
データをさまざまなストレージ システムに保存すると、断片化されたセキュリティの管理が大きな課題となる可能性があります。
財務記録などの機密情報は、Google Cloud ストレージ上の Apache Iceberg などのオープン形式で保存する場合でも、保護する必要があります。これらの保護は、BigQuery SQL や Apache Spark などのさまざまなクエリエンジンに適用する必要があります。
このチュートリアルでは、これらの課題を解決するために安全なデータ レイクハウスを構築します。スクリプトを使用してセキュリティ ポリシーを定義し、Knowledge Catalog(旧称 Dataplex Universal Catalog)と Lakehouse for Apache Iceberg が連携して、さまざまなクエリエンジンにポリシーを適用する方法を確認します。
アーキテクチャの概要
Apache Iceberg などのオープン テーブル形式で詳細なアクセス制御を設定するには、厳格で統一されたセキュリティ アーキテクチャを作成する必要があります。
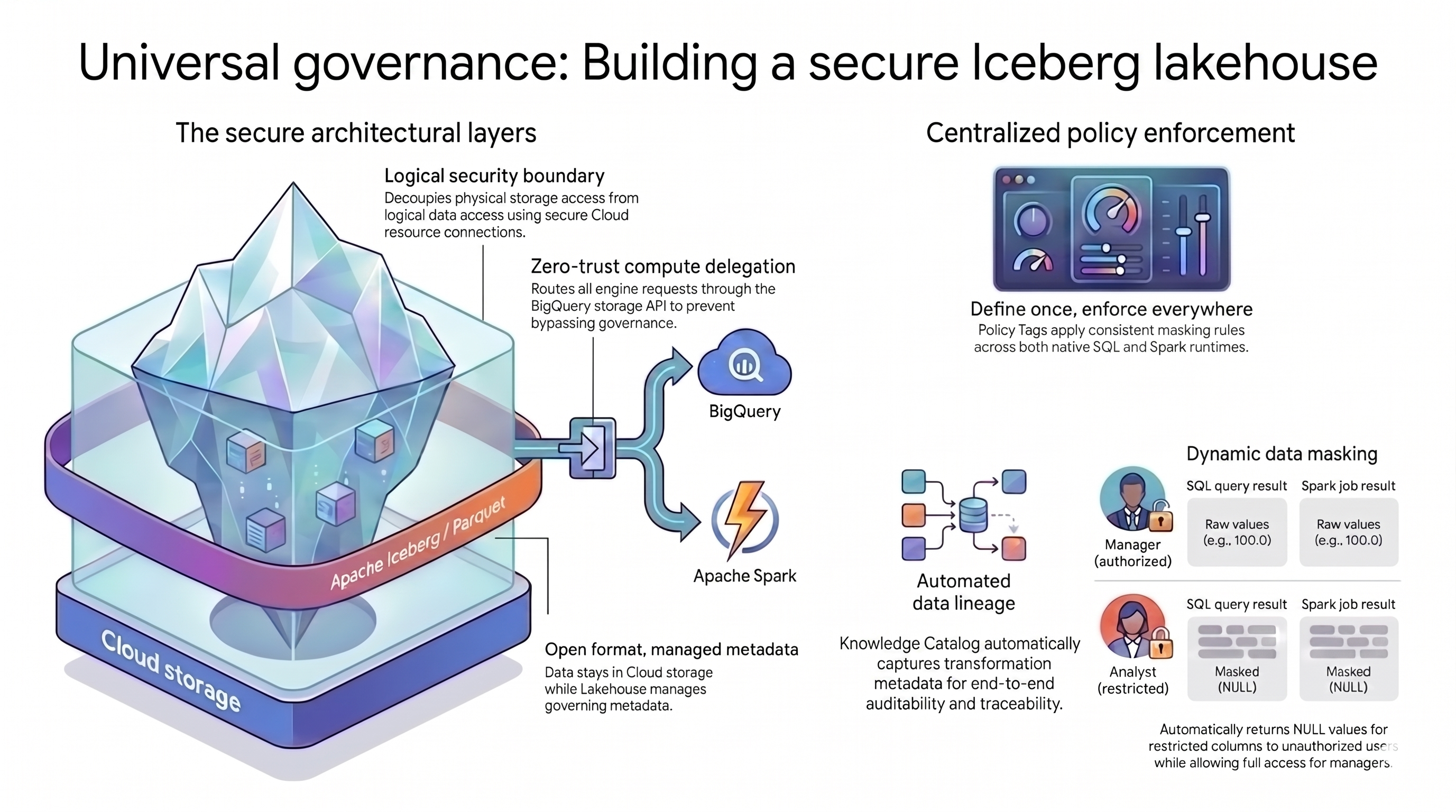
このチュートリアルで使用するレイクハウス パターンは、この課題を解決するために次の 2 つの主要なコンセプトに依存しています。
- 安全なアーキテクチャ レイヤ: ユーザーやクエリエンジンが Cloud Storage バケットに直接アクセスするのではなく、次の属性に基づいて安全な階層化された基盤を構築します。
- 管理されたメタデータを含むオープン形式: データは Cloud Storage 内のオープンな Apache Iceberg(Parquet)形式のままですが、Lakehouse for Apache Iceberg がテーブル メタデータを管理します。
- 論理セキュリティ境界: 安全な Cloud リソース接続を使用して、ストレージ権限とデータクエリを分離します。エンドユーザーにファイルへの直接アクセス権を付与することはありません。
- コンピューティングの委任: クエリエンジンがルールをバイパスしないように、すべてのデータ リクエストを BigQuery Storage API 経由でルーティングします。
- 一元化されたポリシー適用: 安全な基盤が整っている場合、Knowledge Catalog はアーキテクチャの単一のコントロール プレーンとして機能し、ルールを普遍的に適用します。
- 一度定義すれば、どこでも適用可能: Knowledge Catalog でポリシータグを一度定義すると、サポートされているすべてのクエリエンジンに一貫したマスキング ルールが適用されます。
- 動的データ マスキング: システムはクエリ中にユーザー ID を評価します。認可されたユーザーには未加工の値が表示されますが、制限付きユーザーにはすべてのクエリエンジンで
NULL出力が表示されます。 - 自動データリネージ: Knowledge Catalog はデータ変換を自動的に追跡し、カスタム ロギング コードを使用せずに監査証跡を作成します。
目標
- BigQuery で管理される Apache Iceberg テーブルを作成します。Lakehouse は Iceberg メタデータを管理します。
- ポリシータグを使用して中央のセキュリティ ルールを設定し、機密性の高い列をマスクして保護します。
- Cloud リソース接続を使用して、物理ストレージ権限と論理データクエリを分離します。
- 外部エンジンがセキュリティ ルールをバイパスできないように、Managed Service for Apache Spark を介してクエリを安全にルーティングします。
- データリネージを使用して、データのインタラクティブ マップを探索します。
始める前に
始める前に、次のことを行います。
- このチュートリアルで使用する Google Cloud プロジェクトを選択します。
- プロジェクトで課金が有効になっていることを確認します。
環境を準備する
このチュートリアルでは、クラウドで実行されるコマンドライン環境である Cloud Shell を使用します。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell] アイコンをクリックします。
プロジェクト変数を設定します。
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"小売アナリストと小売マネージャーの 2 つのユーザー ペルソナの変数を定義します。
