カスタム コネクタを使用すると、Gemini Enterprise の標準コネクタ ライブラリに含まれない外部データソースを統合できます。これにより、Gemini と Google の高度な検索インテリジェンスを活用して、組織に固有のデータを自然言語で検索してアクセスできるようになります。カスタム コネクタは Discovery Engine API と直接やり取りし、堅牢なデータ ストレージ、インデックス登録、インテリジェント検索機能を有効にします。コネクタは、ソース情報を標準化された JSON ベースのドキュメント形式(コンテンツ、メタデータ、アクセス制御リスト(ACL)の構造化)に変換し、このデータがデータストアに整理されるようにします。これらのストアは論理リポジトリとして機能し、理想的には単一のドキュメント形式を表します。それぞれに専用の検索インデックスと構成があります。
カスタム コネクタの仕組み
カスタム コネクタは、自動化されたデータ パイプラインを使用して、取得、変換、同期の 3 つの主要なアクションを実行します。このプロセスにより、外部データが正しく準備され、Gemini Enterprise にアップロードされます。
取得: コネクタは、API、データベース、またはファイル形式を使用して、ドキュメント、メタデータ、権限などのデータを外部システムから pull します。
変換: コネクタは、元データを Discovery Engine のドキュメント形式に変換し、コンテンツとメタデータを構造化して、各ドキュメントにグローバルに一意の ID を割り当てます。アクセス制御には、Google が認識する ID を直接使用するか、外部ユーザーまたはカスタム グループの ID マッピングを使用できます。
同期: コネクタはドキュメントを Gemini Enterprise データストアにアップロードし、スケジュールされたジョブを通じてドキュメントを最新の状態に保ちます。データの同期は、エンティティ用に作成されたデータストアを使用して実行されます。データストアの作成の詳細については、データストアの作成プロセスをご覧ください。ニーズに応じて同期モードを選択します。増分ではデータの追加と更新が行われ、完全ではデータセット全体が置き換えられます。
ACL と ID マッピング
ドキュメント レベルのアクセスを管理するには、データの ID 形式に応じて、Pure ACL または ID マッピングの 2 つの方法から選択します。
純粋な ACL (AclInfo): このメソッドは、データソースが(Google Cloud)で認識されるメールベースの ID を使用する場合に使用されます。この方法は、アクセス権を付与されているユーザーを直接定義する場合に最適です。
ID マッピング: この方法は、データソースがユーザー名、以前の ID、その他の外部 ID システムを使用している場合に使用されます。これにより、外部 ID グループ(例: EXT1)と内部 ID プロバイダ(IDP)のユーザーまたはグループ(例: IDPUser1@example.com)との間に明確かつ 1 対 1 の関連性が確立されます。これにより、システムはソースシステムからグループベースのアクセス制御を理解して適用できます。これは、API が完全なユーザー メンバーシップなしでグループラベルを返す場合や、ドキュメントごとに数千人のユーザーをリストすることなく ACL を効率的にスケーリングする場合に有効です。このプロセスでは、すべてのネストされた ID 構造または階層型 ID 構造を、通常は指定された JSON 形式で、直接マッピングのフラットリストに解決する必要があります。一意の外部 ID グループ ID(例: EXT1)を使用して、システム整合性を維持します。詳細と例については、ID マッピングをご覧ください。
