
Depois de criar regras de alerta no projeto do dispositivo isolado do Google Distributed Cloud (GDC), pode consultar e ver alertas em painéis de controlo a partir da interface do utilizador (IU) da instância de monitorização do sistema do projeto ou consultar alertas a partir da API HTTP de observabilidade do GDC.
Consulte e veja alertas em painéis de controlo
Pode ver alertas em painéis de controlo a partir da
instância de monitorização do sistema do projeto platform-obs.
A instância de monitorização do sistema inclui métricas, registos e alertas ao nível do projeto para realizar processos de monitorização, como a monitorização de rede e a monitorização de servidores.
Antes de começar
Antes de consultar e ver alertas em painéis de controlo, tem de obter acesso à instância de monitorização do sistema. Para mais informações, consulte o artigo Aceda aos painéis de controlo.
Para iniciar sessão e visualizar alertas, peça ao administrador de IAM do projeto para lhe conceder a função de visualizador do Grafana do projeto (project-grafana-viewer). Este processo de controlo de acesso baseado em funções permite-lhe aceder a visualizações de dados de forma segura.
Ponto final da instância de monitorização do sistema
Para o operador da aplicação (AO):
Abra o seguinte URL para aceder ao ponto final do seu projeto:
https://GDC_URL/PROJECT_NAMESPACE/grafana
Substitua o seguinte:
- GDC_URL: o URL da sua organização no GDC.
- PROJECT_NAMESPACE: o espaço de nomes do seu projeto.
A IU do projeto contém painéis de controlo predefinidos, como o painel de controlo Alertas – Vista geral com informações sobre alertas. A consulta de alertas a partir da IU permite-lhe obter visualmente informações de alerta do seu projeto e ter uma vista integrada dos recursos para estar a par e resolver rapidamente os problemas.
Para o administrador da plataforma (PA):
Abra o seguinte URL para aceder ao ponto final do seu projeto do platform-obs:
https://GDC_URL/platform-obs/grafana
Substitua GDC_URL pelo URL da sua organização no GDC.
A interface do utilizador (IU) da instância de monitorização do sistema contém painéis de controlo predefinidos, como o painel de controlo Alertas – Vista geral com informações sobre alertas para a observabilidade de dados. A consulta de alertas a partir da IU permite-lhe obter visualmente informações de alerta do seu projeto e ter uma vista integrada dos recursos para estar a par e resolver rapidamente os problemas.

Figura 1. O painel de controlo Alertas – Vista geral na IU do Grafana.
Alertmanager
O Alertmanager permite-lhe monitorizar notificações de alertas de aplicações cliente. Pode inspecionar e silenciar alertas através do Alertmanager, bem como filtrar ou agrupar alertas:
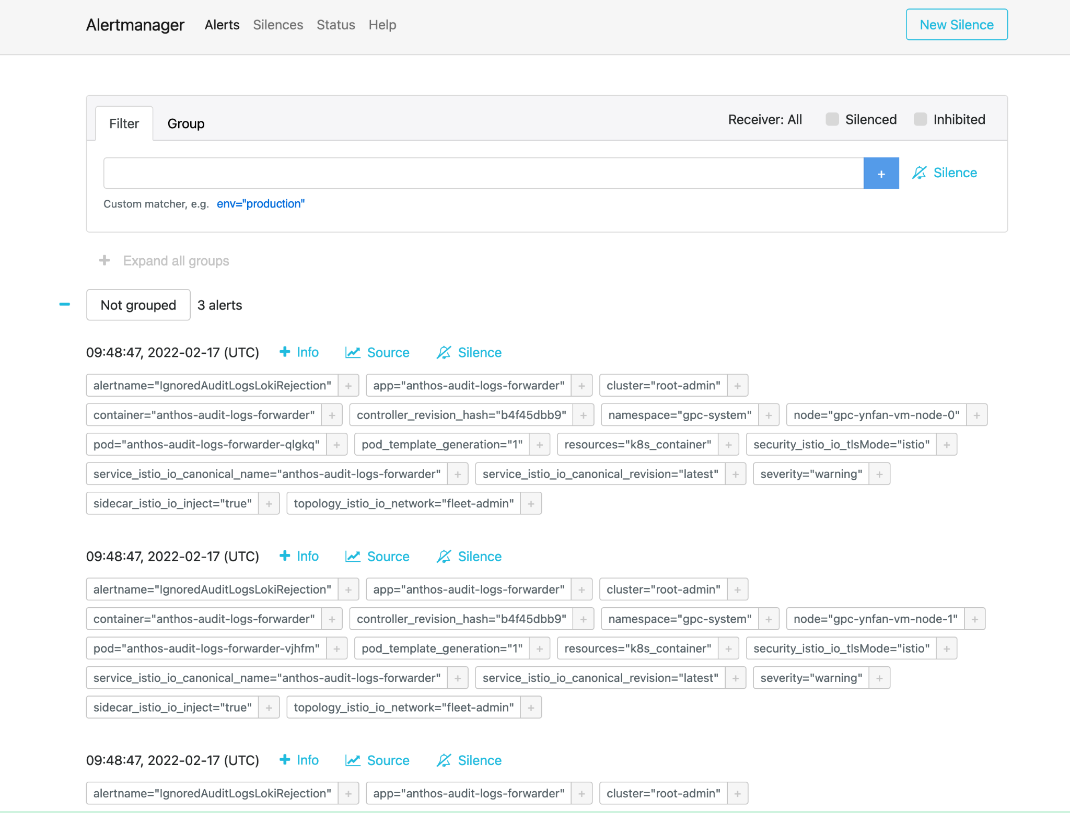
Figura 2. Opção de menu para consultar registos de auditoria a partir do Alertmanager.
Políticas de alerta predefinidas
A tabela seguinte apresenta as regras de alerta pré-instaladas no Prometheus:
| Nome | Descrição |
|---|---|
| KubeAPIDown (crítico) | A KubeAPI desapareceu da descoberta de destinos do Prometheus durante 15 minutos. |
| KubeClientErrors (aviso) | A proporção de erros do cliente do servidor da API Kubernetes é superior a 0,01 durante 15 minutos. |
| KubeClientErrors (crítico) | Rácio de erros do cliente do servidor da API Kubernetes > 0,1 durante 15 minutos. |
