
In diesem Dokument wird beschrieben, wie Sie TPU-Messwerte im Ray-Dashboard mit KubeRay in Google Kubernetes Engine (GKE) ansehen. In einem GKE-Cluster mit dem Ray GKE-Add-on sind TPU-Messwerte in Cloud Monitoring verfügbar.
Hinweise
Führen Sie die folgenden Aufgaben aus, bevor Sie beginnen:
- Aktivieren Sie die Google Kubernetes Engine API. Google Kubernetes Engine API aktivieren
- Wenn Sie die Google Cloud CLI für diesen Task verwenden möchten, müssen Sie die gcloud CLI installieren und dann initialisieren. Wenn Sie die gcloud CLI bereits installiert haben, rufen Sie die neueste Version mit dem Befehl
gcloud components updateab. In früheren gcloud CLI-Versionen werden die Befehle in diesem Dokument möglicherweise nicht unterstützt.
Sie haben einen GKE-Cluster, der die folgenden Bedingungen erfüllt:
- Ein Knotenpool, der für die Verwendung von TPUs konfiguriert ist.
- Das Ray on GKE-Add-on darf für diesen Cluster nicht aktiviert sein.
- Eine Bereitstellungs- oder Trainingsarbeitslast in GKE mit Ray und TPUs.
Wenn Sie einen Cluster mit diesen Bedingungen erstellen müssen, wählen Sie eine Beispiel-TPU-Arbeitslast wie LLM mithilfe von JAX, Ray Train und TPU Trillium in GKE trainieren oder LLM mithilfe von TPUs in GKE mit KubeRay bereitstellen aus und folgen Sie der Anleitung zum Einrichten eines Clusters.
Umgebung vorbereiten
In dieser Anleitung verwenden Sie Cloud Shell, eine Shell-Umgebung für die Verwaltung von Ressourcen, die inGoogle Cloudgehostet werden.
Die Google Cloud CLI und das kubectl-Befehlszeilentool sind in Cloud Shell vorinstalliert. Die gcloud CLI ist die primäre Befehlszeile für Google Cloudund kubectl ist die primäre Befehlszeile zum Ausführen von Befehlen für Kubernetes-Cluster.
Cloud Shell aufrufen
Zur Google Cloud Console.
Klicken Sie in der oberen rechten Ecke der Console auf die Schaltfläche Cloud Shell aktivieren:

In einem Frame im unteren Teil der Console wird eine Cloud Shell-Sitzung geöffnet.
In dieser Shell führen Sie gcloud- und kubectl-Befehle aus.
Bevor Sie Befehle ausführen, legen Sie Ihr Standardprojekt in der Google Cloud CLI mit dem folgenden Befehl fest:
gcloud config set project PROJECT_ID
Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID.
TPU-Messwerte im Ray-Dashboard ansehen
So rufen Sie TPU-Messwerte im Ray-Dashboard auf:
Aktivieren Sie in Ihrer Shell Messwerte im Ray-Dashboard, indem Sie den Kubernetes Prometheus-Stack installieren.
./install/prometheus/install.sh --auto-load-dashboard true kubectl get all -n prometheus-systemDie Ausgabe sieht etwa so aus:
NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/prometheus-grafana 1/1 1 1 46s deployment.apps/prometheus-kube-prometheus-operator 1/1 1 1 46s deployment.apps/prometheus-kube-state-metrics 1/1 1 1 46sBei dieser Installation wird ein Helm-Chart verwendet, um Ihrem Cluster die benutzerdefinierten Ressourcendefinitionen (Custom Resource Definitions, CRDs), einen Pod-Monitor und einen Dienstmonitor für Ray-Pods hinzuzufügen.
Installieren Sie den KubeRay-Operator v1.5.0 oder höher mit aktiviertem Messwert-Scraping. Wenn Sie TPU-Messwerte in Grafana mit den in KubeRay bereitgestellten Standard-Dashboards ansehen möchten, müssen Sie KubeRay v1.5.0 oder höher installieren.
helm repo add kuberay https://ray-project.github.io/kuberay-helm/ helm install kuberay-operator kuberay/kuberay-operator --version 1.5.0-rc.0 \ --set metrics.serviceMonitor.enabled=true \ --set metrics.serviceMonitor.selector.release=prometheusInstallieren Sie den KubeRay-Webhook für TPUs. Mit diesem Webhook wird eine Umgebungsvariable
TPU_DEVICE_PLUGIN_HOST_IPfestgelegt, mit der Ray TPU-Messwerte aus demtpu-device-plugin-DaemonSet abruft.helm install kuberay-tpu-webhook \ oci://us-docker.pkg.dev/ai-on-gke/kuberay-tpu-webhook-helm/kuberay-tpu-webhook \ --set tpuWebhook.image.tag=v1.2.6-gke.0Um Ihre Arbeitslast für die Protokollierung der Messwerte vorzubereiten, legen Sie die folgenden Ports und Umgebungsvariablen in der RayCluster-Spezifikation fest:
headGroupSpec: ... ports: ... - containerPort: 44217 name: as-metrics - containerPort: 44227 name: dash-metrics env: - name: RAY_GRAFANA_IFRAME_HOST value: http://127.0.0.1:3000 - name: RAY_GRAFANA_HOST value: http://prometheus-grafana.prometheus-system.svc:80 - name: RAY_PROMETHEUS_HOST value: http://prometheus-kube-prometheus-prometheus.prometheus-system.svc:9090Arbeitslast mit TPUs mit Ray ausführen Sie können eine Beispiel-TPU-Arbeitslast wie LLM mit JAX, Ray Train und TPU Trillium in GKE trainieren oder LLM mithilfe von TPUs in GKE mit KubeRay bereitstellen verwenden.
