
Ce document explique comment créer et optimiser les ensembles de contexte qui permettent d'obtenir une grande précision des requêtes QueryData dans vos applications d'agent de données. L'agent d'ingénierie du contexte vous aide à créer, évaluer et améliorer des ensembles de contexte en automatisant leur création et leur optimisation.
Pour en savoir plus sur les ensembles de contexte et QueryData, consultez Présentation des ensembles de contexte et Présentation de QueryData.Pour créer des applications de données de niveau entreprise, la précision du modèle text-to-SQL doit généralement atteindre une qualité proche de 100 %. Des résultats de requête incorrects affectent l'expérience utilisateur et l'usabilité globale de l'application. Pour obtenir des réponses explicables et pertinentes pour l'entreprise avec une grande précision, il faut recourir à l'ingénierie du contexte. Il s'agit du processus de création et d'optimisation itérative du contexte pour atteindre une précision optimale.
En fournissant QueryData avec le contexte ciblé sur votre application métier, vous fournissez les règles métier précises dont le système a besoin pour résoudre l'intention utilisateur nuancée.
Agent d'ingénierie du contexte
L'agent d'ingénierie du contexte automatise ce workflow d'optimisation. Vous pouvez discuter avec l'agent pour gérer des tâches ponctuelles et optimiser votre contexte. La liste suivante fournit des exemples de requêtes en langage naturel que vous pouvez utiliser pour donner des instructions à l'agent, ainsi qu'une description de la façon dont l'agent répond. Utilisez ces exemples pour vous aider à créer et à optimiser votre contexte :
- Exemple de requête pour l'analyse des échecs : "Mets à jour le contexte pour que nous identifions correctement l'aéroport pour les requêtes telles que 'vols disney world'." L'agent analyse l'échec, réfléchit à l'écart et recommande d'ajouter un élément de contexte approprié, tel qu'une requête de recherche de valeur.
- Exemple de requête pour une suggestion de contexte : Lis le code de mon application et suggère du contexte à ajouter. L'agent analyse le code, réfléchit au domaine de votre application et suggère les éléments de contexte qui seraient pertinents.
- Exemple de requête pour le traitement par lot : "Voici 10 exemples de questions et de requêtes SQL. Transformez-les en modèles." L'agent traite vos entrées par lot et met à jour votre ensemble de contexte.
Importance de l'ensemble de données de référence
Pour optimiser votre contexte, vous devez d'abord créer un ensemble de données correspondant aux entrées en langage naturel de votre application. L'agent peut vous aider à créer cet ensemble de données de référence, qui se compose de questions d'utilisateurs et des requêtes de base de données attendues. Un ensemble de données de référence vous permet de :
- Établissez une référence pour les performances des requêtes.
- Validez les mises à jour par rapport aux requêtes de base de données de vérité terrain.
- Mesurez les améliorations de la précision au fil des itérations.
Processus systématique d'escalade
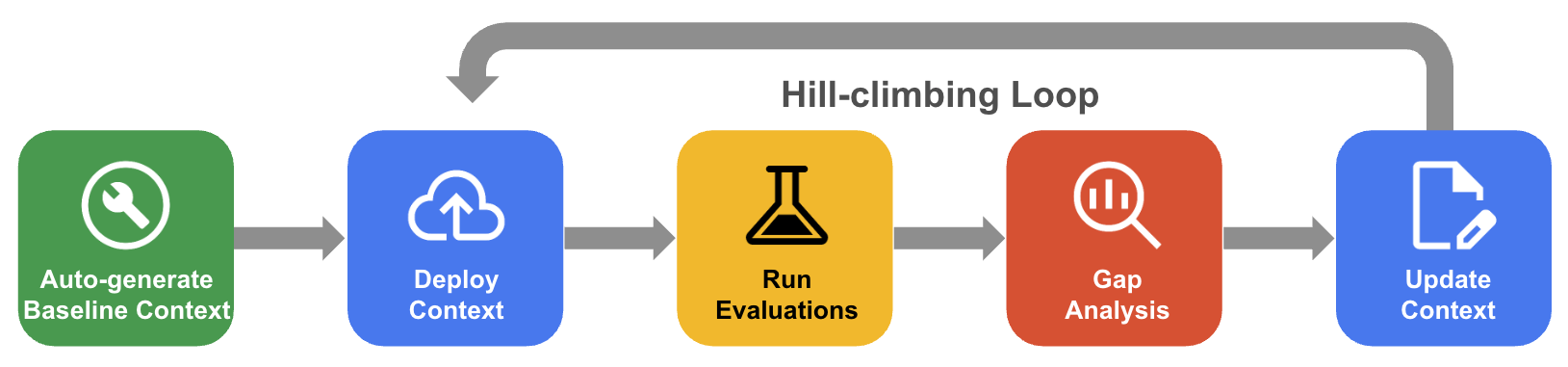
Dans l'escalade systématique, l'agent améliore de manière itérative un ensemble de contextes en évaluant l'ensemble de données de référence, en analysant les écarts et en apportant des modifications pour atteindre une précision proche de 100%.