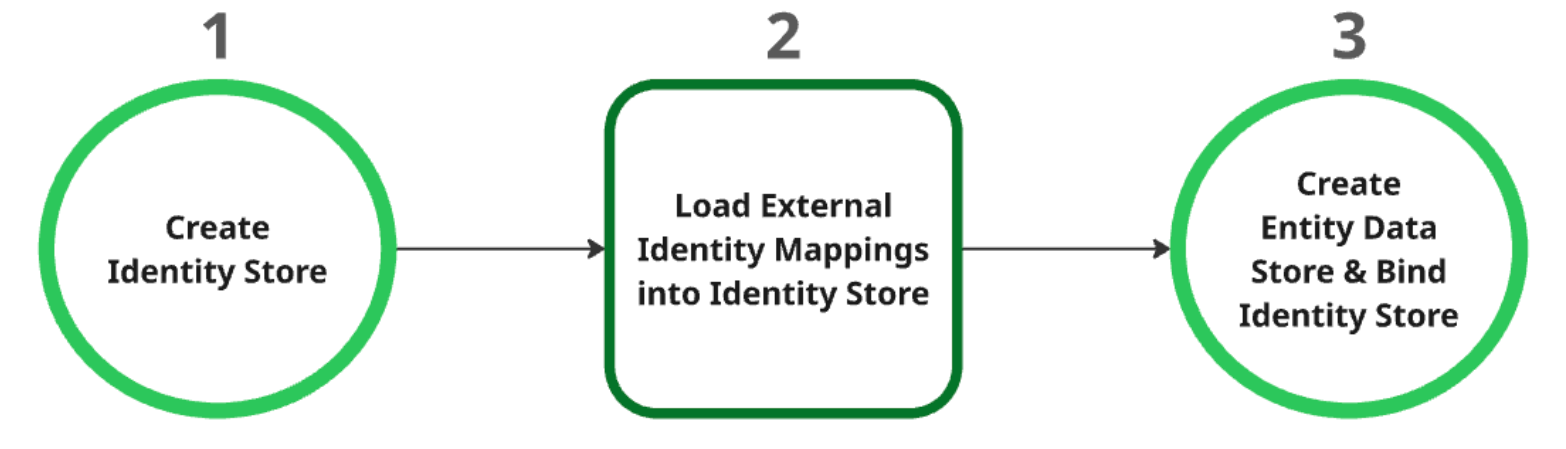
データストアの作成プロセス
ID ストアを作成する: このストアは、すべての ID マッピングの親リソースとして機能します。作成時に、プロジェクト レベルの ID プロバイダ(IDP)設定が自動的に取得されます。詳細については、ID ストアを取得または作成するをご覧ください。
外部 ID マッピングを ID ストアに読み込む: ID ストアを作成したら、外部 ID データを読み込みます。詳細については、ID マッピングを ID ストアに取り込むをご覧ください。
エンティティ データストアを作成してバインドする: エンティティ データストアは、ID ストアが正常に作成され、ID マッピングが読み込まれた後にのみ作成できます。ID ストアは、作成時にエンティティ データストアにバインドする必要があります。エンティティ データストアの作成の詳細については、データストアを作成するをご覧ください。
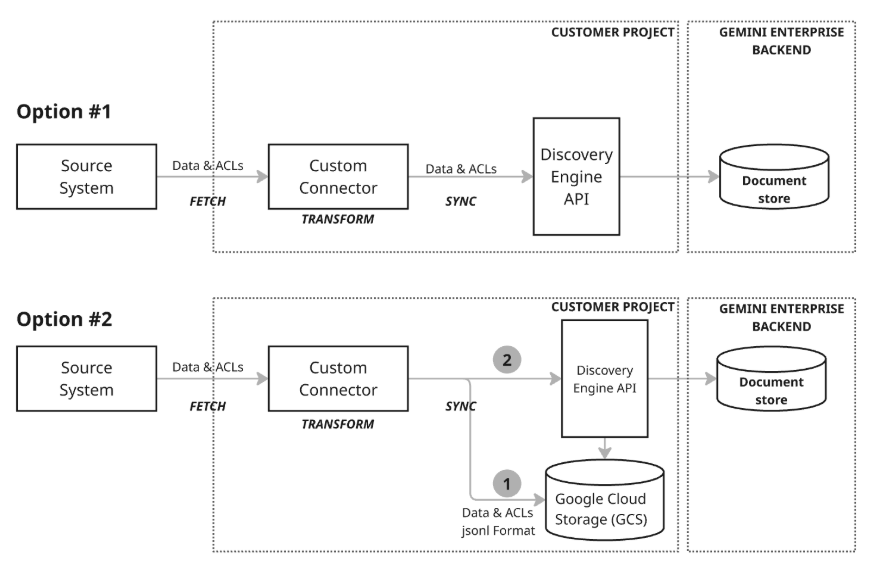
データの同期
データを同期するためのアーキテクチャ モデルは 2 つあります。
アーキテクチャ モデル 1: 増分 upsert: 増分 upsert アプローチは、データがストリーミングされ、リアルタイムの更新が必要なシナリオに最適です。このコネクタは、Discovery Engine API を活用して、適切な関数を呼び出すことで、効率的な増分 upsert(データの挿入または更新)を実行します。変更サイズと遅延を最小限に抑えることに重点を置くことで、データが急速に変化する場合でも、ドキュメント ストアの最新性を維持できます。
アーキテクチャ モデル 2: Google Cloud Storage との包括的な同期: この推奨アプローチでは、包括的なデータ管理機能と高い柔軟性が実現されます。完全同期(データセット全体でのデータの挿入、更新、削除が可能)と増分同期(変更を送信することで挿入と更新のみを処理)をサポートしています。これにより、このアプローチは幅広いデータニーズに対応でき、特に大規模で複雑なデータ オペレーションの管理に有効です。このモデルでは、コネクタが最初に Google Cloud Storage(GCS)にデータを書き込み、次に Discovery Engine API を利用して、ステージングされた GCS の場所から必要なインポート関数を呼び出してドキュメント ストアを更新するステージング プロセス(図のステップ 1)を利用します。
カスタム コネクタは、ハイブリッド アーキテクチャをサポートするのに十分な柔軟性を備えているため、頻繁に変更されるデータに対して増分 upsert を実装し、スケジュールされた完全なデータ更新または削除に対して包括的な同期を実装できます。