
Questo tutorial mostra come utilizzare la sintassi YAML di Apache Beam per creare pipeline di elaborazione dati Dataflow. Imparerai a leggere i dati da un file, applicare trasformazioni e scrivere i risultati in un altro file utilizzando l'interfaccia utente del builder di job nella console Google Cloud . Questo tutorial è destinato agli sviluppatori che non hanno mai utilizzato Apache Beam o che vogliono imparare a utilizzare l'API YAML per creare pipeline.
La tabella seguente mostra un grafico della pipeline nella console Google Cloud e la relativa specifica YAML.
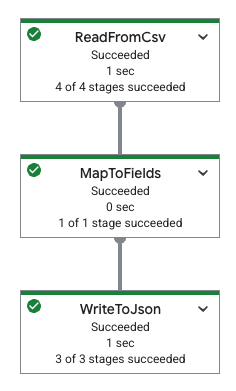
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
Obiettivi
In questo tutorial imparerai a:
- Crea pipeline Beam YAML che leggono, scrivono e trasformano i dati.
- Filtra i dati in base ai contenuti.
- Mappa i campi utilizzando le espressioni Python.
- Utilizza SQL per eseguire query e aggregare i dati.
- Crea ed esegui pipeline Beam YAML utilizzando il modulo del builder nell'interfaccia utente del builder dei job nella console Google Cloud .
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per saperne di più, consulta Esegui la pulizia.
Prima di iniziare
Completa i seguenti passaggi prima di eseguire la pipeline.
Configura il progetto
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
Crea un bucket Cloud Storage
Prima di poter eseguire una pipeline, devi creare un bucket Cloud Storage.
Crea un bucket Cloud Storage:
- Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci le informazioni del bucket. Per andare al passaggio
successivo, fai clic su Continua.
- Per Assegna un nome al bucket, inserisci un nome univoco per il bucket. Non includere informazioni sensibili nel nome del bucket, poiché lo spazio dei nomi dei bucket è globale e visibile pubblicamente.
-
Nella sezione Scegli dove archiviare i tuoi dati, segui questi passaggi:
- Seleziona un Tipo di località.
- Scegli una posizione in cui i dati del bucket vengono archiviati in modo permanente dal menu a discesa Tipo di località.
- Se selezioni il tipo di località a doppia regione, puoi anche scegliere di attivare la replica turbo utilizzando la casella di controllo pertinente.
- Per configurare la replica tra bucket, seleziona
Aggiungi una replica tra bucket mediante Storage Transfer Service e
segui questi passaggi:
Configura la replica tra bucket
- Nel menu Bucket, seleziona un bucket.
Nella sezione Impostazioni di replica, fai clic su Configura per configurare le impostazioni per il job di replica.
Viene visualizzato il riquadro Configura replica tra bucket.
- Per filtrare gli oggetti da replicare in base al prefisso del nome dell'oggetto, inserisci un prefisso da cui includere o escludere gli oggetti, quindi fai clic su Aggiungi un prefisso.
- Per impostare una classe di archiviazione per gli oggetti replicati, seleziona una classe di archiviazione dal menu Classe di archiviazione. Se salti questo passaggio, gli oggetti replicati utilizzeranno per impostazione predefinita la classe di archiviazione del bucket di destinazione.
- Fai clic su Fine.
-
Nella sezione Scegli come archiviare i tuoi dati, segui questi passaggi:
- Nella sezione Impostare una classe predefinita, seleziona quanto segue: Standard.
- Per attivare lo spazio dei nomi gerarchico, nella sezione Ottimizza l'archiviazione per workload con uso intensivo dei dati, seleziona Abilita uno spazio dei nomi gerarchico in questo bucket.
- Nella sezione Scegli come controllare l'accesso agli oggetti, seleziona se il bucket applica o meno la prevenzione dell'accesso pubblico e seleziona un metodo di controllo dell'accesso per gli oggetti del bucket.
-
Nella sezione Scegli come proteggere i dati degli oggetti, segui questi passaggi:
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
- Per attivare l'eliminazione temporanea, fai clic sulla casella di controllo Criterio di eliminazione temporanea (per il recupero dei dati) e specifica il numero di giorni per cui vuoi conservare gli oggetti dopo l'eliminazione.
- Per impostare il controllo delle versioni degli oggetti, seleziona la casella di controllo Controllo delle versioni degli oggetti (per il controllo delle versioni) e specifica il numero massimo di versioni per oggetto e il numero di giorni dopo i quali scadono le versioni non correnti.
- Per abilitare il criterio di conservazione su oggetti e bucket, seleziona la casella di controllo Conservazione (per la conformità), quindi procedi nel seguente modo:
- Per attivare il blocco della conservazione degli oggetti, fai clic sulla casella di controllo Abilita conservazione degli oggetti.
- Per attivare Bucket Lock, fai clic sulla casella di controllo Imposta criterio di conservazione del bucket e scegli un'unità di tempo e una durata per il periodo di conservazione.
- Per scegliere come verranno criptati i dati degli oggetti, espandi la sezione Crittografia dei dati () e seleziona un metodo di crittografia dei dati.