- Générer automatiquement un contexte de référence : créez un ensemble de contexte de départ dérivé du schéma de votre base de données et des artefacts de votre application.
- Workflow d'optimisation par escalade : laissez l'agent évaluer la précision de vos QueryData, effectuer une analyse des écarts sur les échecs et proposer automatiquement des améliorations pour augmenter la précision.
Le schéma suivant illustre le workflow systématique d'escalade de colline :
Avant de commencer
Remplissez les conditions préalables suivantes avant d'utiliser l'agent d'ingénierie du contexte.
Activer les services requis
Activez les services suivants pour votre projet :Préparer une instance Cloud SQL
- Assurez-vous d'avoir accès à une instance Cloud SQL existante ou créez-en une. Pour en savoir plus, consultez Créer des instances pour Cloud SQL.
- Assurez-vous de créer une base de données dans votre instance dans laquelle vous créerez les tables. Pour en savoir plus, consultez Créer une base de données sur l'instance Cloud SQL.
Rôles et autorisations nécessaires
- Ajoutez un compte d'utilisateur ou un compte de service IAM au niveau de l'instance. Pour en savoir plus, consultez Ajouter une liaison de stratégie IAM à un utilisateur, un compte de service ou un groupe.
- Attribuez les rôles
cloudsql.studioUser,cloudsql.instanceUseretgeminidataanalytics.queryDataUserà l'utilisateur IAM ou au compte de service au niveau du projet. Pour en savoir plus, consultez Ajouter une association de stratégie IAM pour un projet. - Vous devez demander à un utilisateur privilégié d'accorder des droits sur la base de données à l'utilisateur ou au compte de service IAM.
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";.
Pour en savoir plus, consultez Accorder des droits sur une base de données à un utilisateur ou à un compte de service IAM individuel.
Accorder l'autorisation executesql à l'instance Cloud SQL
Pour accorder l'autorisation executesql à l'instance Cloud SQL et activer l'API Cloud SQL Data, exécutez la commande suivante :
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID: ID de votre projet Google Cloud .INSTANCE_ID: ID de votre instance Cloud SQL.
Préparer la base de données pour les recherches de valeurs
Pour utiliser les recherches de valeurs sémantiques et trigrammes, vous devez configurer votre instance Cloud SQL pour MySQL afin qu'elle soit compatible avec les embeddings vectoriels et l'indexation des n-grammes.
Pour permettre à l'instance Cloud SQL pour MySQL d'effectuer des recherches de valeurs sémantiques, activez les indicateurs suivants.
Activez l'option
cloudsql_vector.gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=onActivez le flag
enable-google-ml-integrationpour permettre à l'instance Cloud SQL pour MySQL de s'intégrer à Vertex AI.gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integrationCréer une colonne de vecteurs pour stocker les embeddings de villes
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);générer et stocker des embeddings vectorielles pour les noms de villes ;
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
Pour permettre à l'instance Cloud SQL pour MySQL d'effectuer des recherches de valeurs trigrammes, procédez comme suit :
Activez l'option
ngram_token_size.gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3Créez un index FULLTEXT pour la correspondance de trigrammes sur le nom de l'aéroport :
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
Préparer votre environnement
Vous pouvez créer des fichiers d'ensemble de contexte à partir de n'importe quel environnement de développement local ou IDE. Pour préparer votre environnement, procédez comme suit :
- Installer l'agent d'ingénierie du contexte
- Configurer la connexion à la base de données
Installer l'agent d'ingénierie du contexte
L'agent d'ingénierie du contexte exécute le serveur MCP (Model Context Protocol) qui nécessite uv pour gérer les packages Python sous-jacents.
