
Halaman ini menunjukkan cara membuat cluster Managed Service untuk Apache Spark yang menggunakan konektor Spark Spanner untuk membaca data dari dan menulis data ke Spanner menggunakan Apache Spark.
Konektor Spanner berfungsi dengan Spark untuk membaca data dari dan menulis data ke database Spanner menggunakan library Java Spanner. Konektor Spanner mendukung pembacaan tabel dan grafik Spanner ke dalam DataFrames dan GraphFrames Spark, serta penulisan data DataFrame ke dalam tabel Spanner.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Berikan peran yang diperlukan.
- Siapkan cluster Managed Service untuk Apache Spark.
- Siapkan instance Spanner dengan tabel database Singers.
Memberikan peran yang diperlukan
Peran IAM tertentu diperlukan untuk menjalankan contoh di halaman ini. Bergantung pada kebijakan organisasi, peran ini mungkin sudah diberikan. Untuk memeriksa pemberian peran, lihat Apakah Anda perlu memberikan peran?.
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Untuk memastikan bahwa akun layanan default Compute Engine memiliki izin yang diperlukan untuk membuat cluster Managed Service for Apache Spark, minta administrator Anda untuk memberikan peran IAM berikut ke akun layanan default Compute Engine di project:
-
Worker Dataproc (
roles/dataproc.worker) -
Pengguna Database Cloud Spanner (
roles/spanner.databaseUser) -
Cloud Spanner Database Reader dengan DataBoost (
roles/spanner.databaseReaderWithDataBoost)
Menyiapkan cluster Managed Service untuk Apache Spark
Buat cluster Managed Service untuk Apache Spark
atau gunakan cluster Managed Service untuk Apache Spark yang sudah ada yang dibuat dengan
image Managed Service untuk Apache Spark 2.1 atau yang lebih baru atau, jika
cluster dibuat dengan image 2.0 atau yang lebih lama, cluster harus dibuat dengan
setelan properti scope ke
cakupan cloud-platform.
Menyiapkan instance Spanner dengan tabel database Singers
Buat instance Spanner
dengan database yang berisi tabel Singers. Catat ID instance
Spanner dan ID database.
Menggunakan konektor Spanner dengan Spark
Konektor Spanner tersedia untuk Spark versi 3.1+. Anda
menentukan
versi konektor
sebagai bagian dari spesifikasi file JAR konektor Cloud Storage saat Anda
mengirimkan tugas ke cluster
Managed Service untuk Apache Spark.
Contoh: Pengiriman tugas Spark gcloud CLI dengan konektor Spanner.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Ganti kode berikut:
CONNECTOR_VERSION: Versi konektor Spanner.
Pilih versi konektor Spanner dari daftar versi di repositori GitHub
GoogleCloudDataproc/spark-spanner-connector.
Membaca tabel Spanner
Anda dapat menggunakan Python atau Scala untuk membaca data tabel Spanner ke dalam DataFrame Spark menggunakan Spark Data Source API.
PySpark
Anda dapat menjalankan contoh kode PySpark di bagian ini pada cluster dengan mengirimkan tugas ke layanan Managed Service untuk Apache Spark atau dengan menjalankan tugas dari REPL spark-submit di node master cluster.
Tugas Managed Service untuk Apache Spark
- Buat file
singers.pymenggunakan editor teks lokal atau di Cloud Shell menggunakan editor teksvi,vim, ataunanoyang telah diinstal sebelumnya. - Setelah mengisi variabel placeholder, tempelkan kode berikut
ke dalam file
singers.py. Perhatikan bahwa fitur Data Boost Spanner diaktifkan, yang hampir tidak berdampak pada instance Spanner utama.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ganti kode berikut:
- PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Dasbor Google Cloud konsol.
- INSTANCE_ID, DATABASE_ID, dan TABLE_NAME : Lihat
Menyiapkan instance Spanner dengan tabel database
Singers.
- Simpan file
singers.py. - Kirimkan tugas
ke Managed Service for Apache Spark menggunakan konsol Google Cloud , gcloud CLI, atau
REST API.
Contoh: Pengiriman tugas gcloud CLI dengan konektor Spanner.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarGanti kode berikut:
- CLUSTER_NAME: Nama cluster baru.
- REGION: Region Compute Engine yang tersedia untuk menjalankan beban kerja.
- CONNECTOR_VERSION: Versi konektor Spanner.
Pilih versi konektor Spanner dari daftar versi di repositori GitHub
GoogleCloudDataproc/spark-spanner-connector.
