
Esta página mostra como criar um cluster do Serviço Gerenciado para Apache Spark que usa o conector do Spark Spanner para ler e gravar dados no Spanner usando Apache Spark.
O conector do Spanner funciona com o Spark para ler dados de e gravar dados no banco de dados do Spanner usando a biblioteca Java do Spanner. O conector do Spanner oferece suporte à leitura de tabelas e gráficos do Spanner em DataFrames DataFrames e GraphFrames do Spark, e à gravação de dados do DataFrame em tabelas do Spanner.
Custos
Neste documento, você usa os seguintes componentes faturáveis do Google Cloud:
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
Para gerar uma estimativa de custo baseada na projeção de uso,
use a calculadora de preços.
Antes de começar
- Faça login na sua Google Cloud conta do. Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho dos nossos produtos em situações reais. Clientes novos também recebem US $300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Conceder os papéis necessários.
- Configure um cluster do Serviço Gerenciado para Apache Spark.
- Configure uma instância do Spanner com uma tabela de banco de dados de cantores.
Conceder os papéis necessários
Alguns papéis do IAM são necessários para executar os exemplos nesta página. Dependendo das políticas da organização, esses papéis já podem ter sido concedidos. Para verificar as concessões de papéis, consulte Você precisa conceder papéis?.
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Para garantir que a conta de serviço padrão do Compute Engine tenha as permissões necessárias para criar um cluster do Serviço Gerenciado para Apache Spark, peça ao administrador para conceder os seguintes papéis do IAM à conta de serviço padrão do Compute Engine no projeto:
-
Worker do Dataproc (
roles/dataproc.worker) -
Usuário do banco de dados do Cloud Spanner (
roles/spanner.databaseUser) -
Leitor de banco de dados do Cloud Spanner com DataBoost (
roles/spanner.databaseReaderWithDataBoost)
Configurar um cluster do Serviço Gerenciado para Apache Spark
Crie um cluster do Serviço Gerenciado para Apache Spark
ou use um cluster do Serviço Gerenciado para Apache Spark que foi criado com a
2.1 ou mais recente do Serviço Gerenciado para Apache Spark ou, se o
cluster foi criado com a 2.0 ou anterior, ele precisa ter sido criado com
a propriedade scope definida como
cloud-platform scope.
Configurar uma instância do Spanner com uma tabela de banco de dados de cantores
Crie uma instância do Spanner
com um banco de dados que contenha uma tabela Singers. Anote o ID da instância do Spanner e o ID do banco de dados.
Usar o conector do Spanner com o Spark
O conector do Spanner está disponível para as versões 3.1+ do Spark. Você
especifica a
versão do conector
como parte da especificação do arquivo JAR do conector do Cloud Storage ao
enviar um job para um cluster do
Serviço Gerenciado para Apache Spark.
Exemplo:envio de job do Spark da CLI gcloud com o conector do Spanner.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Substitua:
CONNECTOR_VERSION: versão do conector do Spanner.
Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
GoogleCloudDataproc/spark-spanner-connector.
Ler tabelas do Spanner
É possível usar o Python ou o Scala para ler dados da tabela do Spanner em um DataFrame do Spark usando a API de origem de dados do Spark.
PySpark
É possível executar o código de exemplo do PySpark nesta seção no cluster enviando o job para o Serviço Gerenciado para Apache Spark ou executando o job no REPL spark-submit no nó mestre do cluster.
Job do Serviço Gerenciado para Apache Spark
- Crie um arquivo
singers.pyusando um editor de texto local ou no Cloud Shell usando o editor de textovi,vim, ounanopré-instalado. - Depois de preencher as variáveis do marcador, cole o código a seguir
no arquivo
singers.py. Observe que o recurso do Spanner Data Boost está ativado, o que tem um impacto quase zero na instância principal do Spanner.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Substitua:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no painel do Google Cloud console Dashboard.
- INSTANCE_ID, DATABASE_ID, e TABLE_NAME : consulte
Configurar uma instância do Spanner com a tabela de banco de dados
Singers.
- Salve o arquivo
singers.py. - Envie o job
para o Serviço Gerenciado para Apache Spark usando o Google Cloud console, a CLI gcloud ou
a API REST.
Exemplo:envio de job da CLI gcloud com o conector do Spanner.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarSubstitua:
- CLUSTER_NAME: o nome do novo cluster.
- REGION: uma região disponível do Compute Engine para executar a carga de trabalho.
