
במאמר הזה מוסבר איך ליצור ולבצע אופטימיזציה של קבוצות ההקשר שעוזרות להשיג רמת דיוק גבוהה בשאילתות QueryData באפליקציות של סוכני הנתונים. הסוכן להנדסת הקשר עוזר לכם ליצור, להעריך ולשפר קבוצות של הקשרים על ידי אוטומציה של היצירה והאופטימיזציה שלהן.
מידע על קבוצות הקשר ועל QueryData זמין במאמרים סקירה כללית על קבוצות הקשר וסקירה כללית על QueryData.כדי ליצור אפליקציות נתונים ברמת הארגון, בדרך כלל צריך להשיג איכות של כמעט 100% בדיוק של מודל המרת טקסט ל-SQL. תוצאות שאילתה שגויות משפיעות על השימושיות הכוללת של האפליקציה ועל חוויית המשתמש. כדי לקבל תשובות מדויקות שניתן להסביר אותן ורלוונטיות לעסק, צריך להשתמש בהנדסת הקשר. זהו תהליך של יצירה ואופטימיזציה חוזרת של ההקשר כדי להשיג את רמת הדיוק האופטימלית.
כשמספקים ל-QueryData את ההקשר שממוקד לאפליקציה העסקית, מספקים את הכללים העסקיים המדויקים שהמערכת צריכה כדי לזהות כוונת משתמש מורכבת.
סוכן הנדסת הקשר
סוכן ה-AI להנדסת הקשר מבצע אוטומציה של תהליך האופטימיזציה הזה. אתם יכולים לנהל שיחה עם הנציג כדי לבצע משימות אד-הוק לאופטימיזציה של ההקשר. בהמשך מופיעה רשימה של הנחיות בשפה טבעית שאפשר להשתמש בהן כדי לתת הוראות לסוכן, וגם תיאור של התגובה של הסוכן. הדוגמאות האלה יעזרו לכם ליצור את ההקשר ולבצע בו אופטימיזציה:
- הנחיה לדוגמה לניתוח כשלים: "עדכן את ההקשר כדי שנוכל לזהות נכון את שדה התעופה בשאילתות כמו 'טיסות לדיסני וורלד'". הסוכן מנתח את הכשל, מסיק מסקנות לגבי הפער וממליץ להוסיף פריט הקשר מתאים, כמו שאילתת חיפוש ערכים.
- הנחיה לדוגמה להוספת הקשר: "Read my app code and suggest some context to add." הסוכן מנתח את הקוד, מסיק מסקנות לגבי תחום האפליקציה ומציע פריטי הקשר רלוונטיים.
- הנחיה לדוגמה לעיבוד בכמות גדולה: "הנה 10 דוגמאות לשאלות ולשאילתות SQL. הופכים אותם לתבניות". הסוכן מעבד את הקלט בכמות גדולה ומעדכן את קבוצת ההקשר.
החשיבות של מערך הנתונים המאומת
כדי לבצע אופטימיזציה של ההקשר, קודם צריך ליצור מערך נתונים שתואם לקלט בשפה טבעית של האפליקציה. הסוכן יכול לעזור לכם ליצור את מערך הנתונים המושלם הזה, שכולל שאלות של משתמשים ואת השאילתות הצפויות שלהם במסד הנתונים. מערך נתונים מאומת מאפשר לכם:
- הגדרת בסיס לביצועי שאילתות.
- אימות העדכונים מול שאילתות במסד נתונים של נתוני אמת.
- למדוד את שיפורי הדיוק לאורך האיטרציות.
