
BigQuery 連接器簡介
BigQuery 連接器可協助您將儲存在 Document AI Warehouse 中的文件中繼資料 (包括屬性) 匯出至 BigQuery 資料表。將資料匯入 BigQuery 後,您就能執行分析、建立報表和資訊主頁,協助您制定業務決策。
如要啟用 BigQuery 連接器,您必須設定 BigQuery 資料表並授予必要權限,然後透過 API 設定非同步工作。BigQuery 連接器會將 Document AI Warehouse 的資料匯出至 BigQuery 資料表。
事前準備
設定 Document AI Warehouse,並擷取文件。詳情請參閱快速入門。
請務必確認託管 BigQuery 資料表的專案,與 Document AI Warehouse 用來儲存文件的專案相同。換句話說,資料一律必須從 Document AI Warehouse 匯出至同一專案中的 BigQuery 資料表。
您必須具備專案的 Owner (roles/owner) 角色,或同時具備 resourcemanager.projects.getIamPolicy 和 resourcemanager.projects.setIamPolicy
」權限。
設定 BigQuery 存取權
繫結服務帳戶 doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
角色:BigQuery Admin
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
設定 BigQuery 資料集和資料表
設定 BigQuery 資料集和資料表,供 Document AI Warehouse 匯出資料。如果沒有 BigQuery 資料集,請按照建立資料集的步驟建立一個。
在 BigQuery 資料集中建立 BigQuery 資料表。按照 BigQuery 指示,使用 DDL 範例陳述式建立資料表:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL 會為您建立新的 BigQuery 資料表。資料表會依小時進行時間分區,分區會在 150 天後刪除。
設定 BigQuery 連接器
建立資料匯出設定
