
Este documento descreve como criar e otimizar os conjuntos de contexto que ajudam a alcançar alta precisão de consulta QueryData nos aplicativos de agente de dados. O agente de engenharia de contexto ajuda a criar, avaliar e melhorar conjuntos de contexto automatizando a criação e a otimização deles.
Para saber mais sobre conjuntos de contexto e QueryData, consulte Visão geral dos conjuntos de contexto e Visão geral do QueryData.Para criar aplicativos de dados de nível empresarial, a precisão do modelo de texto para SQL geralmente precisa atingir uma qualidade próxima de 100%. Resultados de consulta incorretos afetam a usabilidade geral do aplicativo e a experiência do usuário. Para conseguir respostas explicáveis e relevantes para os negócios com alta precisão, é necessário fazer a engenharia de contexto, que é o processo de criar e otimizar iterativamente o contexto para alcançar a precisão ideal.
Ao fornecer ao QueryData o contexto direcionado ao aplicativo de negócios, você fornece as regras de negócios precisas de que o sistema precisa para resolver a intenção do usuário.
Agente de engenharia de contexto
O agente de engenharia de contexto automatiza esse fluxo de trabalho de otimização. Você pode conversar com o agente para lidar com tarefas ad hoc para otimizar o contexto. A lista a seguir fornece exemplos de comandos de linguagem natural que podem ser usados para instruir o agente, além de uma descrição de como o agente responde. Use esses exemplos para ajudar a criar e otimizar o contexto:
- Exemplo de comando para análise de falhas: "Atualize o contexto para que identifiquemos corretamente o aeroporto para consultas como 'voos da Disney World'." O agente analisa a falha, explica a lacuna e recomenda a adição de um item de contexto adequado, como uma consulta de pesquisa de valor.
- Exemplo de comando para sugestão de contexto: "Leia o código do meu app e sugira algum contexto a ser adicionado." O agente analisa o código, explica o domínio do aplicativo e sugere quais itens de contexto seriam relevantes.
- Exemplo de comando para processamento em lote: "Aqui estão 10 exemplos de perguntas e consultas SQL. Transforme-os em modelos." O agente processa suas entradas em lote e atualiza o conjunto de contexto.
Importância do conjunto de dados de referência
Para otimizar o contexto, primeiro crie um conjunto de dados que corresponda às entradas de linguagem natural do aplicativo. O agente pode ajudar a criar esse conjunto de dados de referência, que consiste em perguntas do usuário e as consultas de banco de dados esperadas. Um conjunto de dados de referência permite:
- Estabelecer uma linha de base para o desempenho da consulta.
- Validar atualizações em relação a consultas de banco de dados de informações empíricas.
- Medir melhorias de precisão em todas as iterações.
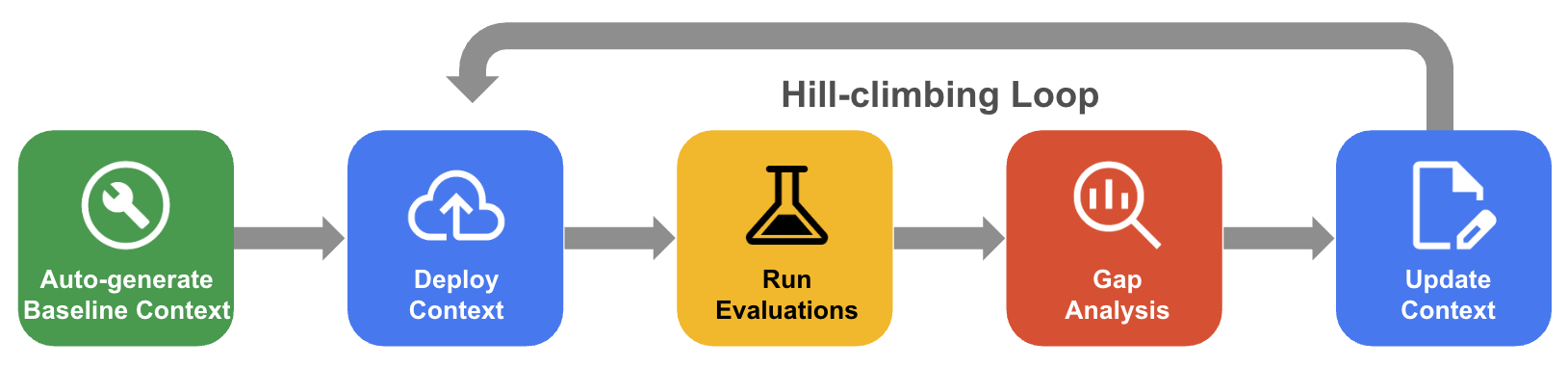
O processo sistemático de escalada
Na escalada sistemática, o agente melhora iterativamente um conjunto de contexto por meio da avaliação do conjunto de dados de referência, da análise de lacunas e das atualizações para aumentar a precisão para quase 100%.
