
Dokumen ini menjelaskan cara membuat dan mengoptimalkan set konteks yang membantu mencapai akurasi kueri QueryData yang tinggi pada aplikasi agen data Anda. Agen rekayasa konteks membantu Anda membuat, mengevaluasi, dan meningkatkan kualitas set konteks dengan mengotomatiskan pembuatan dan pengoptimalannya.
Untuk mempelajari set konteks dan QueryData, lihat Ringkasan set konteks dan Ringkasan QueryData.Untuk membangun aplikasi data tingkat perusahaan, akurasi model text-to-SQL biasanya perlu mencapai kualitas yang hampir 100%. Hasil kueri yang salah memengaruhi kegunaan aplikasi secara keseluruhan dan pengalaman pengguna. Untuk mendapatkan jawaban yang dapat dijelaskan dan relevan dengan bisnis dengan akurasi tinggi, diperlukan rekayasa konteks, yaitu proses pembuatan dan pengoptimalan konteks secara berulang untuk mencapai akurasi yang optimal.
Dengan memberikan QueryData dengan konteks yang ditargetkan ke aplikasi bisnis Anda, Anda menyediakan aturan bisnis yang tepat yang dibutuhkan sistem untuk menyelesaikan niat pengguna yang rumit.
Agen rekayasa konteks
Agen rekayasa konteks mengotomatiskan alur kerja pengoptimalan ini. Anda dapat berbicara dengan agen untuk menangani tugas ad-hoc guna mengoptimalkan konteks Anda. Daftar berikut memberikan contoh perintah bahasa alami yang dapat Anda gunakan untuk memberi petunjuk kepada agen, beserta deskripsi tentang cara agen merespons. Gunakan contoh ini untuk membantu membangun dan mengoptimalkan konteks Anda:
- Contoh perintah untuk analisis kegagalan: "Perbarui konteks agar kita dapat mengidentifikasi bandara dengan benar untuk kueri seperti 'penerbangan disney world'." Agen menganalisis kegagalan, mempertimbangkan kesenjangan, dan merekomendasikan penambahan item konteks yang sesuai, seperti kueri penelusuran nilai.
- Contoh perintah untuk saran konteks: "Baca kode aplikasi saya dan sarankan beberapa konteks untuk ditambahkan." Agen akan mem-parsing kode, memberikan alasan tentang domain aplikasi Anda, dan menyarankan item konteks yang relevan.
- Contoh perintah untuk pemrosesan massal: "Berikut 10 contoh pertanyaan dan kueri SQL. Ubah menjadi template." Agen akan memproses input Anda secara massal dan memperbarui set konteks Anda.
Pentingnya set data emas
Untuk mengoptimalkan konteks, Anda harus membuat set data yang cocok dengan input bahasa alami aplikasi Anda terlebih dahulu. Agen dapat membantu Anda membuat set data emas ini, yang terdiri dari pertanyaan pengguna dan kueri database yang diharapkan. Dengan set data emas, Anda dapat:
- Tetapkan dasar pengukuran untuk performa kueri.
- Memvalidasi pembaruan terhadap kueri database kebenaran nyata.
- Ukur peningkatan akurasi di seluruh iterasi.
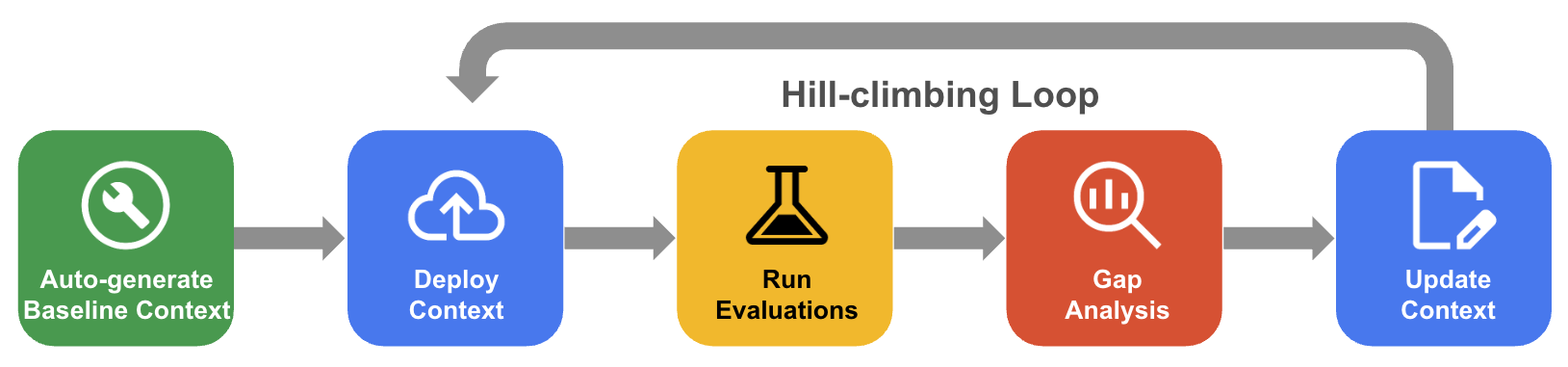
Proses pendakian bukit sistematis
Dalam pendakian bukit sistematis, agen secara iteratif meningkatkan set konteks melalui evaluasi set data emas, analisis kesenjangan, dan pembaruan untuk mendorong akurasi mendekati 100%.
