
Vous pouvez afficher, rechercher, filtrer et archiver les journaux de tâches et de clusters Managed Service pour Apache Spark dans Cloud Logging.
Consultez la page Tarifs de Google Cloud Observability pour comprendre vos coûts.
Consultez la section Durée de conservation des journaux pour obtenir plus d'informations sur la conservation des journaux.
Consultez la page Exclusions de journaux pour désactiver tous les journaux ou en exclure de Logging.
Consultez la page Présentation du routage et du stockage pour acheminer des journaux de Logging vers Cloud Storage, BigQuery ou Pub/Sub.
Niveaux de journalisation des composants
Définissez les niveaux de journalisation de Spark, Hadoop, Flink et d'autres composants Managed Service pour Apache Spark avec des propriétés de cluster log4j spécifiques aux composants, telles que hadoop-log4j, lorsque vous créez un cluster. Les niveaux de journalisation des composants basés sur le cluster s'appliquent aux daemons de service, tels que le ResourceManager YARN, et aux jobs exécutés sur le cluster.
Si les propriétés log4j ne sont pas compatibles avec un composant, tel que le composant Presto, écrivez une action d'initialisation qui modifie le fichier log4j.properties ou log4j2.properties du composant.
Niveaux de journalisation des composants spécifiques aux jobs : vous pouvez également définir des niveaux de journalisation des composants lorsque vous envoyez un job. Ces niveaux de journalisation sont appliqués au job et prévalent sur les niveaux de journalisation définis lors de la création du cluster. Pour en savoir plus, consultez Propriétés du cluster et du job.
Niveaux de journalisation des versions des composants Spark et Hive :
Les composants Spark 3.3.X et Hive 3.X utilisent des propriétés log4j2, tandis que les versions précédentes de ces composants utilisent des propriétés log4j (voir Apache Log4j2).
Utilisez un préfixe spark-log4j: pour définir les niveaux de journalisation Spark sur un cluster.
Exemple : Managed Service pour Apache Spark version 2.0 de l'image avec Spark 3.1 pour définir
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Exemple : Managed Service pour Apache Spark version d'image 2.1 avec Spark 3.3 pour définir
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Niveaux de journalisation des pilotes de jobs
Managed Service pour Apache Spark utilise un niveau de journalisation par défaut de INFO pour les programmes de pilotes de job. Vous pouvez modifier ce paramètre pour un ou plusieurs packages avec l'indicateur --driver-log-levels de la commande gcloud dataproc jobs submit.
Exemple :
Définissez le niveau de journalisation DEBUG lorsque vous envoyez un job Spark qui lit des fichiers Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Exemple :
Définissez le niveau de l'enregistreur root sur WARN et le niveau de l'enregistreur com.example sur INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Niveaux de journalisation de l'exécuteur Spark
Pour configurer les niveaux de journalisation de l'exécuteur Spark :
Préparer un fichier de configuration log4j, puis l'importer dans Cloud Storage
Faites référence à votre fichier de configuration lorsque vous envoyez le job.
Exemple :
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark télécharge le fichier de propriétés Cloud Storage dans le répertoire de travail local de la tâche, référencé sous le nom file:<name> dans -Dlog4j.configuration.
Journaux des jobs Managed Service pour Apache Spark dans Logging
Pour savoir comment activer les journaux du pilote de job Managed Service pour Apache Spark dans Logging, consultez Résultats et journaux des jobs Managed Service pour Apache Spark.
Accéder aux journaux de tâches dans Logging
Accédez aux journaux des jobs Managed Service pour Apache Spark à l'aide de l'explorateur de journaux, de la commande gcloud logging ou de l'API Logging.
Console
Les journaux de conteneurs YARN et de pilotes de tâches Managed Service pour Apache Spark sont répertoriés sous la ressource Tâche Cloud Managed Service pour Apache Spark.