- Gerar contexto de referência automaticamente: crie um conjunto de contexto inicial derivado do esquema de banco de dados e dos artefatos do aplicativo.
- Fluxo de trabalho de otimização de escalada: permita que o agente avalie a acurácia do QueryData, faça uma análise de lacunas nas falhas e proponha melhorias automaticamente para aumentar a acurácia.
O diagrama a seguir mostra o fluxo de trabalho sistemático de escalada:
Antes de começar
Conclua os pré-requisitos a seguir antes de usar o agente de engenharia de contexto.
Ativar serviços obrigatórios
Ative os seguintes serviços para seu projeto:Preparar uma instância do Cloud SQL
Verifique se você tem acesso a uma instância do Cloud SQL ou crie uma. Para mais informações, consulte Criar instâncias para o Cloud SQL.Este tutorial exige que você tenha um banco de dados na instância do Cloud SQL. Para mais informações, consulte Criar um banco de dados na instância do Cloud SQL
Papéis e permissões necessárias
- Adicione um usuário do IAM ou uma conta de serviço à instância. Para mais informações, consulte Gerenciar usuários com a autenticação de banco de dados do IAM para o Cloud SQL.
- Conceda os papéis
cloudsql.studioUser,cloudsql.instanceUseregeminidataanalytics.queryDataUserao usuário do IAM no nível do projeto. Para mais informações, consulte Adicionar uma vinculação de política do IAM a um projeto. - Você também precisa conceder privilégios de banco de dados somente leitura a um usuário do IAM ou a uma conta de serviço fazendo login como um usuário com privilégios de superusuário, como o usuário
postgres.GRANT SELECT ON ALL TABLES IN SCHEMA public TO USER_NAME;
Substitua USER_NAME pelo endereço de e-mail do usuário. É necessário usar aspas em torno do e-mail porque ele contém caracteres especiais (@ e .).
Para mais informações, consulte Conceder privilégios de banco de dados a um usuário individual do IAM ou a uma conta de serviço.
Conceder permissão executesql à instância do Cloud SQL
Para conceder a permissão executesql à instância do Cloud SQL e ativar a API Cloud SQL Data, execute o seguinte comando:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID: o ID doprojeto. Google CloudINSTANCE_ID: o ID da instância do Cloud SQL.
Preparar o ambiente
É possível criar arquivos de conjunto de contexto em qualquer ambiente de desenvolvimento local ou IDE. Para preparar o ambiente, conclua as seguintes etapas:
- Instalar o agente de engenharia de contexto
- Configurar a conexão de banco de dados
Instalar o agente de engenharia de contexto
O agente de engenharia de contexto executa o servidor do Protocolo de Contexto de Modelo (MCP, na sigla em inglês) que exige que o uv gerencie pacotes Python subjacentes.
Instale
uvseguindo as instruções em Instalaruv.Verifique se o
uvestá instalado e acessível na linha de comando:uv --version
Para preparar o ambiente, instale o agente de engenharia de contexto no harness de agente selecionado, como a CLI do Antigravity, o Claude Code ou a CLI do Gemini.
