
Knowledge Catalog 検出エージェントは、Knowledge Catalog の検索機能に基づいて、複雑な自然言語クエリの検索関連性を向上させる AI 搭載アシスタントです。クエリの理解と作成を最適化することで、標準の Knowledge Catalog Search API よりも正確な結果が得られます。この機能は、特に複雑なクエリや長いクエリで重要になります。
ユースケース
検出エージェントは、次のようなシナリオでリッチな会話機能を提供します。
- 複雑なインテントや複合インテントと制約:
us-central1のデータセットを検索するが、BigQuery のリソースは除外するなど、複数の条件で検索リクエストを処理します。 - ビジネス指向の検索: 正確な技術用語を照合するのではなく、インテントとビジネス コンテキストに基づいてデータアセットを検出します。
- マルチターンの探索: 会話形式のダイアログで検索を絞り込み、結果を絞り込みます。
検出エージェントは、 Knowledge Catalog セマンティック検索 に基づいて構築されており、すぐに使用できるハイブリッド検索を提供します。高インテント検索(特定のリソースまたは列がわかっている場合)、低レイテンシ要件、ゼロ設定のハイブリッド検索を処理する必要がある場合は、Knowledge Catalog セマンティック検索を直接使用できます。
仕組み
検出エージェントは、検索クエリに応答するために次の手順を実行します。
- 入力のインテントを分析してクエリを理解し、複数の検索バリエーションを生成して、用語をメタデータ フィルタにマッピングします。
- Knowledge Catalog セマンティック検索を使用してリソースを検索します。
- 関連性に基づいて結合された結果をランク付けします。
次の図に、プロセスの詳細を示します。
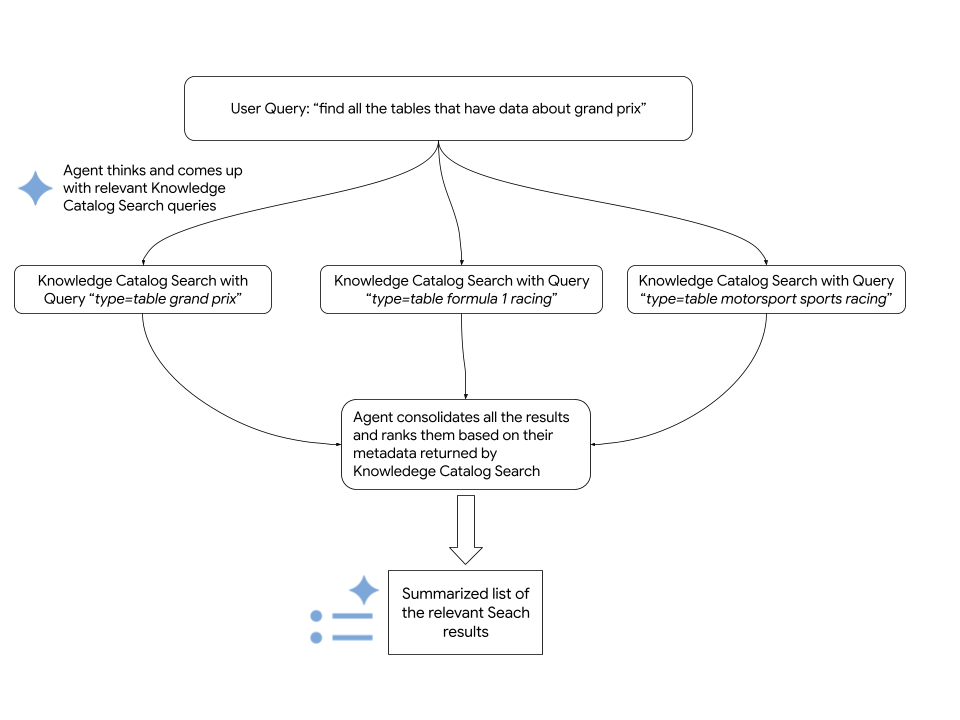
エージェントは Knowledge Catalog Search API を使用して、関連する Google Cloud リソースを取得します。次のコード スニペットは、エージェントが Knowledge Catalog セマンティック検索を呼び出す方法を示しています。
# Configure the request parameters for the
# call to Knowledge Catalog Semantic Search API.
endpoint = "dataplex.googleapis.com"
client = dataplex_v1.CatalogServiceClient(
client_options={"api_endpoint": endpoint}
)
location = "global"
consumer_project_id = "my-gcp-project"
parent_name = f"projects/{consumer_project_id}/locations/{location}"
# Call Knowledge Catalog Semantic Search API.
response = client.search_entries(
request={
"name": parent_name,
"query": query,
"page_size": 50,
"semantic_search": True,
}
)