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)必要な Google Cloud API を有効にします。
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
チュートリアルのソースコードをダウンロードする
このチュートリアルの Python スクリプトを Google Cloud DevRel リポジトリからダウンロードします。
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Storage バケットを作成する
Iceberg テーブル ファイルを保持する新しいバケットを作成します。
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
ID とセキュリティを準備する
このステップでは、Cloud リソース接続を作成してコンピューティングの委任を設定します。この接続は、BigQuery が Iceberg ファイルの管理と読み取りに使用する安全な委任 ID として機能します。これにより、個々のユーザーが Cloud Storage バケットに直接アクセスできなくなります。
次のコマンドを実行して接続を作成し、自動生成されたサービス アカウントを取得して、Iceberg データの管理に必要な権限をそのアカウントに付与します。
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
2 つのペルソナ(アナリスト とマネージャー )のサービス アカウントを作成します。次のコマンドは、これらのサービス アカウントを設定し、現在のユーザーがテストのためにこれらのアカウントの権限を借用できるようにし、クエリの実行とデータの表示を行うための特定のロールを付与します。
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Apache Iceberg テーブルを作成する
BigQuery SQL エンジンを使用して Apache Iceberg テーブルを作成します。BigQuery で作成コマンドを実行しますが、Lakehouse はテーブル メタデータを保存し、Cloud Storage 内の基盤となる Parquet ファイルを保護する管理レイヤとして機能します。
テーブルを作成したら、簡単な変換を実行して、Knowledge Catalog がセキュリティを処理し、データの移動を自動的に追跡する方法を確認します。
BigQuery データセットを作成する
まず、テーブルをグループ化する BigQuery データセットを作成します。
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg テーブルを作成する
次のコマンドを実行して、在庫テーブルとトランザクション テーブルを作成します。
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
サンプルデータを挿入する
テーブルにサンプルデータを挿入します。
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
これで、未加工のサンプルデータを含む 2 つの Iceberg テーブルが作成されました。Lakehouse はメタデータを管理しますが、実際の Parquet ファイルは Cloud Storage バケットにあります。
自動リネージ用にデータを変換する
未加工のトランザクションを日次売上サマリーに集計します。この変換により、新しいテーブルが作成され、Knowledge Catalog がデータの移動を自動的にマッピングするために使用するメタデータが生成されます。
Google Cloudecho "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Python を使用してポリシーを定義する
本番環境では、セキュリティ ルールをコードとして記述する(Infrastructure as Code)ことで、ポリシーを繰り返し使用でき、バージョン管理が可能になり、メンテナンスが容易になります。このセクションでは、 Google Cloud Python SDK を使用してガバナンス ルールを定義し、自動的に適用します。
Python 仮想環境を準備する
依存関係を管理し、ガバナンス スクリプトが確実に実行されるように、隔離された Python 仮想環境を設定します。
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