| KubePodCrashLooping (aviso) | O pod está num estado de ciclo de falhas há mais de 15 minutos. |
| KubePodNotReady (aviso) | O pod está num estado não pronto há mais de 15 minutos. |
| KubePersistentVolumeFillingUp (crítico) | Bytes livres de um PersistentVolume reivindicado < 0,03. |
| KubePersistentVolumeFillingUp (aviso) | Bytes livres de um PersistentVolume reivindicado < 0,15. |
| KubePersistentVolumeErrors (crítico) | O volume persistente está na fase Failed ou Pending durante cinco minutos. |
| KubeNodeNotReady (aviso) | O nó está indisponível há mais de 15 minutos. |
| KubeNodeCPUUsageHigh (crítico) | A utilização da CPU do nó é > 80%. |
| KubeNodeMemoryUsageHigh (crítico) | A utilização de memória do nó é superior a 80%. |
| NodeFilesystemSpaceFillingUp (aviso) | A utilização do sistema de ficheiros do nó é superior a 60%. |
| NodeFilesystemSpaceFillingUp (crítico) | A utilização do sistema de ficheiros do nó é superior a 85%. |
| CertManagerCertExpirySoon (aviso) | Um certificado expira dentro de 21 dias. |
| CertManagerCertNotReady (crítico) | Um certificado não está pronto para apresentar tráfego após 10 minutos. |
| CertManagerHittingRateLimits (crítico) | Foi atingido um limite de taxa na criação e renovação de certificados durante cinco minutos. |
| DeploymentNotReady (crítico). | Uma implementação no cluster de administração da organização está num estado não pronto há mais de 15 minutos. |
Exemplo de alertmanagerConfigurationConfigmaps
A sintaxe das configurações em ConfigMaps que as listas alertmanagerConfigurationConfigmaps têm de seguir https://prometheus.io/docs/alerting/latest/configuration/
apiVersion: observability.gdc.goog/v1alpha1
kind: ObservabilityPipeline
metadata:
# Choose namespace that matches the project's namespace
namespace: kube-system
name: observability-config
# Configure Alertmanager
alerting:
# Storage size for alerting data within organization
# Permission: PA
localStorageSize: 1Gi
# Permission: PA & AO
# alertmanager config must be under the key "alertmanager.yml" in the configMap
alertmanagerConfig: <configmap-for-alertmanager-config>
# Permission: PA
volumes:
- <volume referenced in volumeMounts>
# Permission: PA
volumeMounts:
- <volumeMount referenced in alertmanagerConfig>
Configuração de regras de exemplo
# Configures either an alert or a target record for precomputation
apiVersion: monitoring.gdc.goog/v1alpha1
kind: MonitoringRule
metadata:
# Choose namespace that contains the metrics that rules are based on
# Note: alert/record will be produced in the same namespace
namespace: g-fleetns-a
name: alerting-config
spec:
# Rule evaluation interval
interval: <duration>
# Configure limit for number of alerts (0: no limit)
# Optional, Default: 0 (no limit)
limit: <int>
# Configure record rules
recordRules:
# Define which timeseries to write to (must be a valid metric name)
- record: <string>
# Define PromQL expression to evaluate for this rule
expr: <string>
# Define labels to add or overwrite
# Optional, Map of {key, value} pairs
labels:
<labelname>: <labelvalue>
# Configure alert rules
alertRules:
# Define alert name
- alert: <string>
# Define PromQL expression to evaluate for this rule
# https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
expr: <string>
