
Questo documento mostra come abilitare Lightning Engine per accelerare i workload batch e le sessioni interattive di Managed Service for Apache Spark.
Panoramica
Lightning Engine è un acceleratore di query ad alte prestazioni basato su un motore di ottimizzazione multilivello che esegue tecniche di ottimizzazione consuete, come le ottimizzazioni di query ed esecuzione, nonché ottimizzazioni curate nel livello del file system e nei connettori di accesso ai dati.
Come mostrato nella figura seguente, Lightning Engine accelera le prestazioni di esecuzione delle query Spark su un carico di lavoro simile a TPC-H (dimensioni del set di dati 10 TB).
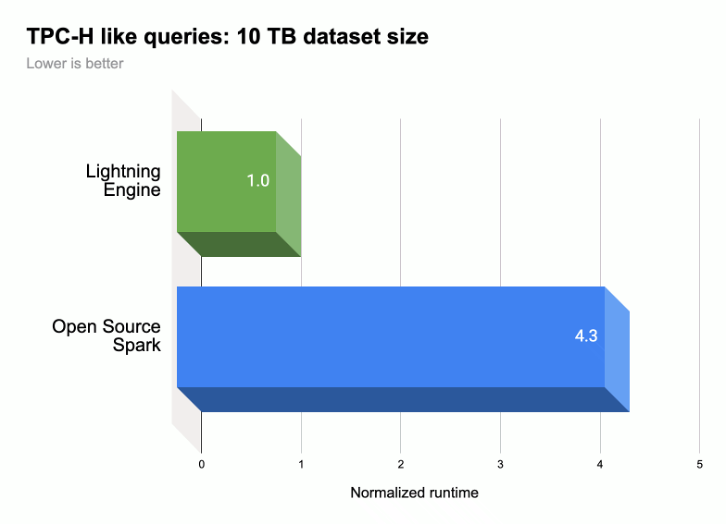
Per saperne di più, consulta Ti presentiamo Lightning Engine, la nuova generazione di prestazioni di Apache Spark.
Disponibilità di Lightning Engine
- Lightning Engine è disponibile per l'utilizzo con Managed Service for Apache Spark runtime 2.3.
- Lightning Engine è disponibile solo con il livello di prezzo premium di Managed Service for Apache Spark.
- Carichi di lavoro batch: Lightning Engine viene attivato automaticamente per i carichi di lavoro batch nel livello Premium. Non è richiesta alcuna azione da parte tua.
- Sessioni interattive: Lightning Engine non è abilitato per impostazione predefinita per le sessioni interattive. Per abilitarlo, consulta Abilitare Lightning Engine.
- Modelli di sessione: Lightning Engine non è attivato per impostazione predefinita per i modelli di sessione. Per abilitarlo, consulta Abilitare Lightning Engine.
Abilita Lightning Engine
Le sezioni seguenti mostrano come attivare Lightning Engine in un workload batch, un modello di sessione e una sessione interattiva di Managed Service for Apache Spark.
Workload batch
Abilitare Lightning Engine su un carico di lavoro batch
Puoi utilizzare la console Google Cloud , Google Cloud CLI o l'API Dataproc per abilitare Lightning Engine in un carico di lavoro batch.
Console
Utilizza la console Google Cloud per abilitare Lightning Engine su un workload batch.
Nella console Google Cloud :
- Vai a Managed Service for Apache Spark Batches.
- Fai clic su Crea per aprire la pagina Crea batch.
Seleziona e compila i seguenti campi:
- Container:
- Versione runtime:seleziona
2.3.
- Versione runtime:seleziona
Configurazione livello:
- Seleziona
Premium. Questa opzione attiva e seleziona automaticamente "Abilita LIGHTNING ENGINE per accelerare le prestazioni di Spark".