Installez
uven suivant les instructions de la section Installeruv.Vérifiez que
uvest installé et accessible depuis votre ligne de commande :uv --version
Pour préparer votre environnement, installez l'agent d'ingénierie du contexte dans le harnais d'agent de votre choix, tel que Antigravity CLI, Claude Code ou Gemini CLI.
En fonction du harnais d'agent sélectionné, suivez les étapes d'installation correspondantes :
CLI Antigravity
Pour installer l'agent d'ingénierie du contexte dans l'interface de ligne de commande Antigravity, procédez comme suit :
- Installez la CLI Antigravity. Consultez Premiers pas avec Antigravity CLI.
- Installez le plug-in d'agent d'ingénierie du contexte, qui inclut des workflows pour la génération de contexte. Remplacez VERSION par la version publiée requise :
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Démarrez la CLI Antigravity :
agy
- Facultatif. Mettez à jour le plug-in :
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Pour installer l'agent d'ingénierie contextuelle dans Claude Code, procédez comme suit :
- Ajoutez le Marketplace de plug-ins :
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Installez le plug-in :
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Actualisez les plug-ins pour activer les modifications :
/reload-plugins
- Facultatif. Mettez à jour le plug-in :
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (obsolète)
Pour installer l'agent d'ingénierie contextuelle dans Gemini CLI, procédez comme suit :
- Installez la Gemini CLI. Consultez Premiers pas avec Gemini CLI.
- Installez l'extension :
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- Facultatif. Mettez à jour l'extension :
gemini extensions update mcp-db-context-enrichment
Configurer la connexion à la base de données
L'agent a besoin d'une connexion à la base de données pour récupérer les schémas et valider la syntaxe du contexte SQL généré. Pour permettre à l'agent d'interagir avec votre base de données, configurez les identifiants d'authentification et définissez la configuration de connexion à votre base de données.
Configurer les identifiants par défaut de l'application
Configurez les identifiants par défaut de l'application (ADC) pour fournir les identifiants utilisateur permettant d'accéder aux ressources Google Cloud à partir de l'agent d'ingénierie du contexte :
- Serveur MCP Toolbox : utilise les identifiants pour se connecter à votre base de données, récupérer les schémas et exécuter le code SQL pour la validation.
- Evalbench : utilise des identifiants pour appeler QueryData à des fins d'évaluation.
Exécutez les commandes suivantes dans votre terminal pour vous authentifier :
gcloud auth application-default loginConfigurer le fichier de connexion à la base de données
L'agent nécessite une connexion à une base de données pour générer le contexte. MCP Toolbox est compatible avec cette connexion et la définit dans un fichier de configuration.
Le fichier de configuration spécifie votre source de données et les outils nécessaires pour récupérer des schémas ou exécuter des requêtes SQL. L'agent d'ingénierie du contexte est fourni avec des compétences d'agent préinstallées pour vous aider à générer la configuration.
Démarrez l'environnement de votre agent.
Demandez à l'agent de vous aider à configurer la connexion à la base de données. Par exemple, saisissez la requête "aide-moi à configurer la connexion à la base de données". Suivez les instructions de l'agent pour créer le fichier de configuration dans votre répertoire de travail actuel sous le nom
autoctx/tools.yaml.Pour appliquer la nouvelle configuration
tools.yaml, rechargez votre connexion :- Dans la CLI Antigravity, exécutez
/mcpet sélectionneztoolboxpour redémarrer. - Dans Gemini CLI, exécutez
/mcp reload. - Dans Claude Code, exécutez
/reload-plugins.
- Dans la CLI Antigravity, exécutez
Pour en savoir plus sur la configuration manuelle du fichier de configuration de la base de données, consultez Configuration de MCP Toolbox.
Générer et optimiser le contexte
L'agent d'ingénierie du contexte fournit un ensemble de compétences d'agent et d'outils MCP pour améliorer la capacité d'ingénierie du contexte de votre agent de codage. Vous pouvez utiliser ces outils ensemble pour générer une référence, mesurer l'efficacité et appliquer des améliorations de manière itérative. Toutefois, vous pouvez commencer à n'importe quelle étape du workflow :
- Si vous avez déjà défini un contexte, vous pouvez passer directement à l'évaluation.
- Si vous avez des requêtes qui échouent et que vous souhaitez corriger, vous pouvez passer directement à l'analyse des écarts.
Chaque capacité décrit les actions, les cas d'utilisation et les commandes d'invocation de l'agent.
Les exemples de requêtes montrent comment interroger l'agent en langage naturel. Si l'agent a besoin d'informations supplémentaires pour répondre à une demande, il vous invite à fournir des précisions.
