

Découvrez la puissance de la technologie de recherche vectorielle de pointe grâce à la démo interactive Vector Search. Exploitant des ensembles de données réels, la démo fournit un exemple réaliste qui vous aidera à comprendre le fonctionnement de Vector Search, à explorer la recherche sémantique et hybride, et à voir le reclassement en action. Envoyez une brève description d'un animal, d'une plante, d'un produit d'e-commerce ou d'un autre élément, et laissez Vector Search s'occuper du reste !
Essayer
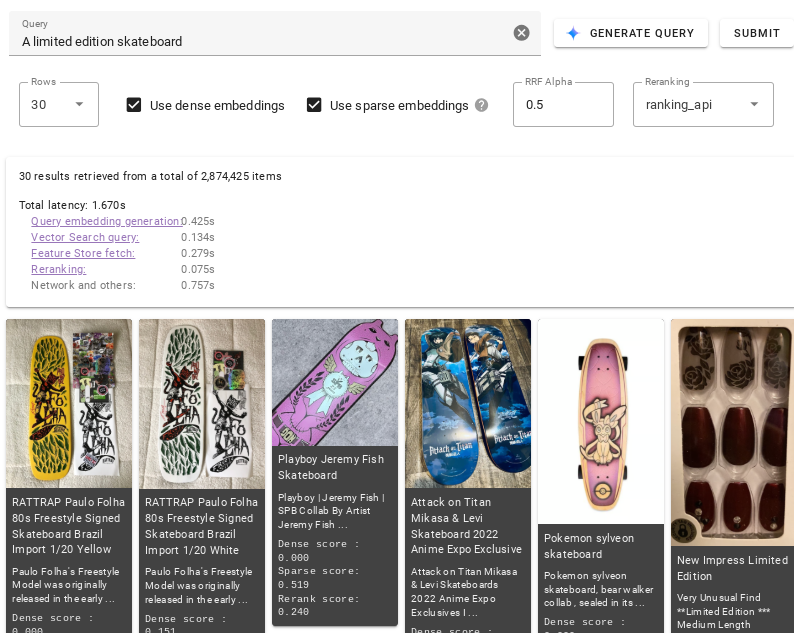
Testez les différentes options de la démo pour vous familiariser avec Vector Search et comprendre les bases de la technologie de recherche vectorielle.
Pour exécuter la démo :
Dans le champ de texte Requête , décrivez les éléments que vous souhaitez interroger (par exemple,
vintage 1970s pinball machine). Vous pouvez également cliquer sur Générer une requête pour générer automatiquement une description.Cliquez sur Envoyer.
Pour en savoir plus sur ce que vous pouvez faire dans la démo, consultez la section Interface utilisateur.
Interface utilisateur
Cette section décrit les paramètres de l'interface utilisateur que vous pouvez utiliser pour contrôler les résultats renvoyés par Vector Search et leur classement.
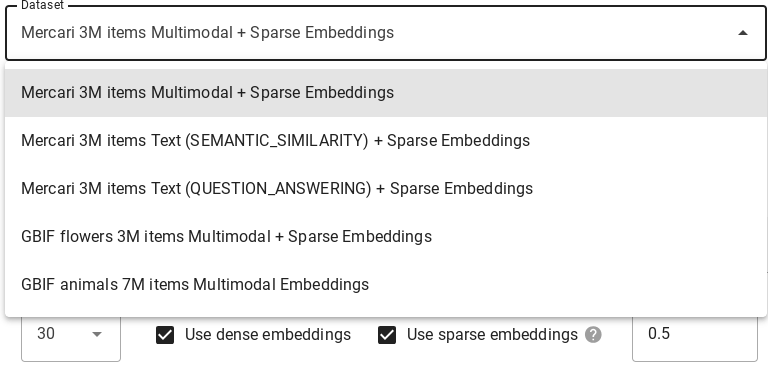
Ensemble de données
Utilisez le menu déroulant Ensemble de données pour choisir l'ensemble de données sur lequel Vector Search exécutera votre requête. Pour en savoir plus sur chacun d'eux, consultez Ensembles de données.
Requête
Dans le champ Requête, ajoutez une description ou un ou plusieurs mots clés pour spécifier les éléments que vous souhaitez que Vector Search trouve. Vous pouvez également cliquer sur Générer une requête pour générer automatiquement une description.