Quando selezioni il livello premium, Livello di computing driver e Livello di computing esecutore sono impostati su
Premium. Queste impostazioni di calcolo del livello Premium impostate automaticamente non possono essere ignorate per i batch che utilizzano runtime precedenti a3.0.Puoi configurare il livello del disco del driver e il livello del disco dell'esecutore su
Premiumo lasciarli al valore predefinitoStandard. Se scegli un livello di disco premium, devi selezionare la dimensione del disco. Per saperne di più, consulta le proprietà di allocazione delle risorse.- Seleziona
Proprietà: (facoltativo) inserisci la seguente coppia
Key(nome della proprietà) eValuese vuoi selezionare il runtime Esecuzione query nativa:Chiave Valore spark.dataproc.lightningEngine.runtimeindigeno/nativo/locale
- Container:
Compila, seleziona o conferma le altre impostazioni dei carichi di lavoro batch. Vedi Inviare un carico di lavoro batch Spark.
Fai clic su Invia per eseguire il carico di lavoro batch Spark.
gcloud
Imposta i seguenti flag del comando
gcloud dataproc batches submit spark
gcloud CLI per abilitare un motore Lightning in un carico di lavoro batch.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Note:
- PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- REGION: una regione di Compute Engine disponibile per l'esecuzione del carico di lavoro.
--properties=dataproc.tier=premium. L'impostazione del livello premium imposta automaticamente le seguenti proprietà sul carico di lavoro batch:spark.dataproc.engine=lightningEngineseleziona Lightning Engine per il workload batch.spark.dataproc.driver.compute.tierespark.dataproc.executor.compute.tiersono impostati supremium(vedi proprietà di allocazione delle risorse). Queste impostazioni di calcolo del livello Premium impostate automaticamente non possono essere sostituite per i batch che utilizzano runtime precedenti a3.0.
Altre proprietà
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeAggiungi questa proprietà se vuoi selezionare il runtime Native Query Execution.Livelli e dimensioni del disco: per impostazione predefinita, le dimensioni del disco del driver e dell'executor sono impostate su livelli e dimensioni
standard. Puoi aggiungere proprietà per selezionare i livelli e le dimensioni del discopremium(in multipli di375 GiB).
Per ulteriori informazioni, consulta Proprietà di allocazione delle risorse.
OTHER_FLAGS_AS_NEEDED: vedi Invia un carico di lavoro batch Spark.
API
Per abilitare Lightning Engine in un carico di lavoro batch, come parte della richiesta
batches.create:
- Imposta RuntimeConfig.version su
2.3. Aggiungi "dataproc.tier":"premium" a RuntimeConfig.properties L'impostazione del livello premium imposta automaticamente le seguenti proprietà nel workload batch:
spark.dataproc.engine=lightningEngineseleziona Lightning Engine per il workload batch.spark.dataproc.driver.compute.tierespark.dataproc.executor.compute.tiersono impostati supremium(vedi proprietà di allocazione delle risorse). Queste impostazioni di calcolo del livello Premium impostate automaticamente non possono essere sostituite per i batch che utilizzano runtime precedenti a3.0.
Altro RuntimeConfig.properties:
Native Query Engine:
spark.dataproc.lightningEngine.runtime:native. Aggiungi questa proprietà se vuoi selezionare il runtime Native Query Execution.Livelli e dimensioni del disco: per impostazione predefinita, le dimensioni del disco del driver e dell'executor sono impostate su livelli e dimensioni
standard. Puoi aggiungere proprietà per selezionare i livelli e le dimensioni dipremium(in multipli di375 GiB).
Per ulteriori informazioni, consulta Proprietà di allocazione delle risorse.
Consulta Invia un carico di lavoro batch Spark per impostare altri campi dell'API batch workload.
Modello di sessione
Abilitare Lightning Engine in un modello di sessione
Puoi utilizzare la console Google Cloud , Google Cloud CLI o l'API Dataproc per attivare Lightning Engine in un modello di sessione per una sessione Jupyter o Spark Connect.
Console
Utilizza la console Google Cloud per abilitare Lightning Engine su un workload batch.
Nella console Google Cloud :
- Vai ai modelli di sessione di Managed Service for Apache Spark.
- Fai clic su Crea per aprire la pagina Crea template sessione.
Seleziona e compila i seguenti campi:
- Informazioni sul modello di sessione:
- Seleziona "Abilita Lightning Engine per accelerare le prestazioni di Spark".
- Configurazione esecuzione:
- Versione runtime:seleziona
2.3.
