
Questo documento descrive come creare e ottimizzare i set di contesti che aiutano a ottenere un'elevata accuratezza delle query QueryData nelle applicazioni dell'agente di dati. L'agente di progettazione del contesto ti aiuta a creare, valutare e migliorare i set di contesti automatizzando la loro creazione e ottimizzazione.
Per scoprire di più sui set di contesti e su QueryData, consulta le panoramiche dei set di contesti e di QueryData.Per creare applicazioni di dati di livello aziendale, l'accuratezza del modello da testo a SQL deve in genere raggiungere una qualità prossima al 100%. I risultati delle query errati influiscono sull'usabilità complessiva dell'applicazione e sull'esperienza utente. Per ottenere risposte spiegabili e pertinenti per l'attività con elevata accuratezza, è necessaria la progettazione del contesto, ovvero il processo di creazione e ottimizzazione iterativa del contesto per ottenere un'accuratezza ottimale.
Fornendo a QueryData il contesto mirato all'applicazione aziendale, fornisci le regole di business precise di cui il sistema ha bisogno per risolvere l'intento utente sfumato.
Agente di progettazione del contesto
L'agente di progettazione del contesto automatizza questo workflow di ottimizzazione. Puoi conversare con l'agente per gestire le attività ad hoc per ottimizzare il contesto. Il seguente elenco fornisce esempi di prompt in linguaggio naturale che puoi utilizzare per dare istruzioni all'agente, insieme a una descrizione di come risponde l'agente. Utilizza questi esempi per creare e ottimizzare il contesto:
- Esempio di prompt per l'analisi degli errori: "Aggiorna il contesto in modo da identificare correttamente l'aeroporto per query come 'voli per Disney World'." L'agente analizza l'errore, ragiona sul divario e consiglia di aggiungere un elemento di contesto appropriato, ad esempio una query di ricerca di valori.
- Esempio di prompt per il suggerimento di contesto: "Leggi il codice della mia app e suggerisci alcuni contesti da aggiungere." L'agente analizza il codice, ragiona sul dominio dell'applicazione e suggerisce gli elementi di contesto pertinenti.
- Esempio di prompt per l'elaborazione collettiva: "Ecco 10 esempi di domande e query SQL. Trasformali in modelli." L'agente elabora collettivamente gli input e aggiorna il set di contesti.
Importanza del set di dati di riferimento
Per ottimizzare il contesto, devi prima creare un set di dati che corrisponda agli input in linguaggio naturale della tua applicazione. L'agente può aiutarti a creare questo set di dati di riferimento, costituito da domande degli utenti e dalle query di database previste. Un set di dati di riferimento ti consente di:
- Stabilire una baseline per il rendimento delle query.
- Convalidare gli aggiornamenti rispetto alle query di database di riferimento.
- Misurare i miglioramenti dell'accuratezza nelle iterazioni.
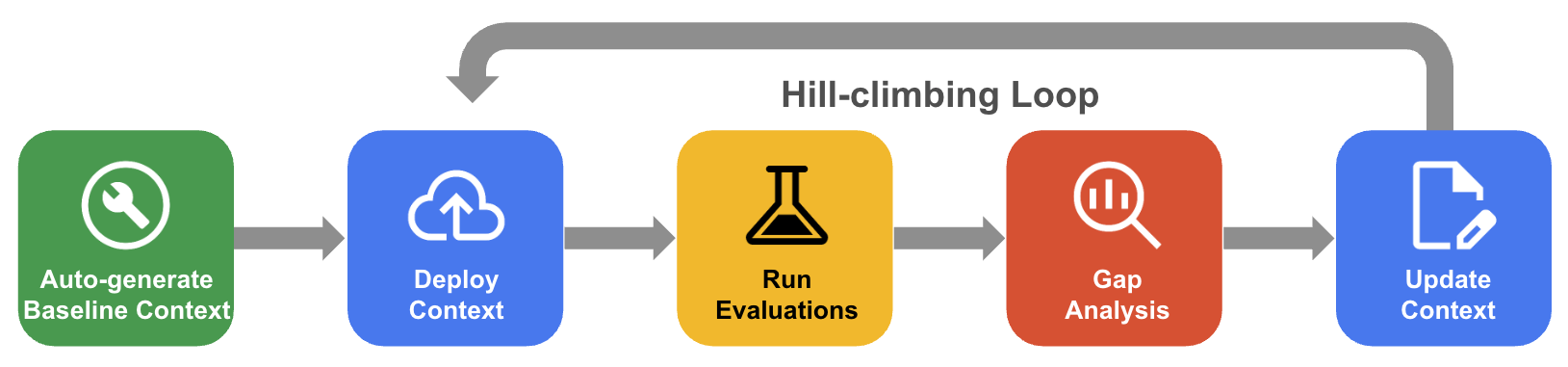
Il processo sistematico di hill climbing
Nell'hill climbing sistematico, l'agente migliora in modo iterativo un set di contesti tramite la valutazione del set di dati di riferimento, l'analisi del divario e gli aggiornamenti per portare l'accuratezza a un valore prossimo al 100%.