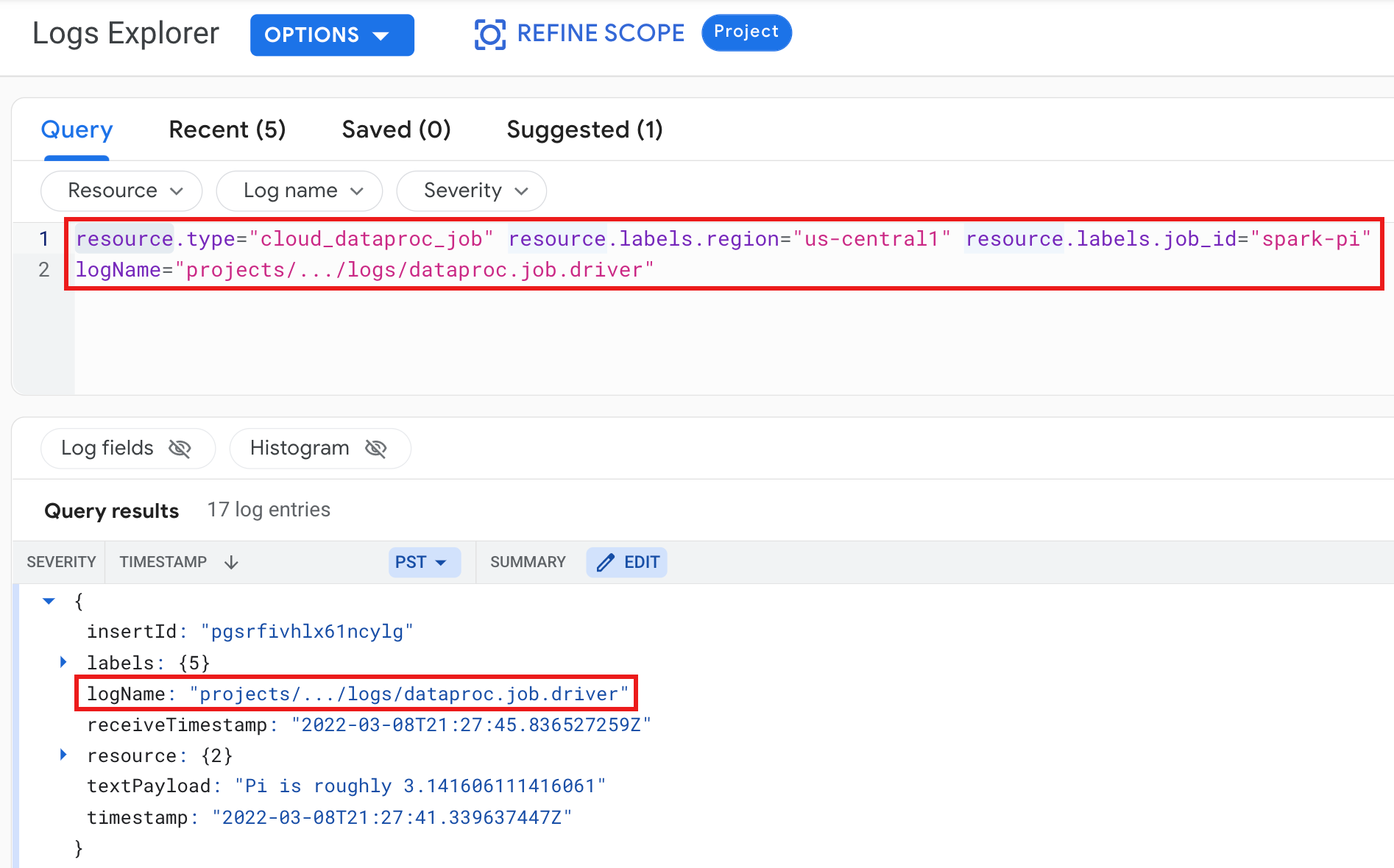
Exemple : Journal du pilote de job après l'exécution d'une requête dans l'explorateur de journaux avec les sélections suivantes :
- Ressource :
Cloud Dataproc Job - Nom du journal :
dataproc.job.driver
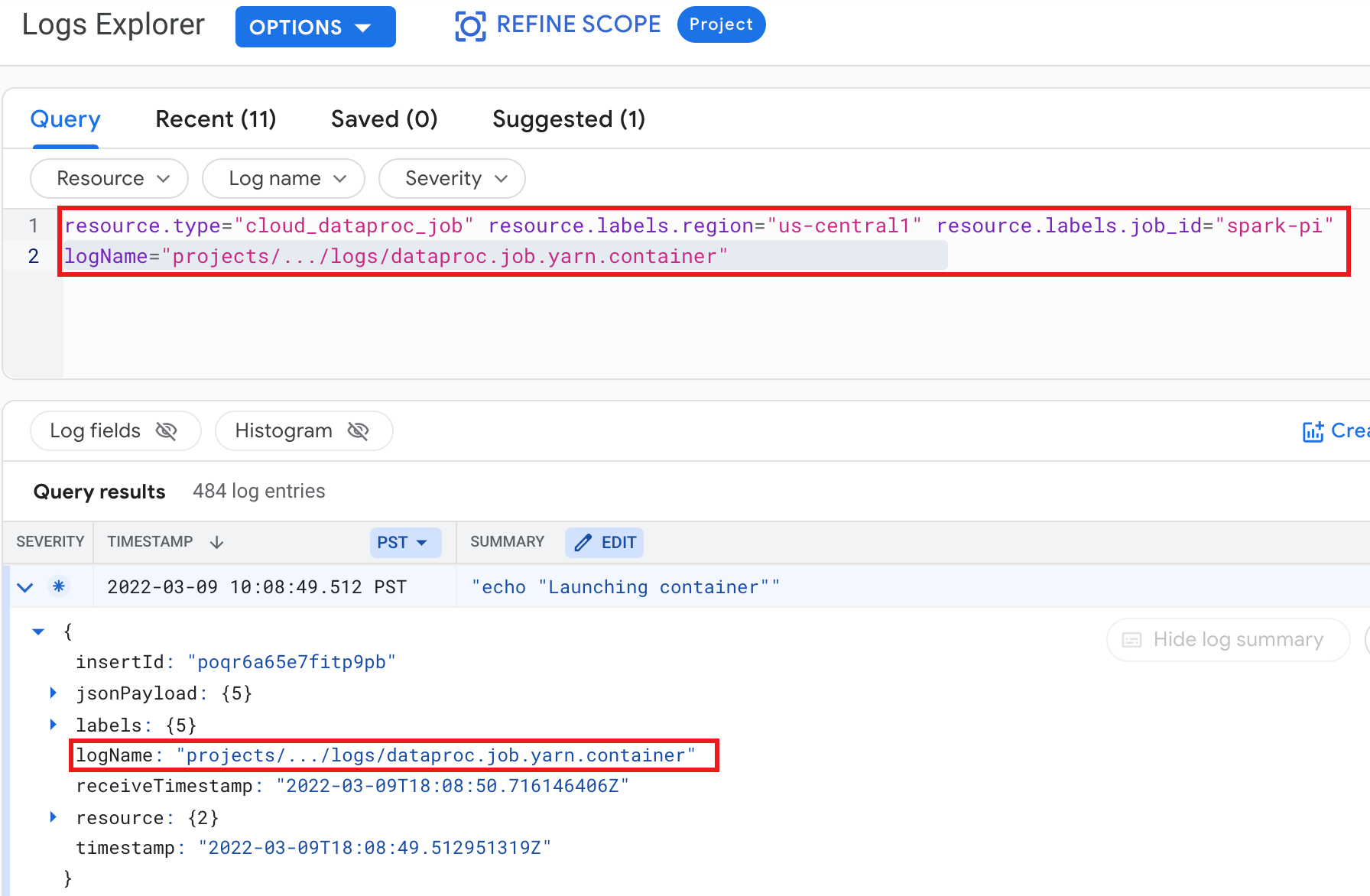
Exemple : Journal de conteneur YARN après l'exécution d'une requête de l'explorateur de journaux avec les sélections suivantes :
- Ressource :
Cloud Dataproc Job - Nom du journal :
dataproc.job.yarn.container
gcloud
Vous pouvez lire les entrées de journal de tâches à l'aide de la commande gcloud logging read. Les arguments de la ressource doivent être placés entre guillemets ("..."). La commande suivante filtre les entrées de journal renvoyées à l'aide de libellés de cluster.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Exemple de résultat (partiel) :
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API REST
Vous pouvez utiliser l'API REST Logging pour répertorier les entrées de journal (consultez la page sur entries.list).