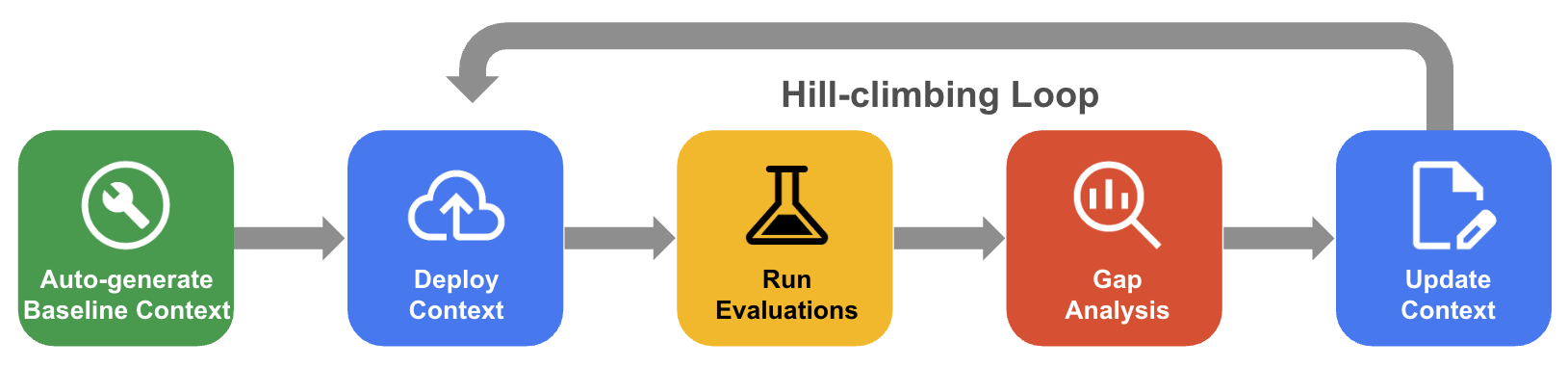
תהליך שיטתי של חיפוש מקסימום מקומי
בשיטת הטיפוס על גבעה שיטתי, הסוכן משפר באופן איטרטיבי קבוצת הקשר באמצעות הערכה של מערך נתוני הזהב, ניתוח פערים ועדכונים כדי לשפר את הדיוק לרמה של כמעט 100%.
- יצירה אוטומטית של הקשר בסיסי: יצירת קבוצת הקשר הראשונית שנגזרת מסכימת מסד הנתונים ומארטיפקטים של האפליקציה.
- תהליך עבודה של אופטימיזציה מסוג Hill-climbing: הסוכן יכול להעריך את הדיוק של QueryData, לבצע ניתוח פערים של כשלים ולהציע שיפורים באופן אוטומטי כדי להגדיל את הדיוק.
הדיאגרמה הבאה מציגה את תהליך העבודה השיטתי של טיפוס גבעות:
לפני שמתחילים
לפני שמשתמשים בסוכן הנדסת ההקשר, צריך לוודא שמתקיימות הדרישות המוקדמות הבאות.
הפעלת שירותים נדרשים
מפעילים את השירותים הבאים בפרויקט:הכנת מכונה של Cloud SQL
- מוודאים שיש לכם גישה למופע קיים של Cloud SQL או יוצרים מופע חדש. מידע נוסף זמין במאמר יצירת מופעים ל-Cloud SQL.
- מוודאים שיוצרים מסד נתונים במופע שבו ייצרו את הטבלאות. מידע נוסף זמין במאמר יצירת מסד נתונים במכונת Cloud SQL.
תפקידים והרשאות נדרשים
- מוסיפים חשבון שירות או משתמש IAM ברמת המופע. מידע נוסף זמין במאמר בנושא הוספת קשר בין מדיניות IAM לבין משתמש, חשבון שירות או קבוצה.
- מקצים את התפקידים
cloudsql.studioUser, cloudsql.instanceUserו-geminidataanalytics.queryDataUserלמשתמש IAM או לחשבון השירות ברמת הפרויקט. מידע נוסף זמין במאמר הוספת קשירת מדיניות IAM לפרויקט. - משתמש עם הרשאות אדמין צריך לתת הרשאות למסד הנתונים למשתמש IAM או לחשבון השירות.
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";.
מידע נוסף זמין במאמר איך נותנים הרשאות למסד הנתונים למשתמש IAM או לחשבון שירות ספציפיים.
מתן הרשאה ל-executesql למופע Cloud SQL
כדי להעניק את ההרשאה executesql למכונת Cloud SQL ולהפעיל את Cloud SQL Data API, מריצים את הפקודה הבאה:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
-
PROJECT_ID: מזהה הפרויקט ב- Google Cloud . -
INSTANCE_ID: המזהה של מופע Cloud SQL.
הכנת מסד הנתונים לחיפושים של ערכים
כדי להשתמש בחיפושי ערכים סמנטיים וטריגרמיים, צריך להגדיר את מופע Cloud SQL ל-MySQL כך שיתמוך בהטמעות וקטוריות ובהוספת אינדקסים של n-גרם.