セキュリティ分類とタグを定義する
まず、セキュリティ ルールの基盤を構築します。このステップでは、コンテナとして機能する分類と、センシティブ データの特定のセキュリティ ラベルとして機能するポリシータグを作成します。
スクリプトを実行してリソースを作成します。
python 1_create_taxonomy.py
1_create_taxonomy.py を確認して、コアロジックを確認します。
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
FINE_GRAINED_ACCESS_CONTROL ポリシータイプを明示的に設定することで、標準のメタデータ タグをデフォルトで厳格に拒否するセキュリティ境界に変換します。このタグが付いた列は、デフォルトですべてのユーザーからのアクセスを拒否します。
動的データ マスキング ポリシーを作成する
次に、権限のないユーザーがタグ付きの列をクエリした場合の動作を定義します。アナリスト ペルソナの機密値を自動的に NULL に置き換えるデータ マスキング ポリシーを作成します。
スクリプトを実行してマスキング ルールを構成します。
python 2_create_masking.py
2_create_masking.py 内で、スクリプトは作成したポリシータグの ID を検索し、アナリスト サービス アカウントにデータポリシーを適用します。
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
データへの特権アクセスを付与する
デフォルトで拒否する設定のため、タグ付きの列を読み取ることはできません。認可されたユーザーに明示的にアクセス権を付与する必要があります。マネージャー ペルソナと自分のアカウントにきめ細かい読み取りのロールを付与します。これにより、これらの特定のユーザーはマスキング ルールをバイパスして、マスクされていないデータを読み取ることができます。
スクリプトを実行してアクセス権を付与します。
python 3_grant_access.py
3_grant_access.py 内で、スクリプトはポリシータグの IAM ポリシーを変更します。
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
テーブル スキーマにセキュリティ タグを適用する
最後に、論理ルールを実際のデータに接続できます。Iceberg テーブル スキーマを更新して、ポリシータグを amount 列に直接適用します。この操作を行うと、Lakehouse はバケット内の Iceberg テーブル ファイル全体に保護を即座に適用します。
スクリプトを実行してポリシータグを適用します。
python 4_attach_tag.py
4_attach_tag.py を確認します。このスクリプトは BigQuery テーブル スキーマを取得し、フィールドを反復処理して、タグを amount 列に適用します。
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
セキュリティ ポリシーを確認する
いくつかのテストクエリを実行して、権限が想定どおりに機能していることを確認します。クエリエンジンを切り替えたときに Lakehouse が同じセキュリティ ポリシーを適用することを証明するために、BigQuery と Apache Spark の両方を使用してこれらのテストを実行します。
BigQuery SQL でテストする
まず、BigQuery でポリシーを直接確認します。これが、マスキング ルールと権限が有効になっていることを確認する最も簡単な方法です。
マネージャーとして確認する
マネージャー ペルソナには、特権付きのきめ細かい読み取りアクセス権があります。amount 列の値など、テーブルのすべての詳細が表示されます。
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
マネージャーにはきめ細かい読み取りのロールがあるため、クエリには未加工の金額値が表示されます。
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
アナリストとして確認する
アナリスト ペルソナに切り替えて、同じクエリを実行します。
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
同じクエリを実行しても、Knowledge Catalog は amount 列の機密値をマスクします。