- Buat konteks dasar pengukuran yang dibuat secara otomatis: Buat set konteks awal yang berasal dari skema database dan artefak aplikasi Anda.
- Alur kerja pengoptimalan pendakian bukit: Biarkan agen mengevaluasi akurasi QueryData Anda, melakukan analisis kesenjangan pada kegagalan, dan secara otomatis menyarankan peningkatan untuk meningkatkan akurasi.
Diagram berikut menunjukkan alur kerja pendakian bukit sistematis:
Sebelum memulai
Selesaikan prasyarat berikut sebelum menggunakan agen rekayasa konteks.
Mengaktifkan layanan yang diperlukan
Aktifkan layanan berikut untuk project Anda:Siapkan instance Cloud SQL
- Pastikan Anda memiliki akses ke instance Cloud SQL yang ada atau buat instance baru. Untuk mengetahui informasi selengkapnya, lihat Membuat instance untuk Cloud SQL.
- Pastikan Anda membuat database di instance tempat Anda akan membuat tabel. Untuk mengetahui informasi selengkapnya, lihat Membuat database pada instance Cloud SQL.
Peran dan izin yang diperlukan
- Tambahkan akun pengguna atau layanan IAM di tingkat instance. Untuk mengetahui informasi selengkapnya, lihat Menambahkan binding kebijakan IAM ke pengguna, akun layanan, atau grup.
- Berikan peran
cloudsql.studioUser,cloudsql.instanceUser, dangeminidataanalytics.queryDataUserkepada pengguna IAM atau akun layanan di tingkat project. Untuk mengetahui informasi selengkapnya, lihat Menambahkan binding kebijakan IAM untuk project. - Anda harus memiliki pengguna istimewa yang memberikan hak istimewa database kepada akun pengguna atau layanan IAM.
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";.
Untuk mengetahui informasi selengkapnya, lihat Memberikan hak istimewa database kepada setiap akun pengguna atau layanan IAM.
Memberikan izin executesql ke instance Cloud SQL
Untuk memberikan izin executesql ke instance Cloud SQL dan mengaktifkan Cloud SQL Data API, jalankan perintah berikut:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID: ID Google Cloud project Anda.INSTANCE_ID: ID instance Cloud SQL Anda.
Menyiapkan database untuk penelusuran nilai
Untuk menggunakan penelusuran nilai semantik dan trigram, Anda harus mengonfigurasi instance Cloud SQL untuk MySQL agar mendukung embedding vektor dan pengindeksan n-gram.
Agar instance Cloud SQL untuk MySQL dapat melakukan penelusuran nilai semantik, aktifkan flag berikut.
Aktifkan tanda
cloudsql_vector.gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=onAktifkan tanda
enable-google-ml-integrationagar instance Cloud SQL untuk MySQL dapat terintegrasi dengan Vertex AI.gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integrationBuat kolom vektor untuk menyimpan embedding kota
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);Membuat dan menyimpan embedding vektor untuk nama kota
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
Agar instance Cloud SQL untuk MySQL dapat melakukan penelusuran nilai trigram, ikuti langkah-langkah berikut:
Aktifkan tanda
ngram_token_size.gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3Buat indeks FULLTEXT untuk pencocokan trigram pada nama bandara:
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
Menyiapkan lingkungan Anda
Anda dapat membuat file set konteks dari lingkungan pengembangan lokal atau IDE mana pun. Untuk mempersiapkan lingkungan Anda, lakukan langkah-langkah berikut:
- Menginstal agen rekayasa konteks
- Siapkan koneksi database
Menginstal agen rekayasa konteks
Agen rekayasa konteks menjalankan server Model Context Protocol (MCP) yang memerlukan uv untuk mengelola paket Python yang mendasarinya.
