
Antes de começar
Se você ainda não tiver feito isso, configure um Google Cloud projeto e dois (2) buckets do Cloud Storage.
Criar o projeto
- Faça login na sua conta do Google Cloud . Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instale a CLI do Google Cloud.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instale a CLI do Google Cloud.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init
Criar ou usar dois buckets do Cloud Storage no projeto
Você precisará de dois buckets do Cloud Storage no projeto: um para arquivos de entrada e outro para saída.
- No console do Google Cloud , acesse a página Buckets do Cloud Storage.
- Clique em Criar.
- Na página Criar um bucket, insira as informações do seu bucket. Para ir à próxima
etapa, clique em Continuar.
-
Na seção Começar, faça o seguinte:
- Insira um nome globalmente exclusivo que atenda aos requisitos de nomeação de bucket.
- Para adicionar um
rótulo de bucket,
abra a seção Rótulos (),
clique em add_box
Adicionar rótulo e especifique um
keye umvaluepara o rótulo.
-
Na seção Escolha onde armazenar seus dados, faça o seguinte:
- Selecione um tipo de local.
- Escolha um local onde os dados do bucket são armazenados permanentemente no menu suspenso Tipo de local.
- Se você selecionar o tipo de local birregional, também poderá ativar a replicação turbo usando a caixa de seleção relevante.
- Para configurar a replicação entre buckets, selecione
Adicionar replicação entre buckets usando o Serviço de transferência do Cloud Storage e
siga estas etapas:
Configurar a replicação entre buckets
- No menu Bucket, selecione um bucket.
Na seção Configurações de replicação, clique em Configurar para definir as configurações do job de replicação.
O painel Configurar a replicação entre buckets aparece.
- Para filtrar objetos a serem replicados por prefixo de nome de objeto, insira um prefixo com que você quer incluir ou excluir objetos e clique em Adicionar um prefixo.
- Para definir uma classe de armazenamento para os objetos replicados, selecione uma classe de armazenamento no menu Classe de armazenamento. Se você pular esta etapa, os objetos replicados vão usar a classe de armazenamento do bucket de destino por padrão.
- Clique em Concluído.
-
Na seção Escolha como armazenar seus dados, faça o seguinte:
- Selecione uma classe de armazenamento padrão para o bucket ou Classe automática para gerenciamento automático da classe de armazenamento dos dados do bucket.
- Para ativar o namespace hierárquico, na seção Otimizar o armazenamento para cargas de trabalho com uso intensivo de dados, selecione Ativar namespace hierárquico neste bucket.
- Na seção Escolha como controlar o acesso a objetos, selecione se o bucket aplica ou não a prevenção de acesso público e selecione um método de controle de acesso para os objetos do bucket.
-
Na seção Escolha como proteger os dados do objeto, faça o
seguinte:
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
- Para ativar a exclusão reversível, clique na caixa de seleção Política de exclusão reversível (para recuperação de dados) e especifique o número de dias que você quer reter os objetos após a exclusão.
- Para definir o controle de versões de objetos, clique na caixa de seleção Controle de versões de objetos (para controle de versões) e especifique o número máximo de versões por objeto e o número de dias após os quais as versões não atuais expiram.
- Para ativar a política de retenção em objetos e buckets, clique na caixa de seleção Retenção (para compliance) e faça o seguinte:
- Para ativar o bloqueio de retenção de objetos, clique na caixa de seleção Ativar retenção de objetos.
- Para ativar o Bloqueio de buckets, clique na caixa de seleção Definir política de retenção de buckets e escolha uma unidade e um período de armazenamento para a retenção.
- Para escolher como os dados do objeto serão criptografados, expanda a seção Criptografia de dados () e selecione um método de Criptografia de dados.
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
-
Na seção Começar, faça o seguinte:
- Clique em Criar.
Criar um modelo de fluxo de trabalho
Para criar e definir um modelo de fluxo de trabalho, copie e execute os comandos a seguir em uma janela de terminal local ou no Cloud Shell.
- Crie o modelo de fluxo de trabalho.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Adicione o job de contagem de palavras ao modelo de fluxo de trabalho.
-
Especifique o output-bucket-name antes de executar o comando (a função fornecerá o bucket de entrada).
Depois que você inserir o nome do bucket de saída, o argumento do bucket de saída deverá ler da seguinte maneira:
gs://your-output-bucket/wordcount-output". -
O ID da etapa "count" é obrigatório e identifica o job do hadoop adicionado.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Especifique o output-bucket-name antes de executar o comando (a função fornecerá o bucket de entrada).
