
Introdução ao conector do BigQuery
O conector do BigQuery ajuda a exportar os metadados do documento (incluindo propriedades) armazenados no Document AI Warehouse para a sua BigQuery. Com seus dados no BigQuery, você pode executar análises, criar relatórios e painéis para ajudar a tomar decisões de negócios.
Para ativar o conector do BigQuery, é necessário configurar uma tabela do BigQuery com as permissões necessárias e configurar as tarefas assíncronas pela API. O conector do BigQuery exporta os dados do Document AI Warehouse para as tabelas do BigQuery.
Antes de começar
Configure o Document AI Warehouse e ingira seus documentos. Para mais informações, siga o guia de início rápido.
Verifique se o projeto que hospeda a tabela do BigQuery é o mesmo usado pelo Document AI Warehouse para armazenar seus documentos. Em outras palavras, os dados precisam sempre ser exportados do Document AI Warehouse para a tabela do BigQuery no mesmo projeto.
No projeto, você precisa ter o papel Owner (roles/owner) ou as permissões resourcemanager.projects.getIamPolicy e resourcemanager.projects.setIamPolicy.
mais permissões.
Configurar o acesso ao BigQuery
Vincule a conta de serviço doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
ao papel BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
Configurar o conjunto de dados e a tabela do BigQuery
Configure um conjunto de dados e uma tabela do BigQuery para que o Document AI Warehouse exporte os dados. Se você não tiver um conjunto de dados do BigQuery, siga as instruções para criar um.
Crie uma tabela do BigQuery no conjunto de dados do BigQuery. Seguindo as instruções do BigQuery, você cria tabelas com as instruções de exemplo DDL:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
O DDL cria uma nova tabela do BigQuery para você. A tabela é particionada por hora, e a partição é excluída em 150 dias.
Configurar o conector do BigQuery
Criar configuração de exportação de dados
As instruções a seguir criam um novo job de exportação de dados, que configura os jobs assíncronos para exportar dados. Recomendamos começar com uma tabela vazia para cada novo job de exportação de dados. Consulte a referência da API para mais detalhes da configuração.
Você tem as seguintes opções de execução. Elas podem ser configuradas usando FREQUENCY.
Consulte a API
referência.
- ADHOC:o job é executado apenas uma vez. Todos os dados são exportados para a tabela do BigQuery.
- DAILY:o job é executado diariamente. Na primeira execução, todos os dados são exportados para a tabela do BigQuery. Depois que a exportação inicial é concluída, apenas as mudanças de dados do dia anterior (ou o delta da última sincronização bem-sucedida) são exportadas para a tabela do BigQuery.
- HOURLY:o job é executado por hora. Na primeira execução, todos os dados são exportados para a tabela do BigQuery. Depois que a exportação inicial é concluída, apenas as mudanças de dados da hora anterior (ou o delta da última sincronização bem-sucedida) são exportadas para a tabela do BigQuery.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_NUMBER: seu Google Cloud número do projeto
- LOCATION: o local do Document AI Warehouse (como `us`)
- DATASET_LOCATION: o local do conjunto de dados
- DATASET_NAME: o nome do conjunto de dados
- TABLE_NAME: o nome da tabela
-
FREQUENCY: um de
ADHOC,DAILYouHOURLY.
Corpo JSON da solicitação:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
Execução do trabalho
Depois de criar um job, ele será executado com base na sua configuração. Os jobs são executados de forma assíncrona porque levam tempo para serem executados. Dependendo da quantidade de dados a serem exportados, a primeira execução pode levar algum tempo para ser concluída. Para jobs diários, aguarde 24 horas para que os resultados apareçam na tabela do BigQuery.
Excluir configuração de exportação de dados
O comando a seguir exclui (arquivando) um job que você criou.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_NUMBER: seu Google Cloud número do projeto
- LOCATION: o local do Document AI Warehouse (como `us`)
- JOB_ID: o ID do job, na resposta quando você o criou
Corpo JSON da solicitação:
{}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
Depois disso, o job de exportação será excluído (arquivado), e o Document AI Warehouse não o executará mais.