Instal
uvdengan mengikuti petunjuk di Menginstaluv.Pastikan
uvtelah diinstal dan dapat diakses dari command line Anda:uv --version
Untuk menyiapkan lingkungan, instal agen rekayasa konteks di platform agen pilihan Anda, seperti Antigravity CLI, Claude Code, atau Gemini CLI.
Bergantung pada harness agen yang Anda pilih, ikuti langkah-langkah penginstalan yang sesuai:
Antigravity CLI
Untuk menginstal agen rekayasa konteks di Antigravity CLI, ikuti langkah-langkah berikut:
- Instal Antigravity CLI. Lihat Mulai Menggunakan Antigravity CLI.
- Instal plugin agen rekayasa konteks, yang mencakup alur kerja untuk pembuatan konteks. Ganti VERSION dengan versi yang dirilis yang diperlukan:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Mulai Antigravity CLI:
agy
- Opsional. Perbarui plugin:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Untuk menginstal agen rekayasa konteks di Claude Code, ikuti langkah-langkah berikut:
- Tambahkan marketplace plugin:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Instal plugin:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Muat ulang plugin untuk mengaktifkan perubahan:
/reload-plugins
- Opsional. Perbarui plugin:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (Tidak digunakan lagi)
Untuk menginstal agen rekayasa konteks di Gemini CLI, ikuti langkah-langkah berikut:
- Instal Gemini CLI. Lihat Mulai Menggunakan Gemini CLI.
- Instal ekstensi:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- Opsional. Perbarui ekstensi:
gemini extensions update mcp-db-context-enrichment
Siapkan koneksi database
Agen memerlukan koneksi database untuk mengambil skema dan kemampuan untuk memvalidasi sintaksis konteks SQL yang dihasilkan. Agar agen dapat berinteraksi dengan database Anda, konfigurasi kredensial autentikasi dan tentukan konfigurasi koneksi database Anda.
Mengonfigurasi Kredensial Default Aplikasi
Konfigurasi Kredensial Default Aplikasi (ADC) untuk memberikan kredensial pengguna guna mengakses Google Cloud resource dari agen teknik konteks:
- Server MCP Toolbox: Menggunakan kredensial untuk terhubung ke database Anda, mengambil skema, dan menjalankan SQL untuk validasi.
- Evalbench: Menggunakan kredensial untuk memanggil QueryData untuk evaluasi.
Jalankan perintah berikut di terminal Anda untuk mengautentikasi:
gcloud auth application-default loginMengonfigurasi file koneksi database
Agen memerlukan koneksi database untuk pembuatan konteks, yang didukung dan ditentukan oleh MCP Toolbox dalam file konfigurasi.
File konfigurasi menentukan sumber database dan alat yang diperlukan untuk mengambil skema atau menjalankan SQL. Agen rekayasa konteks dilengkapi dengan Keterampilan Agen yang telah diinstal sebelumnya untuk membantu Anda membuat konfigurasi.
Mulai lingkungan agen Anda.
Minta agen untuk membantu menyiapkan koneksi database—misalnya, berikan perintah "bantu saya menyiapkan koneksi database". Ikuti petunjuk agen untuk membuat file konfigurasi di direktori kerja Anda saat ini sebagai
autoctx/tools.yaml.Untuk menerapkan konfigurasi
tools.yamlbaru, muat ulang koneksi Anda:- Di Antigravity CLI, jalankan
/mcpdan pilihtoolboxuntuk memulai ulang. - Di Gemini CLI, jalankan
/mcp reload. - Di Claude Code, jalankan
/reload-plugins.
- Di Antigravity CLI, jalankan
Untuk mengetahui informasi selengkapnya tentang cara mengonfigurasi file konfigurasi database secara manual, lihat Konfigurasi MCP Toolbox.
Membuat dan mengoptimalkan konteks
Agen rekayasa konteks menyediakan serangkaian Keterampilan Agen dan alat MCP untuk meningkatkan kemampuan rekayasa konteks agen coding Anda. Anda dapat menggunakan alat-alat ini bersama-sama untuk membuat tolok ukur, mengukur efektivitas, dan menerapkan peningkatan secara iteratif. Namun, Anda dapat memulai di tahap alur kerja mana pun:
- Jika sudah menetapkan konteks, Anda dapat langsung melanjutkan ke evaluasi.
- Jika ada kueri yang gagal dan ingin Anda perbaiki, Anda dapat langsung melanjutkan ke analisis kesenjangan.
Setiap kemampuan menjelaskan tindakan, kasus penggunaan, dan perintah pemanggilan agen.
