
本文說明如何啟用 Lightning Engine,加快 Managed Service for Apache Spark 批次工作負載和互動式工作階段的執行速度。
總覽
Lightning Engine 是高效能的查詢加速器,搭載多層最佳化引擎,可執行查詢和執行最佳化等常見最佳化技術,以及檔案系統層和資料存取連線程式中的精選最佳化。
如下圖所示,Lightning Engine 可加速執行類似 TPC-H 的工作負載 (10 TB 資料集大小),提升 Spark 查詢執行效能。
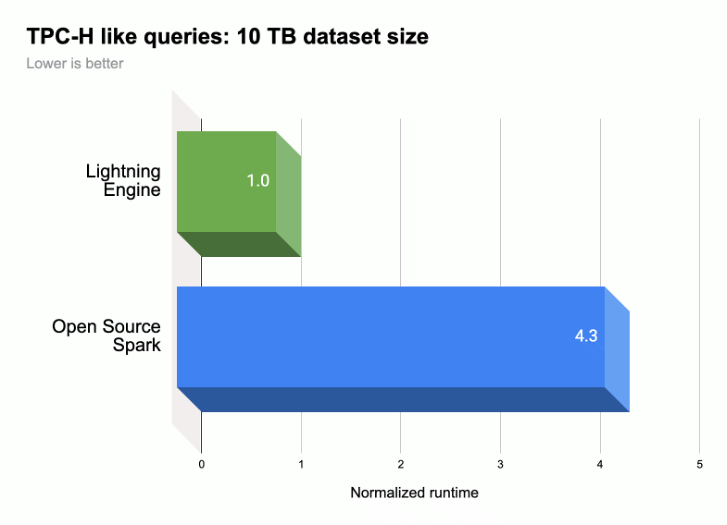
詳情請參閱「隆重推出 Lightning Engine:新一代的 Apache Spark 效能大幅提升」。
Lightning Engine 適用情形
- Lightning Engine 適用於 Managed Service for Apache Spark 執行階段 2.3。
- Lightning Engine 僅適用於 Managed Service for Apache Spark 的進階定價層級。
- 批次工作負載:系統會自動為進階層級的批次工作負載啟用 Lightning Engine。您無須採取任何行動。
- 互動式工作階段:根據預設,互動式工作階段不會啟用 Lightning Engine。如要啟用,請參閱「啟用 Lightning Engine」。
- 工作階段範本:工作階段範本預設不會啟用 Lightning Engine。如要啟用,請參閱「啟用 Lightning Engine」。
啟用 Lightning Engine
以下各節說明如何在 Managed Service for Apache Spark 批次工作負載、工作階段範本和互動式工作階段中啟用 Lightning 引擎。
批次工作負載
為批次工作負載啟用 Lightning Engine
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Dataproc API,在批次工作負載上啟用 Lightning Engine。
控制台
使用 Google Cloud 控制台在批次工作負載上啟用 Lightning Engine。
在 Google Cloud 控制台中:
- 前往 Managed Service for Apache Spark Batches。
- 按一下「建立」,開啟「建立批次」頁面。
選取並填寫下列欄位:
- 容器:
- 執行階段版本:選取
2.3。
- 執行階段版本:選取
層級設定:
- 選取「
Premium」。系統會自動啟用並勾選「啟用 Lightning Engine 來提高 Spark 效能」。
選取進階層級時,「驅動程式運算層級」和「執行器運算層級」會設為
Premium。如果批次作業使用的執行階段早於3.0,就無法覆寫這些自動設定的進階級運算設定。您可以將「Driver Disk Tier」(驅動程式磁碟層級) 和「Executor Disk Tier」(執行器磁碟層級) 設為
Premium,或保留預設的Standard層級值。如果選擇進階磁碟層級,則必須選取磁碟大小。詳情請參閱資源分配屬性。- 選取「
屬性:選用:輸入下列
Key(屬性名稱) 和Value配對,選取「原生查詢執行」執行階段:鍵 值 spark.dataproc.lightningEngine.runtime原生
- 容器:
填寫、選取或確認其他批次工作負載設定。請參閱「提交 Spark 批次工作負載」。
按一下「提交」,執行 Spark 批次工作負載。
gcloud
設定下列 gcloud CLI
gcloud dataproc batches submit spark
指令標記,在批次工作負載上啟用 Lightning 引擎。
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
注意:
- PROJECT_ID:您的 Google Cloud 專案 ID。 專案 ID 會列在 Google Cloud 控制台資訊主頁的「Project info」(專案資訊) 部分。
- REGION:可執行工作負載的 Compute Engine 區域。
--properties=dataproc.tier=premium。 設定進階層級時,系統會自動為批次工作負載設定下列屬性:spark.dataproc.engine=lightningEngine為批次工作負載選取 Lightning Engine。spark.dataproc.driver.compute.tier和spark.dataproc.executor.compute.tier設為premium(請參閱資源分配屬性)。如果批次作業使用的執行階段早於3.0,就無法覆寫這些自動設定的進階級運算設定。
其他屬性
OTHER_FLAGS_AS_NEEDED:請參閱「提交 Spark 批次工作負載」。