Analisar dados ingeridos no BigQuery
Para extrair metadados e propriedades de documentos em campos de tabela distintos no BigQuery para suas necessidades de análise, use as consultas DDL de exemplo abaixo. Esses campos extraídos também podem ser usados no Data Studio ou em qualquer ferramenta de painel de BI para visualizar relações nos dados.
Extrair campos principais de document_json
Essa consulta seleciona campos relevantes da exportação de dados, incluindo campos principais de metadados de documentos (armazenados no campo document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Descompactar propriedades de document_json
Essa consulta descompacta propriedades dos metadados do documento (document_json) para criar pares de chave-valor (nome da propriedade, valor). Esses pares de chave-valor serão transformados em campos de tabela individuais na próxima consulta para permitir a análise de dados no nível da propriedade e a visualização do painel.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Pivotar propriedades de document_json para criar campos de tabela no BigQuery
Os procedimentos a seguir criam uma tabela com todas as propriedades do documento transformadas como campos de tabela individuais, pivotando as propriedades e os valores associados. Os resultados dessa tabela podem ser usados para gerar mais insights por meio de consultas subsequentes no Data Studio e em outras ferramentas de visualização de BI.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Procedimentos de limpeza e transformação de dados (específicos para casos de uso)
Dependendo dos dados ingeridos no BigQuery, talvez seja necessário realizar outros procedimentos de limpeza e transformação de dados para permitir mais análises. Esses procedimentos variam de caso a caso (conjunto de dados para conjunto de dados) e precisam ser realizados conforme apropriado.
Alguns exemplos de procedimentos de limpeza de dados podem incluir (mas não se limitam a):
- Unificar formatos de data.
- Consolidar valores de propriedade.
- Transmitir tipos de dados para strings, flutuantes e números inteiros, por exemplo.
Visualizar os dados no Data Studio
Depois que os dados forem extraídos, limpos e transformados no BigQuery, o conjunto de dados final poderá ser exportado para o Data Studio para análise visual.
Painéis do Looker
Os painéis de exemplo descritos mostram possíveis visualizações que podem ser criadas no conjunto de dados. Nesse cenário, a exportação de dados de amostra do Document AI Warehouse consiste em W2s e faturas (dois esquemas).
Exemplo de visualização: visão geral da análise do Document AI Warehouse
O painel a seguir oferece uma visão geral da variedade de documentos ingeridos na instância do Document AI Warehouse.
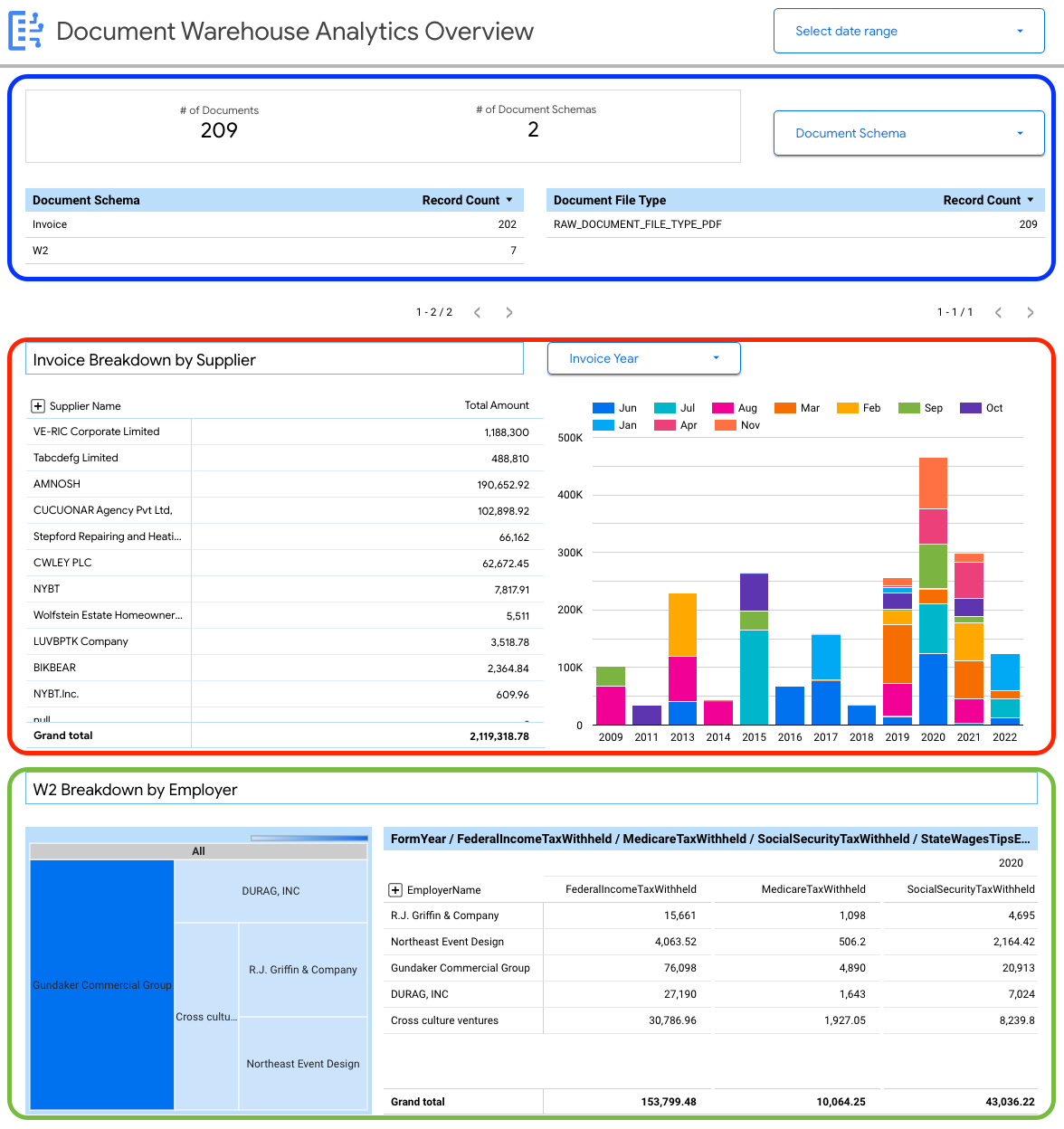