下列操作說明會建立新的資料匯出工作,設定非同步工作來匯出資料。建議您為每項新的資料匯出工作,從空白表格開始。如要瞭解設定詳情,請參閱 API 參考資料。
您可以選擇下列執行方式。您可以使用 FREQUENCY 設定這些屬性。請參閱 API 參考資料。
- ADHOC:工作只會執行一次。所有資料都會匯出至 BigQuery 資料表。
- DAILY:工作每天執行。首次執行時,所有資料都會匯出至 BigQuery 資料表。完成初始匯出作業後,系統只會將前一天的資料變更 (或上次成功同步處理後的差異) 匯出至 BigQuery 資料表。
- HOURLY:工作每小時執行一次。首次執行時,所有資料都會匯出至 BigQuery 資料表。完成初始匯出作業後,系統只會將前一小時的資料變更 (或上次成功同步處理後的差異) 匯出至 BigQuery 資料表。
使用任何要求資料之前,請先修改下列項目的值:
- PROJECT_NUMBER:您的 Google Cloud 專案編號
- LOCATION:Document AI Warehouse 位置 (例如 `us`)
- DATASET_LOCATION:資料集位置
- DATASET_NAME:資料集名稱
- TABLE_NAME:資料表名稱
-
FREQUENCY:
ADHOC、DAILY或HOURLY。
JSON 要求內文:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
工作執行作業
成功建立工作後,系統會根據您的設定執行工作。請注意,由於執行作業需要時間,因此工作會以非同步方式執行。視匯出的資料量而定,第一次執行作業可能需要一段時間才能完成。如果是每日工作,結果最多需要 24 小時才會顯示在 BigQuery 資料表中。
刪除資料匯出設定
下列指令會刪除 (封存) 您建立的工作。
使用任何要求資料之前,請先修改下列項目的值:
- PROJECT_NUMBER:您的 Google Cloud 專案編號
- LOCATION:Document AI Warehouse 位置 (例如 `us`)
- JOB_ID:您在建立工作時,回應中顯示的工作 ID
JSON 要求內文:
{}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