כדי לאפשר למכונת Cloud SQL ל-MySQL לבצע חיפושים סמנטיים של ערכים, צריך להפעיל את הדגלים הבאים.
מפעילים את התכונה הניסיונית
cloudsql_vector.gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=onמפעילים את הדגל
enable-google-ml-integrationכדי לאפשר למכונת Cloud SQL ל-MySQL להשתלב עם Vertex AI.gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integrationיצירת עמודת וקטורים לאחסון הטמעות של ערים
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);יצירה ואחסון של הטמעות וקטוריות לשמות של ערים
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
כדי לאפשר למכונת Cloud SQL ל-MySQL לבצע חיפושים של ערכי טריגרם, צריך לבצע את השלבים הבאים:
מפעילים את התכונה הניסיונית
ngram_token_size.gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3יוצרים אינדקס FULLTEXT להתאמת טריגרמות בשם שדה התעופה:
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
הכנת הסביבה
אפשר ליצור קובצי הגדרת הקשר מכל סביבת פיתוח מקומית או IDE. כדי להכין את הסביבה, פועלים לפי השלבים הבאים:
- התקנת סוכן הנדסת ההקשר
- הגדרת החיבור למסד הנתונים
התקנת סוכן הנדסת ההקשר
הסוכן Context Engineering מריץ שרת Model Context Protocol (MCP) שנדרש לו uv כדי לנהל חבילות Python בסיסיות.
כדי להתקין את
uv, פועלים לפי ההוראות במאמר התקנתuv.מוודאים ש-
uvמותקן ושאפשר לגשת אליו משורת הפקודה:uv --version
כדי להכין את הסביבה, מתקינים את סוכן הנדסת ההקשר ב-מעטפת אג'נטית שבחרתם, כמו Antigravity CLI, Claude Code או Gemini CLI.
בהתאם ל-Agent Harness שבחרתם, פועלים לפי שלבי ההתקנה המתאימים:
Antigravity CLI
כדי להתקין את סוכן הנדסת ההקשר ב-Antigravity CLI, פועלים לפי השלבים הבאים:
- מתקינים את Antigravity CLI. תחילת העבודה עם Antigravity CLI
- מתקינים את הפלאגין של סוכן הנדסת ההקשר, שכולל תהליכי עבודה ליצירת הקשר. מחליפים את VERSION בגרסה שפורסמה הנדרשת:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- מפעילים את Antigravity CLI:
agy
- זה שינוי אופציונלי. מעדכנים את הפלאגין:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
כדי להתקין את סוכן הנדסת ההקשר ב-Claude Code, פועלים לפי השלבים הבאים:
- מוסיפים את חנות הפלאגינים:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- מתקינים את הפלאגין:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- טוענים מחדש את הפלאגינים כדי להפעיל את השינויים:
/reload-plugins
- זה שינוי אופציונלי. מעדכנים את הפלאגין:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (יצא משימוש)
כדי להתקין את הסוכן להנדסת הקשר ב-Gemini CLI, פועלים לפי השלבים הבאים:
- מתקינים את Gemini CLI. איך מתחילים להשתמש ב-Gemini CLI
- מתקינים את התוסף:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- זה שינוי אופציונלי. מעדכנים את התוסף:
gemini extensions update mcp-db-context-enrichment
הגדרת החיבור למסד הנתונים
הסוכן דורש חיבור למסד נתונים כדי לאחזר סכימות, ויכול לאמת את התחביר של הקשר SQL שנוצר. כדי לאפשר לסוכן לקיים אינטראקציה עם מסד הנתונים, צריך להגדיר פרטי אימות ולהגדיר את חיבור מסד הנתונים.
הגדרת Application Default Credentials
מגדירים Application Default Credentials (ADC) כדי לספק פרטי כניסה של משתמש לצורך גישה למשאבים של Google Cloud הסוכן להנדסת הקשר:
- שרת MCP של ערכת הכלים: משתמש בפרטי כניסה כדי להתחבר למסד הנתונים, לאחזר סכימות ולהריץ SQL לצורך אימות.
- Evalbench: משתמש בהרשאות כדי להפעיל את QueryData לצורך הערכה.