Contoh perintah menunjukkan cara Anda dapat mengajukan kueri ke agen dalam bahasa natural. Jika agen memerlukan detail tambahan untuk menyelesaikan permintaan, agen akan meminta klarifikasi kepada Anda.
Membangun dan memperluas set data evaluasi
Untuk meningkatkan performa, Anda harus mengukurnya terlebih dahulu. Rekayasa konteks tanpa set data emas, yang terdiri dari pertanyaan pengguna yang dipasangkan dengan SQL yang diharapkan, tidak memiliki verifikasi sistematis. Dengan set data emas, setiap perubahan adalah peningkatan terukur yang dapat Anda validasi terhadap kebenaran nyata.
Membuat set data emas yang representatif secara manual membutuhkan waktu, dan set data kecil mungkin tidak mencakup variasi frasa pengguna. Agen menyelesaikan masalah ini dengan:
- Membuat pasangan pertanyaan-SQL kandidat berdasarkan skema database Anda.
- Memperluas set data awal kecil menggunakan variasi filter, sinonim, dan penyusunan ulang kata.
Secara opsional, Anda dapat mengizinkan agen menjalankan SQL yang dihasilkan terhadap database Anda. Verifikasi ini mengonfirmasi bahwa kueri berhasil dijalankan sebelum Anda menambahkannya ke set data.
Set data adalah file JSON yang berisi pasangan pertanyaan-SQL:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Pasangan yang disetujui akan mengisi file autoctx/golden.json di ruang kerja Anda, tempat
pasangan tersebut siap dievaluasi. Anda dapat memberikan file yang ada atau menulis beberapa contoh evaluasi inline agar agen dapat memperluasnya.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Buat set data evaluasi dari skema saya."
- "Berikut pertanyaan awal dan SQL—perluas ke set data yang lebih luas dan verifikasi kueri yang dijalankan."
Buat set data konteks dasar pengukuran
Untuk menghindari pembuatan konteks dari awal, Anda dapat membiarkan agen mendapatkan set konteks awal dari skema database dan artefak aplikasi Anda, seperti aturan bisnis, contoh kueri, atau file README. Meskipun konteks dasar ini belum final, konteks ini memberikan titik awal yang divalidasi dan didasarkan pada model database Anda.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Buat set konteks dari skema saya."
- "Buat konteks awal menggunakan skema ini dan aturan bisnis di
requirements.md."
Agen akan meminta Anda untuk memberi nama eksperimen, yang akan mengatur artefak yang dihasilkan, dan mungkin meminta Anda untuk mempersempit cakupan jika skema database Anda besar. Untuk mengupload konteks menggunakan Cloud SQL Studio, ikuti petunjuk setelah agen membuat file JSON.
Mengevaluasi efektivitas konteks
Setelah membuat set konteks dan set data standar, Anda dapat membiarkan agen mengukur performa konteks dengan membuat kueri QueryData API agen data Anda dengan setiap pertanyaan standar. Agen membandingkan SQL yang dihasilkan dan hasil eksekusinya dengan jawaban yang diharapkan menggunakan Evalbench untuk menangani perbandingan.
Menjalankan evaluasi akan memberikan hal berikut:
- Metrik kuantitatif, seperti hasil lulus dan gagal serta skor gabungan, untuk melacak progres di seluruh iterasi konteks.
- Ringkasan percakapan inline dan laporan CSV mendetail yang ditulis ke direktori
eval_reports/di folder eksperimen Anda.
Untuk memulai evaluasi, berikan jalur set data standar dan ID set konteks. Untuk mempelajari cara menemukan ID set konteks, lihat Menemukan ID konteks agen.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Evaluate my context against
golden.json." (Evaluasi konteks saya terhadapgolden.json). - "Jalankan ulang evaluasi menggunakan konfigurasi dari eksperimen terakhir saya."
Untuk menjalankan kembali konfigurasi evaluasi yang dibuat sebelumnya tanpa menyiapkan ulang, tanyakan kepada agen atau panggil CLI secara langsung:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Untuk mengetahui detail tentang skema konfigurasi evaluasi dan cara menyesuaikan proses evaluasi, lihat dokumentasi Evalbench.
Melakukan analisis kesenjangan dan mengusulkan peningkatan
Untuk mengatasi kegagalan kueri, Anda harus mengidentifikasi penyebab utamanya, seperti kolom yang salah, gabungan tabel yang tidak ada, atau istilah fuzzy yang belum diselesaikan. Mengidentifikasi masalah ini secara manual memerlukan analisis ekstensif terhadap laporan evaluasi.