完成後,匯出工作就會遭到刪除 (封存),Document AI Warehouse 不會再執行該工作。
探索擷取至 BigQuery 的資料
如要將文件的中繼資料和屬性擷取至 BigQuery 中不同的資料表欄位,以滿足分析需求,可以使用下列 DDL 查詢範例。您也可以在 Google 數據分析或任何 BI 資訊主頁工具中使用這些擷取的欄位,將資料中的關係視覺化。
從 document_json 擷取重要欄位
這項查詢會從資料匯出內容中選取相關欄位,包括文件元資料中的鍵欄位 (儲存在 document_json 欄位中)。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
從 document_json 取消巢狀結構屬性
這項查詢會從文件中繼資料 (document_json) 取消巢狀結構屬性,建立鍵值配對 (屬性名稱、值)。在下一個查詢中,這些鍵/值組合會轉換為個別資料表欄位,以便探索資源層級的資料,並以資訊主頁呈現。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
從 document_json 樞紐分析屬性,在 BigQuery 中建立資料表欄位
下列程序會建立資料表,並將所有文件屬性轉換為個別資料表欄位,方法是樞紐分析屬性和相關聯的值。您可以運用這個資料表的結果,在數據分析和其他 BI 視覺化工具中,透過後續查詢取得更多洞察資料。
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
資料清理與轉換程序 (特定商業案例)
視載入 BigQuery 的資料而定,您可能需要執行額外的資料清理和轉換程序,才能進一步分析。這類程序會因案例 (資料集) 而異,應視情況執行。
資料清理程序可能包括 (但不限於):
- 統一日期格式。
- 合併屬性值。
- 例如,將資料類型轉換為字串、浮點數和整數。
在數據分析中以視覺化的方式呈現資料
在 BigQuery 中擷取、清除及轉換資料後,即可將最終資料集匯出至數據分析,進行視覺化分析。
Looker 資訊主頁
這些範例資訊主頁展示了可從資料集建立的可能視覺化效果。在這個情境中,從 Document AI Warehouse 匯出的範例資料包含 W2 和發票 (兩種結構定義)。