Tugas spark-submit
- Hubungkan ke node master cluster Managed Service untuk Apache Spark menggunakan SSH.
- Buka halaman Managed Service for Apache Spark Clusters di konsol Google Cloud , lalu klik nama cluster Anda.
- Di halaman Cluster details, pilih tab VM Instances. Kemudian, klik
SSHdi sebelah kanan nama node master cluster.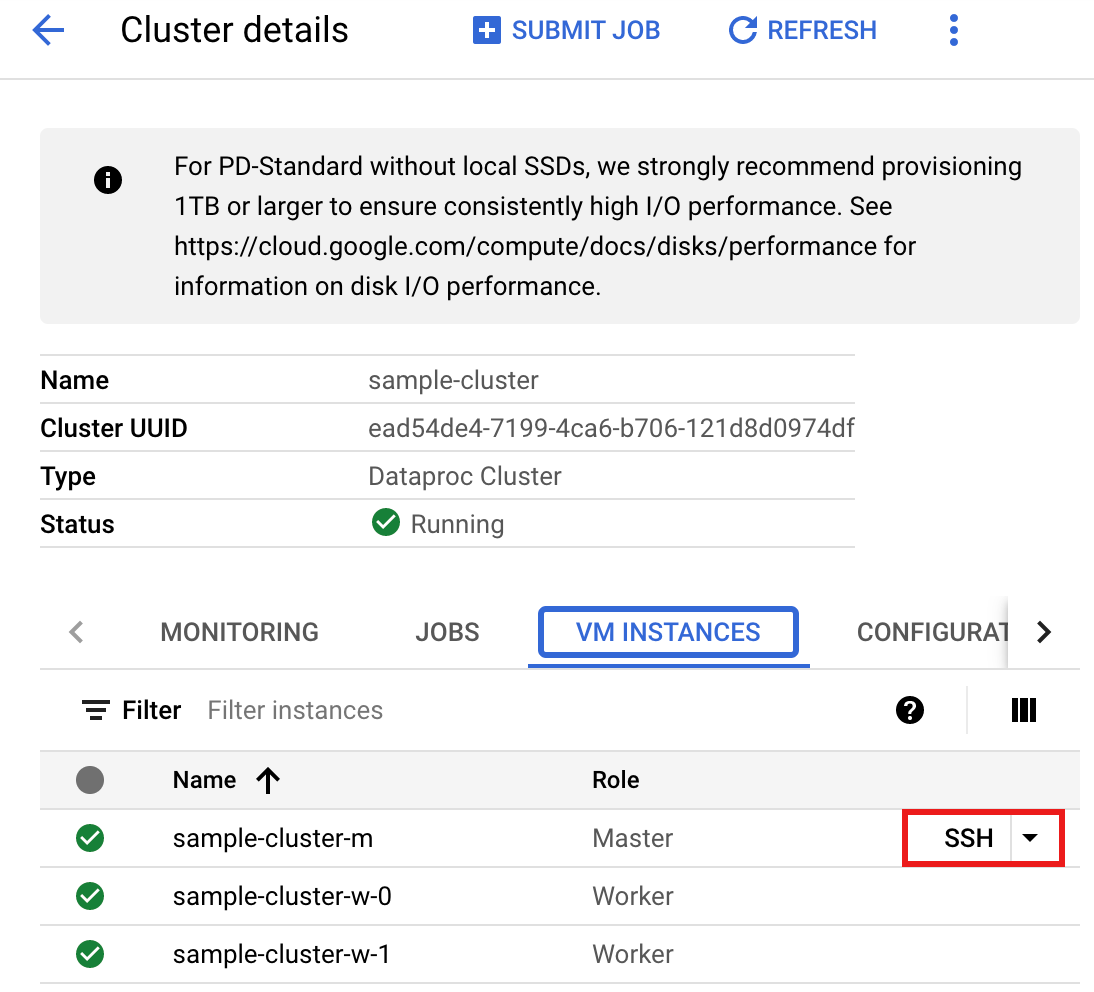
Jendela browser akan terbuka di direktori beranda Anda di node master.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Buat file
singers.pydi node master menggunakan editor teksvi,vim, ataunanoyang telah diinstal sebelumnya.- Tempelkan kode berikut ke dalam file
singers.pysetelah mengisi variabel placeholder ke dalam filesingers.py. Perhatikan bahwa fitur Data Boost Spanner diaktifkan, yang hampir tidak berdampak pada instance Spanner utama.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ganti kode berikut:
- PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Dasbor Google Cloud konsol.