API
如要在批次工作負載上啟用 Lightning Engine,請在 batches.create 要求中執行下列操作:
- 將 RuntimeConfig.version 設為
2.3。 將「dataproc.tier」:「premium」新增至 RuntimeConfig.properties。設定進階層級時,系統會自動為批次工作負載設定下列屬性:
spark.dataproc.engine=lightningEngine為批次工作負載選取 Lightning Engine。spark.dataproc.driver.compute.tier和spark.dataproc.executor.compute.tier設為premium(請參閱資源分配屬性)。如果批次作業使用的執行階段早於3.0,就無法覆寫這些自動設定的進階級運算設定。
其他 RuntimeConfig.properties:
原生查詢引擎:
spark.dataproc.lightningEngine.runtime:native。 如要選取「原生查詢執行」執行階段,請新增這項屬性。磁碟層級和大小:根據預設,驅動程式和執行器磁碟大小會設為
standard層級和大小。您可以新增屬性,選取premium層級和大小 (以375 GiB的倍數)。
詳情請參閱資源分配屬性。
如要設定其他批次工作負載 API 欄位,請參閱「提交 Spark 批次工作負載」。
工作階段範本
在工作階段範本上啟用 Lightning Engine
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Dataproc API,在 Jupyter 或 Spark Connect 工作階段的範本中啟用 Lightning Engine。
控制台
使用 Google Cloud 控制台在批次工作負載上啟用 Lightning Engine。
在 Google Cloud 控制台中:
- 前往 Managed Service for Apache Spark 工作階段範本。
- 按一下「建立」,開啟「建立工作階段範本」頁面。
選取並填寫下列欄位:
填寫、選取或確認其他工作階段範本設定。請參閱「建立工作階段範本」。
按一下「提交」,建立工作階段範本。
gcloud
您無法使用 gcloud CLI 直接建立 Managed Service for Apache Spark 工作階段範本。您可以改用 gcloud beta dataproc session-templates import 指令匯入現有的工作階段範本,編輯匯入的範本以啟用 Lightning Engine 和 (選用) Native Query 執行階段,然後使用 gcloud beta dataproc session-templates export 指令匯出編輯後的範本。
API
如要在工作階段範本上啟用 Lightning Engine,請在 sessionTemplates.create 要求中執行下列操作:
- 將 RuntimeConfig.version 設為
2.3。 - 將「dataproc.tier」:「premium」和「spark.dataproc.engine」:「lightningEngine」新增至 RuntimeConfig.properties。
其他 RuntimeConfig.properties:
- 原生查詢引擎:
spark.dataproc.lightningEngine.runtime:native: 將這個屬性新增至 RuntimeConfig.properties, 選取 Native Query Execution 執行階段。
如要設定其他工作階段範本 API 欄位,請參閱「建立工作階段範本」。
互動工作階段
在互動工作階段中啟用 Lightning Engine
您可以使用 Google Cloud CLI 或 Dataproc API,在 Managed Service for Apache Spark 互動式工作階段中啟用 Lightning Engine。您也可以在 BigQuery Studio 筆記本的互動式工作階段中啟用 Lightning Engine。
gcloud
設定下列 gcloud CLI gcloud beta dataproc sessions create spark 指令標記,在互動式工作階段中啟用 Lightning Engine。
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
注意:
- PROJECT_ID:您的 Google Cloud 專案 ID。 專案 ID 會列在 Google Cloud 控制台資訊主頁的「Project info」(專案資訊) 部分。
- REGION:可執行工作負載的 Compute Engine 區域。
