
Cette page explique comment créer un cluster Managed Service pour Apache Spark qui utilise le connecteur Spark Spanner pour lire et écrire des données dans Spanner à l'aide d'Apache Spark.
Le connecteur Spanner fonctionne avec Spark pour lire des données depuis et écrire des données dans la base de données Spanner à l'aide de la bibliothèque Java Spanner. Le connecteur Spanner permet de lire les tables et les graphiques Spanner dans les DataFrames DataFrames et les GraphFrames GraphFrames Spark, et d'écrire des données DataFrame dans les tables Spanner.
Coûts
Dans ce document, vous utilisez les composants facturables de suivants Google Cloud:
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
Obtenez une estimation des coûts en fonction de votre utilisation prévue,
utilisez le simulateur de coût.
Avant de commencer
- Connectez-vous à votre Google Cloud compte. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Attribuez les rôles requis.
- Configurez un cluster Managed Service pour Apache Spark.
- Configurez une instance Spanner avec une table de base de données Singers.
Attribuer les rôles requis
Certains rôles IAM sont requis pour exécuter les exemples de cette page. En fonction des règles d'administration, ces rôles peuvent déjà avoir été attribués. Pour vérifier les attributions de rôles, consultez la section Devez-vous attribuer des rôles ?.
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Pour vous assurer que le compte de service Compute Engine par défaut dispose des autorisations nécessaires pour créer un cluster Managed Service pour Apache Spark, demandez à votre administrateur d'attribuer les rôles IAM suivants au compte de service Compute Engine par défaut dans le projet :
-
Nœud de calcul Dataproc (
roles/dataproc.worker) -
Utilisateur de bases de données Cloud Spanner (
roles/spanner.databaseUser) -
Lecteur de bases de données Cloud Spanner avec DataBoost (
roles/spanner.databaseReaderWithDataBoost)
Configurer un cluster Managed Service pour Apache Spark
Créez un cluster Managed Service pour Apache Spark
ou utilisez un cluster Managed Service pour Apache Spark existant créé avec l'image Managed Service pour Apache Spark
2.1 ou une version ultérieure. Si le
cluster a été créé avec l'image 2.0 ou une version antérieure, la propriété scope doit être définie sur
cloud-platform.
Configurer une instance Spanner avec une table de base de données Singers
Créez une instance Spanner
avec une base de données contenant une table Singers. Notez l'ID de l'instance Spanner et l'ID de la base de données.
Utiliser le connecteur Spanner avec Spark
Le connecteur Spanner est disponible pour les versions 3.1+ de Spark. Vous
spécifiez la
version du connecteur
dans le cadre de la spécification du fichier JAR du connecteur Cloud Storage lorsque vous
envoyez une tâche à un
cluster Managed Service pour Apache Spark.
Exemple : Envoi d'une tâche Spark à l'aide de la gcloud CLI avec le connecteur Spanner.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Remplacez les éléments suivants :
CONNECTOR_VERSION : version du connecteur Spanner.
Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
GoogleCloudDataproc/spark-spanner-connector.
Lire les tables Spanner
Vous pouvez utiliser Python ou Scala pour lire les données de table Spanner dans un DataFrame Spark à l'aide de l' API de source de données Spark.
PySpark
Vous pouvez exécuter l'exemple de code PySpark de cette section sur votre cluster en envoyant la tâche au service Managed Service pour Apache Spark ou en exécutant la tâche à partir du REPL spark-submit sur le nœud maître du cluster.
Tâche Managed Service pour Apache Spark
- Créez un fichier
singers.pydans à l'aide d'un éditeur de texte local ou dans Cloud Shell à l'aide de l'éditeur de texte préinstallévi,vim, ounano. - Après avoir renseigné les variables d'espace réservé, collez le code suivant
dans le fichier
singers.py. Notez que la fonctionnalité Data Boost de Spanner est activée, ce qui a un impact quasiment nul sur l'instance Spanner principale.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre Google Cloud projet. Les ID de projet sont listés dans la section Informations sur le projet du tableau Google Cloud de bord de la console.
- INSTANCE_ID, DATABASE_ID, et TABLE_NAME : consultez
Configurer une instance Spanner avec une table de base de données
Singers.
- Enregistrez le fichier
singers.py. - Envoyez la tâche
à Managed Service pour Apache Spark à l'aide de la Google Cloud console, de gcloud CLI ou de l'
API REST.
Exemple : Envoi d'une tâche à l'aide de la gcloud CLI avec le connecteur Spanner.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarRemplacez les éléments suivants :
- CLUSTER_NAME : nom du nouveau cluster.
- REGION : région Compute Engine disponible pour exécuter la charge de travail.