É possível visualizar detalhes no nível do documento, incluindo:
- Número total de documentos.
- Número total de esquemas de documentos.
- Contagem de registros por esquema de documento.
- Tipo de arquivo de documento (como PDF, texto, tipo não especificado).
Você também pode usar as propriedades extraídas dos metadados do documento (document_json) para criar detalhamentos de chave para as faturas e W2s ingeridos no BigQuery.
Exemplo de visualização: painel de insights específicos para empresas (faturas)
O painel a seguir oferece ao usuário uma visão detalhada de um único esquema de documento (faturas) para permitir insights sobre todas as faturas ingeridas no Document AI Warehouse.
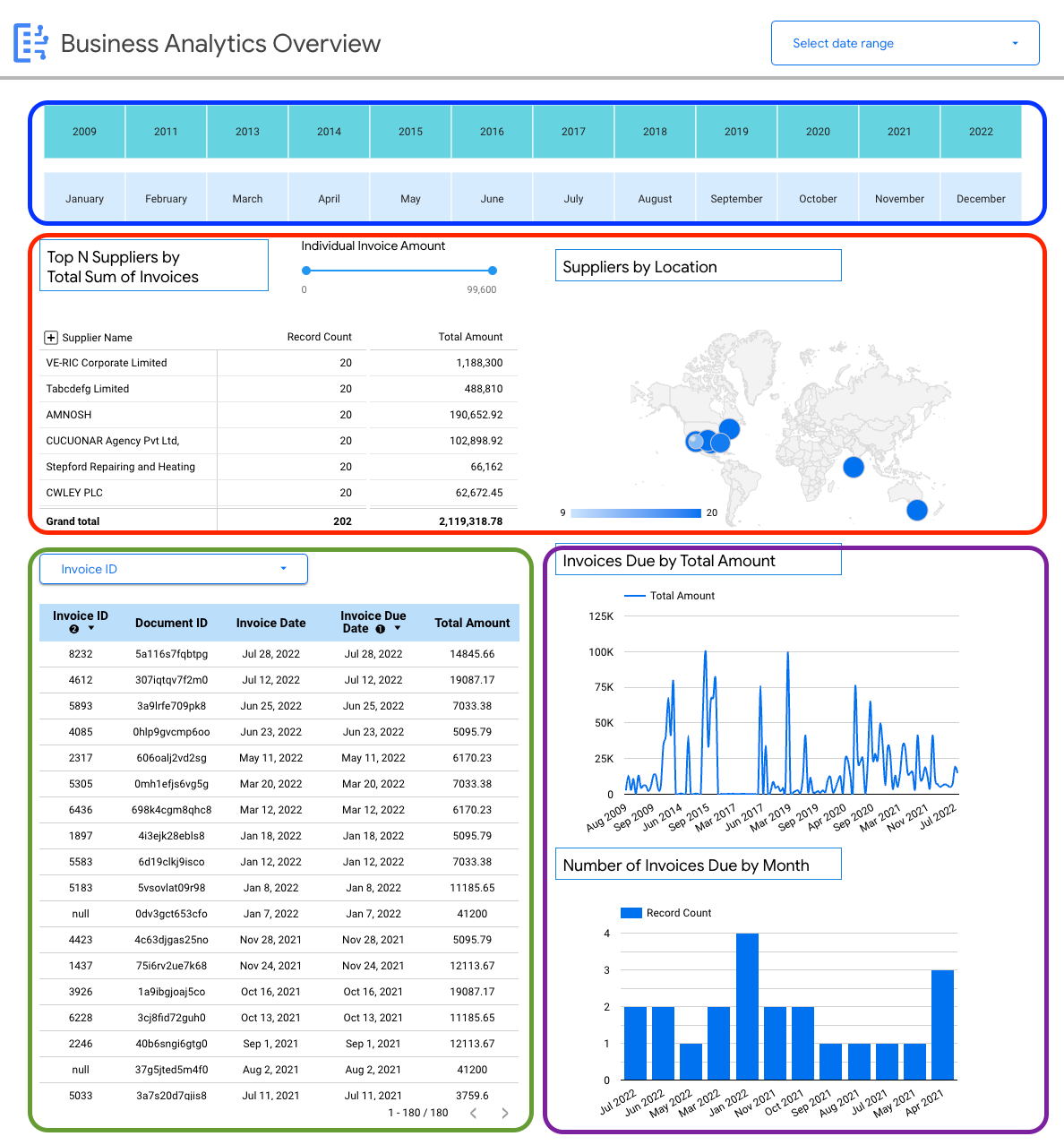
É possível visualizar detalhes específicos do esquema nas faturas, por exemplo:
- Principais fornecedores por valores de faturas.
- Fornecedores por local.
- Datas de faturas e datas de vencimento correspondentes.
- Tendências em faturas mês a mês por valor e contagem de registros.
Conectar a fonte de dados aos painéis
Para usar estes exemplos de painel como ponto de partida para visualizar o conjunto de dados, conecte a fonte de dados do BigQuery.
Antes de conectar os painéis de exemplo à fonte de dados do BigQuery, verifique se você fez login na conta associada ao seu Google Cloud ambiente.

Selecione o botão destacado para revelar as opções suspensas.

Selecione Fazer uma cópia.
