
Déployer un service Dataproc Metastore
Cette page explique comment créer un service Dataproc Metastore et vous y connecter à partir d'un cluster Managed Service pour Apache Spark. Ensuite, vous vous connectez au cluster via SSH, lancez une instance d'Apache Hive et exécutez quelques requêtes de base.
Dataproc Metastore vous fournit un métastore Hive (HMS) entièrement compatible, qui est la norme établie dans l'écosystème Open Source de Big Data pour la gestion des métadonnées techniques. Ce service vous aide à gérer les métadonnées de vos lacs de données et assure l'interopérabilité entre les différents outils de traitement de données que vous utilisez.
Pour obtenir des instructions détaillées sur cette tâche directement dans la Google Cloud console, cliquez sur Visite guidée:
Avant de commencer
- Connectez-vous à votre Google Cloud compte. Si vous n'avez jamais utilisé Google Cloud, créez un compte pour évaluer les performances de nos produits dans des scénarios réels. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc Metastore, Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc Metastore, Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Rôles requis
Pour obtenir les autorisations nécessaires pour créer un cluster Dataproc Metastore et Managed Service pour Apache Spark, demandez à votre administrateur de vous accorder les rôles IAM suivants :
-
Pour accorder un accès complet à toutes les ressources Dataproc Metastore, y compris la définition des autorisations IAM:
(
roles/metastore.admin) sur le compte utilisateur ou le compte de service -
Pour accorder un contrôle total des ressources Dataproc Metastore :
Éditeur Dataproc Metastore (
roles/metastore.editor) sur le compte utilisateur ou le compte de service -
Pour créer un cluster Managed Service pour Apache Spark :
(
roles/dataproc.worker) sur le compte de service
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour créer un cluster Dataproc Metastore et Managed Service pour Apache Spark. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour créer un cluster Dataproc Metastore et Managed Service pour Apache Spark :
- Pour créer un service Dataproc Metastore : metastore.services.create sur le compte utilisateur ou le compte de service
-
Pour créer un cluster Managed Service pour Apache Spark :
Worker Managed Service pour Apache Spark (
roles/dataproc.worker) sur le compte de service