- Versione runtime:seleziona
Proprietà: Inserisci le seguenti coppie
Key(nome proprietà) eValueper selezionare il livello Premium:Chiave Valore dataproc.tierpremium spark.dataproc.enginelightningEngine (Facoltativo) Inserisci la seguente coppia
Key(nome proprietà) eValueper selezionare il runtime Esecuzione query nativa:Chiave Valore spark.dataproc.lightningEngine.runtimenative
- Informazioni sul modello di sessione:
Compila, seleziona o conferma le altre impostazioni del modello di sessione. Vedi Crea un template sessione.
Fai clic su Invia per creare il modello di sessione.
gcloud
Non puoi creare direttamente un modello di sessione Managed Service for Apache Spark utilizzando
gcloud CLI. In alternativa, puoi utilizzare il comando gcloud beta dataproc session-templates import per importare un template di sessione esistente, modificare il template importato per attivare Lightning Engine e, facoltativamente, il runtime delle query native, quindi esportare il template modificato utilizzando il comando gcloud beta dataproc session-templates export.
API
Per abilitare Lightning Engine in un modello di sessione, come parte della richiesta
sessionTemplates.create:
- Imposta RuntimeConfig.version su
2.3. - Aggiungi "dataproc.tier":"premium" e "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Altro RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: aggiungi questa proprietà a RuntimeConfig.properties per selezionare il runtime Native Query Execution.
Consulta Crea un template sessione per impostare altri campi API del template sessione.
Sessione interattiva
Abilitare Lightning Engine in una sessione interattiva
Puoi utilizzare Google Cloud CLI o l'API Dataproc per abilitare Lightning Engine in una sessione interattiva di Managed Service for Apache Spark. Puoi anche attivare Lightning Engine in una sessione interattiva in un notebook BigQuery Studio.
gcloud
Imposta i seguenti flag del comando
gcloud beta dataproc sessions create spark
gcloud CLI per attivare Lightning Engine in una sessione interattiva.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Note:
- PROJECT_ID: l'ID progetto Google Cloud . Gli ID progetto sono elencati nella sezione Informazioni sul progetto della dashboard della console Google Cloud .
- REGION: una regione di Compute Engine disponibile per l'esecuzione del carico di lavoro.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Queste proprietà attivano Lightning Engine nella sessione.Altre proprietà:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: Aggiungi questa proprietà per selezionare il runtime Native Query Execution.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: vedi Creare una sessione interattiva.
API
Per attivare Lightning Engine in una sessione, come parte della richiesta
sessions.create:
- Imposta RuntimeConfig.version su
2.3. - Aggiungi "dataproc.tier":"premium" e "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Altro RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Aggiungi questa proprietà a RuntimeConfig.properties se vuoi selezionare il runtime Native Query Execution.
Consulta Crea una sessione interattiva per impostare altri campi API del modello di sessione.
Notebook BigQuery
Puoi attivare Lightning Engine quando crei una sessione in un notebook PySpark di BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Verifica le impostazioni di Lightning Engine
Puoi utilizzare la console Google Cloud , Google Cloud CLI o l'API Dataproc per verificare le impostazioni di Lightning Engine in un batch, un modello di sessione o una sessione interattiva.
Workload batch
Per verificare che il livello del batch sia impostato su
premiume che il motore sia impostato suLightning Engine:- ConsoleGoogle Cloud : nella pagina Batch, consulta le colonne Livello e Motore per il batch. Puoi fare clic sull'ID batch per visualizzare queste impostazioni anche nella pagina dei dettagli del batch.
- gcloud CLI: esegui il comando
gcloud dataproc batches describe. - API: invia una richiesta
batches.get.
Modello di sessione
Per verificare che engine sia impostato su
Lightning Engineper un modello di sessione:- ConsoleGoogle Cloud : nella pagina Modelli di sessione, visualizza la colonna Motore per il tuo modello. Puoi fare clic sul nome del modello di sessione per visualizzare questa impostazione anche nella pagina dei dettagli del modello di sessione.
- gcloud CLI: esegui il comando
gcloud beta dataproc session-templates describe. - API: invia una richiesta
sessionTemplates.get.