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
アカウントに戻る
Cloud Shell の認証状態をクリーンアップして、管理者ユーザーに戻ります。
gcloud config unset auth/impersonate_service_account
Apache Spark でテストする
ユーザーが Cloud Storage のデータファイルに直接アクセスすると、セキュリティが破られることがよくあります。データ サイエンティストが Apache Spark を使用して Iceberg テーブル ファイルを直接読み取ると、Cloud Storage はバケットレベルの権限のみを認識するため、通常はルールがバイパスされます。
これを防ぐには、コンピューティングの委任を使用します。Spark-BigQuery コネクタを使用すると、すべての Spark リクエストを BigQuery Storage API 経由でルーティングする安全なブリッジが作成されます。これにより、データが Spark クラスタに到達する前に、Knowledge Catalog が権限を確認してマスキング ルールを適用します。
read_transactions.py スクリプトを Cloud Storage バケットにアップロードして、Managed Service for Apache Spark がアクセスできるようにします。
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
アップロードしたスクリプトのコアロジックを確認します。
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
このスクリプトは、Iceberg ファイルの gs:// パスを Spark に指定しません。.format("bigquery") を指定すると、BigQuery Storage API が読み取りリクエストをインターセプトし、Spark ジョブを実行しているユーザーの ID を確認し、Knowledge Catalog マスキング ルールを適用して、認可されたデータのみを Spark DataFrame に返します。
マネージャーとして Spark を実行する
マネージャー ペルソナとして Spark ジョブを送信します。独自のクラスタを管理する手間をかけずに Spark ワークロードを実行できるマネージド サービスである Managed Service for Apache Spark を使用します。
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ターミナルでジョブ出力ログを確認します。マネージャーにはきめ細かい読み取りのロールがあるため、Spark はマスクされていない金額を正常に取得します。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
アナリストとして Spark を実行する
最後に、アナリスト ペルソナとして同じ Spark コードを実行します。
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
ログをもう一度確認します。アナリストが同じ Spark コードを実行しましたが、BigQuery Storage API がリクエストをインターセプトして Knowledge Catalog ポリシーを適用しました。アナリストの Spark DataFrame には、金額が null と表示されます。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
適切なエンジンを選択する: BigQuery SQL と Apache Spark
Knowledge Catalog は、使用するクエリエンジンに関係なくポリシーを適用することがわかりました。ただし、本番環境に移行する場合は、適切なツールを選択する必要があります。
- BigQuery SQL: 高速な分析とビジネス インテリジェンスに使用します。SQL がメイン言語の場合は、データが存在する場所で直接計算を実行するため、これが最適な選択肢です。
- Apache Spark: Python を必要とする複雑なタスクには Spark を選択します。Spark は、機械学習パイプラインや、レガシー Hadoop コードをレイクハウスに移行する必要がある場合に最適です。
自動リネージでデータの移動を確認する