- Genera automaticamente il contesto di base: crea un set di contesti iniziale derivato dallo schema del database e dagli artefatti dell'applicazione.
- Workflow di ottimizzazione dell'hill climbing: consenti all'agente di valutare l'accuratezza di QueryData, eseguire l'analisi del divario sugli errori e proporre automaticamente miglioramenti per aumentare l'accuratezza.
Il seguente diagramma mostra il workflow di hill climbing sistematico:
Prima di iniziare
Completa i seguenti prerequisiti prima di utilizzare l'agente di progettazione del contesto.
Abilita i servizi richiesti
Abilita i seguenti servizi per il tuo progetto:Prepara un cluster, un'istanza e un database AlloyDB per PostgreSQL
Assicurati di avere accesso a un cluster e a un'istanza AlloyDB esistenti o creane uno nuovo.Questo tutorial richiede che tu abbia un database nell'istanza AlloyDB. Per ulteriori informazioni, consulta la sezione Creare un database.
Ruoli e autorizzazioni richiesti
- Aggiungi un utente o un account di servizio Identity and Access Management (IAM) al cluster a livello di database. Per ulteriori informazioni, consulta la sezione Gestire gli utenti del database.
- Concedi i ruoli
alloydb.databaseUser,serviceusage.serviceUsageConsumeregeminidataanalytics.queryDataUserall'utente IAM a livello di progetto. Per ulteriori informazioni, consulta la sezione Aggiungere un binding dei criteri IAM per un progetto.
Concedi l'autorizzazione executesql all'istanza AlloyDB per PostgreSQL
Per concedere l'autorizzazione executesql all'istanza AlloyDB per PostgreSQL e impostare l'impostazione dell'istanza data_api_access sul valore ALLOW_DATA_API, utilizza il seguente comando curl :
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://alloydb.googleapis.com/v1alpha/projects/PROJECT_ID/locations/LOCATION/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=dataApiAccess \
-d '{
"dataApiAccess": "ENABLED",
}'
PROJECT_ID: l'ID del tuo Google Cloud progetto.LOCATION: la regione in cui si trova il cluster AlloyDB.CLUSTER_ID: l'ID del cluster AlloyDB.INSTANCE_ID: l'ID dell'istanza AlloyDB.
Prepara l'ambiente
Puoi creare file di set di contesti da qualsiasi ambiente di sviluppo locale o IDE. Per preparare l'ambiente, completa i seguenti passaggi:
- Installa l'agente di progettazione del contesto
- Configura la connessione al database
Installa l'agente di progettazione del contesto
L'agente di progettazione del contesto esegue il server Model Context Protocol (MCP) che richiede uv per gestire i pacchetti Python sottostanti.
Installa
uvseguendo le istruzioni riportate in Installareuv.Verifica che
uvsia installato e accessibile dalla riga di comando:uv --version
Per preparare l'ambiente, installa l'agente di progettazione del contesto nell'infrastruttura agentica selezionata, ad esempio Antigravity CLI, Claude Code o Gemini CLI.
