
Knowledge Catalog のユースケース
Knowledge Catalog API 呼び出しを行う検出エージェント(Python)を使用して、エンタープライズ データアセットに対して複雑な自然言語クエリを実行します。
Knowledge Catalog API 呼び出しを行うエンリッチメント エージェント(Python)を使用して、データアセットの AI を活用した概要を大規模に生成します。
AI エージェントと Knowledge Catalog をコンテキスト グラフとして使用して、分散データストア間でクロスクラウド分析ワークフローを設計します。
Google Cloud コンソールを使用して、構造化されたスキーマ駆動型メタデータ(アスペクト)とビジネス定義(用語集)をデータアセット(エントリ)に関連付けます。
Apache Iceberg テーブルを作成し、列レベルのセキュリティに対して一元化されたデータポリシーを適用し、セキュリティ ポリシーを定義して、自動化されたデータ リネージを可視化します。
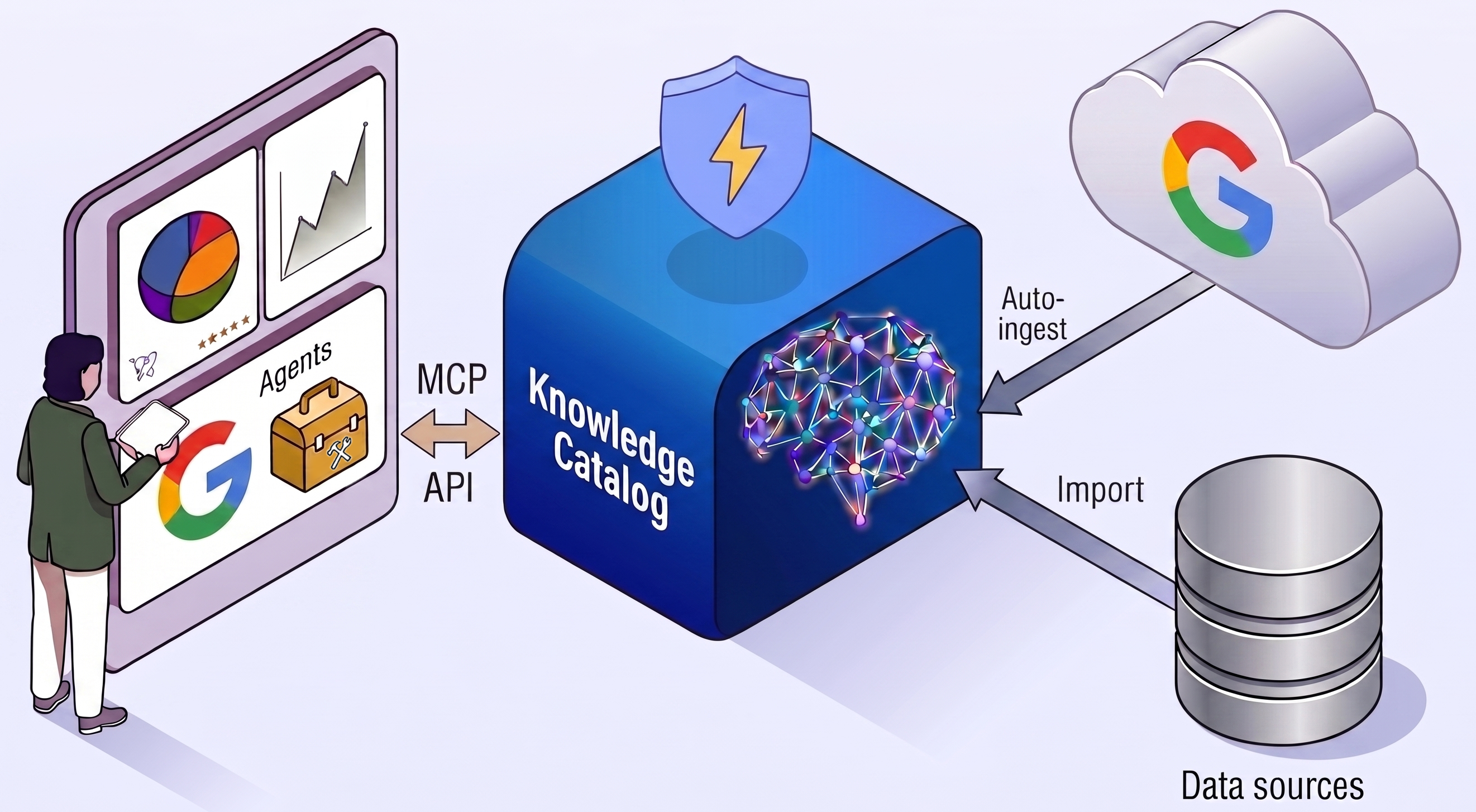
BigQuery などの Google サービスからメタデータを自動的に取り込みます。
オープン API を使用してカスタム データソースからメタデータをインデックス登録します。
Gemini CLI を使用して、自然言語クエリでデータをプロファイリングし、品質ルールを生成してから、データ品質ルールを自動スキャンとしてデプロイします。
自然言語クエリを使用して Gemini CLI にアクセスし、Knowledge Catalog がソースデータと一時的な派生データを区別できることを確認します。
データ変換がダウンストリーム リソース、データの完全性、ワークフローに与える影響を特定します。
センシティブ データの流れを追跡して、信頼できる場所から信頼できない場所に移動するプロセスを特定します。
他のプロセスのソースとして積極的に使用されていないアセットを特定して、ストレージ費用を削減します。
単一の API リクエストを使用して、データアセットの事前フォーマット済みの LLM 対応コンテキストを取得します。