
Membuat, menggunakan, dan mengelola pengklasifikasi dokumen kustom
Gunakan pengklasifikasi kustom untuk mengklasifikasikan dokumen. Bangun dari awal dengan dokumen Anda sendiri dan kelas kustom. Aspek AI generatifnya memungkinkan pembelajaran multi-shot dan penyesuaian. Hal ini meningkatkan akurasi dengan lebih sedikit sampel dan koreksi dengan pelabelan otomatis iteratif.
Pengklasifikasi kustom mencakup tiga kasus penggunaan umum ini.
- Model terlatih: Gunakan model dasar AI generatif terlatih untuk mengklasifikasikan dokumen dengan cepat menggunakan label yang Anda berikan.
- Fine-tuning: Tingkatkan akurasi dengan melatih model dasar AI generatif menggunakan data dan label Anda sendiri.
- Melatih model kustom: Latih pengekstrak kustom AI non-generatif menggunakan data dan label Anda sendiri.
Versi model pengklasifikasi kustom
Skor keyakinan didukung untuk model pengklasifikasi kustom dalam Pratinjau. Untuk performa terbaik, gunakan dengan model yang telah disesuaikan.
| Versi model | Deskripsi | Saluran rilis | Pemrosesan ML di AS/Uni Eropa | Penyesuaian di Amerika Serikat/Uni Eropa | Tanggal rilis |
|---|---|---|---|---|---|
pretrained-classifier-v1.5-2025-08-05 |
Model siap produksi yang didukung oleh LLM Gemini 2.5 Flash. Juga mencakup fitur OCR lanjutan. Model terlatih ini dapat digunakan tanpa pelatihan sebelumnya. Model ini mendukung klasifikasi zero-shot dan memberikan dukungan yang lebih baik untuk class catch-all. | Stabil | Ya | Amerika Serikat, Uni Eropa (Pratinjau) | 5 Agustus 2025 |
pretrained-classifier-v1.6-2026-03-09 |
Kandidat rilis yang didukung oleh LLM Gemini 3.1 Flash. | Kandidat Rilis | Ya | Amerika Serikat, Uni Eropa (Pratinjau) | 9 Maret 2026 |
pretrained-classifier-v1.6-pro-2026-03-09 |
Kandidat rilis yang didukung oleh LLM Gemini 3.1 Pro. | Kandidat Rilis | Ya | Amerika Serikat, Uni Eropa (Pratinjau) | 9 Maret 2026 |
Membuat pengklasifikasi kustom di konsol Google Cloud
Anda dapat membuat pengklasifikasi kustom yang secara khusus cocok dengan dokumen Anda, serta dilatih dan dievaluasi dengan data Anda. Pemroses ini mengidentifikasi kelas dokumen dari serangkaian kelas yang ditentukan pengguna. Selanjutnya, Anda dapat menggunakan pemroses terlatih ini pada dokumen lain. Biasanya, Anda akan menggunakan pengklasifikasi kustom pada dokumen yang memiliki jenis berbeda, lalu menggunakan identifikasi untuk meneruskan dokumen ke pemroses ekstraksi guna mengekstrak entity.
Untuk proses umum dalam membuat dan menggunakan prosesor, lihat bagian Cara.
Anda dapat membuat pilihan konfigurasi sendiri yang sesuai dengan alur kerja Anda.
Untuk mengikuti panduan langkah demi langkah untuk tugas ini langsung di Google Cloud konsol, klik Pandu saya:
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Peran yang diperlukan
Untuk mendapatkan izin yang Anda perlukan untuk membuat pengklasifikasi kustom, minta administrator Anda untuk memberi Anda peran IAM berikut di project Anda:
- Administrator Document AI (
roles/documentai.admin) - Storage Admin (
roles/storage.admin)
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran khusus atau peran bawaan lainnya.
Membuat pemroses
Selesaikan langkah-langkah berikut.