範例檢視畫面:Document AI 倉儲分析總覽
下列資訊主頁提供高階洞察資料,讓您瞭解 Document AI 倉儲執行個體中擷取的各種文件。
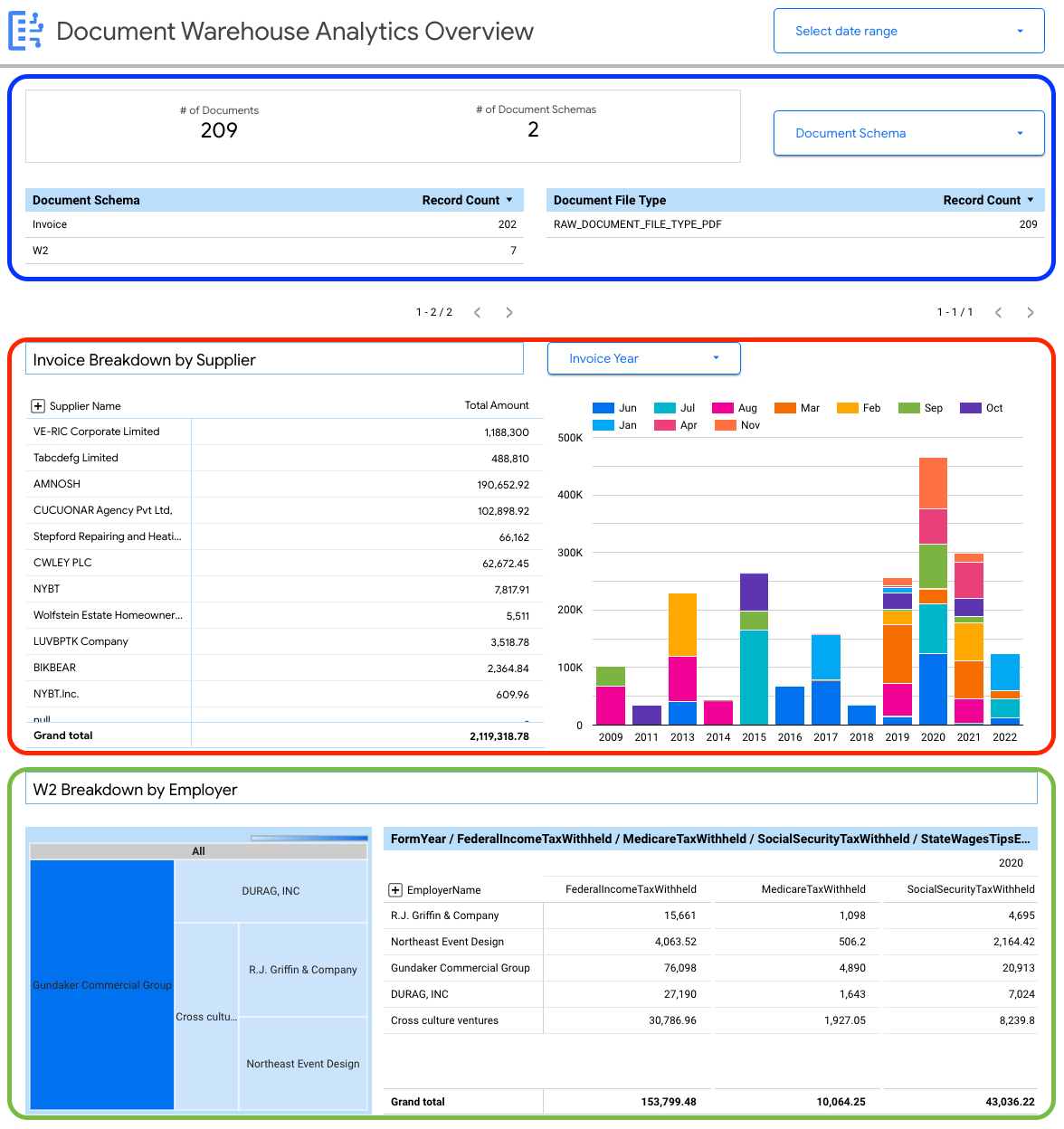
您可以查看文件層級的詳細資料,包括:
- 文件總數。
- 文件結構定義總數。
- 依文件結構定義記錄數量。
- 文件檔案類型 (例如 PDF、文字、未指定類型)。
您也可以使用從文件元資料 (document_json) 擷取的屬性,為擷取至 BigQuery 的發票和 W2 表單建立重要細目。
範例檢視畫面:特定業務洞察資訊主頁 (月結單)
使用者可透過下列資訊主頁,詳細查看單一文件結構定義 (發票),進而取得所有擷取至 Document AI 倉儲的發票洞察資料。
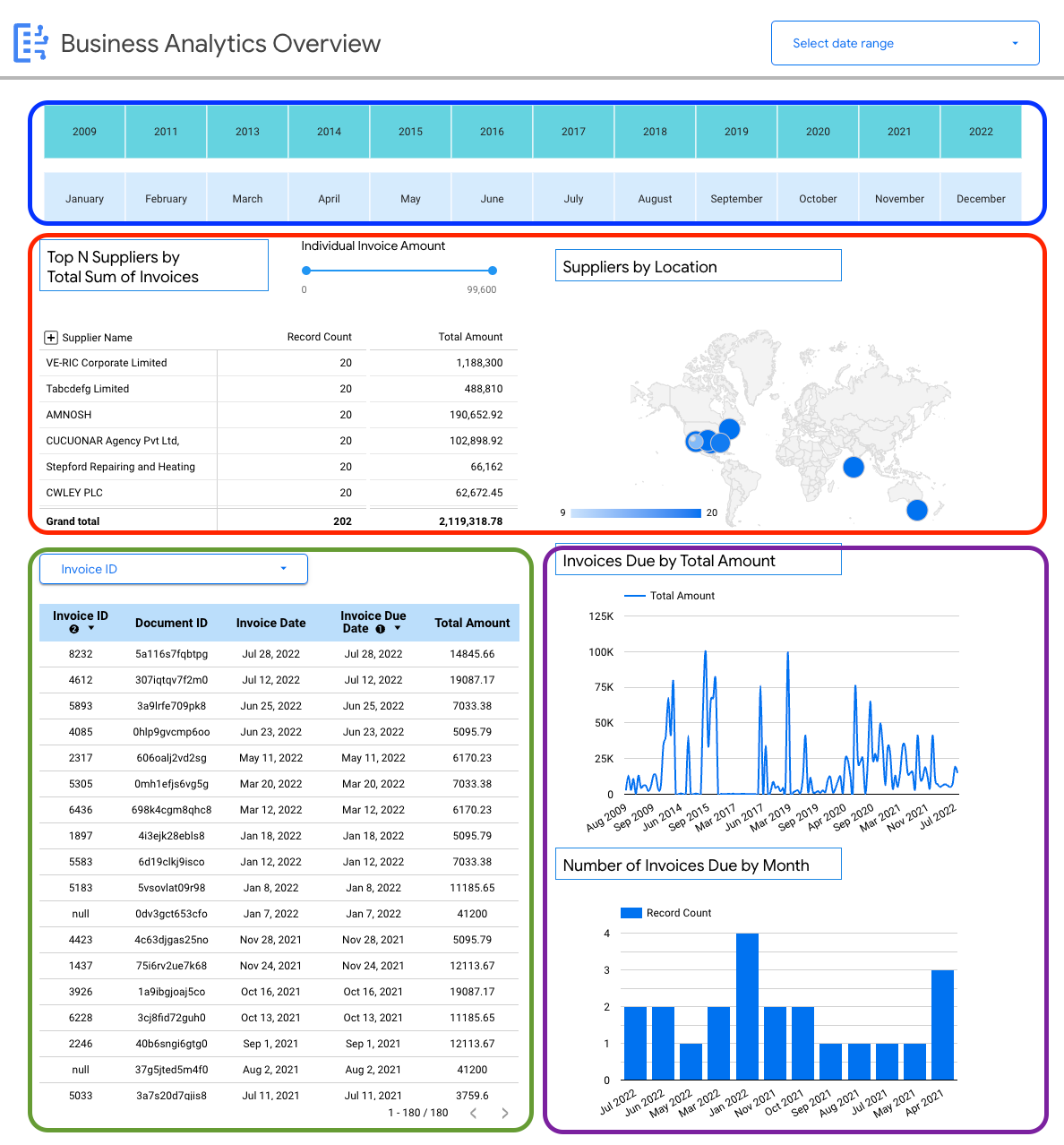
您可以在月結單上查看特定架構的詳細資料,例如:
- 依應付憑據金額排序的頂尖供應商。
- 依地點分類的供應商。
- 月結單日期和對應的付款截止日。
- 以金額和記錄數為準,按月比較月結單的趨勢。
將資料來源連結至資訊主頁
