本页面介绍了 Google Kubernetes Engine (GKE) 推理网关的关键概念和功能,这是 GKE 网关的一项扩展功能,用于优化生成式 AI 应用的服务。
本页面假定您了解以下内容:
- GKE 上的 AI/机器学习编排
- 生成式 AI 术语
- GKE 网络概念,包括 Service 和 GKE Gateway API
- Google Cloud中的负载均衡,尤其是负载均衡器如何与 GKE 交互
本页面适用于以下人员:
- 有兴趣使用 Kubernetes 容器编排功能处理 AI/机器学习工作负载的机器学习 (ML) 工程师、平台管理员和运维人员以及数据和 AI 专家。
- 与 Kubernetes 网络交互的云架构师和网络专家。
概览
GKE 推理网关是 GKE 网关的一种扩展程序,可提供优化路由和负载均衡来处理生成式人工智能 (AI) 工作负载。它简化了 AI 推理工作负载的部署、管理和可观测性。
如需为 AI/机器学习工作负载选择最佳负载均衡策略,请参阅为 GKE 上的 AI 推理选择负载均衡策略。
特性和优势
GKE 推理网关提供以下关键功能,可高效地为 GKE 上的生成式 AI 应用部署生成式 AI 模型:
- 支持的指标:
KV cache hits:键值 (KV) 缓存中成功查找的次数。- GPU 或 TPU 利用率:GPU 或 TPU 处于活跃处理状态的时间百分比。
- 请求队列长度:等待处理的请求数。
- 用于推理的优化负载均衡:分配请求以优化 AI 模型部署性能。它使用来自模型服务器的指标(例如
KV cache hits和queue length of pending requests),以便更高效地使用加速器(例如 GPU 和 TPU)来处理生成式 AI 工作负载。这会启用前缀缓存感知路由,这是一项关键功能,可通过分析请求正文来识别具有共享上下文的请求,并将其发送到同一模型副本,从而最大限度地提高缓存命中率。这种方法可大幅减少冗余计算并缩短首次令牌生成时间,因此非常适合对话式 AI、检索增强生成 (RAG) 和其他基于模板的生成式 AI 工作负载。 - 动态 LoRA 微调模型部署:支持在通用加速器上部署动态 LoRA 微调模型。此功能通过在通用基本模型和加速器上对多个 LoRA 微调模型进行多路复用,减少了部署模型所需的 GPU 和 TPU 数量。