Buka Workbench
Untuk pengklasifikasi dokumen kustom, pilih
Buat prosesor .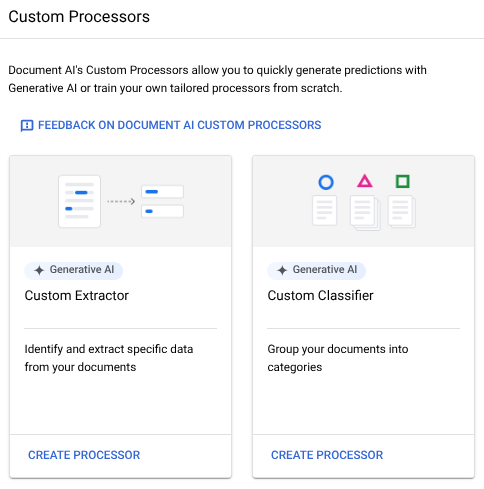
Di menu Buat pemroses, masukkan nama untuk pemroses Anda, misalnya
my-custom-document-classifier.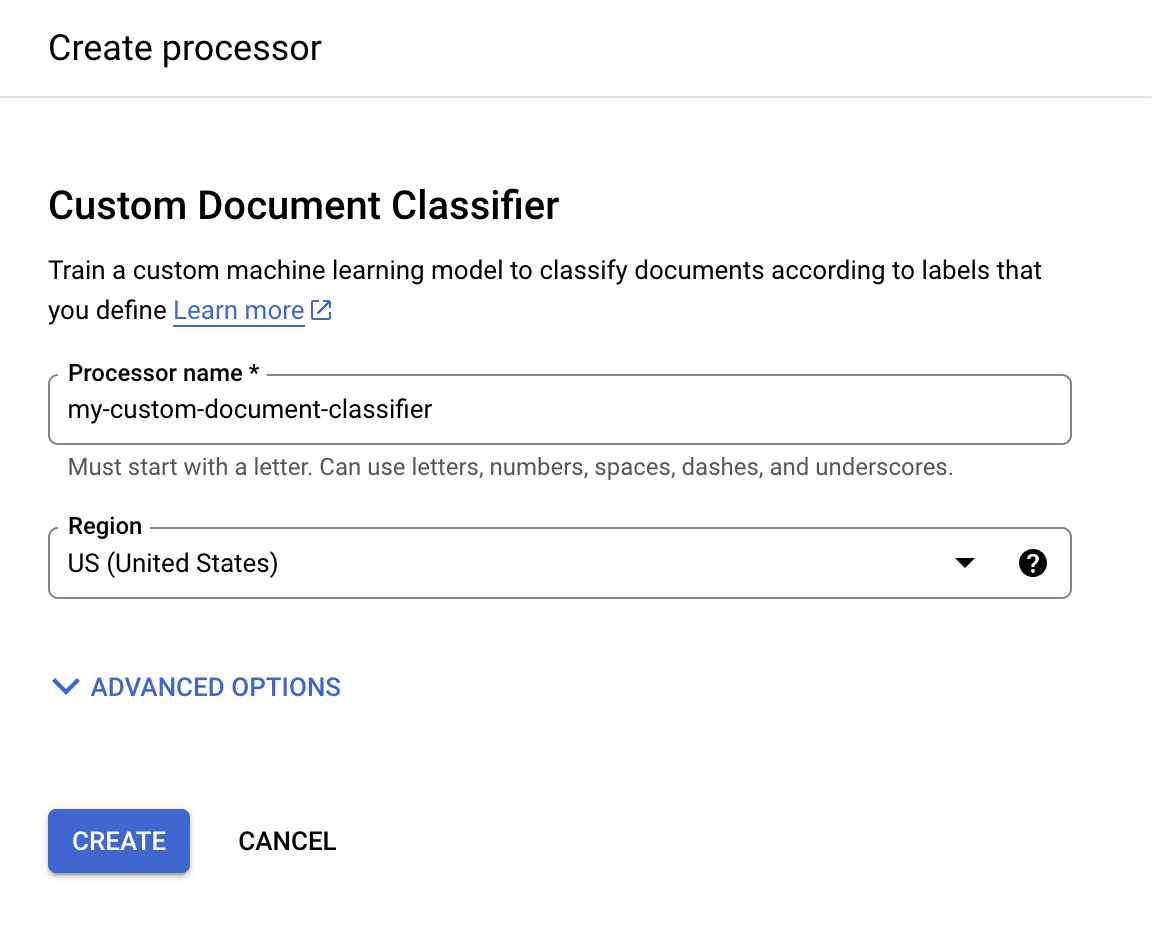
Pilih wilayah yang terdekat dengan Anda.