Dependendo do harness de agente selecionado, siga as etapas de instalação correspondentes:
CLI do Antigravity
Para instalar o agente de engenharia de contexto na CLI do Antigravity, siga estas etapas:
- Instale a CLI do Antigravity. Consulte Introdução à CLI do Antigravity.
- Instale o plug-in do agente de engenharia de contexto, que inclui fluxos de trabalho para geração de contexto. Substitua VERSION pela versão lançada necessária:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Inicie a CLI do Antigravity:
agy
- Opcional. Atualize o plug-in:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Para instalar o agente de engenharia de contexto no Claude Code, siga estas etapas:
- Adicione o marketplace de plug-ins:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Instalar o plug-in:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Recarregue os plug-ins para ativar as mudanças:
/reload-plugins
- Opcional. Atualize o plug-in:
/plugin update db-context-engineering@db-context-enrichment-marketplace
CLI do Gemini (descontinuada)
Para instalar o agente de engenharia de contexto na CLI do Gemini, siga estas etapas:
- Instale a CLI do Gemini. Consulte Introdução à CLI do Gemini.
- Instalar a extensão:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- Opcional. Atualize a extensão:
gemini extensions update mcp-db-context-enrichment
Configurar a conexão de banco de dados
O agente exige uma conexão de banco de dados para buscar esquemas e a capacidade de validar a sintaxe do contexto SQL gerado. Para permitir que o agente interaja com seu banco de dados, configure as credenciais de autenticação e defina a configuração de conexão do banco de dados.
Configurar as credenciais padrão do aplicativo
Configure Application Default Credentials (ADC) para fornecer credenciais de usuário para acessar Google Cloud recursos do agente de engenharia de contexto:
- Servidor MCP da caixa de ferramentas: usa credenciais para se conectar ao banco de dados, buscar esquemas e executar SQL para validação.
- Evalbench: usa credenciais para invocar o QueryData para avaliação.
Execute os comandos a seguir no terminal para autenticar:
gcloud auth application-default loginConfigurar o arquivo de conexão do banco de dados
O agente exige uma conexão de banco de dados para geração de contexto, que a caixa de ferramentas do MCP oferece suporte e define em um arquivo de configuração.
O arquivo de configuração especifica a origem do banco de dados e as ferramentas necessárias para buscar esquemas ou executar SQL. O agente de engenharia de contexto vem com habilidades de agente pré-instaladas para ajudar a gerar a configuração.
Inicie o ambiente do agente.
Peça ajuda ao agente para configurar a conexão de banco de dados. Por exemplo, digite "ajude a configurar a conexão de banco de dados". Siga as instruções do agente para criar o arquivo de configuração no diretório de trabalho atual como
autoctx/tools.yaml.Para aplicar a nova configuração
tools.yaml, recarregue a conexão:- Na CLI do Antigravity, execute
/mcpe selecionetoolboxpara reiniciar. - Na CLI do Gemini, execute
/mcp reload. - No Claude Code, execute
/mcp, selecionetoolboxeReconnect.
- Na CLI do Antigravity, execute
Para mais informações sobre como configurar manualmente o arquivo de configuração do banco de dados, consulte Configuração da caixa de ferramentas do MCP.
Gerar e otimizar o contexto
O agente de engenharia de contexto fornece um conjunto de habilidades de agente e ferramentas MCP para melhorar a capacidade de engenharia de contexto do agente de codificação. É possível usar essas ferramentas juntas para gerar uma linha de base, medir a eficácia e aplicar melhorias de forma iterativa. No entanto, você pode começar em qualquer estágio do fluxo de trabalho:
- Se você já tiver um conjunto de contexto, poderá prosseguir diretamente para a avaliação.
- Se você tiver consultas com falha que quer corrigir, poderá prosseguir diretamente para a análise de lacunas.
Cada capacidade descreve as ações, os casos de uso e os comandos de invocação do agente.