A seconda dell'interfaccia dell'agente selezionata, segui i passaggi di installazione corrispondenti:
Antigravity CLI
Per installare l'agente di progettazione del contesto in Antigravity CLI:
- Installa Antigravity CLI. Consulta la sezione Introduzione ad Antigravity CLI.
- Installa il plug-in dell'agente di progettazione del contesto, che include i workflow per la generazione del contesto. Sostituisci VERSION con la versione rilasciata richiesta:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Avvia Antigravity CLI:
agy
- (Facoltativo) Aggiorna il plug-in: Aggiorna il plug-in:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Per installare l'agente di progettazione del contesto in Claude Code:
- Aggiungi il marketplace dei plug-in:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Installa il plug-in:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Ricarica i plug-in per attivare le modifiche:
/reload-plugins
- (Facoltativo) Aggiorna il plug-in: Aggiorna il plug-in:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (ritirato)
Per installare l'agente di progettazione del contesto in Gemini CLI:
- Installa Gemini CLI. Consulta la sezione Introduzione a Gemini CLI.
- Installa l'estensione:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- (Facoltativo) Aggiorna l'estensione: Aggiorna l'estensione:
gemini extensions update mcp-db-context-enrichment
Configura la connessione al database
L'agente richiede una connessione al database per recuperare gli schemi e la possibilità di convalidare la sintassi del contesto SQL generato. Per consentire all'agente di interagire con il database, configura le credenziali di autenticazione e definisci la configurazione della connessione al database.
Configura le Credenziali predefinite dell'applicazione
Configura le Credenziali predefinite dell'applicazione (ADC) per fornire le credenziali utente per l'accesso alle Google Cloud risorse dall' agente di progettazione del contesto:
- Server MCP Toolbox: utilizza le credenziali per connettersi al database, recuperare gli schemi ed eseguire SQL per la convalida.
- Evalbench: utilizza le credenziali per richiamare QueryData per la valutazione.
Esegui i seguenti comandi nel terminale per autenticarti:
gcloud auth application-default loginConfigura il file di connessione al database
L'agente richiede una connessione al database per la generazione del contesto, che il MCP Toolbox supporta e definisce all'interno di un file di configurazione.
Il file di configurazione specifica l'origine del database e gli strumenti necessari per recuperare gli schemi o eseguire SQL. L'agente di progettazione del contesto viene fornito con le competenze dell'agente preinstallate per aiutarti a generare la configurazione.
Avvia l'ambiente dell'agente.
Chiedi all'agente di aiutarti a configurare la connessione al database, ad esempio con il prompt "help me set up the database connection". Segui le istruzioni dell'agente per creare il file di configurazione nella directory di lavoro corrente come
autoctx/tools.yaml.Per applicare la nuova configurazione
tools.yaml, ricarica la connessione:- In Antigravity CLI, esegui
/mcpe selezionatoolboxper riavviare. - In Gemini CLI, esegui
/mcp reload. - In Claude Code, esegui
/mcp, selezionatoolboxe poiReconnect.
- In Antigravity CLI, esegui
Per ulteriori informazioni sulla configurazione manuale del file di configurazione del database, consulta la sezione Configurazione di MCP Toolbox.
Genera e ottimizza il contesto
L'agente di progettazione del contesto fornisce un insieme di competenze dell'agente e strumenti MCP per migliorare la capacità di progettazione del contesto dell'agente di programmazione. Puoi utilizzare questi strumenti insieme per generare una baseline, misurare l'efficacia e applicare in modo iterativo i miglioramenti. Tuttavia, puoi iniziare in qualsiasi fase del workflow:
- Se hai già un set di contesti, puoi procedere direttamente alla valutazione.
- Se hai query non riuscite che vuoi correggere, puoi procedere direttamente all'analisi del divario.
Ogni funzionalità descrive le azioni, i casi d'uso e i comandi di chiamata dell'agente.
I prompt di esempio mostrano come puoi eseguire query sull'agente in linguaggio naturale. Se l'agente richiede ulteriori dettagli per completare una richiesta, ti chiede chiarimenti.
