
This page shows you how to perform incremental roll out operations, that gradually deploy new versions of your inference infrastructure, for GKE Inference Gateway. This gateway lets you perform safe and controlled updates to your inference infrastructure. You can update nodes, base models, and LoRA adapters with minimal service disruption. This page also provides guidance on traffic splitting and rollbacks to ensure reliable deployments.
This page is for GKE Identity and account admins and Developers who want to perform roll out operations for GKE Inference Gateway.
The following use cases are supported:
Update a node roll out
Node updates safely migrate inference workloads to new node hardware or accelerator configurations. This process occurs in a controlled manner without interrupting model service. Use node updates to minimize service disruption during hardware upgrades, driver updates, or security issue resolution.
Create a new
InferencePool: deploy anInferencePoolconfigured with the updated node or hardware specifications.Split traffic using an
HTTPRoute: configure anHTTPRouteto distribute traffic between the existing and newInferencePoolresources. Use theweightfield inbackendRefsto manage the traffic percentage directed to the new nodes.Maintain a consistent
InferenceObjective: retain the existingInferenceObjectiveconfiguration to ensure uniform model behavior across both node configurations.Retain original resources: keep the original
InferencePooland nodes active during the roll out to enable rollbacks if needed.
For example, you can create a new InferencePool named llm-new. Configure
this pool with the same model configuration as your existing llm
InferencePool. Deploy the pool on a new set of nodes within your cluster. Use
an HTTPRoute object to split traffic between the original llm and the new
llm-new InferencePool. This technique lets you incrementally update your
model nodes.
The following diagram illustrates how GKE Inference Gateway performs a node update roll out.
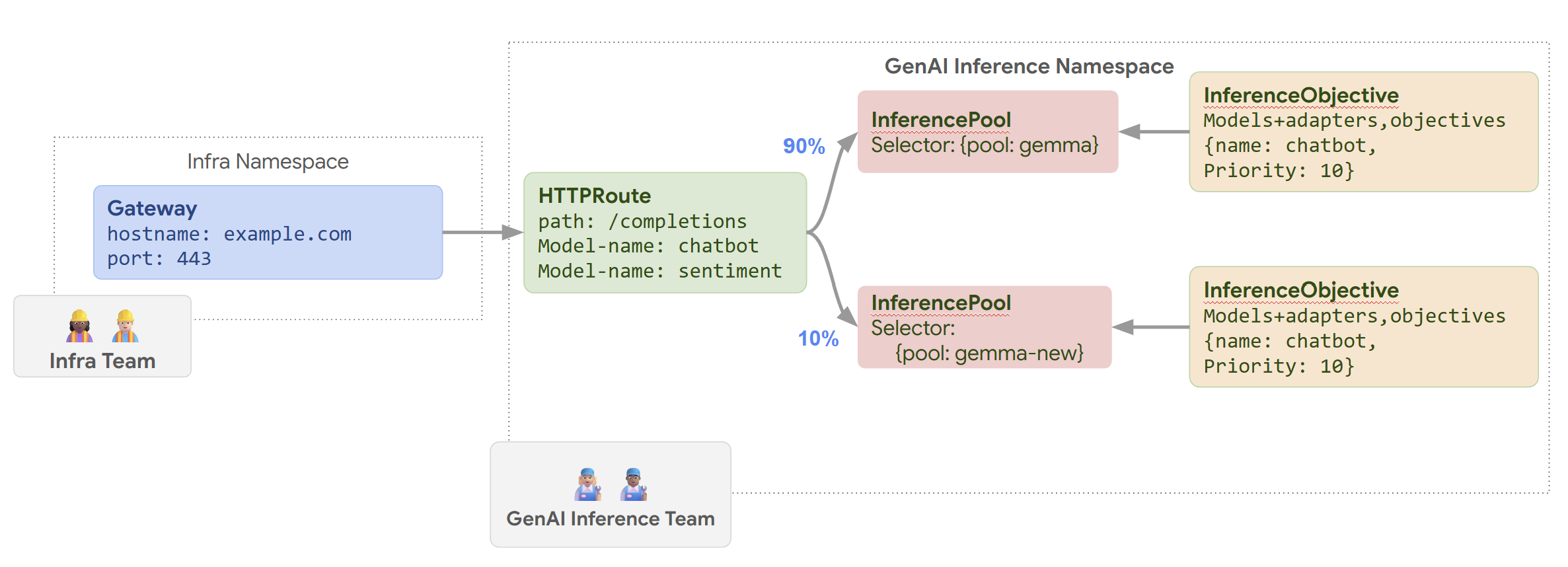
To perform a node update roll out, follow these steps:
Save the following sample manifest as
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Apply the sample manifest to your cluster:
kubectl apply -f routes-to-llm.yaml
The original llm InferencePool receives most of the traffic, while the
llm-new InferencePool receives the rest. Increase the traffic weight gradually
for the llm-new InferencePool to complete the node update roll out.
Roll out a base model
Base model updates roll out in phases to a new base LLM, retaining compatibility with existing LoRA adapters. You can use base model update roll outs to upgrade to improved model architectures or to address model-specific issues.
To roll out a base model update:
- Deploy new infrastructure: create new nodes and a new
InferencePoolconfigured with the new base model that you chose. - Configure traffic distribution: use an
HTTPRouteto split traffic between the existingInferencePool(which uses the old base model) and the newInferencePool(using the new base model). ThebackendRefs weightfield controls the traffic percentage allocated to each pool. - Maintain
InferenceObjectiveintegrity: keep yourInferenceObjectiveconfiguration unchanged. This ensures that the system applies the same LoRA adapters consistently across both base model versions. - Preserve rollback capability: retain the original nodes and
InferencePoolduring the roll out to facilitate a rollback if necessary.
You create a new InferencePool named llm-pool-version-2. This pool deploys
a new version of the base model on a new set of nodes. By
configuring an HTTPRoute, as shown in the provided example, you can
incrementally split traffic between the original llm-pool and
llm-pool-version-2. This lets you control base model updates in your
cluster.
To perform a base model update roll out, follow these steps:
Save the following sample manifest as
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Apply the sample manifest to your cluster:
kubectl apply -f routes-to-llm.yaml
The original llm-pool InferencePool receives most of the traffic, while the
llm-pool-version-2 InferencePool receives the rest. Increase the traffic
weight gradually for the llm-pool-version-2 InferencePool to complete the
base model update roll out.