Créer et étendre des ensembles de données d'évaluation
Pour améliorer vos performances, vous devez d'abord les mesurer. L'ingénierie du contexte sans ensemble de données de référence, qui se compose de questions d'utilisateurs associées à leur requête SQL attendue, manque de vérification systématique. Avec un ensemble de données de référence, chaque modification est une amélioration mesurable que vous pouvez valider par rapport à la vérité terrain.
La création manuelle d'un ensemble de données de référence représentatif prend du temps, et les petits ensembles de données peuvent passer à côté des variations dans la formulation des utilisateurs. L'agent résout ce problème en :
- Génération de paires question/requête SQL candidates en fonction du schéma de votre base de données.
- Développer un petit ensemble de données initiales à l'aide de variantes de filtres, de synonymes et de reformulations.
Vous pouvez éventuellement laisser l'agent exécuter le code SQL généré sur votre base de données. Cette vérification confirme que les requêtes s'exécutent correctement avant que vous ne les ajoutiez à l'ensemble de données.
L'ensemble de données est un fichier JSON contenant des paires question-SQL :
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Les paires approuvées sont ajoutées au fichier autoctx/golden.json de votre espace de travail, où elles sont prêtes à être évaluées. Vous pouvez fournir un fichier existant ou écrire des exemples d'évaluation intégrés pour que l'agent les développe.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Génère un ensemble de données d'évaluation à partir de mon schéma."
- "Voici une question initiale et une requête SQL. Développe-les pour obtenir un ensemble de données plus large et vérifie que les requêtes s'exécutent."
Générer un ensemble de contexte de référence
Pour éviter de créer un contexte à partir de zéro, vous pouvez laisser l'agent dériver un ensemble de contexte initial à partir de votre schéma de base de données et des artefacts d'application, tels que les règles métier, les exemples de requêtes ou les fichiers README. Bien que ce contexte de référence ne soit pas définitif, il fournit un point de départ validé basé sur votre modèle de base de données.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Génère un ensemble de contexte à partir de mon schéma."
- "Génère le contexte initial à l'aide de ces schémas et des règles métier dans
requirements.md."
L'agent vous invite à nommer l'expérience, ce qui permet d'organiser les artefacts générés. Il peut également vous demander de préciser le champ d'application si le schéma de votre base de données est volumineux. Pour importer le contexte à l'aide de Cloud SQL Studio, suivez les instructions une fois que l'agent a généré le fichier JSON.
Évaluer l'efficacité du contexte
Une fois que vous avez établi un ensemble de contexte et un ensemble de données de référence, vous pouvez laisser l'agent mesurer les performances du contexte en interrogeant l'API QueryData de votre agent de données avec chaque question de référence. L'agent compare le code SQL généré et ses résultats d'exécution à la réponse attendue à l'aide d'Evalbench pour gérer la comparaison.
L'exécution d'une évaluation fournit les éléments suivants :
- Métriques quantitatives, telles que les résultats de réussite et d'échec, et les scores agrégés, pour suivre la progression des itérations de contexte.
- Un récapitulatif de conversation intégré et des rapports CSV détaillés écrits dans le répertoire
eval_reports/de votre dossier de test.
Pour lancer une évaluation, indiquez le chemin d'accès à l'ensemble de données de référence et l'ID de l'ensemble de contexte. Pour savoir comment trouver l'ID de l'ensemble de contexte, consultez Trouver l'ID de contexte de l'agent.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Évalue mon contexte par rapport à
golden.json." - "Relance l'évaluation en utilisant la configuration de mon dernier test."
Pour réexécuter une configuration d'évaluation générée précédemment sans la configurer à nouveau, demandez à l'agent ou appelez directement la CLI :
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Pour en savoir plus sur le schéma de configuration de l'évaluation et sur la personnalisation des exécutions d'évaluation, consultez la documentation Evalbench.
Effectuer une analyse des écarts et proposer des améliorations
Pour résoudre les échecs de requêtes, vous devez identifier leurs causes profondes, telles que des colonnes incorrectes, des jointures de tables manquantes ou des termes approximatifs non résolus. L'identification manuelle de ces problèmes nécessite une analyse approfondie des rapports d'évaluation.
L'agent automatise cette boucle d'analyse et de correction :
- Analyse des écarts : l'agent lit les résultats de l'évaluation et votre contexte défini pour regrouper les échecs similaires et recommander des ajouts de contexte ciblés, tels que des modèles, des facettes ou des recherches de valeurs.