Os comandos de exemplo mostram como consultar o agente em linguagem natural. Se o agente precisar de mais detalhes para concluir uma solicitação, ele vai pedir esclarecimentos.
Criar e expandir conjuntos de dados de avaliação
Para melhorar o desempenho, primeiro é necessário medi-lo. A engenharia de contexto sem um conjunto de dados de referência, que consiste em perguntas do usuário pareadas com o SQL esperado, não tem verificação sistemática. Com um conjunto de dados de referência, cada mudança é uma melhoria mensurável que pode ser validada em relação à verdade fundamental.
A criação manual de um conjunto de dados de referência representativo é demorada, e conjuntos de dados pequenos podem perder variações na fraseologia do usuário. O agente resolve isso:
- Gerando pares de perguntas e SQL candidatos com base no esquema do banco de dados.
- Expandindo um pequeno conjunto de dados de semente usando variações de filtro, sinônimos e reformulações.
Opcionalmente, você pode permitir que o agente execute o SQL gerado no banco de dados. Essa verificação confirma que as consultas são executadas com sucesso antes de serem adicionadas ao conjunto de dados.
O conjunto de dados é um arquivo JSON que contém pares de perguntas e SQL:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Os pares aprovados preenchem o arquivo autoctx/golden.json no seu espaço de trabalho, onde estão prontos para avaliação. Você pode fornecer um arquivo atual ou escrever alguns exemplos de avaliação inline para o agente expandir.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Gere um conjunto de dados de avaliação do meu esquema."
- "Aqui está uma pergunta de semente e SQL. Expanda-o para um conjunto de dados mais amplo e verifique se as consultas são executadas."
Gerar um conjunto de contexto de referência
Para evitar a criação de contexto do zero, você pode permitir que o agente derive um conjunto de contexto inicial do esquema de banco de dados e dos artefatos do aplicativo, como regras de negócios, consultas de exemplo ou arquivos README. Embora esse contexto de referência não seja final, ele fornece um ponto de partida validado com base no modelo de banco de dados.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Gere um conjunto de contexto do meu esquema."
- "Gere o contexto inicial usando esses esquemas e as regras de negócios em
requirements.md."
O agente pede que você nomeie o experimento, que organiza os artefatos gerados, e pode pedir que você restrinja o escopo se o esquema do banco de dados for grande. Para fazer o upload do contexto usando o Cloud SQL Studio, siga as instruções depois que o agente gerar o arquivo JSON.
Avaliar a eficácia do contexto
Depois de estabelecer um conjunto de contexto e um conjunto de dados de referência, você pode permitir que o agente meça o desempenho do contexto consultando a API QueryData do agente de dados com cada pergunta de referência. O agente compara o SQL gerado e os resultados da execução com a resposta esperada usando Evalbench para lidar com a comparação.
A execução de uma avaliação fornece o seguinte:
- Métricas quantitativas, como resultados de aprovação e reprovação e pontuações agregadas, para acompanhar o progresso nas iterações de contexto.
- Um resumo da conversa inline e relatórios CSV detalhados gravados no diretório
eval_reports/na pasta do experimento.
Para iniciar uma avaliação, forneça o caminho do conjunto de dados de referência e o ID do conjunto de contexto. Para saber como encontrar o ID do conjunto de contexto, consulte Encontrar o ID do contexto do agente.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Avalie meu contexto em relação a
golden.json." - "Execute novamente a avaliação usando a configuração do meu último experimento."
Para executar novamente uma configuração de avaliação gerada anteriormente sem configurá-la novamente, pergunte ao agente ou invoque a CLI diretamente:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Para detalhes sobre o esquema de configuração de avaliação e como personalizar execuções de avaliação, consulte a documentação do Evalbench.
Realizar análise de lacunas e propor melhorias
Para resolver falhas de consulta, é necessário identificar as causas raiz, como colunas incorretas, junções de tabelas ausentes ou termos vagos não resolvidos. A identificação manual desses problemas exige uma análise extensa dos relatórios de avaliação.