- 用于推理的优化自动扩缩:GKE Pod 横向自动扩缩器 (HPA) 使用模型服务器指标进行自动扩缩,这有助于确保高效使用计算资源并优化推理性能。
- 模型感知路由:根据 GKE 集群的
OpenAI API规范中定义的模型名称来路由推理请求。您可以定义网关路由政策(例如流量分配和请求镜像),以管理不同的模型版本并简化模型发布。例如,您可以将针对特定模型名称的请求路由到不同的InferencePool对象,每个对象部署不同版本的模型。 如需详细了解如何配置此功能,请参阅配置基于正文的路由。 - 集成式 AI 安全和内容过滤:GKE 推理网关与 Google Cloud Model Armor 集成,以便在网关处对提示和回答应用 AI 安全检查和内容过滤。您还可以使用 NVIDIA NeMo Guardrails。 Model Armor 会提供请求、响应和处理的日志,以进行回顾性分析和优化。 GKE 推理网关的开放式接口使第三方提供方和开发者可以将自定义服务集成到推理请求流程中。
- 特定于模型的部署
Priority:可让您指定 AI 模型的部署Priority。优先处理对延迟时间敏感的请求,而非能够容忍延迟时间的批量推理作业。例如在资源受限时,您可以优先处理对延迟时间敏感的应用发出的请求,并舍弃对时间不太敏感的任务。 - 推理可观测性:提供用于推理请求的可观测性指标,例如请求速率、延迟时间、错误和饱和度。通过 Cloud Monitoring 和 Cloud Logging 监控推理服务的性能和行为,并利用专门的预建信息中心获取详细的分析洞见。如需了解详情,请参阅查看 GKE 推理网关信息中心。
- 使用 Apigee 进行高级 API 管理:与 Apigee 集成,以增强推理网关的功能,例如 API 安全性、速率限制和配额。如需了解详细说明,请参阅配置 Apigee 以进行身份验证和 API 管理。