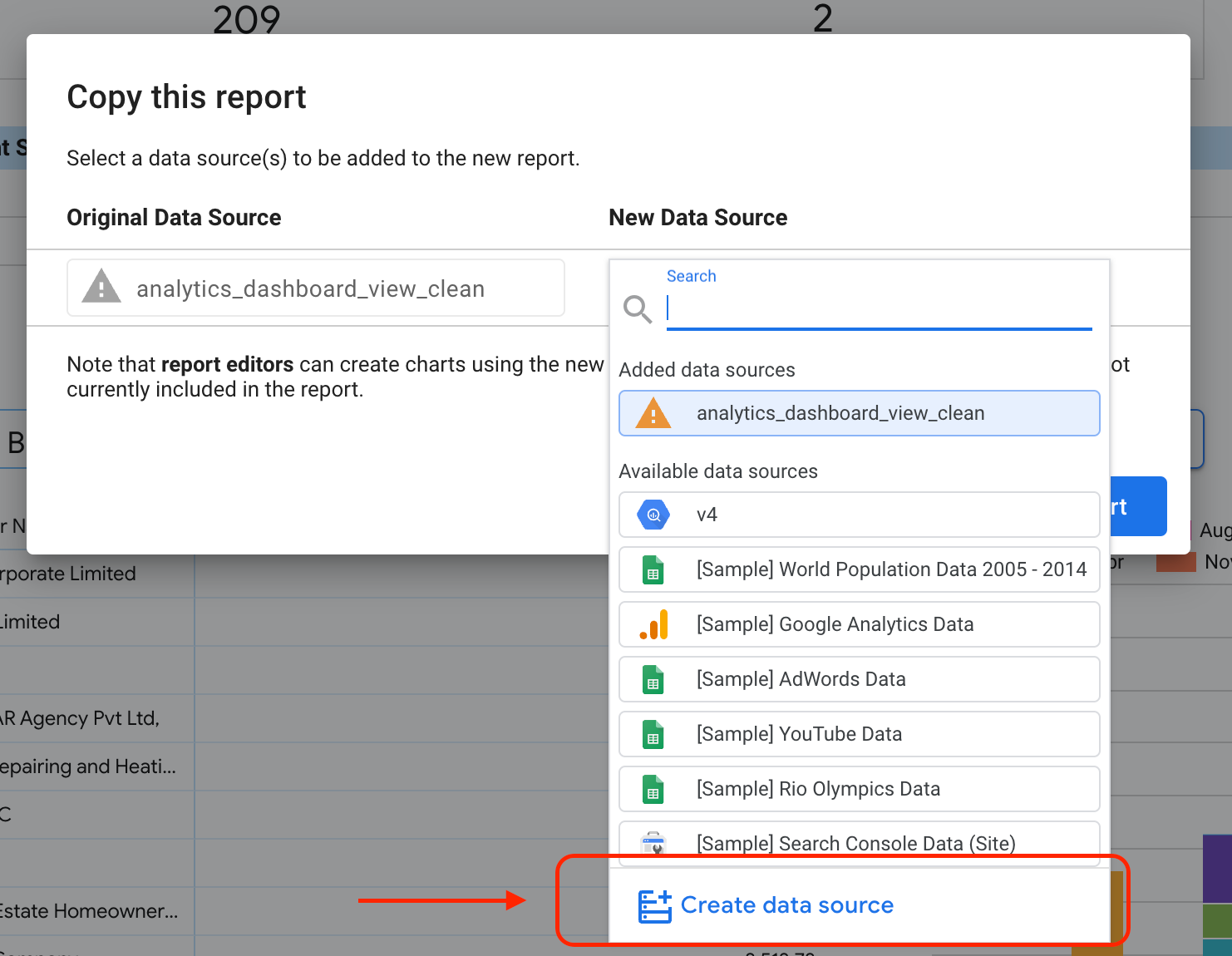
Na subseção "Nova fonte de dados", selecione Criar fonte de dados.