Journaux des clusters Managed Service pour Apache Spark dans Logging
Managed Service pour Apache Spark exporte les journaux de clusters Apache Hadoop, Spark, Hive et Zookeeper suivants ainsi que d'autres journaux de clusters Managed Service pour Apache Spark vers Cloud Logging.
| Type de journal | Nom du journal | Description | Remarques |
|---|---|---|---|
| Journaux de daemons maîtres | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 hadoop-mapred-historyserver zookeeper |
Noeud de journal Composant NameNode HDFS Composant NameNode secondaire HDFS Contrôleur de basculement Zookeeper Gestionnaire de ressources YARN YARN Timeline Server Magasin de métadonnées Hive Hive Server 2 Serveur d'historique de tâches MapReduce Serveur Zookeeper |
|
| Journaux de daemons de calcul |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
Composant DataNode HDFS Gestionnaire des nœuds YARN |
|
| Journaux système |
autoscaler google.dataproc.agent google.dataproc.startup |
Journal de l'autoscaler Managed Service pour Apache Spark Journal de l'agent Managed Service pour Apache Spark Journal du script de démarrage Managed Service pour Apache Spark + journal de l'action d'initialisation |
|
| Journaux étendus (supplémentaires) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Tous les journaux des sous-répertoires /var/log/ correspondant à :knox (y compris gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Définir la propriété
dataproc:dataproc.logging.extended.enabled=false désactive la collecte des journaux étendus sur le cluster.
|
| Journaux syslog de VM |
syslog |
Journaux système des nœuds maîtres et de calcul du cluster |
Définir la propriété
dataproc:dataproc.logging.syslog.enabled=false désactive la collecte des journaux système de VM sur le cluster.
