
使用 Gemini 版面配置剖析器處理文件
Document AI 版面配置剖析器是進階的文字剖析和文件解讀服務,可將複雜檔案中的非結構化內容,轉換為高度結構化、精確且機器可讀取的資訊。這項功能結合了 Google 專用的物件字元辨識 (OCR) 模型,以及 Gemini 的生成式 AI 功能。這項技術可瞭解完整的文件結構,識別表格、圖表、清單和標題等元素,同時保留這些元素之間的脈絡關係,例如哪些段落屬於哪個標題。
這項技術旨在解決搜尋和檢索增強生成 (RAG) 的重大問題:標準 OCR 會將文件平面化,破壞可增加有意義價值的內容和結構,例如標題、表格和清單。
主要應用實例
- 文件 OCR:可剖析 PDF 文件中的文字和版面配置元素,例如標題、頁首、頁尾、表格結構和圖形。
- 高保真搜尋和 RAG:主要用途是準備文件,以供搜尋和 RAG 管道使用。建立脈絡感知區塊,大幅提升檢索品質和生成答案的準確度。
- 結構化資料擷取:可剖析複雜文件 (例如 10-K 申請或報告),並將結構化內容 (例如剖析的表格或圖片說明) 編入資料庫索引,如 BigQuery 所示。
運作方式
Gemini 版面配置剖析器會透過多級式管道處理文件,確保保留語意:
- 剖析和建構:系統會擷取文件內容,所有元素都會經過識別,並以樹狀格式整理。這個
DocumentLayoutproto 欄位會保留文件的固有階層。 - 標註和口述: 預覽 Gemini 的生成功能會口述複雜的視覺元素。圖表和表格會附上豐富的文字說明。
- 分塊和擴增:系統會使用剖析的文件及其註解,建立語意連貫的區塊。這些區塊會加上脈絡資訊 (例如祖先標題),確保即使單獨擷取區塊,意義也不會改變。
處理器版本
版面配置剖析器可使用下列模型。如要變更模型版本,請參閱「管理處理器版本」一文。
如要對預設處理器配額提出配額提高要求 (QIR),請按照「管理配額」中的步驟操作。
| 模型版本 | 說明 | 發布版本 | 發布日期 |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
文件版面分析正式發布版。這是預先訓練的預設處理器版本。 | 穩定 | 2024 年 6 月 3 日 |
pretrained-layout-parser-v1.5-2025-08-25 |
搭載 Gemini 2.5 Flash LLM 的預先發布版,可更準確地分析 PDF 檔案的版面配置。建議想試用新版本的使用者選用。 | 候選版 | 2025 年 8 月 25 日 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
搭載 Gemini 2.5 Pro LLM 的預覽版本,可更準確地分析 PDF 檔案的版面配置。v1.5-pro 的延遲時間比 v1.5 長。 | 候選版 | 2025 年 8 月 25 日 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