- 可扩展性:基于可扩展的开源 Kubernetes Gateway API 推理扩展程序构建,支持用户管理的端点选择器算法。
了解主要概念
GKE 推理网关增强了使用 GatewayClass 对象的现有 GKE 网关。GKE 推理网关引入了以下新的 Gateway API 自定义资源定义 (CRD),这些 CRD 与 OSS Kubernetes Gateway API 推理扩展程序保持一致:
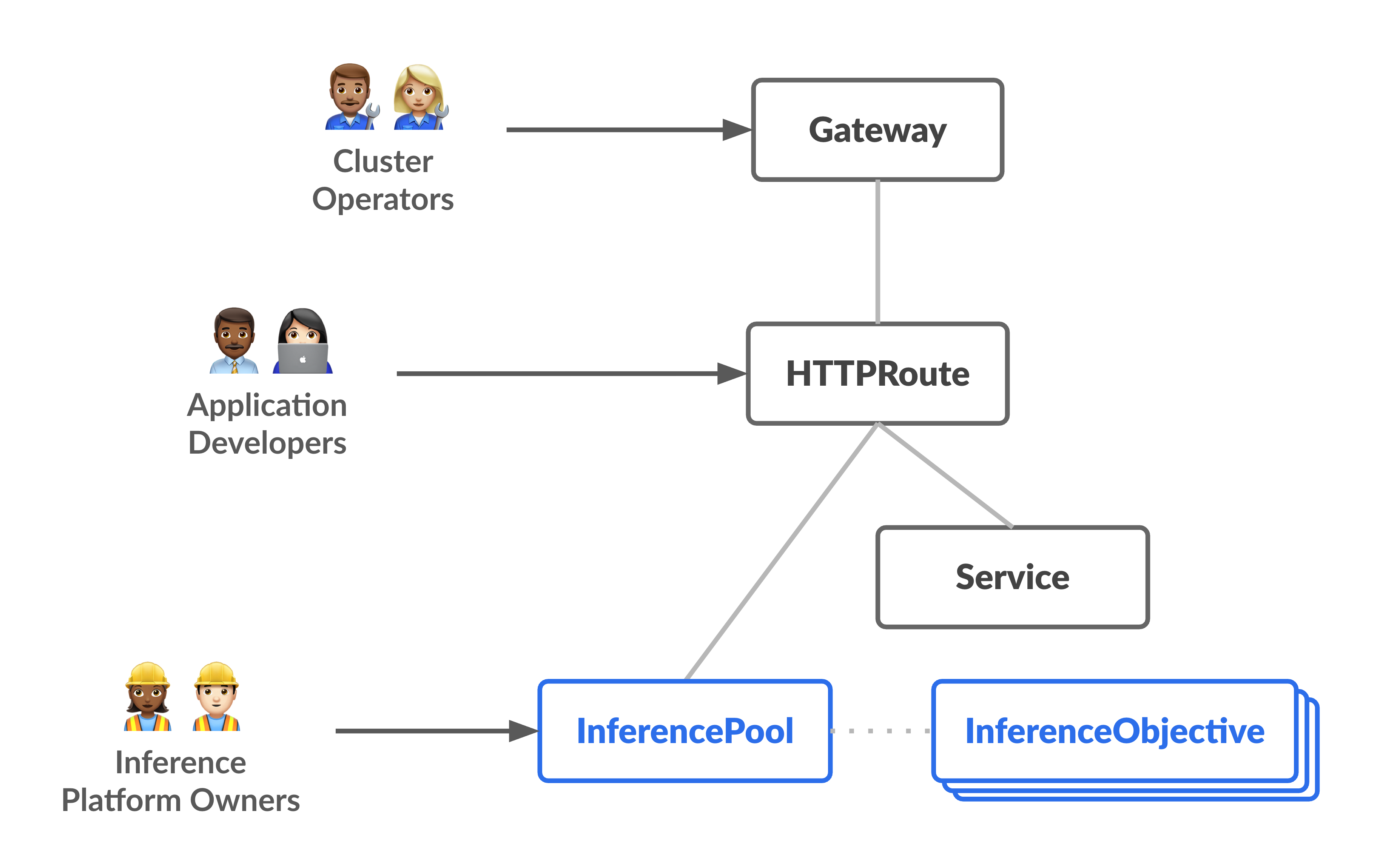
InferencePool对象:表示一组共享相同计算配置、加速器类型、基本语言模型和模型服务器的 Pod(容器)。这样可以对 AI 模型部署资源进行逻辑分组和管理。单个InferencePool对象可以跨多个 Pod(位于不同的 GKE 节点上),并提供可伸缩性和高可用性。InferenceObjective对象:根据OpenAI API规范,通过InferencePool指定部署模型的名称。InferenceObjective对象还指定了模型的部署属性,例如 AI 模型的Priority。GKE 推理网关会优先处理优先级值较高的工作负载。这使您可以在 GKE 集群上多路复用对延迟时间要求严格和能够容忍延迟时间的 AI 工作负载。您还可以配置InferenceObjective对象以部署 LoRA 微调模型。
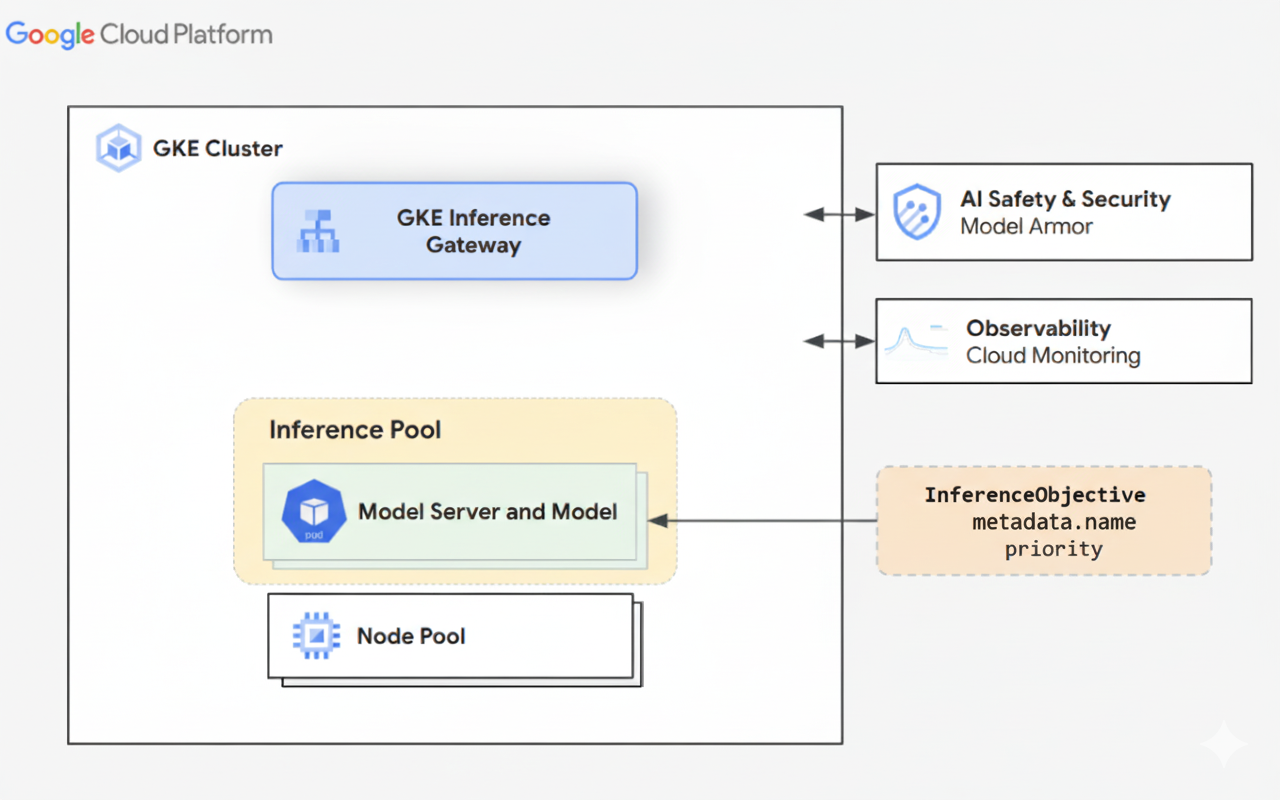
下图展示了 GKE 集群中的 GKE 推理网关及其与 AI 安全、可观测性和模型部署的集成。
下图展示了资源模型,该模型侧重于说明两个新的专注于推理的角色及其管理的资源。
GKE 推理网关的运作方式
GKE 推理网关使用 Gateway API 扩展程序和特定于模型的路由逻辑来处理客户端对 AI 模型的请求。以下步骤介绍了请求流程。
请求流程的运作方式
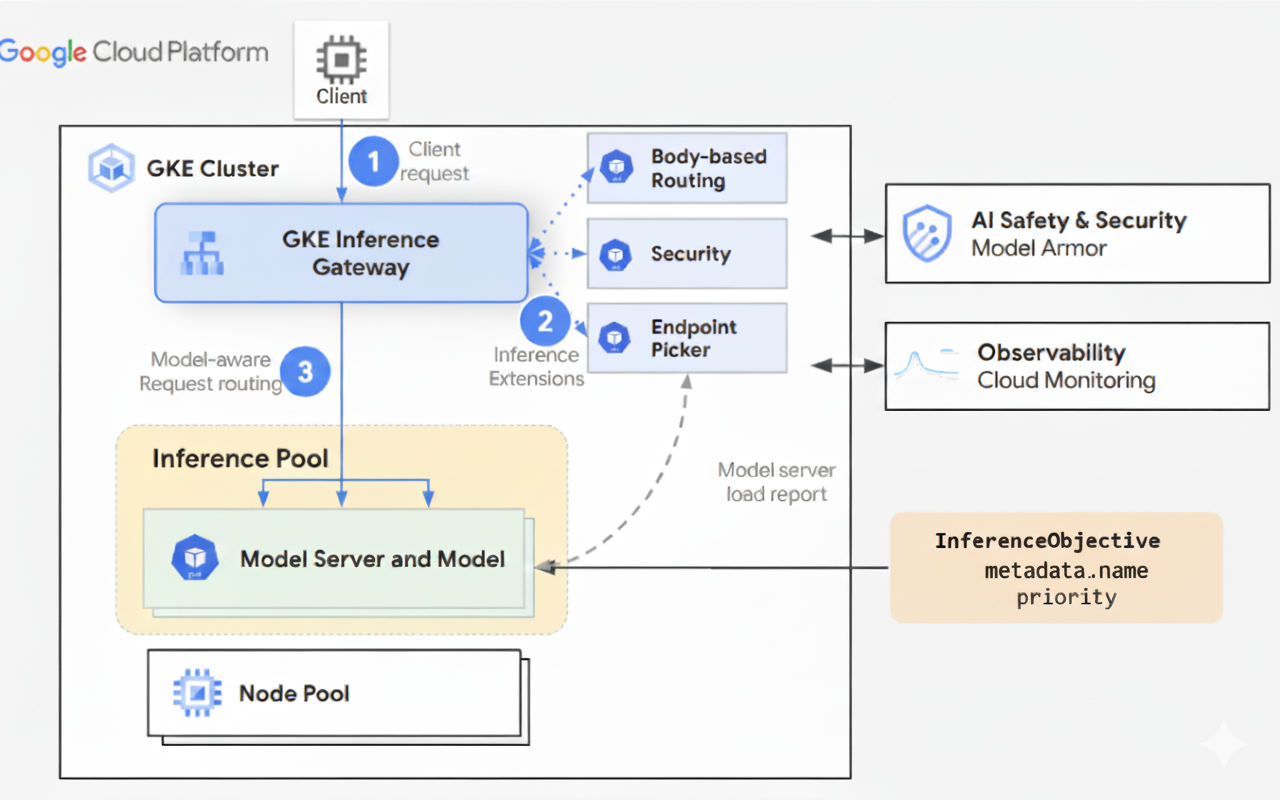