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus sur les rôles et autorisations spécifiques de Dataproc Metastore, consultez la présentation d'IAM pour Dataproc Metastore.Créer un service Dataproc Metastore
Les instructions suivantes vous montrent comment créer un service Dataproc Metastore de base à l'aide des paramètres par défaut fournis.
Console
Dans la Google Cloud console, accédez à la page Dataproc Metastore.
Dans le menu de navigation, cliquez sur + Créer.
La boîte de dialogue Créer un service Metastore s'ouvre.
Sélectionnez Dataproc Metastore 2.
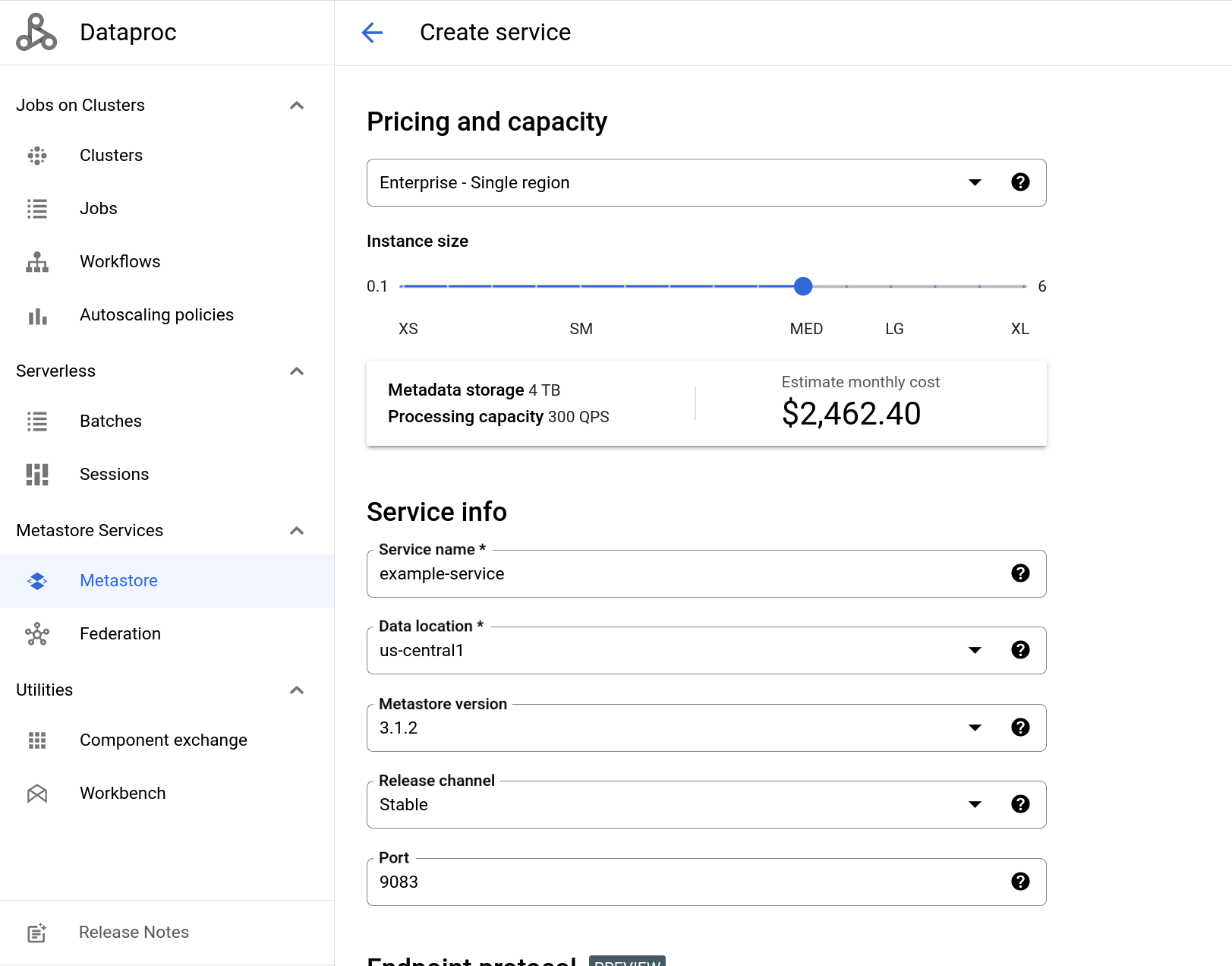
Dans le champ Nom du service, saisissez
example-service.Dans le champ Emplacement des données, sélectionnez
us-central1.Pour les autres options de configuration de service, utilisez les valeurs par défaut fournies.
Pour créer et démarrer le service, cliquez sur Envoyer.
Votre nouveau service de métastore s'affiche sur la page Dataproc Metastore. L'état indique Création en cours jusqu'à ce que le service soit prêt à être utilisé. Une fois prêt, l'état passe à Actif. Le provisionnement du service peut prendre quelques minutes.
La capture d'écran suivante montre un exemple de la page Créer un service utilisant certaines des valeurs par défaut fournies.
Gcloud CLI
gcloud metastore services create example-service \
--location=us-central1 \
--instance-size=MEDIUMREST
Suivez les instructions de l'API pour créer un service à l'aide de l'APIs Explorer.
Créer un cluster Managed Service pour Apache Spark et se connecter à Dataproc Metastore
Ensuite, vous créez un cluster Managed Service pour Apache Spark et vous connectez à votre métastore à partir du cluster. Votre cluster utilise ensuite le service de métastore comme HMS. Le cluster que vous créez ici utilise les paramètres par défaut fournis.
Console
Dans la Google Cloud console, accédez à la page Clusters Dataproc.
Dans la barre de navigation, sélectionnez + Créer un cluster.
La boîte de dialogue Créer un cluster s'ouvre et vous propose plusieurs choix d'infrastructure.
Dans la ligne Cluster sur Compute Engine, sélectionnez Créer.
La page Créer un cluster Managed Service pour Apache Spark sur Compute Engine s'ouvre.
Dans le champ Nom du cluster, saisissez
example-cluster.Dans les menus Région et Zone, sélectionnez
us-central1.Pour les autres options de Configuration du cluster, utilisez les valeurs par défaut fournies.
