
Enregistrez le fichier manifeste suivant sous le nom
vllm-deployment.yaml. Le fichier manifeste est conçu pour être flexible à la fois pour les clusters Autopilot et Standard.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmRemplacez les éléments suivants :
NAMESPACE: votre espace de noms Kubernetes.KSA_NAME: nom de votre compte de service Kubernetes.BUCKET_NAME: nom de votre bucket Cloud Storage.PATH_TO_MODEL: chemin d'accès au répertoire de votre modèle dans le bucket, par exemplemodels/my-llama.
Appliquez le fichier manifeste pour créer le déploiement :
kubectl create -f vllm-deployment.yaml
Vous pouvez générer d'autres fichiers manifestes vLLM à l'aide de l'outil GKE Inference Quickstart.
Vérifier le déploiement
Vérifiez l'état du déploiement :
kubectl get deployments -n NAMESPACEObtenez le nom du pod :
kubectl get pods -n NAMESPACE | grep vllm-streamerNotez le nom du pod commençant par
vllm-streamer-deployment.Pour vérifier si le flux de modèle télécharge le modèle et les pondérations, consultez les journaux du pod :
kubectl logs -f POD_NAME -n NAMESPACERemplacez
POD_NAMEpar le nom du pod obtenu à l'étape précédente. Les journaux de streaming réussis ressemblent à ce qui suit :[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Facultatif : Améliorer les performances avec Anywhere Cache
Cloud Storage Anywhere Cache peut accélérer davantage le chargement des modèles en mettant en cache les données plus près de vos nœuds GKE. La mise en cache est particulièrement utile lorsque vous effectuez un scaling horizontal de plusieurs nœuds dans la même zone.
Vous activez Anywhere Cache pour un bucket Cloud Storage spécifique dans une zone Google Cloud spécifique. Pour améliorer les performances, la zone du cache doit correspondre à celle dans laquelle s'exécutent vos pods d'inférence GKE. Votre approche dépend du fait que vos pods s'exécutent dans des zones prévisibles ou non.
Pour les clusters zonaux GKE Standard, où vous savez dans quelle zone vos pods s'exécuteront, activez Anywhere Cache pour cette zone spécifique.
Pour les clusters GKE régionaux (Autopilot et Standard), où les pods peuvent être planifiés dans plusieurs zones, vous disposez des options suivantes :
- Activer la mise en cache dans toutes les zones : activez Anywhere Cache dans chaque zone de la région du cluster. Cela garantit qu'un cache est disponible, quel que soit l'endroit où GKE planifie vos pods. Notez que des frais vous sont facturés pour chaque zone où la mise en cache est activée. Pour en savoir plus, consultez les tarifs d'Anywhere Cache.
- Placer des pods dans une zone spécifique : utilisez une règle
nodeSelectorounodeAffinitydans le fichier manifeste de votre charge de travail pour contraindre vos pods à une seule zone. Vous pouvez ensuite activer Anywhere Cache uniquement dans cette zone. Il s'agit d'une approche plus rentable si votre charge de travail tolère d'être limitée à une seule zone.
Pour activer Anywhere Cache pour la zone dans laquelle réside votre cluster GKE, exécutez les commandes suivantes :
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce document ne soient facturées sur votre compte Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Pour supprimer les ressources individuelles, procédez comme suit :
Supprimez le cluster GKE. Cette action supprime tous les nœuds et toutes les charges de travail.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONRemplacez les éléments suivants :
CLUSTER_NAME: nom du clusterZONE_OR_REGION: zone ou région de votre cluster.
Si vous l'avez activé, désactivez Anywhere Cache pour éviter les coûts continus. Pour en savoir plus, consultez Désactiver un cache.
Étapes suivantes
- Découvrez comment charger des modèles Hugging Face dans Cloud Storage (version expérimentale).
- Découvrez comment diffuser des LLM sur GKE à l'aide de GPU.
- En savoir plus sur les GPU disponibles sur GKE
- Consultez la présentation de GKE Storage.
- En savoir plus sur la configuration de la fédération d'identité de charge de travail