|
Accéder aux journaux de cluster dans Cloud Logging
Vous pouvez accéder aux journaux des clusters Managed Service pour Apache Spark à l'aide de l'explorateur de journaux, de la commande gcloud logging ou de l'API Logging.
Console
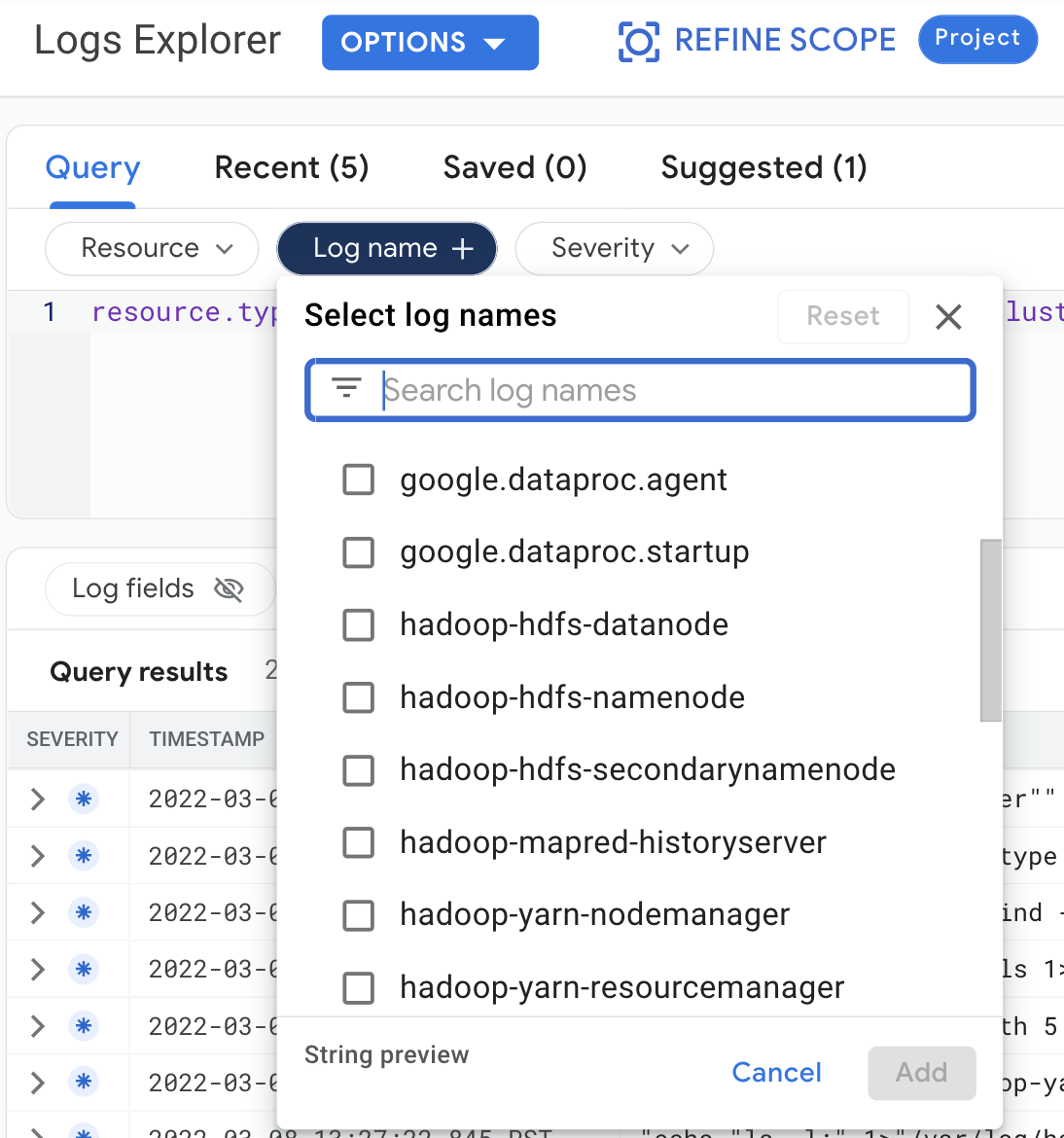
Sélectionnez les requêtes suivantes pour afficher les journaux de cluster dans l'explorateur de journaux :
- Ressource :
Cloud Dataproc Cluster - Nom du journal : log name
gcloud
Vous pouvez lire les entrées de journal de clusters à l'aide de la commande gcloud logging read. Les arguments de la ressource doivent être placés entre guillemets ("..."). La commande suivante filtre les entrées de journal renvoyées à l'aide de libellés de cluster.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Exemple de résultat (partiel) :
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API REST
Vous pouvez utiliser l'API REST Logging pour répertorier les entrées de journal (consultez la page sur entries.list).
Autorisations
Pour écrire des journaux dans Logging, le compte de service des VM Managed Service pour Apache Spark doit disposer du rôle IAM logging.logWriter. Le compte de service Managed Service pour Apache Spark par défaut détient ce rôle. Si vous utilisez un compte de service personnalisé, vous devez attribuer ce rôle au compte de service.
Protéger les journaux
Par défaut, les journaux dans Logging sont chiffrés au repos. Vous pouvez activer les clés de chiffrement gérées par le client (CMEK) pour chiffrer les journaux. Pour en savoir plus sur la compatibilité avec les CMEK, consultez Gérer les clés qui protègent les données du routeur de journaux et Gérer les clés qui protègent les données de stockage de Logging.
Étapes suivantes
- Explorez Google Cloud Observability.