Pilih Create. Tab Processor Details akan muncul.
Mengonfigurasi set data
Untuk melatih prosesor baru ini, Anda harus membuat set data dengan data pelatihan dan pengujian untuk membantu prosesor mengidentifikasi dokumen yang ingin Anda pisahkan dan klasifikasikan. Set data ini memerlukan lokasi baru. Ini dapat berupa bucket Cloud Storage atau folder yang kosong, atau Anda dapat mengizinkan lokasi yang dikelola secara internal.
Setelah tab Detail Pemroses muncul, Anda dapat:
- Pilih Penyimpanan yang dikelola Google jika Anda ingin menggunakan Cloud Storage.
- Pilih Saya akan menentukan lokasi penyimpanan saya sendiri jika Anda ingin menggunakan penyimpanan Anda sendiri untuk menggunakan Kunci Enkripsi yang Dikelola Pelanggan (CMEK), dan ikuti prosedur di Membuat set data.

Mengimpor dokumen ke dalam set data
Selanjutnya, Anda mengimpor dokumen ke dalam set data.
Di tab Build, pilih
Import documents .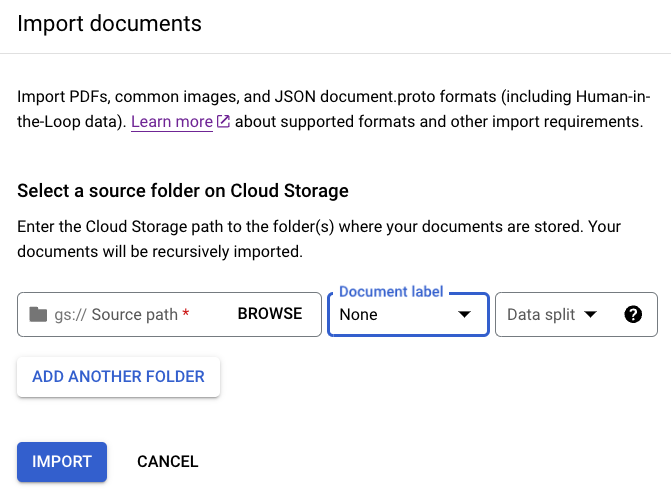
Saat memilih untuk menggunakan bucket penyimpanan, Anda harus memasukkan Jalur Sumber untuk bucket tersebut. Untuk contoh pelatihan ini, masukkan nama bucket ini di
Source path . Link ini mengarah langsung ke satu dokumen.cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdfUntuk Pemisahan data, pilih Tidak ditetapkan. Dokumen dalam folder ini tidak ditetapkan ke set pengujian atau pelatihan. Biarkan Import with auto-labeling tidak dicentang.
Pilih Impor Document AI membaca dokumen dari bucket ke dalam set data. Tidak mengubah bucket impor atau membaca dari bucket setelah impor selesai.
Opsional: Untuk menghapus dokumen yang diimpor, di tab Build, buka Manage dataset > pilih dokumen > klik Delete.
Saat mengimpor dokumen, Anda dapat secara opsional menetapkan dokumen ke set Pelatihan atau Pengujian saat diimpor, atau menunggu untuk menetapkannya nanti.
Untuk mengetahui informasi selengkapnya tentang cara menyiapkan data untuk diimpor, lihat Panduan persiapan data.
Menentukan skema pemroses
Anda dapat membuat skema pemroses sebelum atau setelah mengimpor dokumen ke dalam set data. Skema ini menyediakan label yang Anda gunakan untuk menganotasi dokumen.
Di tab Build, pilih Manage Dataset > Edit Schema. Halaman Edit skema akan terbuka.
Pilih
Buat label .Masukkan nama untuk label.