Depois que você inserir o nome do bucket de saída, o argumento do bucket de saída deverá ler da seguinte maneira:
- Use um cluster gerenciado de nó único para executar o fluxo de trabalho. O Serviço Gerenciado para Apache Spark vai criar o cluster, executar o fluxo de trabalho nele e excluir o cluster quando o fluxo de trabalho for concluído.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Clique no nome do
wordcount-templatena página Fluxos de trabalho do Serviço gerenciado para Apache Spark no console Google Cloud para abrir a página Detalhes do modelo de fluxo de trabalho. Confirme os atributos do modelo de contagem de palavras.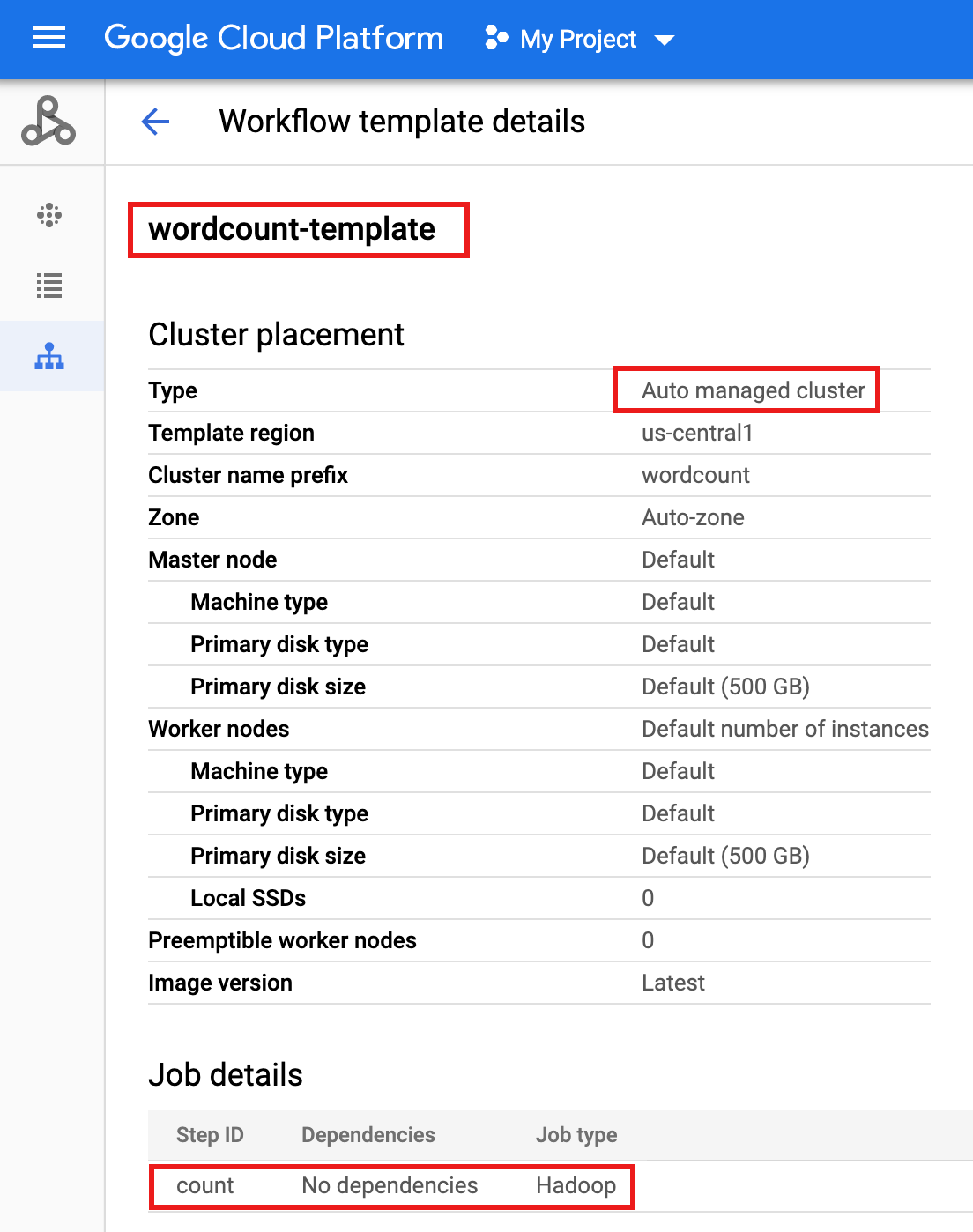
Parametrizar o modelo de fluxo de trabalho
Parametrize a variável do bucket de entrada que será transmitida para o modelo de fluxo de trabalho.