GKE 推理网关将客户端请求从初始请求路由到模型实例。本部分介绍了 GKE 推理网关如何处理请求。此请求流程适用于所有客户端。
- 客户端将请求(采用 OpenAI API 规范中描述的格式)发送到在 GKE 中运行的模型。
- GKE 推理网关使用以下推理扩展程序处理请求:
- 基于正文的路由扩展程序:从客户端请求正文中提取模型标识符,并将其发送到 GKE 推理网关。GKE 推理网关随后会根据 Gateway API
HTTPRoute对象中定义的规则,使用此标识符来路由请求。请求正文路由与基于网址路径的路由类似。不同之处在于请求正文路由使用请求正文中的数据。 - 安全扩展程序:使用 Model Armor、NVIDIA NeMo Guardrails 或受支持的第三方解决方案来强制执行特定于模型的安全政策,包括内容过滤、威胁检测、清理和日志记录。安全扩展程序会将这些政策应用于请求和响应处理路径。
- 端点选择器扩展程序:在
InferencePool中监控来自模型服务器的关键指标。它会跟踪每个模型服务器上的键值对缓存 (KV-cache) 利用率、待处理请求的队列长度、前缀缓存索引和活跃的 LoRA 适配器。然后,它会根据这些指标将请求路由到最佳模型副本,以便针对 AI 推理最大限度地减少延迟时间并最大限度地提高吞吐量。
- 基于正文的路由扩展程序:从客户端请求正文中提取模型标识符,并将其发送到 GKE 推理网关。GKE 推理网关随后会根据 Gateway API
- GKE 推理网关会将请求路由到端点选择器扩展程序返回的模型副本。
下图展示了通过 GKE 推理网关从客户端到模型实例的请求流程。
流量分配的运作方式
GKE 推理网关会将推理请求动态分配给 InferencePool 对象中的模型服务器。这有助于优化资源利用率,并在不同的负载条件下保持性能。GKE 推理网关使用以下两种机制来管理流量分配:
端点选择:动态选择最合适的模型服务器来处理推理请求。它会监控服务器负载和可用性,然后通过计算每个服务器的