Dans le menu de navigation, cliquez sur l'onglet Personnaliser le cluster (facultatif).
Dans la section Dataproc Metastore, sélectionnez le service de métastore que vous avez créé précédemment.
Si vous avez suivi ce tutoriel tel quel, il s'appelle
example-service.Pour les autres options de configuration du service, utilisez les valeurs par défaut fournies.
Pour créer le cluster, cliquez sur Créer.
Votre nouveau cluster apparaît dans la liste Clusters. L'état du cluster indique Provisionnement jusqu'à ce qu'il soit prêt à être utilisé. Une fois prêt, l'état passe à Actif. Le provisionnement du cluster peut prendre quelques minutes.
Gcloud CLI
Pour créer un cluster à l'aide des paramètres par défaut fournis, exécutez la
commande gcloud dataproc clusters create
suivante :
gcloud dataproc clusters create example-cluster \
--dataproc-metastore=projects/PROJECT_ID/locations/us-central1/services/example-service \
--region=us-central1Remplacez PROJECT_ID par l'ID du projet du
projet dans lequel vous avez créé votre service Dataproc Metastore.
REST
Suivez les instructions de l'API pour créer un cluster à l'aide de l'APIs Explorer.
Se connecter à Apache Hive avec un cluster Managed Service pour Apache Spark
Les étapes suivantes vous montrent comment exécuter quelques exemples de commandes dans Apache Hive pour créer une base de données et une table.
Ensuite, ouvrez une session SSH sur le cluster Managed Service pour Apache Spark et lancez une session Hive.
- Dans la Google Cloud console, accédez à la page Instances de VM.
- Dans la liste des instances de machine virtuelle, cliquez sur SSH à côté de
example-cluster.
Une fenêtre de navigateur s'ouvre dans votre répertoire d'accueil sur le nœud avec un résultat semblable à celui-ci :
Connected, host fingerprint: ssh-rsa ...
Linux cluster-1-m 3.16.0-0.bpo.4-amd64 ...
...
example-cluster@cluster-1-m:~$
Pour démarrer Hive et créer une base de données et une table, exécutez les commandes suivantes dans la session SSH :
Démarrez Hive.
hiveCréez une base de données nommée
myDatabase.create database myDatabase;Affichez la base de données que vous avez créée.
show databases;Utilisez la base de données que vous avez créée.
use myDatabase;Créez une table nommée
myTable.create table myTable(id int,name string);Répertoriez les tables sous
myDatabase.show tables;Décrivez le schéma de la table que vous avez créée.
desc MyTable;
L'exécution de ces commandes affiche un résultat semblable à celui-ci :
$hive
hive> show databases;
OK
default
hive> create database myDatabase;
OK
hive> use myDatabase;
OK
hive> create table myTable(id int,name string);
OK
hive> show tables;
OK
myTable
hive> desc myTable;
OK
id int
name string
Libérer de l'espace
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre Google Cloud compte pour les ressources utilisées sur cette page, procédez comme suit :
- Dans la Google Cloud console, accédez à la page Gérer les ressources.
- Si le projet que vous envisagez de supprimer est associé à une organisation, développez la liste Organisation dans la colonne Nom.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez Arrêter pour supprimer le projet.
Vous pouvez également supprimer les ressources utilisées dans ce tutoriel :
Supprimez le service Dataproc Metastore.
Console
Dans la Google Cloud console, ouvrez la page Dataproc Metastore :
Dans la liste des services, sélectionnez
example-service.Dans la barre de navigation, cliquez sur Supprimer.
La boîte de dialogue Supprimer le service s'ouvre.
Dans la boîte de dialogue, cliquez sur Supprimer.
Votre service n'apparaît plus dans la liste des services.
Gcloud CLI
Pour supprimer votre service, exécutez la commande
gcloud metastore services deletesuivante.gcloud metastore services delete example-service \ --location=us-central1REST
Suivez les instructions de l'API pour supprimer un service à l'aide de l'explorateur d'API.
Toutes les suppressions sont effectives immédiatement.
Supprimez le bucket Cloud Storage associé au service Dataproc Metastore.
Supprimez le cluster Managed Service pour Apache Spark qui utilisait le service Dataproc Metastore.