
Anda dapat menggunakan spark-bigquery-connector
dengan Managed Service untuk Apache Spark untuk membaca dan menulis data dari dan ke BigQuery. Tutorial ini menunjukkan aplikasi PySpark yang menggunakan spark-bigquery-connector.
Mengonfirmasi versi konektor
Lihat Rilis runtime Managed Service untuk Apache Spark untuk menentukan versi konektor BigQuery yang diinstal di versi runtime sesi interaktif atau workload batch Anda. Jika konektor tidak tercantum, lihat Membuat konektor tersedia untuk aplikasi.
Membuat konektor tersedia untuk aplikasi (jika diperlukan)
Konektor BigQuery diinstal di semua
versi runtime Managed Service untuk Apache Spark yang didukung.
Jika Anda menggunakan versi runtime yang tidak didukung
yang tidak menginstal konektor (Spark runtime 1.0), Anda dapat membuat konektor tersedia untuk
aplikasi dengan salah satu dari dua cara berikut:
- Gunakan parameter
jarsuntuk mengarah ke file jar konektor saat Anda mengirimkan workload batch Managed Service untuk Apache Spark atau menjalankan sesi interaktif. Contoh workload batch berikut menentukan file jar konektor (lihat repositori GoogleCloudDataproc/spark-bigquery-connector di GitHub untuk mengetahui daftar file jar konektor yang tersedia).- Contoh Google Cloud CLI:
gcloud dataproc batches submit pyspark \ --region=REGION \ --jars=spark-3.5-bigquery-version.jar \ ... other args
- Contoh Google Cloud CLI:
Menghitung biaya
Tutorial ini menggunakan komponen yang dapat ditagih Google Cloud, termasuk:
- Managed Service untuk Apache Spark
- BigQuery
- Cloud Storage
Gunakan Kalkulator Harga untuk membuat perkiraan biaya berdasarkan penggunaan yang Anda proyeksikan.
Mengonfigurasi penagihan
Secara default, project yang terkait dengan kredensial atau akun layanan akan ditagih untuk penggunaan API. Untuk menagih project lain, tetapkan properti konfigurasi berikut: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Anda juga dapat menambahkan properti ini ke operasi baca atau tulis, sebagai berikut:
.option("parentProject", "<BILLED-GCP-PROJECT>").
Mengirimkan workload batch wordcount PySpark
Contoh ini membaca data dari BigQuery ke dalam DataFrame Spark untuk melakukan penghitungan kata menggunakan API sumber data standar.
Konektor menulis output wordcount ke BigQuery dalam urutan operasi berikut:
Menyimpan data ke dalam file sementara di bucket Cloud Storage Anda
Menyalin data dalam satu operasi dari bucket Cloud Storage ke BigQuery
Menghapus file sementara di Cloud Storage setelah operasi pemuatan BigQuery selesai (file sementara juga dihapus setelah aplikasi Spark dihentikan). Jika penghapusan gagal, Anda harus menghapus file Cloud Storage sementara yang tidak diinginkan, yang biasanya ditempatkan di
gs://BUCKET_NAME/.spark-bigquery-JOB_ID-UUID.
Langkah-langkah untuk menjalankan workload wordcount
- Buka terminal lokal atau Cloud Shell.
- Buat
wordcount_datasetdengan alat command line bq di terminal lokal atau di Cloud Shell.bq mk wordcount_dataset
- Buat bucket Cloud Storage dengan
Google Cloud CLI.
gcloud storage buckets create gs://BUCKET_NAME
BUCKET_NAMEdengan nama bucket Cloud Storage yang Anda buat. - Buat file
wordcount.pysecara lokal di editor teks dengan menyalin kode PySpark berikut.#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Cloud Storage bucket used by the connector for temporary BigQuery # export data. bucket = "BUCKET_NAME" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data.samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Kirimkan workload batch PySpark:
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=BUCKET_NAME
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Untuk melihat pratinjau tabel output di Google Cloud konsol, buka halaman BigQuery, pilih tabelwordcount_output, lalu klik Pratinjau.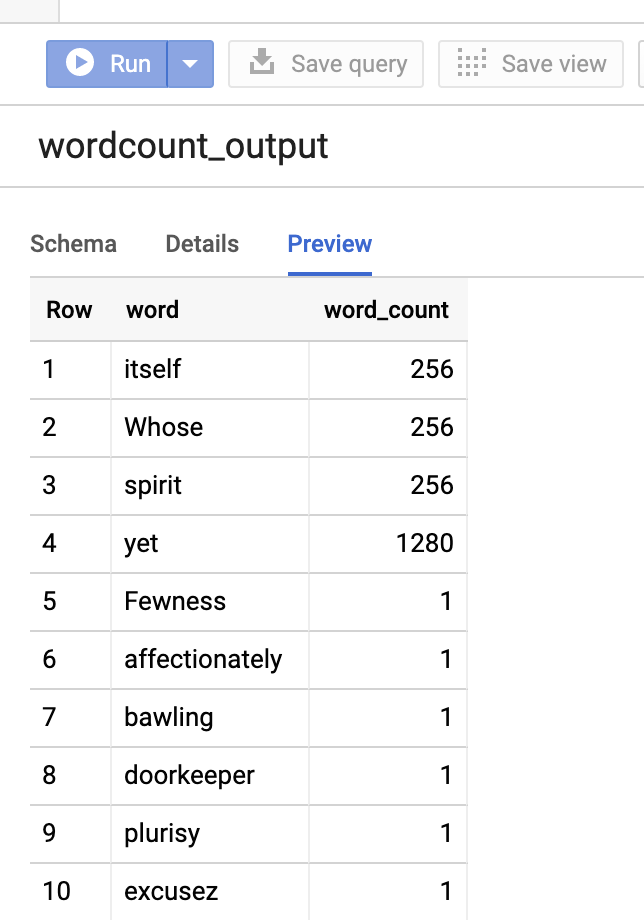
Gambar 1: Melihat pratinjau tabel output di BigQuery
Untuk informasi selengkapnya
- BigQuery Storage &Spark SQL - Python
- Membuat file definisi tabel untuk sumber data eksternal
- Menggunakan data yang dipartisi secara eksternal