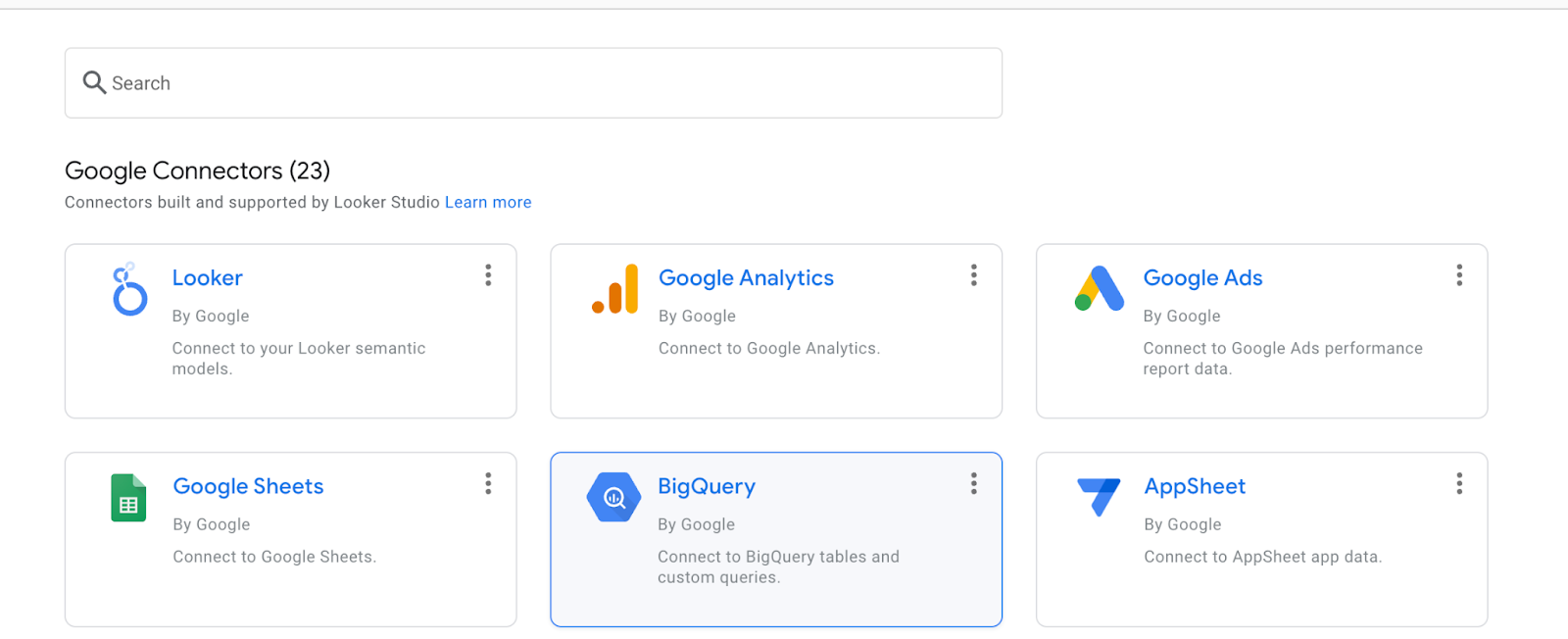
Selecione BigQuery.
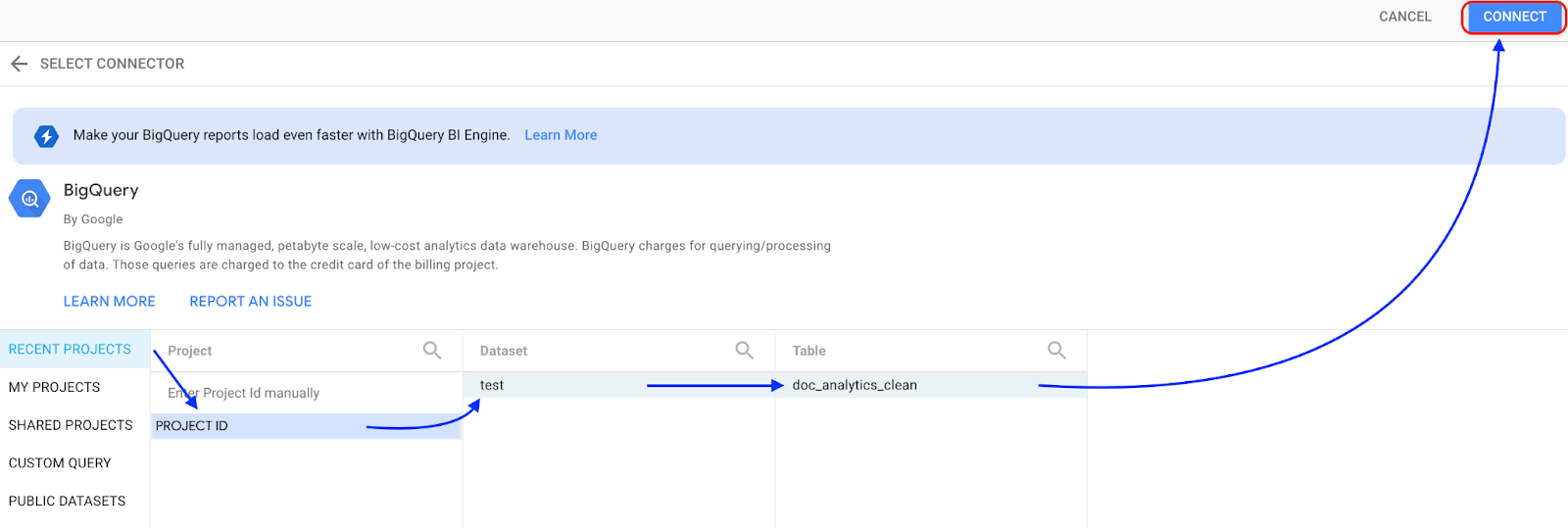
Selecione o projeto em que o conjunto de dados está armazenado e siga as instruções para selecionar o conjunto de dados e a tabela. Clique em Conectar.