Crea ed espandi i set di dati di valutazione
Per migliorare il rendimento, devi prima misurarlo. La progettazione del contesto senza un set di dati di riferimento, costituito da domande degli utenti abbinate al codice SQL previsto, non dispone di una verifica sistematica. Con un set di dati di riferimento, ogni modifica è un miglioramento misurabile che puoi convalidare rispetto alla verità di base.
La creazione manuale di un set di dati di riferimento rappresentativo richiede molto tempo e i set di dati di piccole dimensioni potrebbero non includere le variazioni nella formulazione degli utenti. L'agente risolve questo problema:
- Generando coppie domanda-SQL candidate in base allo schema del database.
- Espandendo un piccolo set di dati iniziali utilizzando variazioni di filtri, sinonimi e riformulazioni.
(Facoltativo) Puoi consentire all'agente di eseguire il codice SQL generato sul database. Questa verifica conferma che le query vengono eseguite correttamente prima di aggiungerle al set di dati.
Il set di dati è un file JSON contenente coppie domanda-SQL:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Le coppie approvate vengono inserite nel file autoctx/golden.json nel workspace, dove sono pronte per la valutazione. Puoi fornire un file esistente o scrivere alcuni esempi di valutazione in linea per l'espansione dell'agente.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Genera un set di dati di valutazione dal mio schema."
- "Ecco una domanda iniziale e un codice SQL: espandili in un set di dati più ampio e verifica che le query vengano eseguite."
Genera un set di contesti di base
Per evitare di creare il contesto da zero, puoi consentire all'agente di derivare un set di contesti iniziale dallo schema del database e dagli artefatti dell'applicazione, come regole di business, query di esempio o file README. Sebbene questo contesto di base non sia definitivo, fornisce un punto di partenza convalidato basato sul modello di database.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Genera un set di contesti dal mio schema."
- "Genera il contesto iniziale utilizzando questi schemi e le regole di business in
requirements.md."
L'agente ti chiede di assegnare un nome all'esperimento, che organizza gli artefatti generati, e potrebbe chiederti di restringere l'ambito se lo schema del database è di grandi dimensioni. Per caricare il contesto utilizzando AlloyDB Studio, segui le istruzioni dopo che l'agente ha generato il file JSON.
Valuta l'efficacia del contesto
Dopo aver stabilito un set di contesti e un set di dati di riferimento, puoi consentire all'agente di misurare il rendimento del contesto eseguendo query sull'API QueryData dell'agente di dati con ogni domanda di riferimento. L'agente confronta il codice SQL generato e i relativi risultati di esecuzione con la risposta prevista utilizzando Evalbench per gestire il confronto.
L'esecuzione di una valutazione fornisce quanto segue:
- Metriche quantitative, come risultati di superamento e non superamento e punteggi aggregati, per monitorare i progressi nelle iterazioni del contesto.
- Un riepilogo della conversazione in linea e report CSV dettagliati scritti nella directory
eval_reports/nella cartella dell'esperimento.
Per avviare una valutazione, fornisci il percorso del set di dati di riferimento e l'ID del set di contesti. Per scoprire come trovare l'ID del set di contesti, consulta la sezione Trovare l'ID del contesto dell'agente.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Valuta il mio contesto rispetto a
golden.json." - "Esegui di nuovo la valutazione utilizzando la configurazione dell'ultimo esperimento."
Per eseguire di nuovo una configurazione di valutazione generata in precedenza senza configurarla di nuovo, chiedi all'agente o richiama direttamente l'interfaccia a riga di comando:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Per informazioni dettagliate sullo schema di configurazione della valutazione e su come personalizzare le esecuzioni della valutazione, consulta la documentazione di Evalbench.
Esegui l'analisi del divario e proponi miglioramenti
Per risolvere gli errori delle query, devi identificarne le cause principali, ad esempio colonne errate, join di tabelle mancanti o termini fuzzy non risolti. L'identificazione manuale di questi problemi richiede un'analisi approfondita dei report di valutazione.
L'agente automatizza questo ciclo di analisi e correzione:
- Analisi del divario: l'agente legge i risultati della valutazione e il set di contesti per raggruppare errori simili e consiglia aggiunte di contesto mirate, come modelli, facet o ricerche di valori.
