
BigQuery משתלב עם Document AI כדי לעזור ליצור ניתוח מסמכים ותרחישי שימוש ב-AI גנרטיבי. הטרנספורמציה הדיגיטלית מתרחשת במהירות, וארגונים יוצרים כמויות עצומות של טקסט ונתונים אחרים במסמכים. לנתונים האלה יש פוטנציאל עצום לתובנות ולשימושים חדשים ב-AI גנרטיבי. כדי לעזור לכם להפיק תועלת מהנתונים האלה, אנחנו שמחים להודיע על שילוב בין BigQuery לבין Document AI. השילוב הזה מאפשר לכם לחלץ תובנות מנתוני מסמכים ולבנות אפליקציות חדשות של מודלים גדולים של שפה (LLM).
סקירה כללית
לקוחות BigQuery יכולים עכשיו ליצור כלי חילוץ בהתאמה אישית של Document AI, שמבוססים על מודלים מתקדמים של Google. הם יכולים להתאים אותם אישית על סמך המסמכים והמטא-נתונים שלהם. אחר כך אפשר להפעיל את המודלים המותאמים אישית מ-BigQuery כדי לחלץ נתונים מובנים ממסמכים בצורה מאובטחת ומבוקרת, באמצעות הפשטות והעוצמה של SQL. לפני השילוב הזה, חלק מהלקוחות ניסו ליצור צינורות נתונים עצמאיים של Document AI, שכללו אוצרות ידניים של לוגיקת חילוץ וסכימה. היעדר יכולות שילוב מובנות גרם להם לפתח תשתית בהתאמה אישית כדי לסנכרן ולשמור על עקביות הנתונים. כך כל פרויקט של ניתוח מסמכים הפך למשימה גדולה שדרשה השקעה משמעותית. השילוב הזה מאפשר ללקוחות ליצור מודלים מרוחקים ב-BigQuery עבור כלי החילוץ המותאמים אישית שלהם ב-Document AI, ולהשתמש בהם כדי לבצע ניתוח מסמכים ו-AI גנרטיבי בקנה מידה נרחב. כך נפתח עידן חדש של תובנות מבוססות-נתונים וחדשנות.
חוויה אחידה ומבוקרת של נתונים ל-AI
אפשר ליצור חילוץ מותאם אישית ב-Document AI בשלושה שלבים:
- מגדירים את הנתונים שרוצים לחלץ מהמסמכים. הוא נקרא
document schema, הוא מאוחסן בכל גרסה של כלי החילוץ המותאם אישית ואפשר לגשת אליו מ-BigQuery. - אפשר גם לספק מסמכים נוספים עם הערות כדוגמאות לחילוץ.
- מאמנים את המודל לחילוץ המותאם אישית, על סמך מודלי הבסיס שמופיעים ב-Document AI.
בנוסף לחילוץ מותאם אישית שדורש אימון ידני, Document AI מספק גם חילוץ מוכן לשימוש של הוצאות, קבלות, חשבוניות, טפסי מס, תעודות מזהות רשמיות ומגוון תרחישים אחרים, בגלריית המעבדים.
אחרי שהכלי המותאם לחילוץ מוכן, אפשר לעבור ל-BigQuery Studio כדי לנתח את המסמכים באמצעות SQL בארבעת השלבים הבאים:
- רישום מודל מרוחק של BigQuery לחילוץ באמצעות SQL. המודל יכול להבין את סכימת המסמך (שנוצרה למעלה), להפעיל את הכלי המותאם אישית לחילוץ ולנתח את התוצאות.
- יצירת טבלאות אובייקטים באמצעות SQL למסמכים שמאוחסנים ב-Cloud Storage. אתם יכולים לשלוט בנתונים הלא מובנים בטבלאות על ידי הגדרת מדיניות גישה ברמת השורה, שמגבילה את הגישה של המשתמשים למסמכים מסוימים וכך מגבילה את יכולות ה-AI לצורך שמירה על פרטיות ואבטחה.
- משתמשים בפונקציה
ML.PROCESS_DOCUMENTבטבלת האובייקטים כדי לחלץ שדות רלוונטיים על ידי שליחת קריאות היקש לנקודת קצה ל-API. אפשר גם לסנן את המסמכים לחילוצים באמצעות פסקהWHEREמחוץ לפונקציה. הפונקציה מחזירה טבלה מובנית, כאשר כל עמודה היא שדה שחולץ. - אפשר לצרף את הנתונים שחולצו לטבלאות אחרות ב-BigQuery כדי לשלב נתונים מובנים ולא מובנים, וכך להפיק ערכים עסקיים.
