
Knowledge Catalog 사용 사례
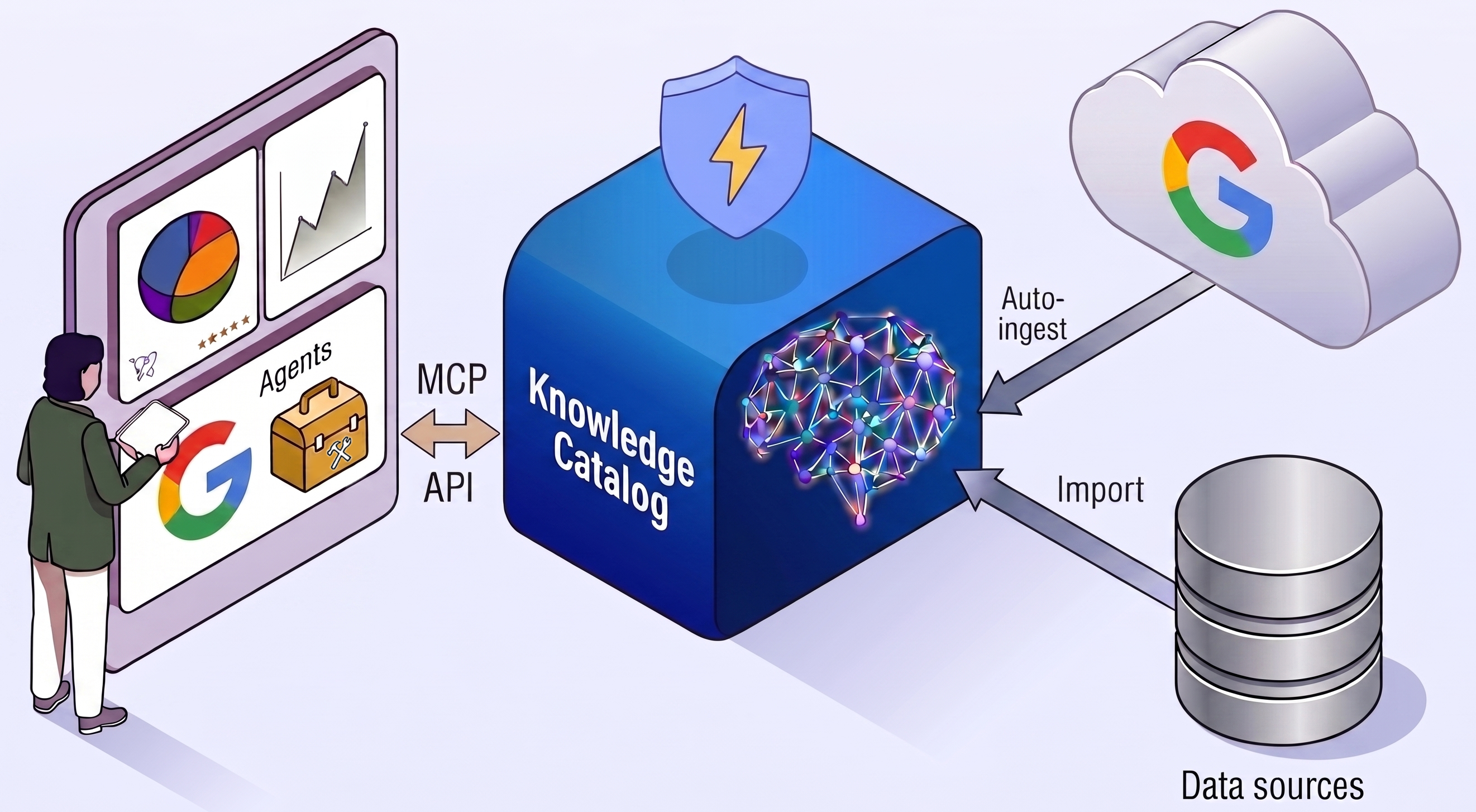
Knowledge Catalog API 호출을 실행하는 검색 에이전트 (Python)를 사용하여 엔터프라이즈 데이터 애셋에 대해 복잡한 자연어 쿼리를 실행합니다.
Knowledge Catalog API 호출을 실행하는 보강 에이전트를 사용하여 데이터 애셋에 대한 AI 기반 개요를 대규모로 생성합니다 (Python).
AI 에이전트와 Knowledge Catalog를 컨텍스트 그래프로 사용하여 분산 데이터 스토어 전반에서 크로스 클라우드 분석 워크플로를 설계합니다.
Google Cloud 콘솔을 사용하여 구조화된 스키마 기반 메타데이터 (관점)와 비즈니스 정의 (용어집)를 데이터 애셋 (항목)에 연결합니다.
Apache Iceberg 테이블을 만들고, 열 수준 보안을 위한 중앙 집중식 데이터 정책을 적용하고, 보안 정책을 정의하고, 자동화된 데이터 계보를 시각화합니다.
BigQuery와 같은 Google 서비스에서 메타데이터를 자동으로 수집합니다.
개방형 API를 사용하여 맞춤 데이터 소스의 메타데이터를 색인 생성합니다.
Gemini CLI를 통해 자연어 쿼리를 사용하여 데이터를 프로파일링하고 품질 규칙을 생성한 다음 데이터 품질 규칙을 자동 스캔으로 배포합니다.
자연어 쿼리를 사용하여 Gemini CLI에 Knowledge Catalog가 소스 데이터와 임시 파생 상품을 구분할 수 있는지 확인합니다.
데이터 변환이 다운스트림 리소스, 데이터 무결성, 워크플로에 미치는 영향을 파악합니다.
민감한 정보의 흐름을 추적하여 신뢰할 수 있는 위치에서 신뢰할 수 없는 위치로 이동하는 프로세스를 파악합니다.
다른 프로세스의 소스로 적극적으로 사용되지 않는 애셋을 식별하여 스토리지 비용을 절감합니다.
단일 API 요청을 사용하여 데이터 애셋의 사전 형식화된 LLM 지원 컨텍스트를 가져옵니다.