Pilih Create. Baca dokumentasi tentang cara Menentukan skema pemroses untuk petunjuk mendetail tentang cara membuat dan mengedit skema.
Buat semua label berikut untuk skema pemroses.
computer_visioncryptomed_techother
Pilih
Simpan setelah label selesai.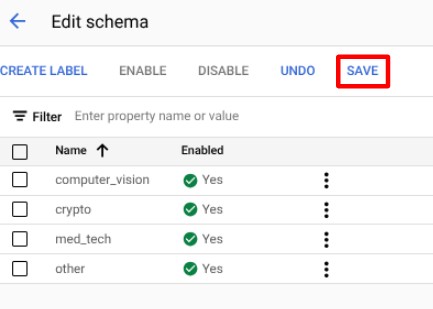
Memberi label dokumen
Proses memilih teks dalam dokumen dan menerapkan label disebut sebagai anotasi.
Kembali ke tab Build, lalu pilih
dokumen untuk membuka konsol Manage Dataset.Di antara
opsi , pilih label yang sesuai untuk dokumen. Jika Anda menggunakan dokumen contoh yang disediakan, pilihcomputer_vision.Setelah diberi label, dokumen akan terlihat seperti ini:

Pilih
Tandai sebagai Berlabel setelah Anda selesai membuat anotasi pada dokumen.Di tab Manage Dataset, panel Document menunjukkan bahwa satu dokumen telah diberi label.
Menetapkan dokumen yang dianotasi ke set pelatihan
Setelah memberi label pada contoh dokumen ini, Anda dapat menetapkannya ke set pelatihan.
Di tab Kelola Set Data, centang kotak
Pilih Semua .Dari daftar
Tetapkan ke Set , pilih Training.
Di panel Dokumen, Anda dapat menemukan bahwa satu dokumen telah ditetapkan ke set pelatihan.
(Opsional) Mengimpor data yang telah diberi label ke set pelatihan dan pengujian
Jika Anda menggunakan v1.4, Anda harus mengupload set pelatihan dan pengujian untuk melatih pemroses kustom. Anda dapat melewati langkah ini saat menggunakan v1.5.
Dalam panduan ini, Anda akan disediakan data yang telah diberi label. Jika yang dikerjakan adalah project Anda sendiri, Anda harus menentukan cara memberi label pada data Anda. Lihat Opsi pelabelan.
Prosesor kustom Document AI memerlukan minimal satu dokumen dalam set pelatihan dan pengujian untuk setiap jenis dokumen yang akan diberi label. Sebaiknya Anda memiliki minimal 10 dokumen untuk setiap label agar mendapatkan performa terbaik. Untuk 5 label, Anda memerlukan 50 dokumen untuk pelatihan dan 50 dokumen untuk pengujian. Makin banyak data pelatihan, biasanya makin tinggi akurasinya.
Pilih
Impor dokumen .Masukkan jalur berikut di
Source path . Bucket ini berisi dokumen yang telah diberi label sebelumnya dalam format Document JSON.cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionTypeDari daftar Data split, pilih Auto-split. Dokumen akan otomatis terbagi menjadi 80%-nya dalam set pelatihan dan 20%-nya dalam set pengujian. Abaikan bagian Terapkan label.
Pilih Impor Proses impor mungkin memerlukan waktu beberapa menit.
Setelah impor selesai, Anda akan menemukan dokumen di tab Kelola Set Data.
Memberi label pada dokumen dalam batch saat impor
Secara opsional, setelah skema dikonfigurasi, Anda dapat memberi label pada semua dokumen yang ada di direktori tertentu saat mengimpor untuk menghemat waktu pelabelan.