データリネージを使用すると、データの出所と変換方法を把握できます。 「この販売レポートの作成に使用された未加工のテーブルはどれですか?」などの重要な質問に答えることで、コンプライアンスを維持し、データ パイプラインを迅速にデバッグし、信頼性の高いデータ基盤を構築できます。
複雑なロギング コードを手動で記述する代わりに、Lakehouse はこのライフサイクルを自動的に追跡します。たとえば、このチュートリアルでサマリー テーブルを作成したときに、BigQuery は変換の詳細を即座にキャプチャして Knowledge Catalog に送信しました。
インタラクティブ リネージグラフを探索する
Knowledge Catalog が生成したインタラクティブ マップを確認します。未加工のデータが transactions テーブルから transactions_summary テーブルにどのように流れるかを示します。これにより、データ監査に必要なエンドツーエンドのトレーサビリティが提供されます。
- コンソールで、Knowledge Catalog > 検索 に移動します。 Google Cloud
- 検索バーに「
lakehouse_retail_demo.transactions_summary」と入力し、テーブルをクリックします。 - [リネージ] タブをクリックします。
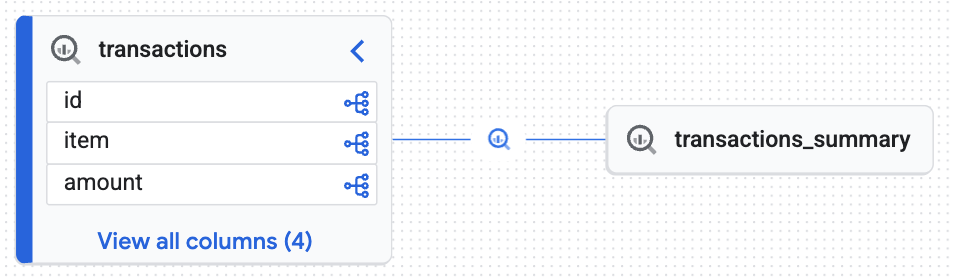
インタラクティブ グラフは、ターゲット テーブル(transactions_summary)が未加工の管理対象 Iceberg テーブル(transactions)から派生していることを示しています。この可視化は、データのエンドツーエンドのトレーサビリティを示しています。
クリーンアップ
継続的な課金を避けるため、このチュートリアルで作成したリソースを削除します。
ガバナンス リソースを削除する
BigQuery データセットまたは Cloud Storage バケットを削除する前に、ガバナンス ルールを削除する必要があります。
Python クリーンアップ スクリプトを実行します。
python cleanup_governance.py
リポジトリの cleanup_governance.py スクリプトを確認して、次の削除ロジックを見つけます。削除順序は重要です。まず、データ マスキング ポリシーを削除します。次に、親分類を削除します。これにより、基盤となるすべてのポリシータグが自動的に削除され、リソース依存関係エラーが回避されます。
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
ID、ストレージ、コンピューティング アセットを削除する
BigQuery テーブル、Cloud Storage バケット、サービス アカウント、ローカル Python 仮想環境を削除します。
Cloud Shell で次のクリーンアップ スクリプトをコピーして実行します。
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
プロジェクト ファイルをクリーンアップします。
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
まとめ
安全なデータ レイクハウスを構築できました。Lakehouse for Apache Iceberg を使用して Iceberg テーブルを管理し、基盤となるテーブル ファイルを Cloud Storage で安全に保ちました。1 つの中央の場所でポリシータグを定義し、さまざまなクエリエンジンに普遍的に適用しました。最後に、リアルタイムのデータリネージを使用して、データの移動全体を自動的に追跡しました。
次のステップ
- Managed Service for Apache Spark: Serverless Spark のドキュメント ページで、クラスタをプロビジョニングせずにデータ パイプラインをスケーリングする方法を確認します。
- 高度なアクセス制御を調べる: より複雑なセキュリティ シナリオを実装するには、追加機能を使用して Lakehouse をカスタマイズする方法に関する公式ドキュメントをご覧ください。
- GenAI の非構造化データを管理する: オブジェクト テーブルを確認します。この安全なブリッジ パターンを Cloud Storage 内の非構造化ファイル(PDF、画像)に拡張し、Vertex AI と RAG パイプラインの安全で管理されたデータ基盤を確立します。
- 他のユースケースを試す: Knowledge Catalog の他のユースケースを試します。