- INSTANCE_ID, DATABASE_ID, dan TABLE_NAME : Lihat
Menyiapkan instance Spanner dengan tabel database
Singers.
- Simpan file
singers.py.
- Tempelkan kode berikut ke dalam file
- Jalankan
singers.pydenganspark-submituntuk membuat tabelSingersSpanner.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Ganti kode berikut:
- CONNECTOR_VERSION: Versi konektor Spanner.
Pilih versi konektor Spanner dari daftar versi di repositori GitHub
GoogleCloudDataproc/spark-spanner-connector.
Outputnya adalah:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: Versi konektor Spanner.
Pilih versi konektor Spanner dari daftar versi di repositori GitHub
Scala
Untuk menjalankan contoh kode Scala di cluster Anda, selesaikan langkah-langkah berikut:
- Hubungkan ke node master cluster Managed Service untuk Apache Spark menggunakan SSH.
- Buka halaman Managed Service for Apache Spark Clusters di konsol Google Cloud , lalu klik nama cluster Anda.
- Di halaman Cluster details, pilih tab VM Instances. Kemudian, klik
SSHdi sebelah kanan nama node master cluster.
Jendela browser akan terbuka di direktori beranda Anda di node master.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Buat file
singers.scaladi node master menggunakan editor teksvi,vim, ataunanoyang telah diinstal sebelumnya.- Tempelkan kode berikut ke dalam file
singers.scala. Perhatikan bahwa fitur Data Boost Spanner diaktifkan, yang hampir tidak berdampak pada instance Spanner utama.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Ganti kode berikut:
- PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Dasbor Google Cloud konsol.
- INSTANCE_ID, DATABASE_ID, dan TABLE_NAME : Lihat
Menyiapkan instance Spanner dengan tabel database
Singers.
- Simpan file
singers.scala.
- Tempelkan kode berikut ke dalam file
- Luncurkan REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Ganti kode berikut:
CONNECTOR_VERSION: Versi konektor Spanner. Pilih versi konektor Spanner dari daftar versi di repositori GitHub
GoogleCloudDataproc/spark-spanner-connector. - Jalankan
singers.scaladengan perintah:load singers.scalauntuk membuat tabelSingersSpanner. Output listing menampilkan contoh dari output Penyanyi.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Membaca grafik Spanner
Konektor Spanner mendukung ekspor grafik ke dalam
node dan edge
DataFrames
terpisah serta ekspor ke
GraphFrames
secara langsung.
Contoh berikut mengekspor Spanner ke GraphFrame. Class
Python SpannerGraphConnector, yang disertakan dalam
file jar konektor Spanner, digunakan untuk membaca
Spanner Graph.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Ganti kode berikut:
- CONNECTOR_VERSION: Versi konektor Spanner.
Pilih versi konektor Spanner dari daftar versi di repositori GitHub
GoogleCloudDataproc/spark-spanner-connector. - PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Google Cloud Dasbor konsol.
- INSTANCE_ID, DATABASE_ID, dan TABLE_NAME Insert the instance, database, and graph IDs.
Untuk mengekspor node dan tepi DataFrames, bukan GraphFrames, gunakan load_dfs
sebagai gantinya:
df_vertices, df_edges, df_id_map = connector.load_dfs()
Menulis tabel Spanner
Konektor Spanner mendukung penulisan Spark Dataframe ke tabel Spanner menggunakan Spark Data Source API.
Contoh penulisan DataFrame ke tabel Spanner
Isi variabel sebelum menyimpan dan menjalankan kode.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
Ganti kode berikut.
- PROJECT_ID: Google Cloud Project ID. Project ID tercantum di bagian Project info di Google Cloud Dasbor konsol.
- INSTANCE_ID, DATABASE_ID, dan TABLE_NAME Insert the instance, database, and table IDs.
Pembersihan
Untuk menghindari tagihan berkelanjutan ke akun Anda, Anda dapat menghentikan atau menghapus cluster Managed Service untuk Apache Spark dan menghapus instance Spanner. Google Cloud
Langkah berikutnya
- Lihat
contoh
pyspark.sql.DataFrame. - Untuk dukungan bahasa DataFrame Spark, lihat hal berikut:
- Lihat repositori Spark Spanner Connector di GitHub.
- Lihat Tips penyesuaian tugas Spark.