score(结合了多种优化启发法)做出最佳路由决策:- 前缀缓存感知路由:GKE 推理网关会跟踪每个模型服务器上的可用前缀缓存索引,并为具有较长前缀缓存匹配的服务器提供更高的分数。
- 负载感知型路由:GKE 推理网关会监控服务器负载(KV 缓存利用率和待处理队列深度),并为负载较低的服务器提供更高的分数。
- LoRA 感知型路由:启用动态 LoRA 部署后,GKE 推理网关会监控每个服务器上的活跃 LoRA 适配器,并为具有所请求的活跃 LoRA 适配器或有额外空间来动态加载所请求的 LoRA 适配器的服务器提供更高的分数。选择总得分最高的服务器。
排队和卸除:管理请求流程并防止流量过载。GKE 推理网关会将传入的请求存储在队列中,并根据定义的优先级确定请求优先级。
GKE 推理网关使用数值 Priority 系统(也称为 Criticality)来管理请求流并防止过载。此 Priority 是用户为每个 InferenceObjective 定义的可选整数字段。值越高,表示请求越重要。当系统面临压力时,Priority小于 0 的请求会被视为优先级较低,并首先被舍弃,同时返回 429 错误,以保护更关键的工作负载。Priority 的默认值为 0。只有当请求的 Priority 明确设置为小于 0 的值时,请求才会因优先级而被舍弃。借助此系统,您可以优先处理对延迟时间敏感的在线推理流量,而非对时间不太敏感的批量作业。
对于需要持续更新或近乎实时的更新的应用(例如聊天机器人和实时翻译),GKE 推理网关支持流式推理。流式推理以增量块或分段的形式提供回答,而不是以单个完整输出的形式提供。如果在流式响应期间发生错误,则流会终止,并且客户端会收到错误消息。GKE 推理网关不会重试流式回答。
探索应用示例
本部分提供了一些示例,展示了如何使用 GKE 推理网关来应对各种生成式 AI 应用场景。
示例 1:在 GKE 集群上部署多个生成式 AI 模型
一家公司希望部署多个大型语言模型 (LLM) 来处理不同的工作负载。例如,他们可能希望部署 Gemma3 模型以用于聊天机器人界面,并部署 Deepseek 模型以用于推荐应用。该公司需要确保为这些 LLM 实现最佳部署性能。