Clique em Adicionar ao relatório.
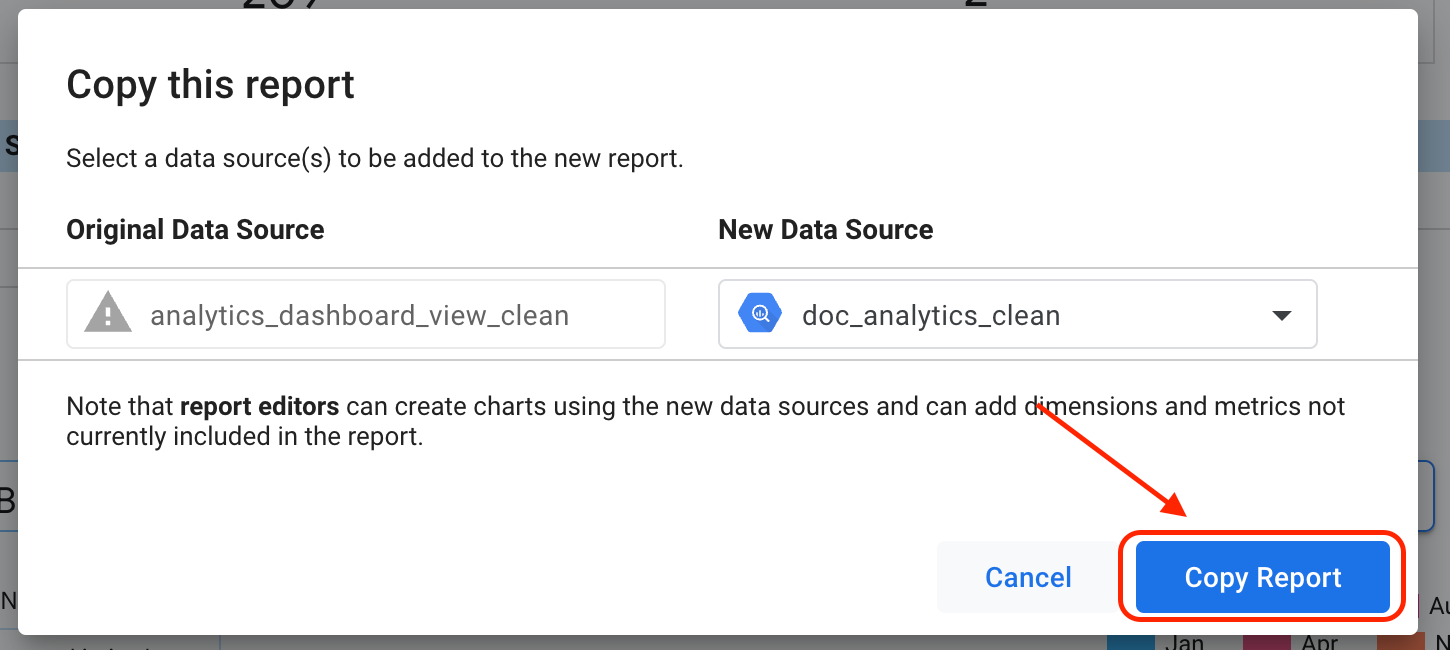
Clique em Copiar relatório.