Agen mengotomatiskan loop analisis dan koreksi ini:
- Analisis kesenjangan: Agen membaca hasil evaluasi dan set konteks Anda untuk mengelompokkan kegagalan serupa dan merekomendasikan penambahan konteks yang ditargetkan, seperti template, aspek, atau penelusuran nilai.
- Perbaikan yang diusulkan: Agen mengusulkan pengeditan konkret dan secara opsional menguji SQL terhadap database Anda untuk memverifikasi penyelesaiannya.
- Mempertahankan dasar pengukuran: Agen menulis peningkatan ke file JSON baru bersama konteks dasar pengukuran Anda, dengan mempertahankan file asli.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Run gap analysis on my last evaluation and propose fixes." (Lakukan analisis kesenjangan pada evaluasi terakhir saya dan sarankan perbaikan.)
- "Optimalkan set konteks ini terhadap
golden.json."
Untuk mempersiapkan iterasi berikutnya, upload konteks yang ditingkatkan ke set konteks target menggunakan Data Agents Studio, ikuti petunjuk.
Item konteks khusus penulis sesuai permintaan
Jika Anda sudah mengetahui konteks yang diperlukan, seperti template untuk pertanyaan tertentu, aspek untuk filter berulang, atau penelusuran nilai untuk kolom tertentu, menulis JSON konteks secara manual dapat menimbulkan kesalahan serialisasi dalam nama parameter, metadata jenis, atau sintaksis fragmen. Agen menangani pemformatan JSON agar Anda dapat berfokus pada maksud bisnis Anda.
Anda juga dapat menggunakan fitur ini untuk update ad hoc, seperti saat Anda perlu mendukung pola kueri baru atau mengatasi detail skema yang tidak ada. Untuk mendapatkan JSON, jelaskan konteks yang diperlukan kepada agen tanpa menjalankan evaluasi atau menyiapkan eksperimen.
Ini juga merupakan kemampuan yang tepat untuk digunakan saat Anda diberi tugas satu kali: pemangku kepentingan memberi Anda pasangan SQL-pertanyaan baru yang ingin mereka dukung, atau Anda melihat aspek yang hilang selama peninjauan kode. Anda tidak perlu menyiapkan eksperimen atau menjalankan evaluasi untuk memperbaikinya—jelaskan apa yang Anda inginkan dan agen akan menghasilkan JSON.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Buat template untuk: 'Bandara mana saja yang ada di California?' dengan SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'." - "Buat aspek untuk filter
departure_time BETWEEN '00:00:00' AND '06:00:00'berlabel 'mata merah'." - "Buat penelusuran nilai untuk
airports.iata."
Alasan pemilihan jenis konteks
Memilih jenis konteks yang benar, terlepas dari apakah itu template, faset, atau penelusuran nilai, membantu mencegah pembengkakan konteks dan regresi kueri database. Misalnya, menggunakan template, bukan aspek, dapat menyebabkan aturan duplikat, sementara penelusuran nilai yang diperkenalkan saat template sudah cukup dapat meningkatkan latensi kueri. Untuk menemukan format skema yang benar, minta agen merekomendasikan jenis berdasarkan struktur kueri atau kolom database sebelum Anda membuat item konteks. Agen menjelaskan alasannya untuk membantu Anda memahami opsi konteks.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Saya terus menulis filter
departure_time BETWEEN '00:00:00' AND '06:00:00'di banyak kueri. Bagaimana cara terbaik untuk merekamnya?" - "Pengguna mendeskripsikan status penerbangan dalam teks bebas dan saya ingin mencocokkannya dengan
flights.status. Jenis penelusuran nilai apa yang harus saya siapkan?" - "Apa perbedaan antara template dan aspek, dan kapan saya harus menggunakan masing-masing?"
Menerapkan operasi massal di seluruh set konteks
Agen mendukung update massal untuk mengelola set konteks besar secara konsisten. Jika Anda perlu memperbarui beberapa item konteks secara bersamaan, seperti saat kolom database diganti namanya, format nilai kode berubah, atau template mereferensikan tabel yang tidak digunakan lagi, agen dapat menerapkan perubahan di setiap item yang terpengaruh tanpa mengubah entri yang tidak terkait.
Anda dapat menggunakan contoh perintah berikut untuk memberikan petunjuk kepada agen:
- "Baca
golden.txtdan ubah semua pasangan menjadi template." - "Di
context_set.json, gantiairline = 'UA'denganairline = 'United Airlines'untuk setiap item yang mereferensikan 'United'. Biarkan item yang tidak terkait."
Langkah berikutnya
- Pelajari lebih lanjut set konteks.
- Pelajari cara membuat atau menghapus set konteks di Cloud SQL Studio.
- Pelajari cara menguji set konteks.