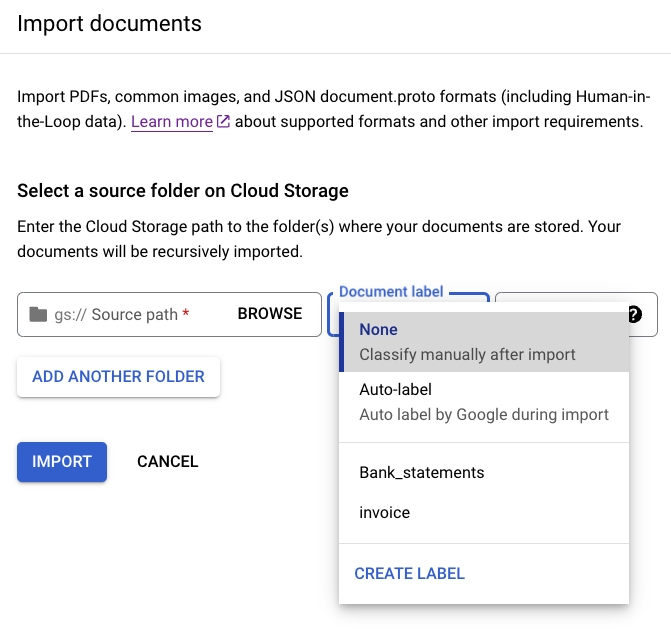
Pilih
Impor dokumen .Masukkan jalur berikut di
Source path . Bucket ini berisi dokumen tanpa label dalam format PDF.cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelDari daftar Data split, pilih Auto-split. Dokumen akan otomatis terbagi menjadi 80%-nya dalam set pelatihan dan 20%-nya dalam set pengujian.
Di bagian Terapkan label, pilih Pilih label.
Untuk dokumen contoh ini, pilih
other.Pilih Impor dan tunggu hingga proses selesai. Anda dapat keluar dari halaman ini dan kembali lagi nanti. Setelah selesai, Anda akan menemukan dokumen di tab Manage Dataset dengan label yang diterapkan.
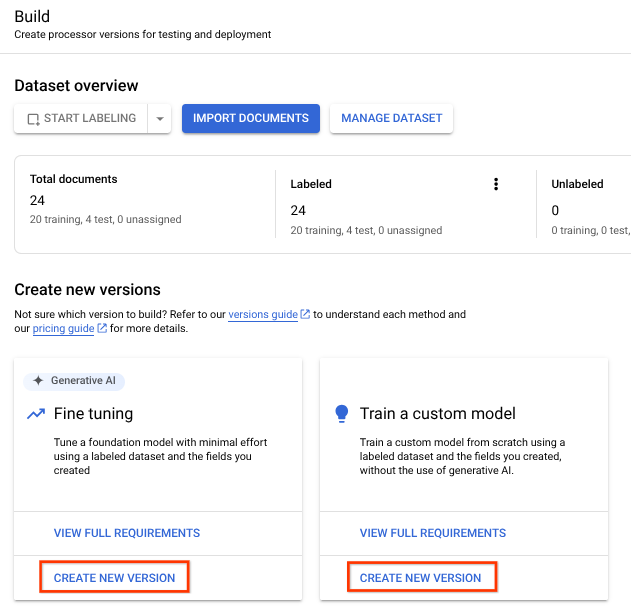
(Opsional) Melatih pemroses
Jika menggunakan v1.4, Anda harus melatih pemroses kustom pada set data pelatihan dan pengujian. Anda dapat melewati langkah ini saat menggunakan v1.5.
Setelah mengimpor data pelatihan dan pengujian, Anda dapat melatih pemroses. Karena pelatihan mungkin memerlukan waktu beberapa jam, pastikan Anda telah menyiapkan pemroses dengan data dan label yang sesuai sebelum memulai pelatihan.
Anda dapat melatih model kustom dan yang disesuaikan dengan data berlabel Anda. Model yang dioptimalkan menggunakan AI generatif. Model kustom melatih Model bahasa besar yang unik menggunakan data berlabel Anda. Anda memerlukan minimal dua label dalam skema, dengan rekomendasi sepuluh dokumen pelatihan dan 10 dokumen pengujian (minimal 1).
- Pilih
Train New Version .
Di kolom
Version name , masukkan nama untuk versi pemroses ini, misalnyamy-cdc-version-1.Opsional: Pilih Lihat Statistik Label untuk menemukan informasi tentang label dokumen yang dapat membantu menentukan cakupan Anda. Pilih Tutup untuk kembali ke penyiapan pelatihan.