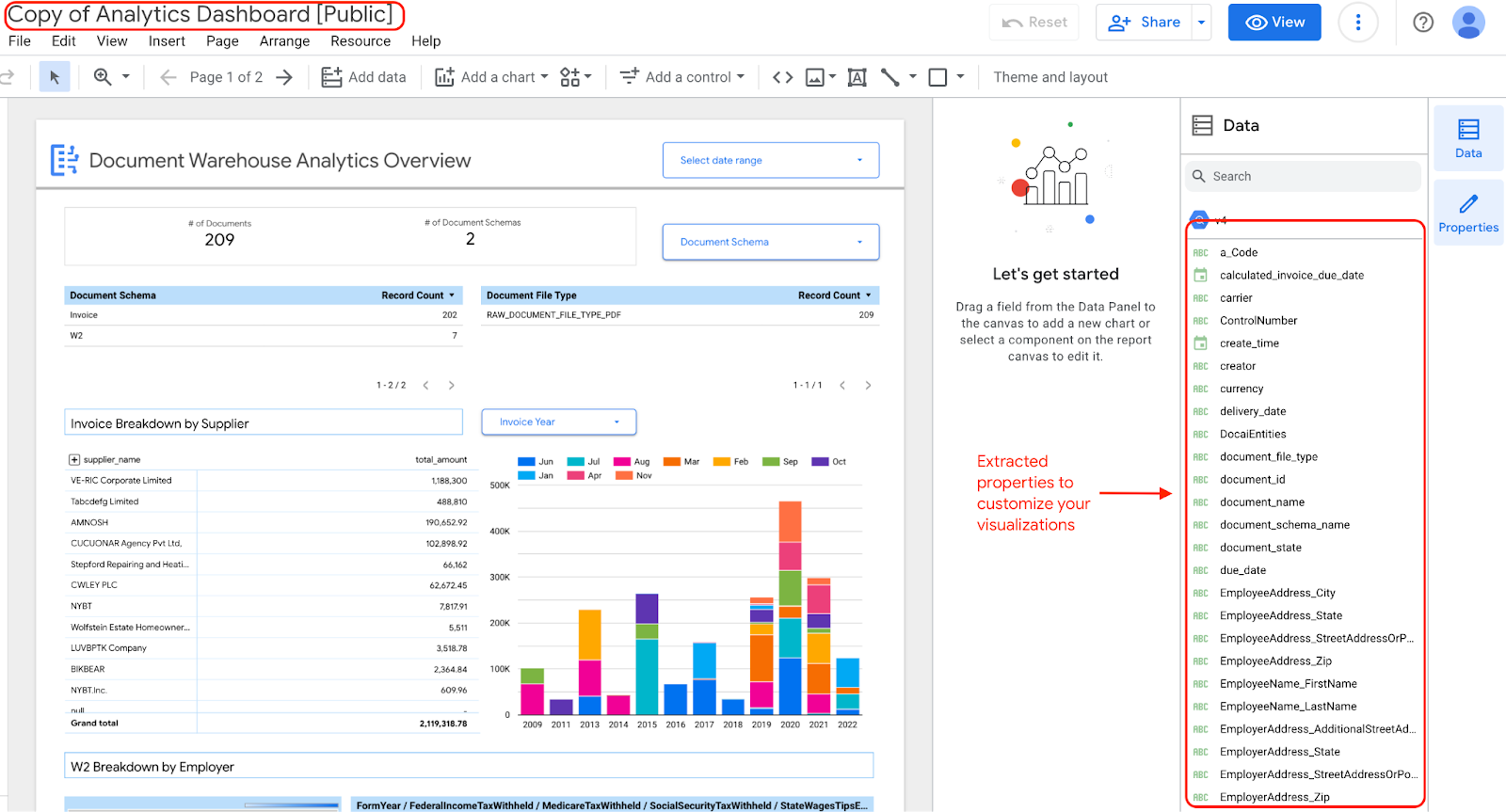
Se você optar por editar e atualizar os widgets no painel, poderá editá-lo, porque tem uma cópia do painel com as propriedades extraídas.