בדוגמה הבאה אפשר לראות את חוויית המשתמש:
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
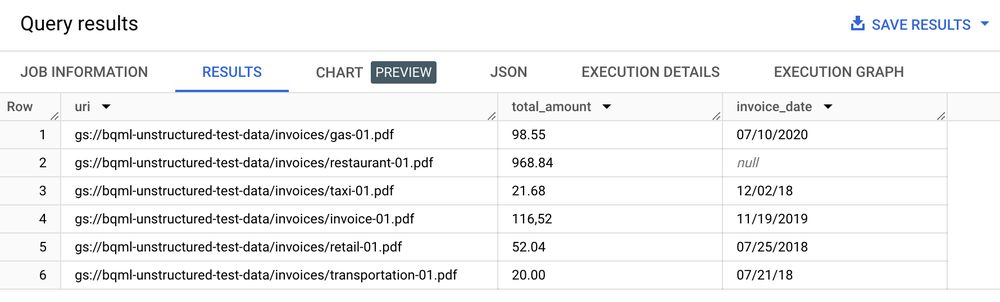
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
טבלת תוצאות
ניתוח טקסט, סיכום ותרחישי שימוש אחרים בניתוח מסמכים
אחרי שמחלצים טקסט מהמסמכים, אפשר לבצע ניתוח של המסמכים בכמה דרכים:
- שימוש ב-BigQuery ML לביצוע ניתוח טקסט: BigQuery ML תומך באימון ובפריסה של מודלים להטמעה במגוון דרכים. לדוגמה, אתם יכולים להשתמש ב-BigQuery ML כדי לזהות את הסנטימנט של הלקוחות בשיחות תמיכה, או כדי לסווג משוב על מוצרים לקטגוריות שונות. אם אתם משתמשים ב-Python, אתם יכולים גם להשתמש ב-BigQuery DataFrames for pandas ובממשקי API דומים ל-scikit-learn לניתוח טקסט של הנתונים.
- משתמשים ב-
text-embedding-004LLM כדי ליצור הטבעות מהמסמכים המחולקים לחלקים: ל-BigQuery יש פונקציהML.GENERATE_EMBEDDINGשקוראת למודלtext-embedding-004כדי ליצור הטבעות. לדוגמה, אפשר להשתמש ב-Document AI כדי לחלץ משוב מלקוחות ולסכם את המשוב באמצעות PaLM 2, והכול באמצעות BigQuery SQL. - צירוף מטא-נתונים של מסמכים לנתונים מובנים אחרים שמאוחסנים בטבלאות BigQuery:
לדוגמה, אפשר ליצור הטמעה באמצעות מסמכים מחולקים לחלקים ולהשתמש בה לחיפוש וקטורי.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
הטמעה של תרחישי שימוש בחיפוש וב-AI גנרטיבי
אחרי שמחלצים טקסט מובנה מהמסמכים, אפשר ליצור אינדקסים שממוטבים לשאילתות מסוג'מחט בערימת שחת'. האפשרות הזו זמינה בזכות יכולות החיפוש והאינדוקס של BigQuery, ומאפשרת לבצע חיפוש יעיל. השילוב הזה גם עוזר להפעיל אפליקציות חדשות של מודלים גדולים של שפה (LLM) גנרטיביים, כמו ביצוע עיבוד של קובצי טקסט לצורך סינון פרטיות, בדיקות בטיחות תוכן וחלוקה לאסימונים באמצעות SQL ומודלים מותאמים אישית של Document AI. הטקסט שחולץ, בשילוב עם מטא-נתונים אחרים, מפשט את תהליך האוצרות של מאגר הנתונים לאימון שנדרש כדי לבצע כוונון עדין של מודלים גדולים של שפה. בנוסף, אתם יכולים ליצור תרחישי שימוש ב-LLM על נתונים ארגוניים מנוהלים, שעברו הארקה באמצעות יכולות יצירת ההטמעה וניהול אינדקס הווקטורים של BigQuery. על ידי סנכרון האינדקס הזה עם Vertex AI, תוכלו להטמיע תרחישי שימוש של יצירה משופרת באמצעות אחזור, וליהנות מחוויית AI מנוהלת ויעילה יותר.
אפליקציה לדוגמה
דוגמה לאפליקציה מקצה לקצה שמשתמשת ב-Document AI Connector:
- אפשר לעיין בהדגמה של דוח ההוצאות הזה ב-GitHub.
- לקריאת הפוסט בבלוג
- צפייה בסרטון מ- Google Cloud Next 2021 עם מידע מעמיק.