O agente automatiza esse loop de análise e correção:
- Análise de lacunas: o agente lê os resultados da avaliação e o conjunto de contexto para agrupar falhas semelhantes e recomendar adições de contexto direcionadas, como modelos, facetas ou pesquisas de valor.
- Correções propostas: o agente propõe edições concretas e, opcionalmente, testa o SQL no banco de dados para verificar a resolução.
- Preservação da linha de base: o agente grava as melhorias em um novo arquivo JSON ao lado do contexto de referência, preservando os arquivos originais.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Execute a análise de lacunas na minha última avaliação e proponha correções."
- "Otimize esse conjunto de contexto em relação a
golden.json."
Para se preparar para a próxima iteração, faça o upload do contexto aprimorado para o conjunto de contexto de destino usando o Data Agents Studio. Siga as instruções.
Criar itens de contexto específicos sob demanda
Se você já conhece o contexto necessário, como um modelo para uma pergunta específica, uma faceta para um filtro repetido ou uma pesquisa de valor para uma coluna específica, a gravação manual do JSON de contexto pode introduzir erros de serialização em nomes de parâmetros, metadados de tipo ou sintaxe de fragmento. O agente processa a formatação JSON para que você possa se concentrar na intenção de negócios.
Também é possível usar esse recurso para atualizações ad hoc, como quando você precisa oferecer suporte a um novo padrão de consulta ou resolver um detalhe de esquema ausente. Para receber o JSON, descreva o contexto necessário para o agente sem executar uma avaliação ou configurar um experimento.
Essa também é a capacidade certa para usar quando você recebe uma tarefa única: um stakeholder fornece um novo par de perguntas e SQL que ele quer que seja compatível, ou você identifica uma faceta ausente durante uma revisão de código. Não é necessário configurar um experimento ou executar uma avaliação para corrigir o problema. Descreva o que você quer e o agente produz o JSON.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Crie um modelo para: 'Quais aeroportos estão na Califórnia?' com SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'." - "Crie uma faceta para o filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'rotulada como 'red eye'." - "Crie uma pesquisa de valor para
airports.iata."
Explicar qual seleção de tipo de contexto
Selecionar o tipo de contexto correto, independentemente de um modelo, faceta ou pesquisa de valor, ajuda a evitar o inchaço do contexto e as regressões de consulta de banco de dados. Por exemplo, usar um modelo em vez de uma faceta pode causar regras duplicadas, enquanto pesquisas de valor introduzidas quando um modelo é suficiente podem aumentar a latência da consulta. Para encontrar o formato de esquema correto, peça ao agente que recomende um tipo com base na estrutura da consulta ou nas colunas do banco de dados antes de criar itens de contexto. O agente explica o raciocínio para ajudar você a entender as opções de contexto.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Continuo escrevendo o filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'em muitas consultas. Qual é a melhor maneira de capturar isso?" - "Os usuários descrevem o status do voo em texto livre e eu quero combiná-los com
flights.status. Que tipo de pesquisa de valor devo configurar?" - "Qual é a diferença entre um modelo e uma faceta e quando devo usar cada um deles?"
Aplicar operações em lote em um conjunto de contexto
O agente oferece suporte a atualizações em lote para gerenciar conjuntos de contexto grandes de maneira consistente. Se você precisar atualizar vários itens de contexto simultaneamente, como quando uma coluna de banco de dados é renomeada, um valor de código muda de formato ou modelos referenciam uma tabela descontinuada, o agente pode aplicar a mudança a todos os itens afetados sem alterar entradas não relacionadas.
É possível usar os seguintes comandos de exemplo para instruir o agente:
- "Leia
golden.txte transforme todos os pares em modelos." - "Em
context_set.json, substituaairline = 'UA'porairline = 'United Airlines'para qualquer item que faça referência a 'United'. Deixe os itens não relacionados sozinhos."
A seguir
- Saiba mais sobre conjuntos de contexto.
- Saiba como criar ou excluir um conjunto de contexto no Cloud SQL Studio.
- Saiba como testar um conjunto de contexto.