- CONNECTOR_VERSION : version du connecteur Spanner.
Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
GoogleCloudDataproc/spark-spanner-connector.
Tâche spark-submit
- Connectez-vous au nœud maître du cluster Managed Service pour Apache Spark à l'aide de SSH.
- Accédez à la page Clusters de Managed Service pour Apache Spark dans la Google Cloud console, puis cliquez sur le nom de votre cluster.
- Sur la page Détails du cluster, sélectionnez l'onglet Instances de VM. Cliquez ensuite sur
SSHà droite du nom du nœud maître du cluster.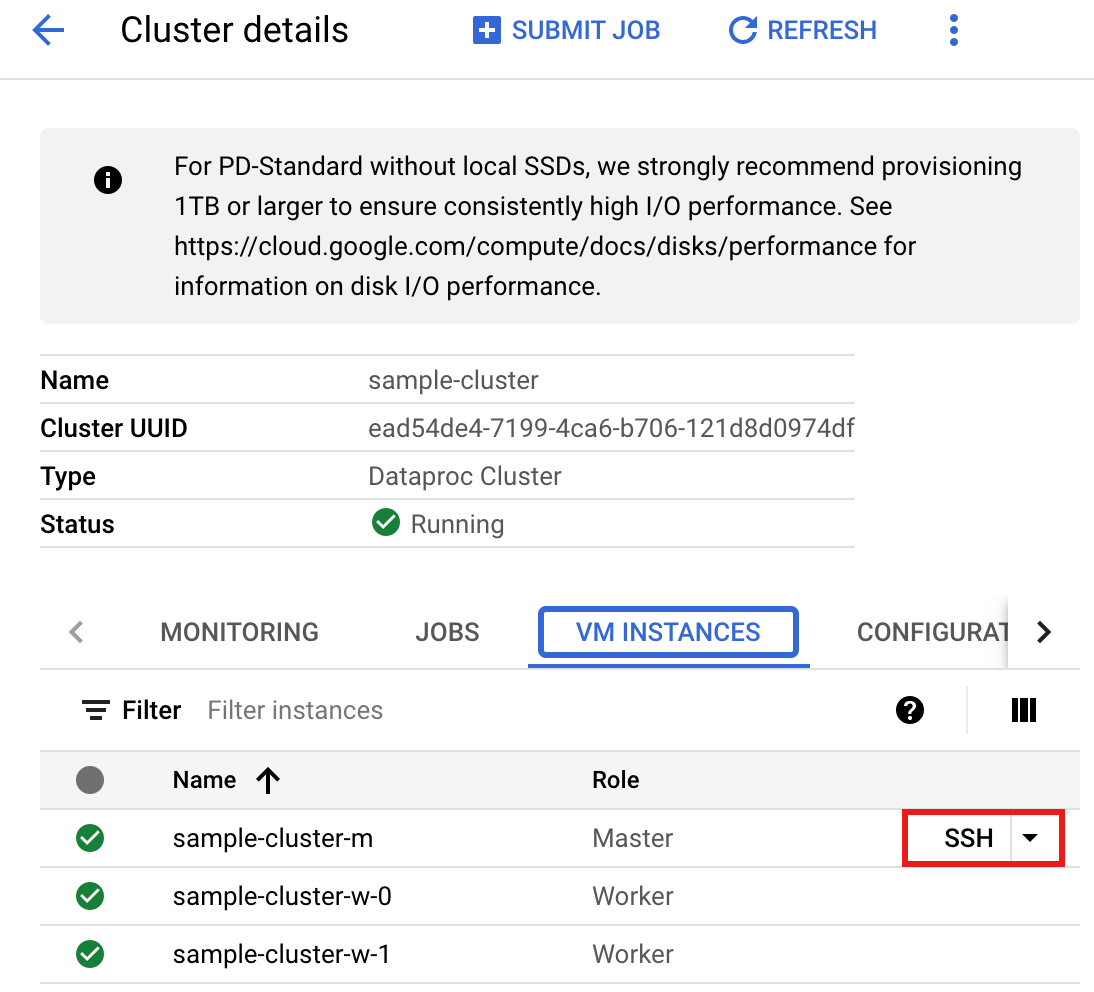
Une fenêtre de navigateur s'ouvre dans votre répertoire de base sur le nœud maître.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Créez un fichier
singers.pysur le nœud maître à l'aide de l'éditeur de texte préinstallévi,vim, ounano.- Collez le code suivant dans le fichier
singers.pyaprès avoir renseigné les variables d'espace réservé dans le fichiersingers.py. Notez que la fonctionnalité Spanner Data Boost est activée, ce qui a un impact quasiment nul sur l'instance Spanner principale.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre Google Cloud projet. Les ID de projet sont listés dans la section Informations sur le projet du tableau Google Cloud de bord de la console.