Messwerte im Ray-Dashboard oder in Grafana ansehen
Um eine Verbindung zum RayCluster herzustellen, leiten Sie den Ray-Head-Dienst per Portweiterleitung weiter:
kubectl port-forward service/RAY_CLUSTER_NAME-head-svc 8265:8265Ersetzen Sie
RAY_CLUSTER_NAMEdurch den Namen Ihres RayClusters. Wenn Ihre Arbeitslast aus der Anleitung LLM mit JAX, Ray Train und TPU Trillium in GKE trainieren stammt, ist dieser Wertmaxtext-tpu-cluster.Rufen Sie
http://localhost:8265/auf Ihrem lokalen Computer auf, um das Ray-Dashboard aufzurufen.Leiten Sie den Port für die Grafana-Web-UI weiter. Sie müssen Grafana portweiterleiten, um TPU-Messwerte aufzurufen, die in Grafana-Dashboards angezeigt werden, die in das Ray-Dashboard eingebettet sind.
kubectl port-forward -n prometheus-system service/prometheus-grafana 3000:http-webÖffnen Sie im Ray-Dashboard den Tab Messwerte und suchen Sie nach dem Tab TPU-Auslastung nach Knoten. Wenn TPUs ausgeführt werden, werden knotenbezogene Messwerte für die Tensor-Core-Auslastung, die HBM-Auslastung, den TPU-Duty-Cycle und die Arbeitsspeichernutzung an das Dashboard gestreamt. Diese Messwerte können in Grafana auf dem Tab „Ansicht“ aufgerufen werden.
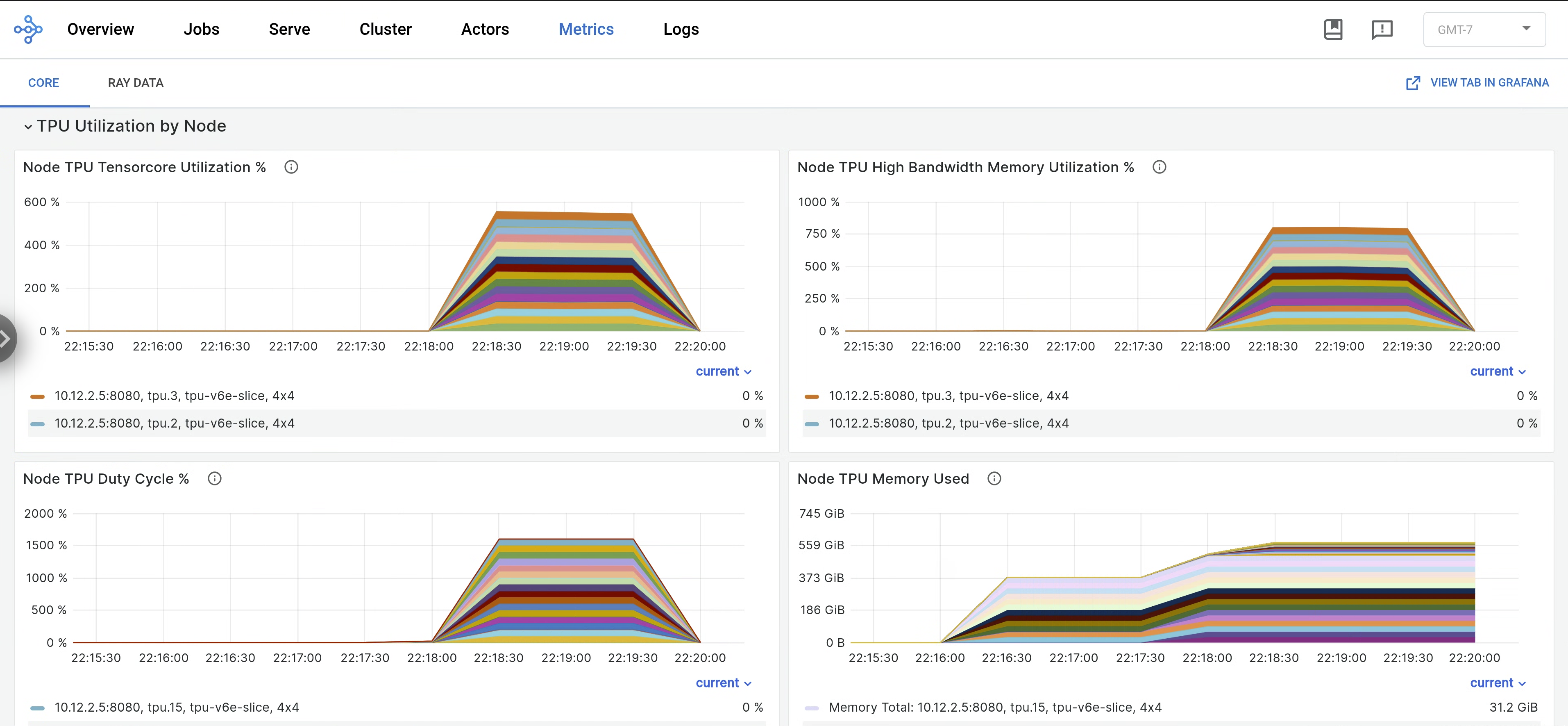
Wenn Sie
libtpu-Logs aufrufen möchten, rufen Sie im Ray-Dashboard den Tab Logs auf und wählen Sie den TPU-Knoten aus. Libtpu-Logs werden in das Verzeichnis/tpu_logsgeschrieben.
Weitere Informationen zum Konfigurieren der TPU-Protokollierung finden Sie unter TPU-VM-Logs debuggen.
Nächste Schritte
- Informationen zum Erfassen und Ansehen von Logs und Messwerten für Ray-Cluster in Google Kubernetes Engine (GKE)
- Ray Operator-Logs ansehen