# Define when an active alert moves from pending to firing
# Optional, Default: 0s
for: <duration>
# Define labels to add or overwrite
# Required, Map of {key, value} pairs
# Required labels:
# severity: [error, critical, warning, info]
# code:
# resource: component/service/hardware related to alert
# additional labels are optional
labels:
severity: <enum: [error, critical, warning, info]>
code:
resource: <Short name of the related operable component>
<labelname>: <tmpl_string>
# Define annotations to add
# Optional, Map of {key, value} pairs
# Recommended annotations:
# message: value of Message field in UI
# expression: value of Rule field in UI
# runbookurl: URL for link in Actions to take field in UI
annotations:
<labelname>: <tmpl_string>
# Configures either an alert or a target record for precomputation
apiVersion: logging.gdc.goog/v1alpha1
kind: LoggingRule
metadata:
# Choose namespace that contains the logs that rules are based on
# Note: alert/record will be produced in the same namespace
namespace: g-fleetns-a
name: alerting-config
spec:
# Choose which log source to base alerts on (Operational/Audit/Security Logs)
# Optional, Default: Operational
source: <string>
# Rule evaluation interval
interval: <duration>
# Configure limit for number of alerts (0: no limit)
# Optional, Default: 0 (no limit)
limit: <int>
# Configure record rules
recordRules:
# Define which timeseries to write to (must be a valid metric name)
- record: <string>
# Define LogQL expression to evaluate for this rule
# https://grafana.com/docs/loki/latest/rules/
expr: <string>
# Define labels to add or overwrite
# Optional, Map of {key, value} pairs
labels:
<labelname>: <labelvalue>
# Configure alert rules
alertRules:
# Define alert name
- alert: <string>
# Define LogQL expression to evaluate for this rule
expr: <string>
# Define when an active alert moves from pending to firing
# Optional, Default: 0s
for: <duration>
# Define labels to add or overwrite
# Required, Map of {key, value} pairs
# Required labels:
# severity: [error, critical, warning, info]
# code:
# resource: component/service/hardware related to alert
# additional labels are optional
labels:
severity: <enum: [error, critical, warning, info]>
code:
resource: <Short name of the related operable component>
<labelname>: <tmpl_string>
# Define annotations to add
# Optional, Map of {key, value} pairs
# Recommended annotations:
# message: value of Message field in UI
# expression: value of Rule field in UI
# runbookurl: URL for link in Actions to take field in UI
annotations:
<labelname>: <tmpl_string>
Consulte alertas a partir da API HTTP
A plataforma de observabilidade expõe um ponto final da API HTTP para consultar e ler métricas, alertas e outros dados de séries cronológicas do seu projeto para monitorização do sistema.Consulte alertas diretamente a partir da API HTTP Observability para configurar tarefas automatizadas, adaptar respostas e criar integrações de acordo com o seu exemplo de utilização. Por exemplo, inserir a saída noutro comando, exportar detalhes para formatos de ficheiros de texto ou configurar uma tarefa cron do Linux. Pode chamar a API HTTP de observabilidade a partir da interface de linha de comandos (CLI) ou de um navegador de Internet e obter o resultado no formato JSON.