כדי לבצע אימות, מריצים את הפקודות הבאות בטרמינל:
gcloud auth application-default loginהגדרת קובץ החיבור למסד הנתונים
הסוכן צריך חיבור למסד נתונים כדי ליצור הקשר, וMCP Toolbox תומך בכך ומגדיר את החיבור בקובץ תצורה.
קובץ התצורה מציין את מקור מסד הנתונים ואת הכלים שנדרשים כדי לאחזר סכימות או להריץ SQL. סוכן הנדסת ההקשר מגיע עם כישורי סוכן שהותקנו מראש כדי לעזור לכם ליצור את ההגדרה.
מפעילים את סביבת הסוכן.
מבקשים מהסוכן לעזור בהגדרת החיבור למסד הנתונים – לדוגמה, מזינים את ההנחיה "help me set up the database connection". פועלים לפי ההוראות של הסוכן כדי ליצור את קובץ ההגדרות בספריית העבודה הנוכחית בתור
autoctx/tools.yaml.כדי להחיל את ההגדרה החדשה של
tools.yaml, צריך לטעון מחדש את החיבור:- ב-CLI של Antigravity, מריצים את הפקודה
/mcpובוחרים באפשרותtoolboxכדי להפעיל מחדש. - ב-Gemini CLI, מריצים את הפקודה
/mcp reload. - ב-Claude Code, מריצים את הפקודה
/reload-plugins.
- ב-CLI של Antigravity, מריצים את הפקודה
מידע נוסף על הגדרה ידנית של קובץ התצורה של מסד הנתונים זמין במאמר הגדרת MCP Toolbox.
יצירה ואופטימיזציה של הקשר
הסוכן Context Engineering מספק קבוצה של כישורי סוכן וכלי MCP כדי לשפר את יכולת הנדסת ההקשר של סוכן התכנות. אפשר להשתמש בכלים האלה יחד כדי ליצור בסיס להשוואה, למדוד את היעילות ולבצע שיפורים באופן איטרטיבי. עם זאת, אפשר להתחיל בכל שלב בתהליך העבודה:
- אם כבר הגדרתם הקשר, אתם יכולים להמשיך ישירות להערכה.
- אם יש לכם שאילתות שנכשלות ואתם רוצים לתקן אותן, אתם יכולים לעבור ישירות לניתוח הפערים.
כל יכולת מתארת את הפעולות של הסוכן, תרחישי השימוש ופקודות ההפעלה.
ההנחיות לדוגמה מראות איך אפשר לשאול את הסוכן בשפה טבעית. אם הסוכן צריך פרטים נוספים כדי להשלים בקשה, הוא יבקש ממך הבהרה.
יצירה והרחבה של מערכי נתונים להערכה
כדי לשפר את הביצועים, קודם צריך למדוד אותם. הנדסת הקשר ללא מערך נתונים מוזהב, שמורכב משאלות של משתמשים שמשויכות לשאילתות SQL הצפויות שלהן, לא כוללת אימות שיטתי. בעזרת מערך נתונים מושלם, כל שינוי הוא שיפור מדיד שאפשר לאמת מול נתוני האמת.
יצירה ידנית של מערך נתונים מייצג היא תהליך שלוקח זמן, ומערכי נתונים קטנים עלולים לפספס וריאציות בניסוחים של משתמשים. הסוכן פותר את הבעיה באמצעות:
- המערכת יוצרת זוגות של שאלות ושאילתות SQL על סמך סכימת מסד הנתונים.
- הרחבת מערך נתונים קטן של מילות מפתח ראשוניות באמצעות וריאציות של מסננים, מילים נרדפות וניסוחים מחדש.
לחלופין, אפשר לאפשר לסוכן להריץ את ה-SQL שנוצר מול מסד הנתונים. האימות הזה מאשר שהשאילתות מופעלות בהצלחה לפני שמוסיפים אותן למערך הנתונים.
מערך הנתונים הוא קובץ JSON שמכיל זוגות של שאלות ו-SQL:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
הזוגות שאושרו מאכלסים את הקובץ autoctx/golden.json בסביבת העבודה, והם מוכנים להערכה. אתם יכולים לספק קובץ קיים או לכתוב כמה דוגמאות להערכה בשורה כדי שהסוכן ירחיב אותן.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "תייצר מערך נתונים להערכה מהסכימה שלי".
- "Here's a seed question and SQL—expand it into a broader dataset and verify the queries run."