Sessione interattiva
Per il motore è impostato su
Lightning Engineper una sessione interattiva:- ConsoleGoogle Cloud : nella pagina Sessioni interattive, consulta la colonna Motore per il modello. Puoi fare clic sull'ID sessione interattiva per visualizzare questa impostazione anche nella pagina dei dettagli del modello di sessione.
- gcloud CLI: esegui il comando
gcloud beta dataproc sessions describe. - API: invia una richiesta
sessions.get.
Esecuzione di query native
Native Query Execution (NQE) è una funzionalità facoltativa di Lightning Engine che migliora le prestazioni tramite un'implementazione nativa basata su Apache Gluten e Velox, progettata per l'hardware Google.
Il runtime di esecuzione delle query native include la gestione unificata della memoria per il passaggio dinamico tra memoria off-heap e on-heap senza richiedere modifiche alle configurazioni Spark esistenti. NQE include un supporto esteso per operatori, funzioni e tipi di dati Spark, nonché l'intelligenza per identificare automaticamente le opportunità di utilizzare il motore nativo per operazioni di pushdown ottimali.
Identifica i workload di esecuzione delle query native
Utilizza l'esecuzione di query native nei seguenti scenari:
API Spark Dataframe, API Spark Dataset e query Spark SQL che leggono i dati dai file Parquet e ORC. Il formato del file di output non influisce sul rendimento dell'esecuzione della query nativa.
Carichi di lavoro consigliati dallo strumento di qualificazione dell'esecuzione di query native.
L'esecuzione di query native non è consigliata per i workload con input dei seguenti tipi di dati:
- Byte: ORC e Parquet
- Timestamp: ORC
- Struct, Array, Map: Parquet
Limitazioni dell'esecuzione delle query native
L'attivazione dell'esecuzione di query native nei seguenti scenari può causare eccezioni, incompatibilità di Spark o fallback del workload al motore Spark predefinito.
Fallback
L'esecuzione di query native nella seguente esecuzione può comportare il fallback del carico di lavoro al motore di esecuzione Spark, con conseguente regressione o errore.
ANSI:se la modalità ANSI è attivata, l'esecuzione torna a Spark.
Modalità sensibile alle maiuscole:l'esecuzione di query native supporta solo la modalità predefinita di Spark che non fa distinzione tra maiuscole e minuscole. Se la modalità sensibile alle maiuscole/minuscole è abilitata, possono verificarsi risultati errati.
Scansione della tabella partizionata: l'esecuzione di query native supporta la scansione della tabella partizionata solo quando il percorso contiene le informazioni sulla partizione. In caso contrario, il carico di lavoro torna al motore di esecuzione Spark.
Comportamento incompatibile
Un comportamento incompatibile o risultati errati possono verificarsi quando si utilizza l'esecuzione di query native nei seguenti casi:
Funzioni JSON: l'esecuzione di query native supporta le stringhe racchiuse tra virgolette doppie, non singole. I risultati errati si verificano con gli apici singoli. L'utilizzo di "*" nel percorso con la funzione
get_json_objectrestituisceNULL.Configurazione di lettura Parquet:
- L'esecuzione di query native considera
spark.files.ignoreCorruptFilescome impostato sul valore predefinitofalse, anche se impostato sutrue. - L'esecuzione di query native ignora
spark.sql.parquet.datetimeRebaseModeInReade restituisce solo i contenuti del file Parquet. Le differenze tra il calendario ibrido legacy (giuliano gregoriano) e il calendario gregoriano prolettico non vengono prese in considerazione. I risultati di Spark possono variare.
- L'esecuzione di query native considera
NaN: non supportato. Si possono verificare risultati imprevisti, ad esempio, quando si utilizzaNaNin un confronto numerico.Lettura colonnare Spark:può verificarsi un errore irreversibile perché il vettore colonnare Spark non è compatibile con l'esecuzione di query native.
Spill:quando le partizioni di shuffling sono impostate su un numero elevato, la funzionalità di spill-to-disk può attivare un
OutOfMemoryException. Se si verifica questo problema, la riduzione del numero di partizioni può eliminare questa eccezione.