- Exporte o modelo de fluxo de trabalho para um arquivo de texto
wordcount.yamlpara parametrização.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Usando um editor de texto, abra
wordcount.yamle adicione um blocoparametersao final do arquivo YAML para que o INPUT_BUCKET_URI do Cloud Storage possa ser transmitido comoargs[1]para o binário de contagem de palavras, quando o fluxo de trabalho for acionado.Veja abaixo um exemplo de arquivo YAML exportado. Você pode adotar uma das duas abordagens para atualizar seu modelo:
- Copie e cole o arquivo inteiro para substituir o
wordcount.yamlexportado depois de substituí-lo your-output_bucket pelo nome do bucket de saída, OU - Copie e cole somente a seção
parametersno final do arquivowordcount.yamlexportado.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copie e cole o arquivo inteiro para substituir o
- Importe o arquivo de texto
wordcount.yamlparametrizado. Digite "Y" quando solicitado para substituir o modelo.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
crie uma função do Cloud
Abra a página Cloud Run functions no Google Cloud console e clique em CRIAR FUNÇÃO.
Na página Criar função, digite ou selecione as seguintes informações:
- Nome: contagem de palavras
- Memória alocada: mantenha a seleção padrão.
- Gatilho:
- Cloud Storage
- Tipo de evento: finalizar/criar