如要使用這些資訊主頁範本做為起點,以視覺化方式呈現資料集,您可以連結 BigQuery 中的資料來源。
將範例資訊主頁連結至 BigQuery 資料來源前,請務必登入與環境相關聯的帳戶 Google Cloud。

選取醒目顯示的按鈕,即可顯示下拉式選單選項。

選取「建立副本」。
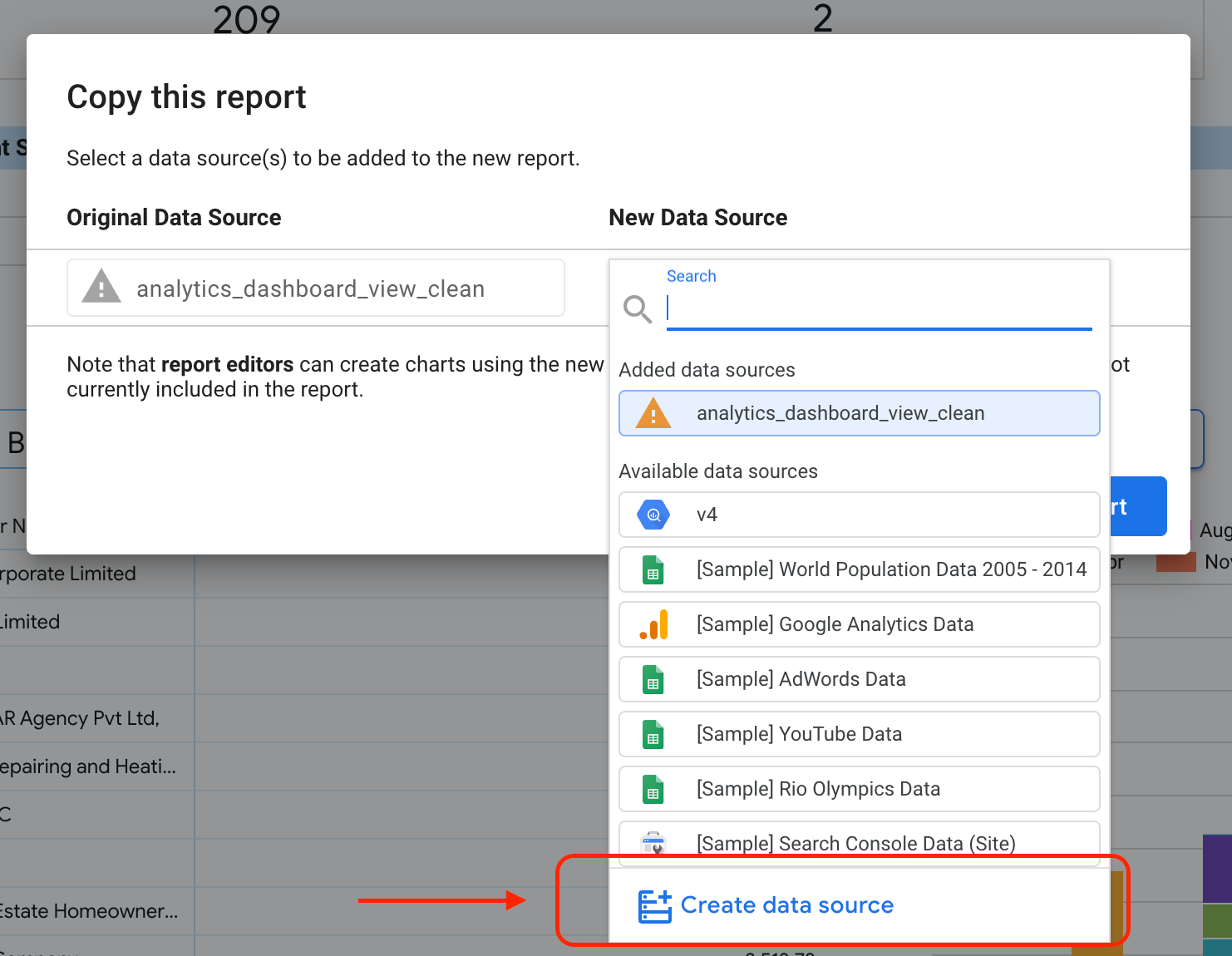
在「新資料來源」子區段下方,選取「建立資料來源」。
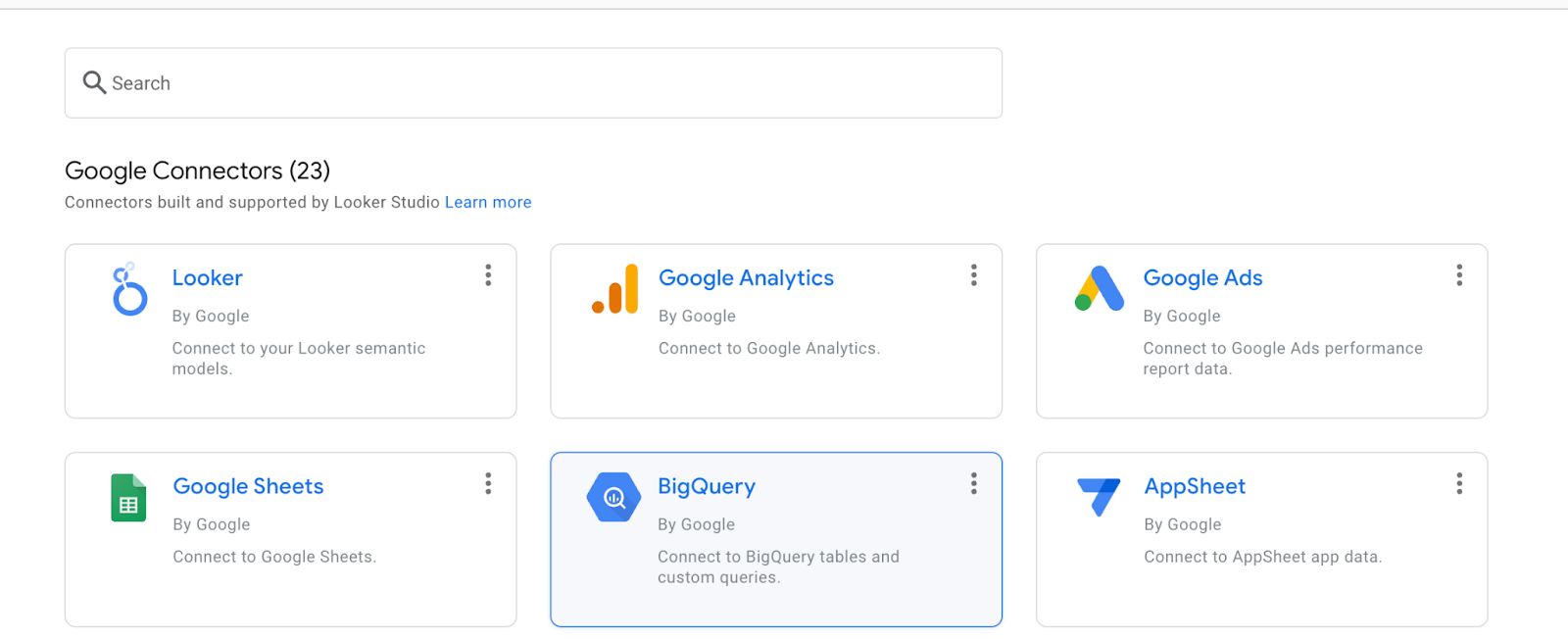
選取 [BigQuery]。
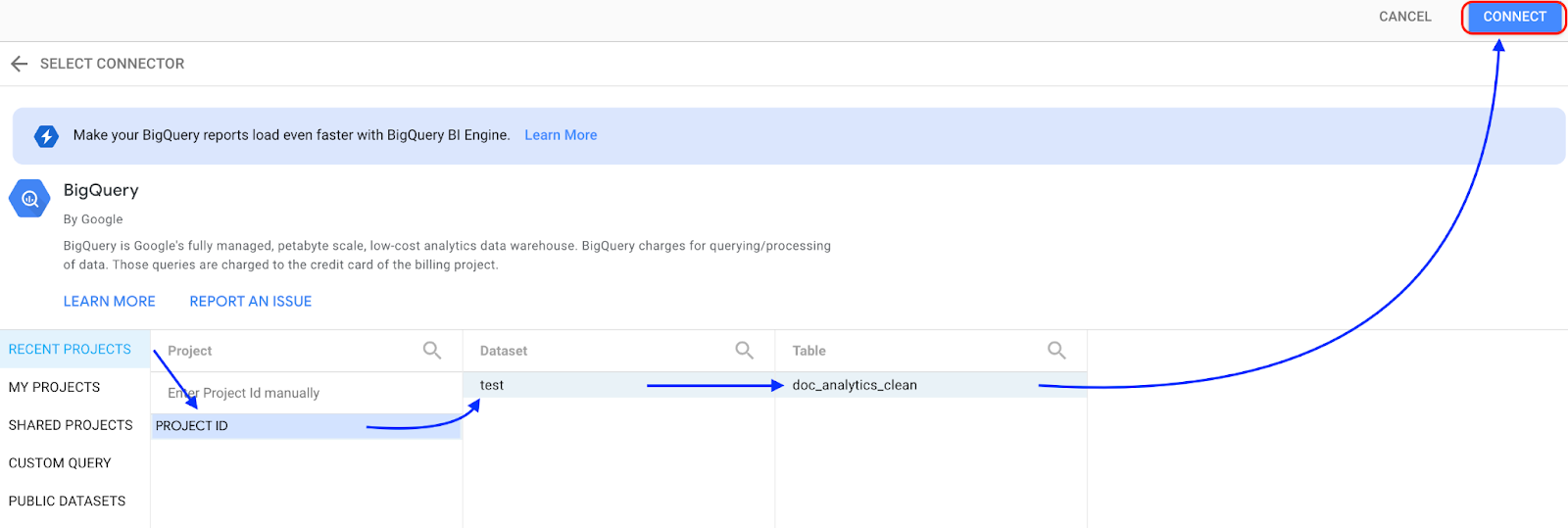
選取儲存資料集的專案,然後按照提示選取資料集和資料表。按一下「連線」。

按一下 [Add to Report] (加入報表)。
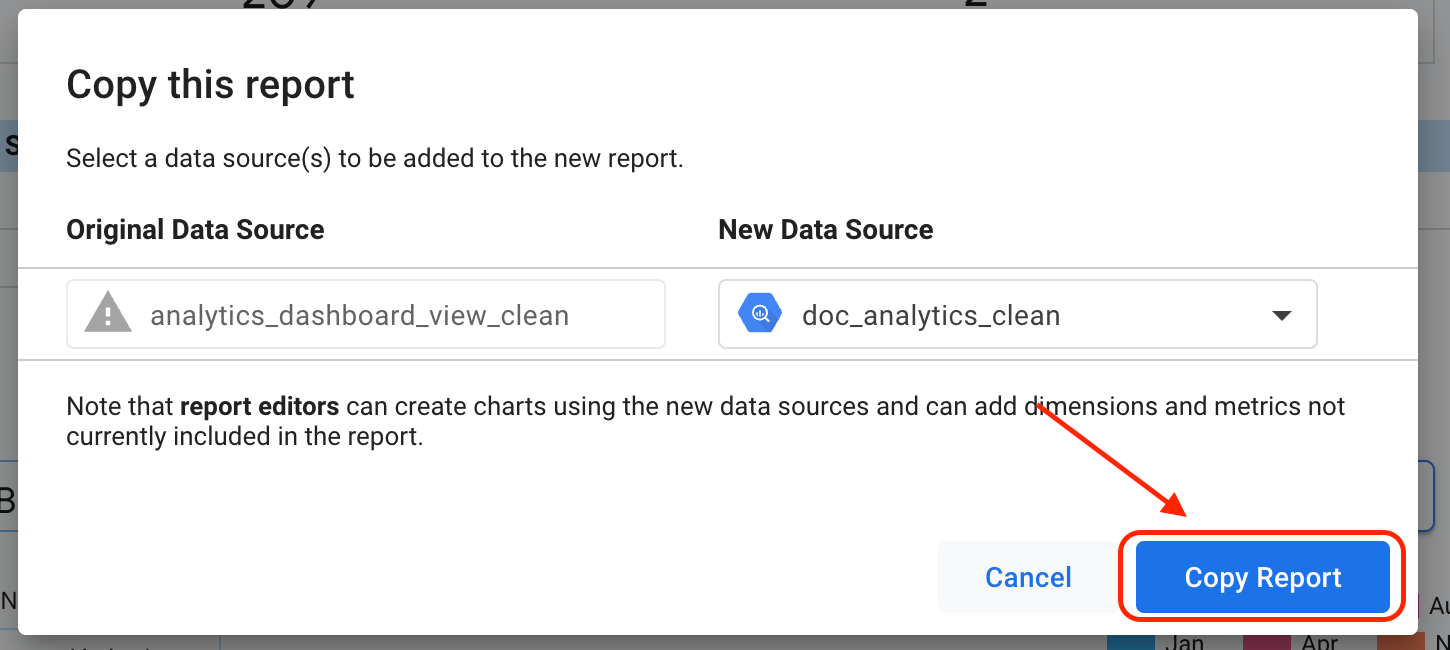
按一下「複製報表」。
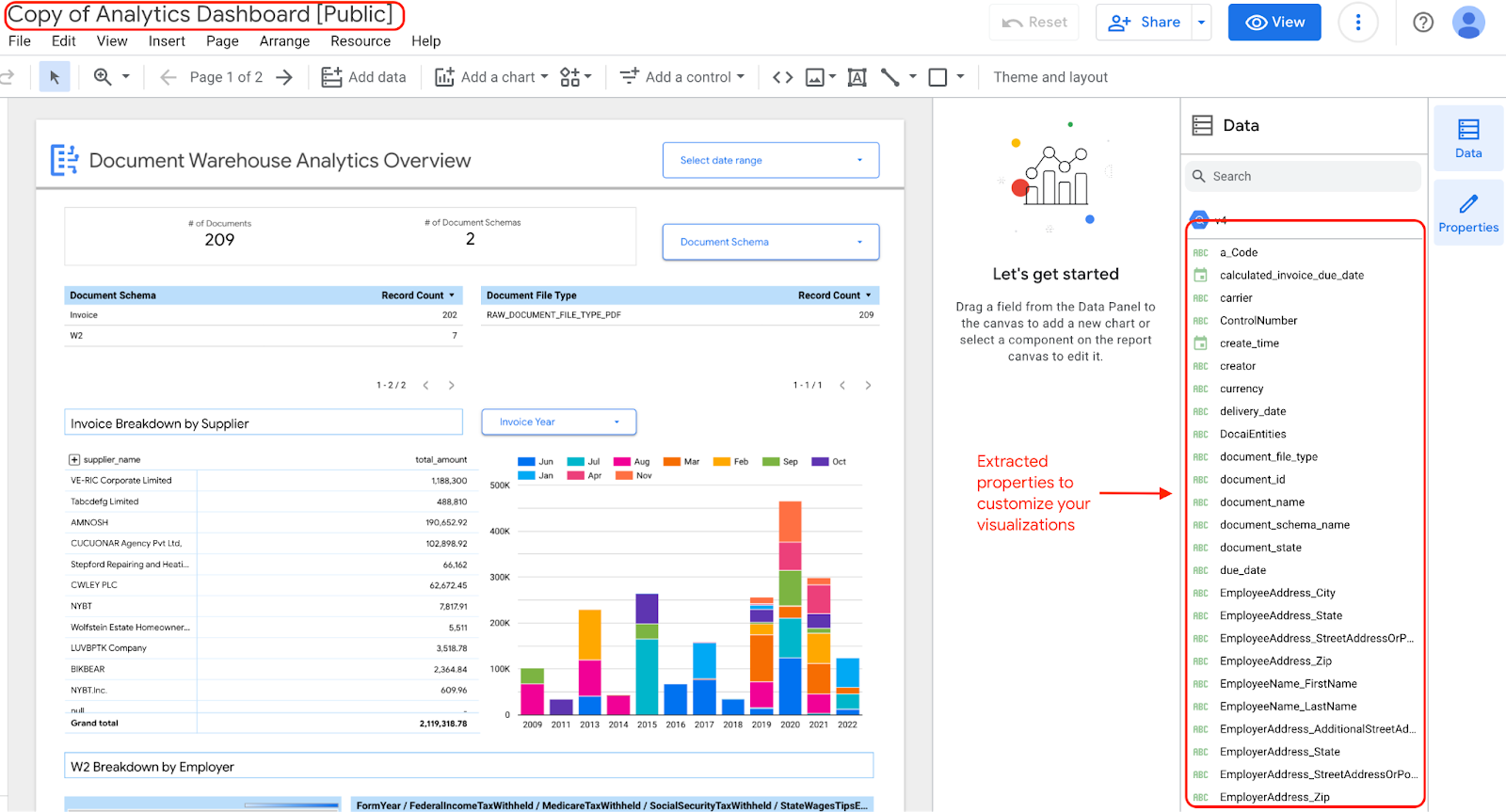
如果您選擇編輯及更新資訊主頁上的小工具,由於您擁有資訊主頁副本和擷取的屬性,因此可以編輯小工具。