搭載 Gemini 3.0 Pro LLM 的預先發布版。 | 候選版 | 2025 年 12 月 1 日 |
pretrained-layout-parser-v1.6-2026-01-13 |
搭載 Gemini 3.0 Flash LLM 的預先發布版。 | 候選版 | 2026 年 1 月 13 日 |
主要功能
在本文中,Gemini 版面配置剖析器是指以 Gemini 為基礎的預先訓練版面配置剖析器處理器版本,例如 pretrained-layout-parser-v1.5-2025-08-25 和 pretrained-layout-parser-v1.5-pro-2025-08-25。Gemini 版面配置剖析器支援下列主要功能。
進階資料表剖析
財務報表或技術手冊中的表格是 RAG 的常見失敗點。Gemini 版面配置剖析器擅長從複雜的表格中擷取資料, 包括合併儲存格和複雜的標題。
示例:在 Alphabet 的 10-K 歸檔文件中,競爭對手的剖析器無法正確對齊標題和儲存格,因而誤解財務資料。Gemini 版面配置剖析器可準確剖析整個表格結構,確保資料完整性。
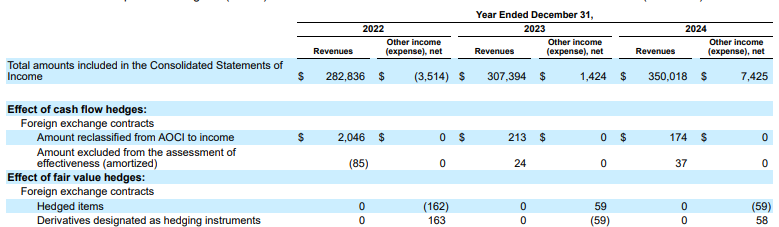
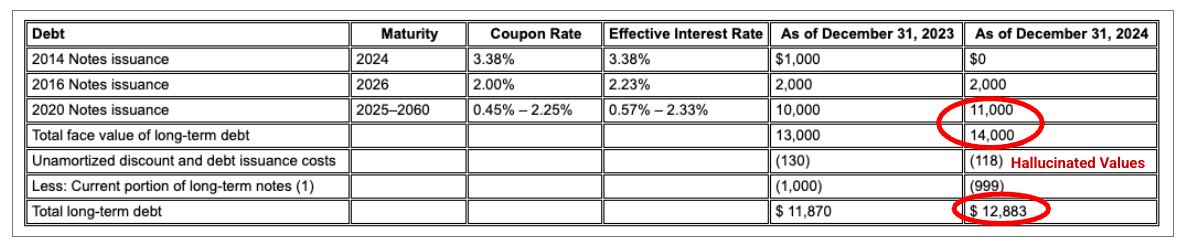
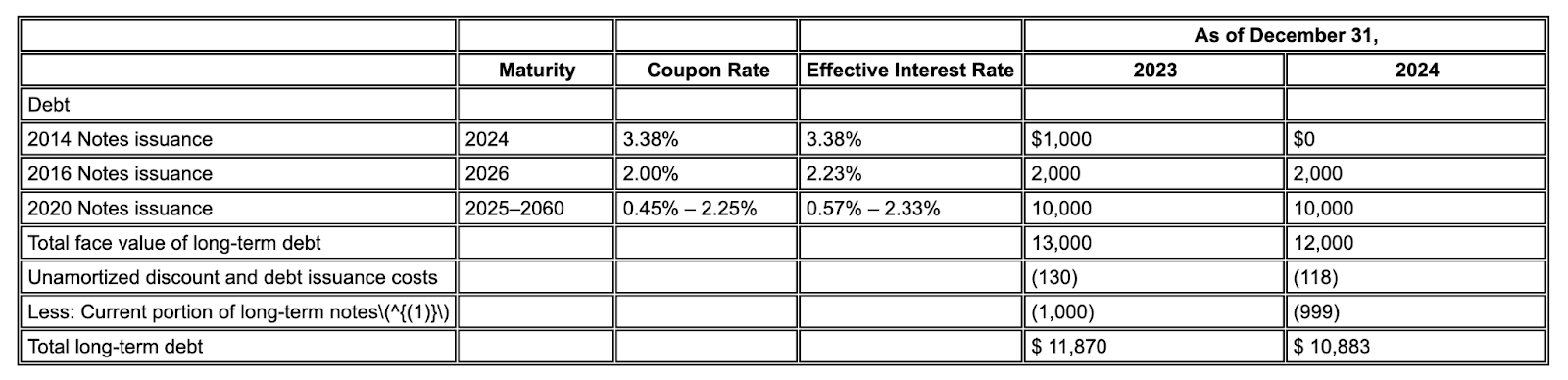
圖 1. 這份輸入文件的來源為「Alphabet 2024 年 SEC 表單 10-K」,第 72 頁。
競爭對手剖析器無法正確偵測儲存格和欄對齊方式,並產生幻覺值。
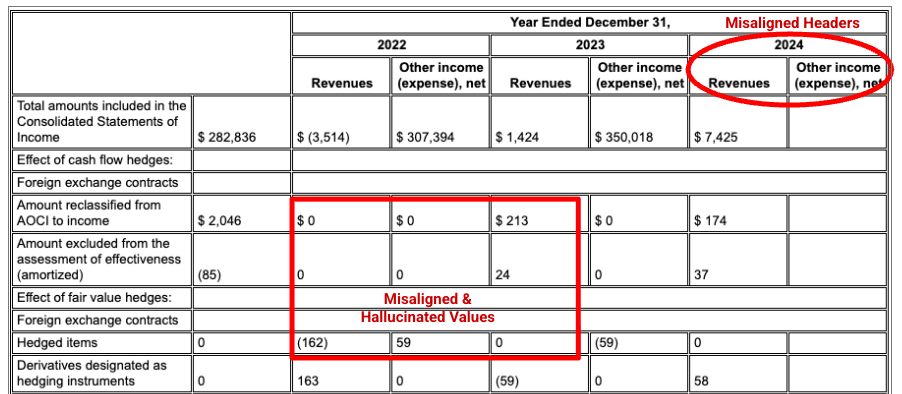
Gemini 版面配置剖析器會正確對齊欄,並提供準確的值。
減少幻覺
與純粹以大型語言模型為基礎的剖析器不同,Gemini 版面配置剖析器以進階 OCR 為基礎,可從文件實際內容中擷取資訊,這可大幅減少幻覺。
範例:在這份 10-K 摘錄中,競爭對手的模型產生了錯誤的文字,Gemini 版面配置剖析器可準確擷取網頁上的文字,不會夾雜其他內容。
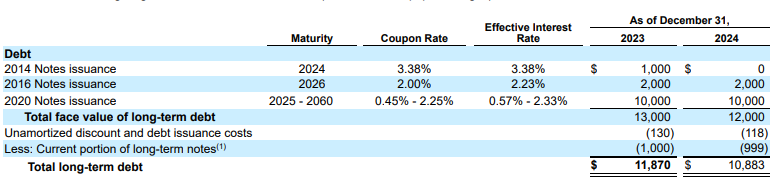
圖 2:輸入文件 (Alphabet 2024 年 10k 報告第 75 頁)
競爭對手模型會產生幻覺值。
Gemini 版面配置剖析器可正確識別圖片和表格中的值。
版面配置感知區塊
標準剖析器通常會建立從原始環境移除的區塊,將段落與標題分開。Gemini 版面配置剖析器可瞭解文件的階層結構。這項功能會建立內容認知分塊,其中包含來自上層標題和表格標題的內容。擷取的區塊不僅包含文字,還包含準確的 LLM 回覆所需的結構背景資訊。
圖 3:這張圖片的來源為 Shangbang Long、Siyang Qin、Yasuhisa Fujii、Alessandro Bissacco 和 Michalis Raptis 撰寫的「Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis」。