- Bucket: selecione o bucket de entrada. Consulte Criar um bucket do Cloud Storage no projeto. Quando um arquivo é adicionado a esse bucket, a função aciona o fluxo de trabalho. O fluxo de trabalho executará o aplicativo de contagem de palavras, que processará todos os arquivos de texto no bucket.
Código-fonte:
- Editor in-line
- Ambiente de execução: Node.js 8
- Guia
INDEX.JS: substitua o snippet de código padrão pelo código a seguir e edite a linhaconst projectIdpara fornecer -your-project-id- (sem um "-" inicial ou final).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Guia
PACKAGE.JSON: substitua o snippet de código padrão pelo código a seguir.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Função a ser executada: Insert: "startWorkflow".
Clique em CRIAR
Testar a função
Copie o arquivo público
rose.txtpara o bucket para acionar a função. Insira your-input-bucket-name (o bucket usado para acionar a função) no comando.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Aguarde 30 segundos e execute o seguinte comando para verificar se a função foi concluída.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Para ver os registros de função na página da lista Funções no console do Google Cloud , clique no nome da função
wordcounte depois em VER LOGS na página Detalhes da função.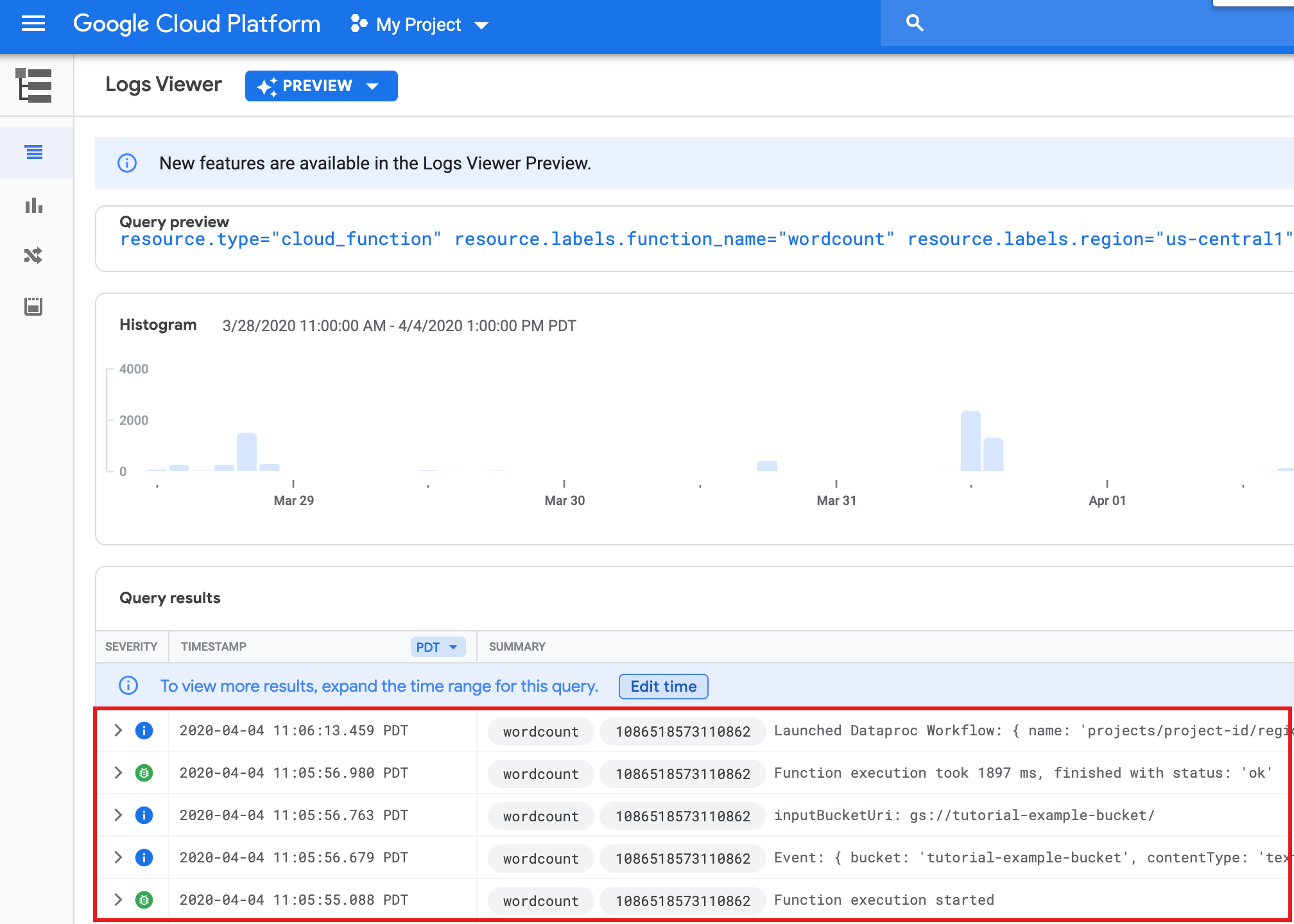
Você pode ver a pasta