- Corrections proposées : l'agent propose des modifications concrètes et teste éventuellement le code SQL par rapport à votre base de données pour vérifier la résolution.
- Préservation de la référence : l'agent écrit les améliorations dans un nouveau fichier JSON à côté de votre contexte de référence, en conservant les fichiers d'origine.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Effectue une analyse des écarts sur ma dernière évaluation et propose des corrections."
- "Optimise cet ensemble de contexte par rapport à
golden.json."
Pour préparer la prochaine itération, importez le contexte amélioré dans l'ensemble de contexte cible à l'aide de Data Agents Studio. Pour ce faire, suivez les instructions.
Éléments de contexte spécifiques à l'auteur à la demande
Si vous connaissez déjà le contexte requis, comme un modèle pour une question spécifique, un facette pour un filtre répété ou une recherche de valeur pour une colonne particulière, l'écriture manuelle du JSON de contexte peut entraîner des erreurs de sérialisation dans les noms de paramètres, les métadonnées de type ou la syntaxe de fragment. L'agent gère la mise en forme JSON pour vous permettre de vous concentrer sur votre intention commerciale.
Vous pouvez également utiliser cette fonctionnalité pour des mises à jour ponctuelles, par exemple lorsque vous devez prendre en charge un nouveau modèle de requête ou corriger un détail de schéma manquant. Pour obtenir le fichier JSON, décrivez le contexte requis à l'agent sans exécuter d'évaluation ni configurer de test.
C'est également la bonne capacité à utiliser lorsque vous êtes confronté à une tâche ponctuelle : un partenaire vous donne une nouvelle paire question-SQL qu'il souhaite prendre en charge, ou vous repérez une facette manquante lors d'une revue de code. Vous n'avez pas besoin de configurer un test ni d'exécuter une évaluation pour résoudre ce problème. Décrivez ce que vous voulez, et l'agent génère le fichier JSON.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Crée un modèle pour : 'Quels aéroports se trouvent en Californie ?' avec SQL :
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'." - "Crée un facette pour le filtre
departure_time BETWEEN '00:00:00' AND '06:00:00'intitulé "yeux rouges"." - "Crée une recherche de valeur pour
airports.iata."
Raison du choix du type de contexte
Sélectionner le bon type de contexte, qu'il s'agisse d'une recherche de modèle, de facette ou de valeur, permet d'éviter le gonflement du contexte et les régressions des requêtes de base de données. Par exemple, l'utilisation d'un modèle au lieu d'un facette peut entraîner des règles en double, tandis que les recherches de valeurs introduites lorsqu'un modèle est suffisant peuvent augmenter la latence des requêtes. Pour trouver le format de schéma approprié, demandez à l'agent de recommander un type en fonction de la structure de la requête ou des colonnes de la base de données avant de créer des éléments de contexte. L'agent explique son raisonnement pour vous aider à comprendre les options de contexte.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "J'écris sans cesse le filtre
departure_time BETWEEN '00:00:00' AND '06:00:00'dans de nombreuses requêtes. Quelle est la meilleure façon de capturer cela ?" - "Les utilisateurs décrivent l'état des vols en texte libre et je souhaite les faire correspondre à
flights.status. Quel type de recherche de valeurs dois-je configurer ?" - "Quelle est la différence entre un modèle et un facette, et quand dois-je utiliser chacun d'eux ?"
Appliquer des opérations groupées à un ensemble de contexte
L'agent est compatible avec les mises à jour groupées pour gérer de grands ensembles de contexte de manière cohérente. Si vous devez mettre à jour plusieurs éléments de contexte simultanément (par exemple, lorsqu'une colonne de base de données est renommée, qu'une valeur de code change de format ou que des modèles font référence à une table obsolète), l'agent peut appliquer la modification à tous les éléments concernés sans altérer les entrées non liées.
Vous pouvez utiliser les exemples de requêtes suivants pour donner des instructions à l'agent :
- "Lis
golden.txtet transforme toutes les paires en modèles." - Dans
context_set.json, remplacezairline = 'UA'parairline = 'United Airlines'pour tout élément faisant référence à "United". Ne touchez pas aux éléments sans rapport."
Étapes suivantes
- En savoir plus sur les ensembles de contexte
- Découvrez comment créer ou supprimer un ensemble de contexte dans Cloud SQL Studio.
- Découvrez comment tester un ensemble de contexte.