- CONNECTOR_VERSION: versão do conector do Spanner.
Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
GoogleCloudDataproc/spark-spanner-connector.
Job spark-submit
- Conecte-se ao nó mestre do cluster do Serviço Gerenciado para Apache Spark usando SSH.
- Acesse a página Clusters do Serviço Gerenciado para Apache Spark no Google Cloud console e clique no nome do cluster.
- Na página Detalhes do cluster, selecione a guia Instâncias de VM. Em seguida, clique em
SSHà direita do nome do nó mestre do cluster.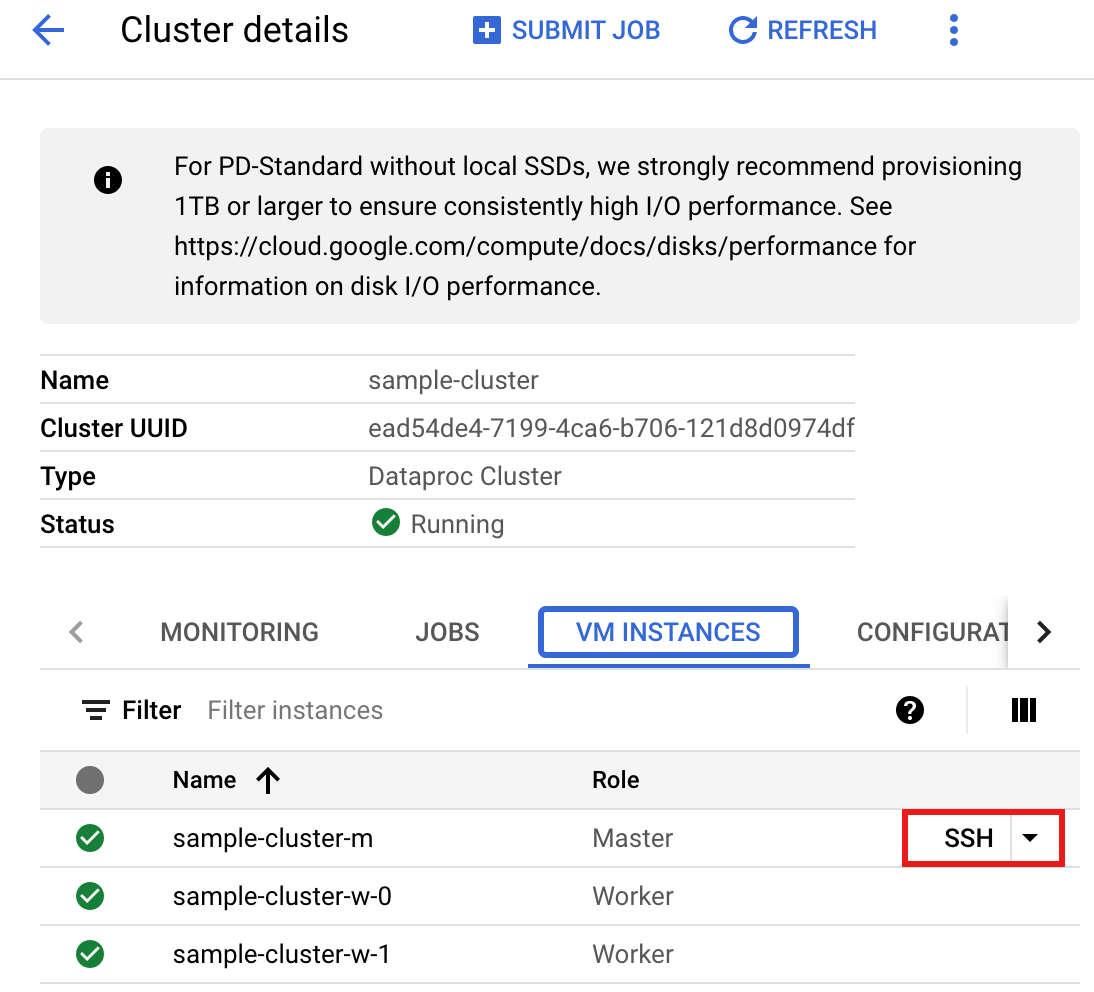
Uma janela de navegador é aberta no diretório inicial do nó mestre.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crie um arquivo
singers.pyno nó mestre usando o editor de textovi,vimounanopré-instalado.- Cole o código a seguir no arquivo
singers.pydepois de preencher as variáveis do marcador no arquivosingers.py. Observe que o recurso do Spanner Data Boost está ativado, o que tem um impacto quase zero na instância principal do Spanner.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Substitua:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no painel do Google Cloud console Dashboard.