Modifier
Plusieurs options sont disponibles pour modifier les résultats renvoyés par Vector Search :

Cliquez sur Lignes , puis choisissez le nombre maximal de résultats de recherche que vous souhaitez que Vector Search renvoie.
Sélectionnez Utiliser des embeddings denses si vous souhaitez que Vector Search renvoie des résultats sémantiquement similaires.
Sélectionnez Utiliser des embeddings creux si vous souhaitez que Vector Search renvoie des résultats basés sur la syntaxe du texte de votre requête. Tous les ensembles de données disponibles ne sont pas compatibles avec les modèles d'embedding creux.
Sélectionnez à la fois Utiliser des embeddings denses et Utiliser des embeddings creux si vous souhaitez que Vector Search utilise la recherche hybride. Tous les ensembles de données ne sont pas compatibles avec ce modèle. La recherche hybride combine des éléments d'embeddings denses et creux, ce qui peut améliorer la qualité des résultats de recherche. Pour en savoir plus, consultez À propos de la recherche hybride.
Dans le champ RRF Alpha , saisissez une valeur comprise entre 0,0 et 1,0 pour spécifier l'effet de classement RRF.
Pour reclasser les résultats de recherche, sélectionnez ranking_api dans le menu déroulant Reclassement ou sélectionnez Aucun pour désactiver le reclassement.
Métriques
Une fois une requête exécutée, des métriques de latence sont fournies. Elles indiquent la répartition du temps nécessaire pour que les différentes étapes de la recherche se terminent.

Processus de requête
Lorsqu'une requête est traitée, les étapes suivantes se produisent :
Génération d'embeddings de requête : un embedding est généré pour le texte de requête spécifié.
Requête Vector Search : la requête est exécutée avec l'index Vector Search.
Extraction du Feature Store Gemini Enterprise Agent Platform : les caractéristiques (par exemple, le nom de l'article, sa description ou l'URL de son image) sont lues à partir du Feature Store Gemini Enterprise Agent Platform à l'aide de la liste d'ID d'articles renvoyée par Vector Search.
Reclassement : les éléments récupérés sont triés à l'aide d'API de classement qui utilisent le texte de la requête, le nom de l'article et sa description pour calculer le score de pertinence.
Embeddings
Multimodaux : recherche sémantique multimodale sur les images d'articles. Pour en savoir plus, consultez Qu'est-ce que la recherche multimodale : les LLM avec vision modifient les entreprises.
Texte (similarité sémantique) : recherche sémantique de texte sur les noms et descriptions d'articles en fonction de la similarité sémantique. Pour en savoir plus, consultez Agent Platform Embeddings for Text : faciliter l'ancrage des LLM.
Texte (questions-réponses) : recherche sémantique de texte sur les noms et descriptions d'articles, avec une qualité de recherche améliorée par le type de tâche QUESTION_ANSWERING. Cette option est adaptée aux applications de type questions-réponses. Pour en savoir plus sur les embeddings de type de tâche, consultez Améliorer votre cas d'utilisation d'IA générative avec les types de tâches et les embeddings Agent Platform.
Creux (recherche hybride) : recherche par mot clé (basée sur les jetons) sur les noms et descriptions d'articles, générée avec l'algorithme TF-IDF. Pour en savoir plus, consultez À propos de la recherche hybride.
Ensembles de données
La démo interactive inclut plusieurs ensembles de données sur lesquels vous pouvez exécuter des requêtes. Les ensembles de données diffèrent les uns des autres par le modèle d'embedding, la compatibilité avec les embeddings creux, les dimensions d'embedding et le nombre d'éléments stockés.
| Ensemble de données | Modèle d'embedding | Modèle d'embedding creux | Dimensions d'embedding | Nombre d'éléments |
|---|---|---|---|---|
| Mercari Multimodal + Embeddings creux | Embedding multimodal | TF-IDF (nom et description de l'article) |
1408 | ~3 millions |
| Mercari Text (similarité sémantique) + Embeddings creux | text-embedding-005 (Type de tâche : SEMANTIC_SIMILARITY) |
TF-IDF (nom et description de l'article) |
768 | ~3 millions |
| Mercari Text (systèmes de questions-réponses) + Embeddings creux | text-embedding-005 (Type de tâche : QUESTION_ANSWERING) |
TF-IDF (nom et description de l'article) |
768 | ~3 millions |
| GBIF Flowers Multimodal + Embeddings creux | Embedding multimodal | TF-IDF (nom et description de l'article) |
1408 | ~3,3 millions |
| GBIF Animals Embeddings multimodaux | Embedding multimodal | N/A | 1408 | ~7 millions |
Étapes suivantes
Maintenant que vous êtes familiarisé avec la démo, vous êtes prêt à découvrir comment utiliser Vector Search.
Guide de démarrage rapide: utilisez un exemple d'ensemble de données pour créer et déployer un index en 30 minutes ou moins.
Avant de commencer: découvrez comment préparer les embeddings et choisissez le type de point de terminaison sur lequel déployer votre index.