版面配置註解
版面配置剖析器註解可識別剖析文件中的圖片或表格。如果找到,系統會以描述性文字區塊的形式標註,並提供圖片和表格中顯示的資訊。
舉例來說,在處理銀行報表時,剖析器不會只看到圖片,這項功能會生成詳細說明,並從所有三個圓餅圖中擷取資料點,方便您擷取這些資料。
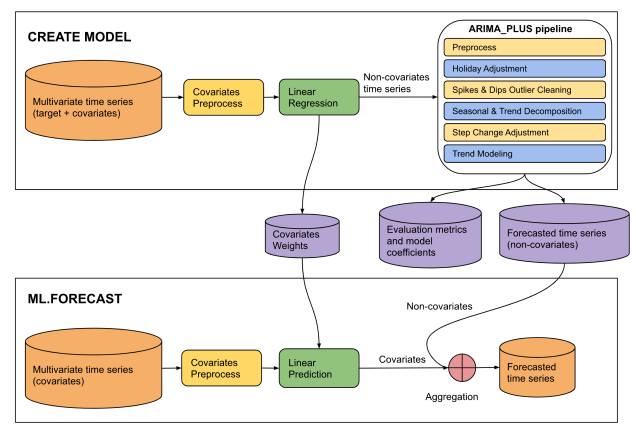
圖 4:這項輸入內容的來源是 Google Cloud 網站上「用於 ARIMA_PLUS_XREG 模型的 CREATE MODEL 陳述式」的 PDF 儲存版本。
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
限制
限制如下:
- 線上處理:
- 所有檔案類型的輸入檔案大小上限為 20 MB
- 每個 PDF 檔案最多 15 頁
- 批次處理:
- PDF 檔案大小上限為 1 GB
- 每個 PDF 檔案最多 500 頁
各檔案類型的版面配置偵測結果
下表列出版面配置剖析器可偵測到的元素,並依文件檔案類型分類。
| 檔案類型 | MIME 類型 | 偵測到的元素 | 限制 |
|---|---|---|---|
| HTML | text/html |
段落、表格、清單、標題、頁首、頁尾 | 請注意,剖析作業主要依賴 HTML 標記,因此系統可能無法擷取以 CSS 為基礎的格式設定。 |
application/pdf |
圖、段落、表格、標題、頁首、頁尾 | 如果表格橫跨多個頁面,可能會分割成兩個表格。 | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
段落、跨多個頁面的表格、清單、標題、標題元素 | 系統不支援巢狀表格。 |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
段落、表格、清單、標題、標題元素 | 如要準確識別標題,請在 PowerPoint 檔案中標示標題。不支援巢狀表格和隱藏投影片。 |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
Excel 試算表中的表格,支援 INT、
FLOAT 和 STRING 值 |
不支援偵測多個表格。隱藏的工作表、列或欄也可能會影響偵測結果。最多可處理 500 萬個儲存格的檔案。 |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
啟用巨集的試算表,支援 INT、
FLOAT 和 STRING 值 |
不支援偵測多個表格。隱藏的工作表、列或欄也可能會影響偵測結果。 |
後續步驟
- 查看處理器清單。
- 建立自訂分類器。
- 使用 Enterprise Document OCR 偵測及擷取文字。
- 請參閱「傳送批次處理文件要求」,瞭解如何處理回應。