- Seleziona una delle opzioni in Protezione dei dati che vuoi impostare per il bucket.
- Fai clic su Crea.
Copia quanto segue, perché ti servirà in una sezione successiva:
- Il nome del bucket Cloud Storage.
- L'ID progetto Google Cloud .
Per trovare questo ID, consulta Identificazione dei progetti.
Rete VPC
Per impostazione predefinita, ogni nuovo progetto viene avviato con una rete
predefinita. Se la rete predefinita per il tuo progetto
è disabilitata o è stata eliminata, devi avere una
rete nel tuo progetto per la quale il tuo account utente ha il ruolo Utente di rete
Compute
(roles/compute.networkUser).
Leggere, scrivere e trasformare i dati
Questa sezione mostra come utilizzare la sintassi Beam YAML con Dataflow per leggere, scrivere e filtrare i dati utilizzando quanto segue:
- Sviluppo basato sull'interfaccia utente per creare ed eseguire job nell'interfaccia utente del builder di job nella console Google Cloud . Nello specifico, utilizzerai il modulo del builder nell'interfaccia utente del builder di job, in modo da non dover creare manualmente i file YAML.
Dati del file CSV archiviati in un bucket Cloud Storage visibile pubblicamente. Questi dati contengono dati fittizi del menu del ristorante e hanno il seguente aspetto:
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
Leggere e filtrare i dati
L'esempio seguente mostra come leggere i dati da un file CSV, filtrarli per informazioni specifiche e scrivere i dati filtrati in un file JSON.
Questo esempio utilizza la Filter
trasformazione, che
consente di conservare in modo selettivo i dati che soddisfano determinati criteri. L'esempio
seguente filtra un set di dati in modo da conservare solo i record in cui Price è maggiore
o uguale a 20.00.
Per leggere i dati CSV e generare contenuti JSON filtrati, completa i seguenti passaggi:
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Fai clic su Crea job da Builder.
Nella scheda Generatore di job, lascia selezionato Modulo del generatore.
Nel campo Nome job, inserisci
filter-python-job.Per Tipo di prestazione, lascia selezionato Batch.
Nella sezione Fonti:
Nel campo Nome origine del riquadro Nuova origine, modifica il nome in
ReadCsv.Nell'elenco Tipo di origine, seleziona CSV da Cloud Storage.
Nel campo Percorso CSV, inserisci:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvFai clic su Fine.
Nella sezione Trasformazioni:
Fai clic su Aggiungi una trasformazione.
Nel campo Nome trasformazione, inserisci
FilterPrice.Nell'elenco Tipo di trasformazione, seleziona Filtro (Python).
Nel campo Espressione di filtro Python, inserisci
Price >= 20.00.Nell'elenco Input step for the transform (Passaggio di input per la trasformazione), lascia selezionata l'opzione
ReadCsv.Fai clic su Fine.
Nella sezione Sink:
Nel campo Nome sink, modifica il nome in
WriteJson.Nell'elenco Tipo di sink, seleziona File JSON su Cloud Storage.
Nel campo Posizione JSON, inserisci:
BUCKET_NAME/output/restaurant-data_filtered.jsonSostituisci
BUCKET_NAMEcon il nome del tuo bucket Cloud Storage.Nell'elenco Passaggio di input per il sink, lascia selezionato
FilterPrice.Fai clic su Fine.
Nella sezione Opzioni Dataflow, fai clic su Esegui job.
Esamina l'output del job
Al termine del job, completa i seguenti passaggi per visualizzare l'output della pipeline:
Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
Nell'elenco dei bucket, fai clic sul nome del bucket che hai creato in Crea un bucket Cloud Storage.
Fai clic sul file denominato
restaurant-data_filtered.json-00000-of-00001.Nella pagina Dettagli oggetto, fai clic sull'URL autenticato per visualizzare l'output della pipeline.
L'output dovrebbe essere simile al seguente:
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Mappare i campi utilizzando Python
Con la MapToFields
trasformazione, puoi creare
nuovi campi in base a quelli esistenti. L'esempio seguente crea una versione in minuscolo
di una voce di menu, calcola un prezzo totale e aggiunge i valori dopo
i valori esistenti.
Vai alla pagina Job Dataflow nella consoleGoogle Cloud .
Fai clic su Crea job da builder.
Nella scheda Generatore di job, lascia selezionato Modulo del generatore.
Nel campo Nome job, inserisci
map-python-job.Per Tipo di prestazione, lascia selezionato Batch.
Nella sezione Fonti:
Nel campo Nome origine del riquadro Nuova origine, modifica il nome in
ReadFromCsvPy.Nell'elenco Tipo di origine, seleziona CSV da Cloud Storage.
Nel campo Percorso CSV, inserisci:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvFai clic su Fine.
Nella sezione Trasformazioni:
Fai clic su Aggiungi una trasformazione.
Nel campo Nome trasformazione, inserisci
MapToFieldsPy.Nell'elenco Tipo di trasformazione, seleziona Mappa campi (Python).
Lascia selezionata l'opzione Conserva campi esistenti.
Nella sezione Campi mappati, fai clic su Aggiungi un campo.