יצירת קבוצת הקשרים של נתוני הבסיס
כדי להימנע מיצירת הקשר מאפס, אפשר לאפשר לסוכן להסיק קבוצת הקשר ראשונית מסכימת מסד הנתונים ומארטיפקטים של האפליקציה, כמו כללים עסקיים, שאילתות לדוגמה או קובצי README. ההקשר הבסיסי הזה לא סופי, אבל הוא מספק נקודת התחלה מאומתת שמבוססת על מודל מסד הנתונים שלכם.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "צור קבוצת הקשר מהסכימה שלי".
- "צור הקשר הראשוני באמצעות הסכימות האלה וכללי העסק שמופיעים ב-
requirements.md".
הסוכן יבקש מכם לתת שם לניסוי, כדי לארגן את הארטיפקטים שנוצרו, ויכול להיות שהוא יבקש מכם לצמצם את ההיקף אם סכימת מסד הנתונים גדולה. כדי להעלות את ההקשר באמצעות Cloud SQL Studio, פועלים לפי ההוראות אחרי שהסוכן יוצר את קובץ ה-JSON.
הערכת האפקטיביות של ההקשר
אחרי שיוצרים קבוצת הקשר ומערך נתונים מוזהב, אפשר לאפשר לסוכן למדוד את ביצועי ההקשר על ידי שליחת שאילתות ל-QueryData API של סוכן הנתונים עם כל שאלה מוזהבת. הסוכן משווה את ה-SQL שנוצר ואת תוצאות ההרצה שלו לתשובה הצפויה באמצעות Evalbench.
הפעלת הערכה מספקת את הנתונים הבאים:
- מדדים כמותיים, כמו תוצאות של מעבר או כישלון וציונים מצטברים, כדי לעקוב אחרי ההתקדמות לאורך איטרציות של הקשר.
- סיכום שיחה מוטבע ודוחות מפורטים בפורמט CSV שנכתבים לספרייה
eval_reports/בתיקיית הניסוי.
כדי להתחיל בהערכה, צריך לספק את הנתיב של מערך הזהב ואת המזהה של קבוצת ההקשר. במאמר איך מוצאים את מזהה ההקשר של הסוכן מוסבר איך למצוא את מזהה קבוצת ההקשר.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "תבדוק את ההקשר שלי בהשוואה ל
golden.json". - "תריץ מחדש את ההערכה באמצעות ההגדרה מהניסוי האחרון שלי".
כדי להריץ מחדש הגדרת הערכה שנוצרה בעבר בלי להגדיר אותה מחדש, אפשר לבקש מהסוכן או להפעיל את ה-CLI ישירות:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
פרטים על סכמת הגדרות ההערכה ועל התאמה אישית של הרצות הערכה מופיעים במסמכי התיעוד של Evalbench.
לבצע ניתוח פערים ולהציע שיפורים
כדי לפתור בעיות בשאילתות, צריך לזהות את שורש הבעיה, למשל עמודות שגויות, צירופי טבלאות חסרים או מונחים לא מדויקים שלא נפתרו. כדי לזהות את הבעיות האלה באופן ידני, צריך לנתח באופן מקיף את דוחות ההערכה.
הסוכן מבצע את הניתוח הזה באופן אוטומטי:
- ניתוח פערים: הסוכן קורא את תוצאות ההערכה ואת ההקשר שהגדרתם כדי לקבץ כשלים דומים ולהמליץ על הוספות ממוקדות להקשר, כמו תבניות, היבטים או חיפושי ערכים.
- הצעות לתיקונים: הסוכן מציע עריכות קונקרטיות, ויכול גם לבדוק את ה-SQL מול מסד הנתונים כדי לוודא שהבעיה נפתרה.
- שמירה של נתוני הבסיס: הסוכן כותב את השיפורים לקובץ JSON חדש לצד נתוני הבסיס של ההקשר, ושומר את הקבצים המקוריים.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "Run gap analysis on my last evaluation and propose fixes." (הפעלת ניתוח פערים בהערכה האחרונה שלי והצעת תיקונים)
- "תבצע אופטימיזציה של קבוצת ההקשר הזו בהשוואה ל-
golden.json".
כדי להתכונן לאיטרציה הבאה, מעלים את ההקשר המשופר אל קבוצת ההקשר של היעד באמצעות Data Agents Studio. אפשר לפעול לפי ההוראות.