Pilih
Mulai pelatihan. Anda dapat memeriksa statusnya di panel samping.
Men-deploy versi pemroses
Setelah pelatihan selesai, buka tab
Kelola Versi . Anda dapat melihat detail tentang versi yang baru saja Anda latih.Pilih
di samping versi yang ingin Anda deploy, lalu pilih Deploy versi. Pilih
Deploy dari jendela dialog.Deployment memerlukan waktu beberapa menit hingga selesai.
Mengevaluasi dan menguji pemroses
Setelah deployment selesai, buka tab
Evaluate & Test .Di halaman ini, Anda dapat melihat metrik evaluasi termasuk skor F1, presisi, dan perolehan untuk dokumen lengkap, dan masing-masing label. Untuk mengetahui informasi selengkapnya tentang evaluasi dan statistik, lihat Mengevaluasi prosesor.
Download dokumen yang belum pernah digunakan dalam pelatihan atau pengujian sebelumnya agar Anda dapat menggunakannya untuk mengevaluasi versi pemroses. Jika menggunakan data Anda sendiri, Anda akan menggunakan kumpulan dokumen yang disediakan untuk tujuan ini.
Pilih
Upload Test Document , lalu pilih dokumen yang baru saja Anda download.Halaman Analisis Pengklasifikasi Dokumen Kustom akan terbuka. Output menunjukkan seberapa baik dokumen diklasifikasikan.
Anda juga dapat menjalankan kembali evaluasi terhadap set pengujian atau versi prosesor yang berbeda.
Otomatis melabeli dokumen yang baru diimpor
Setelah menerapkan versi prosesor terlatih, Anda dapat menggunakan Pelabelan otomatis untuk menghemat waktu pelabelan saat mengimpor dokumen baru.
Di halaman Kelola Set Data,
Impor dokumen .Salin dan tempel jalur Cloud Storage berikut. Direktori ini berisi lima PDF paten tanpa label. Dari daftar drop-down Data split, pilih Training.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabelDi bagian Terapkan label, pilih Pemberian label otomatis.
Pilih versi prosesor yang ada untuk melabeli dokumen.
- Contoh:
2af620b2fd4d1fcf
- Contoh:
Pilih Impor dan tunggu hingga proses selesai. Anda dapat keluar dari halaman ini dan kembali lagi nanti. Setelah selesai, dokumen akan muncul di bagian Auto-labeled di halaman Manage Dataset.
Anda tidak dapat menggunakan dokumen berlabel otomatis untuk pelatihan atau pengujian tanpa menandainya sebagai berlabel. Buka bagian
Berlabel otomatis untuk melihat dokumen berlabel otomatis.Pilih dokumen pertama untuk masuk ke konsol pelabelan.
Verifikasi label untuk memastikan label sudah benar. Sesuaikan jika salah.
Pilih
Tandai sebagai Berlabel setelah selesai.Ulangi verifikasi label untuk setiap dokumen yang diberi label otomatis, lalu kembali ke halaman Kelola Set Data untuk menetapkan data untuk pelatihan.
Menggunakan pemroses
Anda dapat mengelola versi prosesor yang dilatih kustom seperti versi prosesor lainnya. Untuk mengetahui informasi selengkapnya, lihat Mengelola versi pemroses.
Anda juga dapat Mengirim permintaan pemrosesan ke prosesor kustom, dan respons dapat ditangani sama seperti prosesor pengklasifikasi lainnya.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan pada halaman ini, ikuti langkah-langkah berikut.
Di menu navigasi konsol Google Cloud , pilih Document AI, lalu My Processors.
Pilih
Tindakan lainnya di baris yang sama dengan pemroses yang ingin Anda hapus.Pilih Hapus pemroses, masukkan nama pemroses, lalu pilih Hapus lagi untuk mengonfirmasi.
Langkah berikutnya
- Untuk mengetahui detail selengkapnya, lihat Panduan.
- Tinjau daftar pemroses.
- Pisahkan dokumen menjadi bagian-bagian yang mudah dibaca dengan Layout Parser.
- Gunakan Enterprise Document OCR untuk mendeteksi dan mengekstrak teks.