Esta secção explica como chamar o ponto final da API HTTP de observabilidade a partir da CLI através da especificação da API para consultar alertas.
Consulte alertas diretamente a partir da API HTTP Observability para configurar tarefas automatizadas, adaptar respostas e criar integrações de acordo com o seu exemplo de utilização. Por exemplo, inserir a saída noutro comando, exportar detalhes para formatos de ficheiros de texto ou configurar uma tarefa cron do Linux. Pode chamar a API HTTP de observabilidade a partir da interface de linha de comandos (CLI) ou de um navegador de Internet e obter o resultado no formato JSON.
Esta secção explica como chamar o ponto final da API HTTP de observabilidade a partir da CLI usando a especificação da API Alertmanager para consultar métricas.
Antes de começar
Para receber as autorizações necessárias para aceder ao ponto final da API HTTP de observabilidade, peça ao administrador de IAM do projeto que lhe conceda a função de visualizador do Alertmanager do Project Cortex (project-cortex-alertmanager-viewer) no seu espaço de nomes do projeto.
O administrador de IAM do projeto pode conceder-lhe acesso criando uma associação de funções:
a. Administrador principal do operador de infraestrutura (IO) – Project Cortex Alertmanager Viewer:
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
io-cortex-alertmanager-viewer-binding -n infra-obs
--user=fop-infrastructure-operator@example.com
--role=project-cortex-alertmanager-viewer
b. Administrador principal (PA) – Project Cortex Alertmanager Viewer:
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
pa-cortex-alertmanager-viewer-binding -n platform-obs
--user=fop-platform-admin@example.com
--role=project-cortex-alertmanager-viewer
c. Administrador principal do operador da aplicação (AO) – Leitor do Alertmanager do Project Cortex: Projeto: $AO_PROJECT Nome de utilizador do AO: $AO_USER
kubectl --kubeconfig $HOME/root-admin-kubeconfig create rolebinding
project-cortex-alertmanager-viewer-binding -n $AO_PROJECT
--user=$AO_USER
--role=project-cortex-alertmanager-viewer
Depois de criar a associação de funções, pode aceder ao Alertmanager correspondente com o seu nome de utilizador de início de sessão.
Valide a associação de funções
kubectl --kubeconfig $HOME/org-1-admin-kubeconfig get rolebinding -n platform-obs
Para ver informações sobre como definir associações de funções a partir da consola do GDC, consulte o artigo Conceda acesso a recursos.
Ponto final do Cortex
O seguinte URL é o ponto final do Cortex para aceder a alertas:
https://GDC_URL/PROJECT_NAME/cortex/alertmanager/
Substitua o seguinte:
- GDC_URL: o URL da sua organização no GDC.
- PROJECT_NAME: o nome do seu projeto.
Chame o ponto final da API
Siga estes passos para aceder ao ponto final da API Cortex a partir da CLI e consultar alertas:
- Certifique-se de que cumpre os pré-requisitos.
- Abra a CLI.
Use a ferramenta
curlpara chamar o URL do ponto final do Cortex e estenda o URL com o https://prometheus.io/docs/prometheus/latest/querying/api/#alertmanagers padrão para consultar alertas. Por exemplo:curl https://console.org-1.zone1.google.gdch.test/alice/cortex/alertmanager/api/v1/alertmanagers
Obtém a saída na CLI após o comando. O formato de resposta da API é JSON.