פריטי הקשר ספציפיים למחבר לפי דרישה
אם אתם כבר יודעים מה ההקשר הנדרש, כמו תבנית לשאלה ספציפית, מאפיין לסינון חוזר או חיפוש ערך בעמודה מסוימת, כתיבת ה-JSON של ההקשר באופן ידני עלולה לגרום לשגיאות סריאליזציה בשמות הפרמטרים, במטא-נתונים של הסוג או בתחביר של המקטע. הסוכן מטפל בעיצוב JSON כדי שתוכלו להתמקד בכוונה העסקית שלכם.
אפשר להשתמש בתכונה הזו גם לעדכונים אד-הוק, למשל כשצריך לתמוך במבנה שאילתה חדש או לטפל בפרט חסר בסכימה. כדי לקבל את ה-JSON, צריך לתאר לסוכן את ההקשר הנדרש בלי להריץ הערכה או להגדיר ניסוי.
זו גם היכולת הנכונה להשתמש בה כשמקבלים משימה חד-פעמית: בעל עניין נותן לכם זוג חדש של שאלה ו-SQL שהוא רוצה שיהיה לו תמיכה, או שאתם מזהים היבט חסר במהלך סקר קוד. לא צריך להגדיר ניסוי או להריץ הערכה כדי לתקן את זה – פשוט מתארים מה רוצים והסוכן יוצר את ה-JSON.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "צור תבנית לשאלה 'אילו שדות תעופה נמצאים בקליפורניה?' באמצעות SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'". - "צור היבט לסינון
departure_time BETWEEN '00:00:00' AND '06:00:00'עם התווית 'עיניים אדומות'". - "צור חיפוש ערכים עבור
airports.iata".
הסבר על סוג ההקשר שנבחר
בחירה בסוג ההקשר הנכון, בין אם מדובר בתבנית, בפן או בחיפוש ערכים, עוזרת למנוע ניפוח של ההקשר ונסיגות בשאילתות של מסד הנתונים. לדוגמה, שימוש בתבנית במקום בפן יכול לגרום לכללים כפולים, בעוד שחיפושי ערכים שהוצגו במקום שבו תבנית מספיקה יכולים להגדיל את זמן האחזור של השאילתה. כדי למצוא את פורמט הסכימה הנכון, מבקשים מהסוכן להמליץ על סוג על סמך מבנה השאילתה או עמודות מסד הנתונים לפני שיוצרים פריטי הקשר. הסוכן מסביר את ההיגיון שלו כדי לעזור לכם להבין את אפשרויות ההקשר.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "אני ממשיך לכתוב את המסנן
departure_time BETWEEN '00:00:00' AND '06:00:00'בשאילתות רבות. מה הדרך הכי טובה לצלם את זה?" - "משתמשים מתארים את סטטוס הטיסה בטקסט חופשי ואני רוצה להתאים אותם ל-
flights.status. איזה סוג של חיפוש ערכים כדאי לי להגדיר?" - "מה ההבדל בין תבנית לבין היבט, ומתי כדאי להשתמש בכל אחד מהם?"
החלת פעולות בכמות גדולה על קבוצת הקשרים
הסוכן תומך בעדכונים בכמות גדולה כדי לנהל באופן עקבי מערכי הקשר גדולים. אם צריך לעדכן כמה פריטי הקשר בו-זמנית, למשל כשמשנים את השם של עמודה במסד נתונים, כשפורמט של ערך קוד משתנה או כשבתבניות יש הפניה לטבלה שהוצאה משימוש, הסוכן יכול להחיל את השינוי על כל הפריטים המושפעים בלי לשנות רשומות שלא קשורות.
אפשר להשתמש בדוגמאות הבאות להנחיות כדי לתת הוראות לסוכן:
- "Read
golden.txtand turn all the pairs into templates." - "ב-
context_set.json, מחליפים אתairline = 'UA'ב-airline = 'United Airlines'בכל פריט שמפנה אל 'United'. לא לגעת בפריטים שלא קשורים אחד לשני".
המאמרים הבאים
- מידע נוסף על קבוצות של הקשרים
- איך יוצרים או מוחקים קבוצת הקשר ב-Cloud SQL Studio
- איך בודקים קבוצת הקשר