- Correzioni proposte: l'agente propone modifiche concrete e, facoltativamente, testa il codice SQL sul database per verificare la risoluzione.
- Conservazione della baseline: l'agente scrive i miglioramenti in un nuovo file JSON insieme al contesto di base, conservando i file originali.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Esegui l'analisi del divario sull'ultima valutazione e proponi correzioni."
- "Ottimizza questo set di contesti rispetto a
golden.json."
Per prepararti all'iterazione successiva, carica il contesto migliorato nel set di contesti di destinazione utilizzando Data Agents Studio, segui le istruzioni.
Crea elementi di contesto specifici su richiesta
Se conosci già il contesto richiesto, ad esempio un modello per una domanda specifica, un facet per un filtro ripetuto o una ricerca di valori per una colonna specifica, la scrittura manuale del JSON di contesto può introdurre errori di serializzazione nei nomi dei parametri, nei metadati dei tipi o nella sintassi dei frammenti. L'agente gestisce la formattazione JSON per consentirti di concentrarti sull'intento aziendale.
Puoi utilizzare questa funzionalità anche per gli aggiornamenti ad hoc, ad esempio quando devi supportare un nuovo pattern di query o risolvere un dettaglio dello schema mancante. Per ottenere il JSON, descrivi il contesto richiesto all'agente senza eseguire una valutazione o configurare un esperimento.
Questa è anche la funzionalità giusta da utilizzare quando ti viene assegnata un'attività una tantum: una parte interessata ti fornisce una nuova coppia domanda-SQL che vuole supportare oppure noti un facet mancante durante una revisione del codice. Non devi configurare un esperimento o eseguire una valutazione per risolvere il problema: descrivi ciò che vuoi e l'agente produce il JSON.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Crea un modello per: 'Quali aeroporti si trovano in California?' con SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'." - "Crea un facet per il filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'con l'etichetta 'red eye'." - "Crea una ricerca di valori per
airports.iata."
Ragiona sulla selezione del tipo di contesto
La selezione del tipo di contesto corretto, indipendentemente dal fatto che si tratti di un modello, un facet o una ricerca di valori, aiuta a prevenire l'aumento del contesto e le regressioni delle query di database. Ad esempio, l'utilizzo di un modello anziché di un facet può causare regole duplicate, mentre le ricerche di valori introdotte quando un modello è sufficiente possono aumentare la latenza delle query. Per trovare il formato dello schema corretto, chiedi all'agente di consigliare un tipo in base alla struttura della query o alle colonne del database prima di creare gli elementi di contesto. L'agente spiega il suo ragionamento per aiutarti a comprendere le opzioni di contesto.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Continuo a scrivere il filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'in molte query. Qual è il modo migliore per acquisirlo?" - "Gli utenti descrivono lo stato del volo in testo libero e voglio abbinarli a
flights.status. Che tipo di ricerca di valori devo configurare?" - "Qual è la differenza tra un modello e un facet e quando devo utilizzare ciascuno di essi?"
Applica operazioni collettive a un set di contesti
L'agente supporta gli aggiornamenti collettivi per gestire in modo coerente i set di contesti di grandi dimensioni. Se devi aggiornare più elementi di contesto contemporaneamente, ad esempio quando una colonna del database viene rinominata, un valore di codice cambia formato o i modelli fanno riferimento a una tabella ritirata, l'agente può applicare la modifica a ogni elemento interessato senza alterare le voci non correlate.
Puoi utilizzare i seguenti prompt di esempio per dare istruzioni all'agente:
- "Leggi
golden.txte trasforma tutte le coppie in modelli." - "In
context_set.json, sostituisciairline = 'UA'conairline = 'United Airlines'per qualsiasi elemento che faccia riferimento a 'United'. Lascia invariati gli elementi non correlati."
Passaggi successivi
- Scopri di più sui set di contesti.
- Scopri come creare o eliminare un set di contesti in AlloyDB Studio.
- Scopri come testare un set di contesti.