- INSTANCE_ID, DATABASE_ID, et TABLE_NAME : consultez
Configurer une instance Spanner avec une table de base de données
Singers.
- Enregistrez le fichier
singers.py.
- Collez le code suivant dans le fichier
- Exécutez
singers.pyavecspark-submitpour créer la table SpannerSingers.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Remplacez les éléments suivants :
- CONNECTOR_VERSION : version du connecteur Spanner.
Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
GoogleCloudDataproc/spark-spanner-connector.
Voici le résultat :
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION : version du connecteur Spanner.
Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
Scala
Pour exécuter l'exemple de code Scala sur votre cluster, procédez comme suit :
- Connectez-vous au nœud maître du cluster Managed Service pour Apache Spark à l'aide de SSH.
- Accédez à la page Clusters de Managed Service pour Apache Spark dans la Google Cloud console, puis cliquez sur le nom de votre cluster.
- Sur la page Détails du cluster, sélectionnez l'onglet Instances de VM. Cliquez ensuite sur
SSHà droite du nom du nœud maître du cluster.
Une fenêtre de navigateur s'ouvre dans votre répertoire de base sur le nœud maître.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Créez un fichier
singers.scalasur le nœud maître à l'aide de l'éditeur de texte préinstallévi,vim, ounano.- Collez le code suivant dans le fichier
singers.scala. Notez que la fonctionnalité Spanner Data Boost est activée, ce qui a un impact quasiment nul sur l'instance Spanner principale.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre Google Cloud projet. Les ID de projet sont listés dans la section Informations sur le projet du tableau Google Cloud de bord de la console.
- INSTANCE_ID, DATABASE_ID, et TABLE_NAME : consultez
Configurer une instance Spanner avec une table de base de données
Singers.
- Enregistrez le fichier
singers.scala.
- Collez le code suivant dans le fichier
- Lancez le REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Remplacez les éléments suivants :
CONNECTOR_VERSION : version du connecteur Spanner. Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
GoogleCloudDataproc/spark-spanner-connector. - Exécutez
singers.scalaavec la commande:load singers.scalapour créer la table SpannerSingers. La liste de sortie affiche des exemples de la sortie Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Lire les graphiques Spanner
Le connecteur Spanner permet d'exporter le graphique dans des
DataFrames de nœuds et d'arêtes distincts
DataFrames
, ainsi que directement dans
GraphFrames.
L'exemple suivant exporte un Spanner dans un GraphFrame. Il
utilise la classe Python SpannerGraphConnector, incluse dans le
fichier JAR du connecteur Spanner, pour lire le
Spanner Graph.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Remplacez les éléments suivants :
- CONNECTOR_VERSION : version du connecteur Spanner.
Choisissez la version du connecteur Spanner dans la liste des versions du dépôt GitHub
GoogleCloudDataproc/spark-spanner-connector. - PROJECT_ID : ID de votre Google Cloud projet. Les ID de projet sont listés dans la section Informations sur le projet sur le Google Cloud tableau de bord de la console.
- INSTANCE_ID, DATABASE_ID, et TABLE_NAME : insérez les ID de l'instance, de la base de données et du graphique.
Pour exporter des DataFrames de nœuds et d'arêtes au lieu de GraphFrames, utilisez load_dfs :
df_vertices, df_edges, df_id_map = connector.load_dfs()
Écrire des tables Spanner
Le connecteur Spanner permet d'écrire un DataFrame Spark dans une table Spanner à l'aide de l' API de source de données Spark.
Exemple d'écriture d'un DataFrame dans une table Spanner
Renseignez les variables avant d'enregistrer et d'exécuter le code.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
Remplacez les éléments suivants.
- PROJECT_ID : ID du Google Cloud projet. Les ID de projet sont listés dans la section Informations sur le projet sur le Google Cloud tableau de bord de la console.
- INSTANCE_ID, DATABASE_ID et TABLE_NAME : insérez les ID de l'instance, de la base de données et de la table.
Libérer de l'espace
Pour éviter d'être facturé en continu sur votre Google Cloud compte, vous pouvez arrêter ou supprimer votre cluster Managed Service pour Apache Spark et supprimer votre instance Spanner.
Étape suivante
- Reportez-vous aux
pyspark.sql.DataFrameexemples. - Pour en savoir plus sur les langages compatibles avec Spark DataFrame, consultez les pages suivantes :
- Reportez-vous au dépôt du connecteur Spark Spanner sur GitHub.
- Consultez les conseils pour régler des tâches Spark.