wordcount-outputno bucket de saída na página Navegador de armazenamento no console doGoogle Cloud .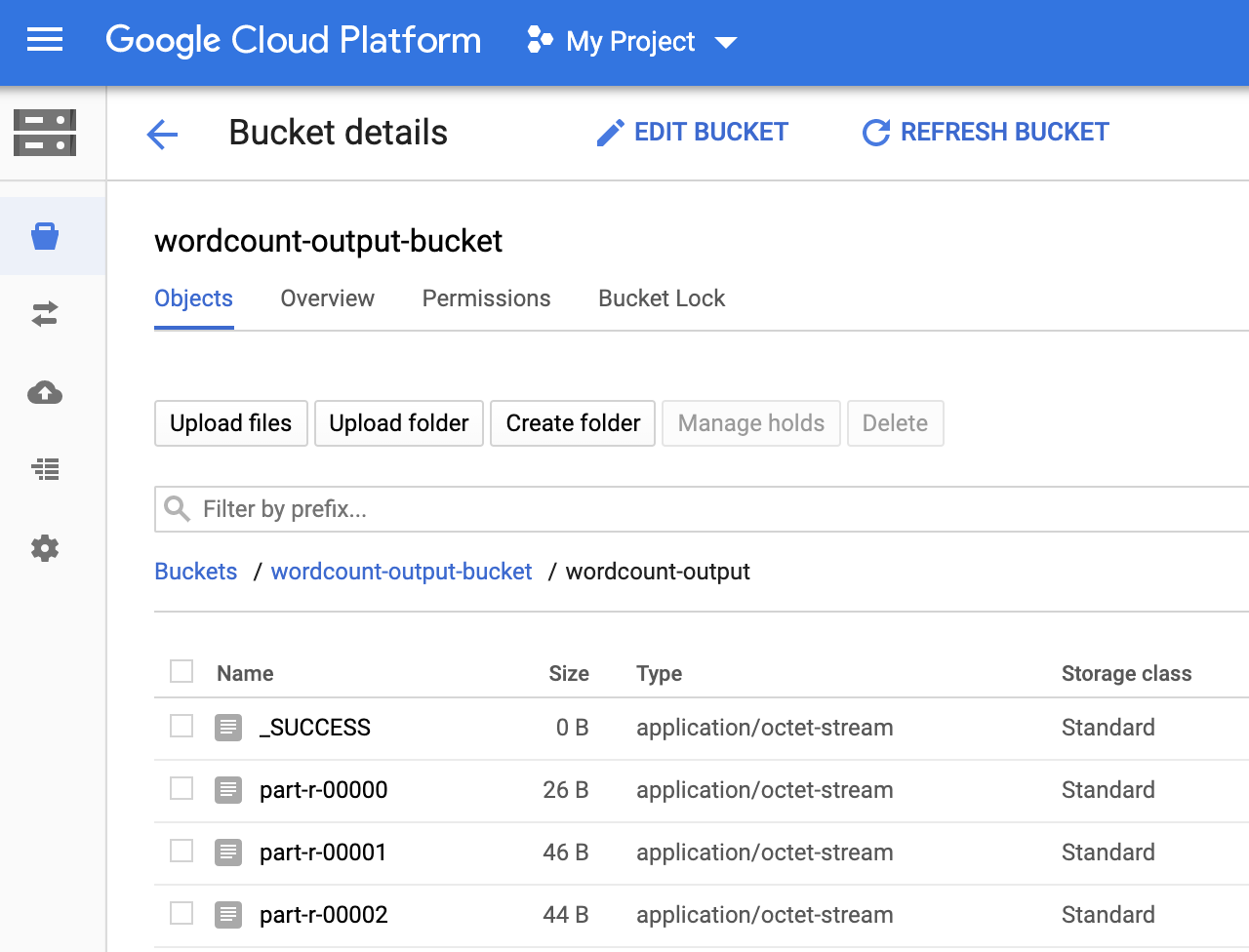
Após a conclusão do fluxo de trabalho, os detalhes do job permanecem no consoleGoogle Cloud . Clique no job
count...listado na página Jobs do Serviço Gerenciado para Apache Spark para conferir os detalhes do job do fluxo de trabalho.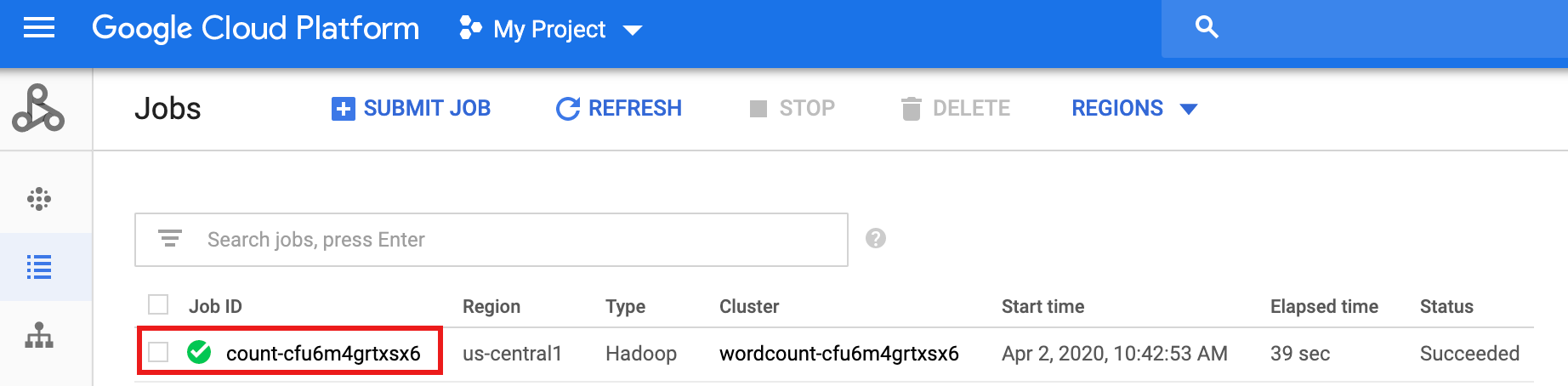
Limpar
O fluxo de trabalho neste tutorial exclui o cluster gerenciado quando o fluxo de trabalho é concluído. Para evitar custos recorrentes, exclua outros recursos associados a este tutorial.
Excluir um projeto
- No console Google Cloud , acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
Excluir buckets do Cloud Storage
- No console do Google Cloud , acesse a página Buckets do Cloud Storage.
- Clique na caixa de seleção do bucket que você quer excluir.
- Para excluir o bucket, clique em Excluir e siga as instruções.
Excluir o modelo de fluxo de trabalho
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Excluir a função do Cloud
Abra a página Funções do Cloud Run no
console do Google Cloud , marque a caixa à esquerda da função wordcount
e clique em Excluir.
A seguir
- Consulte Visão geral dos modelos de fluxo de trabalho do Serviço Gerenciado para Apache Spark.
- Consulte Soluções de programação de fluxo de trabalho.