# Call Knowledge Catalog LookupContext for each search result
# to retrieve rich, LLM-ready metadata.
entries = []
for result in response.results:
entry_name = result.dataplex_entry.name
# Prepare the LookupContext request for the specific resource
lookup_request = {
"name": parent_name,
"resources": [entry_name]
}
# Call the LookupContext API
lookup_response = client.lookup_context(request=lookup_request)
# Extract the rich context YAML to share with the agent
entries.append({
"entry_name": entry_name,
"context": lookup_response.context
})
return {"results": entries}
始める前に
Knowledge Catalog 検出エージェントを実行するには、次の要件を満たしていることを確認してください。
必要なロール
検出エージェントを使用するために必要な権限を取得するには、プロジェクトに対する次の IAM ロールの付与を管理者に依頼してください。 Google Cloud iam.gserviceaccount.com
- Dataplex 閲覧者 (
roles/dataplex.viewer) - Vertex AI ユーザー (
roles/aiplatform.user) - Service Usage コンシューマー (
roles/serviceusage.serviceUsageConsumer)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
これらの事前定義ロールには 検出エージェントの使用に必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
検出エージェントを使用するには、次の権限が必要です。
-
dataplex.projects.search -
aiplatform.endpoints.predict -
serviceusage.services.use
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
API を有効にする
Knowledge Catalog 検出エージェントを使用するには、プロジェクトで Knowledge Catalog API、Vertex AI API、Service Usage API を有効にします。
API を有効にするために必要なロール
API を有効にするには、serviceusage.services.enable 権限が必要です。プロジェクトを作成した場合は、オーナーロール(roles/owner)を介してこの権限が付与されている可能性があります。それ以外の場合は、Service Usage 管理者ロール(roles/serviceusage.serviceUsageAdmin)を介してこの権限を取得できます。ロールを付与する方法をご覧ください。
環境を設定する
検出エージェントの開発環境を設定するには、次の操作を行います。
dataplex-labsリポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/dataplex-labs.gitエージェント ディレクトリに移動します。
cd dataplex-labs/knowledge_catalog_discovery_agentPython 仮想環境を作成して有効にし、 ファイルに記載されている依存関係をインストールします。
requirements.txtgoogle-adk(Agent Development Kit)google-cloud-dataplex(Knowledge Catalog Python クライアント)google-api-core
python3 -m venv /tmp/kcsearch source /tmp/kcsearch/bin/activate pip3 install -r requirements.txt次のコマンドで環境変数を設定します。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID export GOOGLE_GENAI_USE_VERTEXAI=True次のように置き換えます。
PROJECT_IDはプロジェクトの ID に置き換えます。
検出エージェントをルート エージェントとして実行する
検出エージェントをルート エージェントとして直接実行するには、次の操作を行います。
knowledge_catalog_discovery_agentフォルダにあるagent.pyファイルで、discovery_agent変数をroot_agentに変更します。adk runコマンドを使用してエージェントを実行します。adk run path/to/agent/parent/folder次のように置き換えます。
path/to/agent/parent/folderは、エージェントを含むフォルダを含む親ディレクトリに置き換えます。たとえば、エージェントがknowledge_catalog_discovery_agent/にある場合は、agents/ディレクトリからadk runを実行します。
検出エージェントをエージェント ツールとして実行する
検出エージェントを my_custom_agent などの大規模なカスタム エージェントに統合するには、次の操作を行います。
検出エージェント モジュールを含むようにプロジェクト構造を設定します。
my_custom_agent/ ├── agent.py └── knowledge_catalog_discovery_agent/ ├── SKILL.md ├── agent.py ├── tools.py └── utils.pyカスタム エージェントの
agent.pyファイルで、検出エージェントをインポートしてエージェント ツールとして使用します。例をご覧ください。root_agent = llm_agent.Agent( model=google_llm.Gemini(model=GEMINI_MODEL), name="my_custom_agent", instruction=( "You are a Custom Agent. Your goal is to help users understand" " their data landscape, evaluate data assets, and derive insights" " from available resources. **IMPORTANT**: You should use the" " `knowledge_catalog_discovery_agent` to search for and discover" " data assets. For best results, pass in the Natural Language user'" " query as is to the `knowledge_catalog_discovery_agent`. Once assets" " are found, you should analyze their metadata, compare them, and" " provide recommendations or summaries to the user to help them make" " decisions. Focus on general metadata summary and comparison." ), tools=[ agent_tool.AgentTool(discovery_agent), ], )adk runコマンドを使用してエージェントを実行します。adk run path/to/agent/parent/folder次のように置き換えます。
path/to/agent/parent/folderは、my_custom_agent/フォルダを含む親ディレクトリに置き換えます。たとえば、エージェントがagents/my_custom_agent/にある場合は、adk runディレクトリからagents/を実行します。
次のステップ
- Knowledge Catalog の検索構文について理解する。
- Agent Development Kit の詳細を確認する。
- 他の Knowledge Catalog のユースケースを試す。