借助 GKE 推理网关,您可以采用 InferencePool 在 GKE 集群中部署这些 LLM,并使用所选的加速器配置。您随后可以根据模型名称(例如 chatbot 和 recommender)以及 Priority 属性来路由请求。
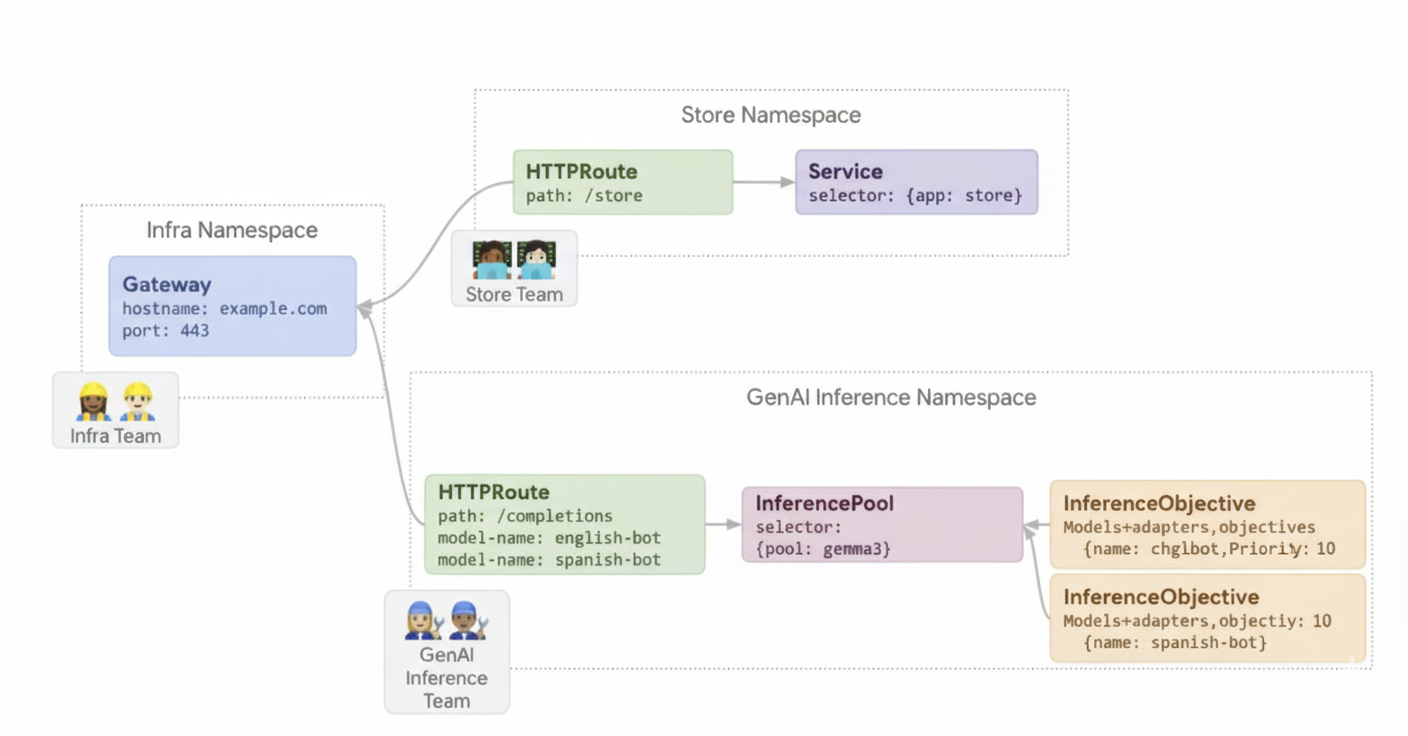
下图展示了 GKE 推理网关如何根据模型名称和 Priority 将请求路由到不同的模型。

此图展示了 GKE 推理网关如何处理对 example.com/completions 上生成式 AI 服务的请求。请求首先到达 Infra 命名空间中的 Gateway。此 Gateway 会将请求转发到 GenAI Inference 命名空间中的 HTTPRoute,该命名空间已配置为处理聊天机器人模型和情感分析模型的请求。对于聊天机器人模型,HTTPRoute 会拆分流量:90% 的流量会定向到运行当前模型版本(由 {pool: gemma} 选择)的 InferencePool,而 10% 的流量会定向到具有较新版本 ({pool: gemma-new}) 的池,通常用于 Canary 版测试。这两个池都与一个 InferenceObjective 相关联,该 InferenceObjective 会为聊天机器人模型的请求分配 10 的 Priority,确保这些请求被视为高优先级。
示例 2:在共享加速器上部署 LoRA 适配器
一家公司希望部署 LLM 来进行文档分析,并专注于多种语言(例如英语和西班牙语)的受众群体。他们针对每种语言对模型进行了微调,但需要高效地使用 GPU 和 TPU 容量。您可以使用 GKE 推理网关在通用基本模型(例如 llm-base)和加速器上为每种语言部署动态 LoRA 微调适配器(例如 english-bot 和 spanish-bot)。这样,您便可以通过在通用加速器上密集封装多个模型来减少所需的加速器数量。
下图展示了 GKE 推理网关如何在共享加速器上部署多个 LoRA 适配器。