- INSTANCE_ID, DATABASE_ID, e TABLE_NAME : consulte
Configurar uma instância do Spanner com a tabela de banco de dados
Singers.
- Salve o arquivo
singers.py.
- Cole o código a seguir no arquivo
- Execute
singers.pycomspark-submitpara criar a tabelaSingersdo Spanner.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Substitua:
- CONNECTOR_VERSION: versão do conector do Spanner.
Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
GoogleCloudDataproc/spark-spanner-connector.
A resposta é:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: versão do conector do Spanner.
Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
Scala
Para executar o código de exemplo do Scala no cluster, siga estas etapas:
- Conecte-se ao nó mestre do cluster do Serviço Gerenciado para Apache Spark usando SSH.
- Acesse a página Clusters do Serviço Gerenciado para Apache Spark no Google Cloud console e clique no nome do cluster.
- Na página Detalhes do cluster, selecione a guia Instâncias de VM. Em seguida, clique em
SSHà direita do nome do nó mestre do cluster.
Uma janela de navegador é aberta no diretório inicial do nó mestre.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crie um arquivo
singers.scalano nó mestre usando o editor de textovi,vimounanopré-instalado.- Cole o código a seguir no arquivo
singers.scala. Observe que o recurso do Spanner Data Boost está ativado, o que tem um impacto quase zero na instância principal do Spanner.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Substitua:
- PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no painel do Google Cloud console Dashboard.
- INSTANCE_ID, DATABASE_ID, e TABLE_NAME : consulte
Configurar uma instância do Spanner com a tabela de banco de dados
Singers.
- Salve o arquivo
singers.scala.
- Cole o código a seguir no arquivo
- Inicie o REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Substitua:
CONNECTOR_VERSION: versão do conector do Spanner. Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
GoogleCloudDataproc/spark-spanner-connector. - Execute
singers.scalacom o comando:load singers.scalapara criar a tabelaSingersdo Spanner. A listagem de saída mostra exemplosda saída de cantores.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Ler gráficos do Spanner
O conector do Spanner oferece suporte à exportação do gráfico para
DataFrames de nós e arestas separados
bem como à exportação diretamente para
GraphFrames.
O exemplo a seguir exporta um Spanner para um GraphFrame. Ele
usa a classe SpannerGraphConnectordo Python, incluída no
jar do conector do Spanner, para ler o
gráfico do Spanner.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Substitua:
- CONNECTOR_VERSION: versão do conector do Spanner.
Escolha a versão do conector do Spanner na lista de versões no repositório do GitHub
GoogleCloudDataproc/spark-spanner-connector. - PROJECT_ID: o ID do projeto do Google Cloud . Os IDs do projeto estão listados na seção Informações do projeto no painel do Google Cloud console Dashboard.
- INSTANCE_ID, DATABASE_ID, e TABLE_NAME: insira os IDs da instância, do banco de dados e do gráfico.
Para exportar nós e arestas DataFrames em vez de GraphFrames, use load_dfs:
df_vertices, df_edges, df_id_map = connector.load_dfs()
Gravar tabelas do Spanner
O conector do Spanner oferece suporte à gravação de um DataFrame do Spark em uma tabela do Spanner usando a API de origem de dados do Spark.
Exemplo de gravação de DataFrame na tabela do Spanner
Preencha as variáveis antes de salvar e executar o código.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
Substitua:
- PROJECT_ID: o Google Cloud ID do projeto. Os IDs do projeto estão listados na seção Informações do projeto no painel do Google Cloud console Dashboard.
- INSTANCE_ID, DATABASE_ID, e TABLE_NAME: insira os IDs da instância, do banco de dados e da tabela.
Limpar
Para evitar cobranças contínuas na sua Google Cloud conta, é possível interromper ou excluir o cluster do Serviço Gerenciado para Apache Spark e excluir a instância do Spanner.
A seguir
- Consulte os
pyspark.sql.DataFrameexemplos. - Para suporte a idiomas do DataFrame do Spark, consulte o seguinte:
- Consulte o repositório do conector do Spark Spanner no GitHub.
- Consulte as dicas de ajuste de jobs do Spark.