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine。 這些屬性會在工作階段中啟用 Lightning Engine。其他屬性:
- 原生查詢引擎:
spark.dataproc.lightningEngine.runtime=native: 新增這項屬性,即可選取原生查詢執行執行階段。
- 原生查詢引擎:
OTHER_FLAGS_AS_NEEDED:請參閱「建立互動式工作階段」。
API
如要在工作階段中啟用 Lightning Engine,請在 sessions.create 要求中執行下列操作:
- 將 RuntimeConfig.version 設為
2.3。 - 將「dataproc.tier」:「premium」和「spark.dataproc.engine」:「lightningEngine」新增至 RuntimeConfig.properties。
其他 RuntimeConfig.properties:
- 原生查詢引擎:
spark.dataproc.lightningEngine.runtime:native: 如要選取「原生查詢執行」執行階段,請將這個屬性新增至 RuntimeConfig.properties。
如要設定其他工作階段範本 API 欄位,請參閱「建立互動工作階段」。
BigQuery 筆記本
在 BigQuery Studio PySpark 筆記本中建立工作階段時,可以啟用 Lightning Engine。
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
確認 Lightning Engine 設定
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Dataproc API,驗證批次工作負載、工作階段範本或互動式工作階段的 Lightning Engine 設定。
批次工作負載
工作階段範本
互動工作階段
原生查詢執行
原生查詢執行 (NQE) 是 Lightning Engine 的選用功能,可透過以 Apache Gluten 和 Velox 為基礎的原生實作項目提升效能,專為 Google 硬體產品設計。
原生查詢執行階段包含統一的記憶體管理功能,可在堆外和堆內記憶體之間動態切換,不必變更現有的 Spark 設定。NQE 擴大支援運算子、函式和 Spark 資料類型,並具備智慧功能,可自動找出使用原生引擎的機會,以執行最佳的下推作業。
找出原生查詢執行工作負載
在下列情況下使用原生查詢執行:
從 Parquet 和 ORC 檔案讀取資料的 Spark DataFrame API、Spark Dataset API 和 Spark SQL 查詢。輸出檔案格式不會影響原生查詢執行效能。
原生查詢執行資格工具建議的工作負載。
如果工作負載的輸入內容屬於下列資料類型,建議不要執行原生查詢:
- Byte:ORC 和 Parquet
- 時間戳記:ORC
- 結構體、陣列、對應:Parquet
原生查詢執行作業限制
在下列情況下啟用原生查詢執行功能,可能會導致例外狀況、Spark 不相容,或工作負載回退至預設的 Spark 引擎。
備用廣告
在下列執行作業中執行原生查詢,可能會導致工作負載回溯至 Spark 執行引擎,進而導致回歸或失敗。
ANSI:如果啟用 ANSI 模式,執行作業會改回使用 Spark。
區分大小寫模式:原生查詢執行作業僅支援 Spark 預設的不區分大小寫模式。如果啟用區分大小寫模式,可能會出現不正確的結果。
分區資料表掃描:只有在路徑包含分區資訊時,原生查詢執行作業才支援分區資料表掃描,否則工作負載會回復為 Spark 執行引擎。
不相容的行為
在下列情況下使用原生查詢執行作業時,可能會導致不相容的行為或不正確的結果:
JSON 函式:原生查詢執行作業支援以雙引號括住的字串,而非單引號。使用單引號會導致結果不正確。在路徑中使用「*」搭配
get_json_object函式會傳回NULL。Parquet 讀取設定:
- 即使設為
true,原生查詢執行作業仍會將spark.files.ignoreCorruptFiles視為設為預設的false值。 - 原生查詢執行會忽略
spark.sql.parquet.datetimeRebaseModeInRead,並只傳回 Parquet 檔案內容。系統不會考量舊版混合式 (儒略格里高利) 日曆與前推格里高利日曆的差異。Spark 結果可能會有所不同。
- 即使設為
NaN:不支援。舉例來說,在數值比較中使用NaN時,可能會出現非預期的結果。Spark 欄狀讀取:Spark 欄狀向量與原生查詢執行作業不相容,因此可能會發生嚴重錯誤。
溢出:如果將隨機重組分區設為大量,溢出至磁碟功能可能會觸發
OutOfMemoryException。如果發生這種情況,減少分區數量即可排除這項例外狀況。