Nel riquadro Nuovo campo che si apre, inserisci
Lowercase_menu_itemcome Nome campo.Nel campo Espressione Python, inserisci
Item.lower().Fai clic su Fine.
Nella stessa sezione Campi mappati, fai di nuovo clic su Aggiungi un campo.
Nel riquadro Nuovo campo che si apre, inserisci
Total_pricecome Nome campo.Nel campo Espressione Python, inserisci
Price + Tax.In questo riquadro Nuovo campo, fai clic su Fine.
In questo riquadro Nuova trasformazione, fai clic su Fine.
Nella sezione Sink:
Nel campo Nome sink, modifica il nome in
WriteToJsonPy.Nell'elenco Tipo di sink, seleziona File JSON su Cloud Storage.
Nel campo Posizione JSON, inserisci:
BUCKET_NAME/output/restaurant-data_map-fields.jsonSostituisci
BUCKET_NAMEcon il nome del tuo bucket Cloud Storage.Nell'elenco Passaggio di input per il sink, lascia selezionato
MapToFieldsPy.Fai clic su Fine.
Nella sezione Opzioni Dataflow, fai clic su Esegui job.
Esamina l'output del job
Al termine del job, completa i seguenti passaggi per visualizzare l'output della pipeline:
Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
Nell'elenco dei bucket, fai clic sul nome del bucket che hai creato in Crea un bucket Cloud Storage.
Fai clic sul file denominato
restaurant-data_map-fields.json-00000-of-00001.Nella pagina Dettagli oggetto, fai clic sull'URL autenticato per visualizzare l'output della pipeline.
L'output dovrebbe essere simile al seguente:
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
Trasformare i dati utilizzando SQL
La Sql
trasformazione
consente di eseguire query SQL sui dati. Il seguente esempio raggruppa le voci di menu
per categoria (ad esempio Entree, Beverage o Dessert) e aggiunge una colonna con
il conteggio degli elementi in ogni categoria.
Per utilizzare l'interfaccia utente di creazione dei job per creare la pipeline:
Vai alla pagina Job Dataflow nella console Google Cloud .
Fai clic su Crea job da builder.
Nella scheda Job Builder, nel campo Nome job, inserisci
sql-transform-job.Per Tipo di prestazione, lascia selezionato Batch.
Nella sezione Fonti:
Nel campo Nome origine, modifica il nome in
SqlTransformSource.Nella scheda Nuova origine, per Tipo di origine, seleziona CSV da Cloud Storage. Si apre il campo Posizione CSV.
In Posizione CSV, inserisci:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvFai clic su Fine.
Nella sezione Trasformazioni:
Fai clic su Aggiungi una trasformazione.
Nel campo Nome trasformazione, aggiorna il nome a
SqlTransform.In Tipo di trasformazione, seleziona Trasformazione SQL. Si aprono le opzioni di Trasformazione SQL.
Nel campo Espressione SQL, inserisci:
select Category, count(*) as category_count from PCOLLECTION group by CategoryFai clic su Fine.
Nella sezione Sink:
In Nome sink, inserisci
SqlTransformSink.In Tipo di sink, seleziona File JSON su Cloud Storage. Si aprono le opzioni Scrivi nei file JSON su Cloud Storage.
In Posizione JSON, inserisci:
BUCKET_NAME/output/restaurant-data_transform-sql.jsonSostituisci
BUCKET_NAMEcon il nome del tuo bucket Cloud Storage.Fai clic su Fine.
(Facoltativo) Visualizza la definizione YAML generata per questa pipeline.
Vai alla parte superiore della scheda Generatore di job.
Seleziona Editor YAML. Dovresti visualizzare la definizione YAML. Dovrebbe avere il seguente aspetto:
Specifica YAML generata
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
Nella sezione Opzioni Dataflow, fai clic su Esegui job.
Esamina l'output del job
Al termine del job, completa i seguenti passaggi per visualizzare l'output della pipeline:
Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
Nell'elenco dei bucket, fai clic sul nome del bucket che hai creato in Crea un bucket Cloud Storage.
Fai clic sul file denominato
restaurant-data_transform-sql.json-00000-of-00001.Nella pagina Dettagli oggetto, fai clic sull'URL autenticato per visualizzare l'output della pipeline.
L'output dovrebbe essere simile al seguente:
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
- Nella console Google Cloud , vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona quello che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Elimina le singole risorse
Se vuoi riutilizzare il progetto in un secondo momento, puoi conservarlo, ma elimina le risorse che hai creato durante il tutorial.
Arresta la pipeline Dataflow
Nella console Google Cloud , vai alla pagina Job di Dataflow.
Fai clic sul job che vuoi interrompere.
Per interrompere un job, il suo stato deve essere In esecuzione.
Nella pagina dei dettagli del job, fai clic su Interrompi.
Fai clic su Annulla.
Per confermare la tua scelta, fai clic su Interrompi lavoro.
Elimina il bucket Cloud Storage
- Nella console Google Cloud , vai alla pagina Bucket in Cloud Storage.
- Fai clic sulla casella di controllo del bucket da eliminare.
- Per eliminare il bucket, fai clic su Elimina, quindi segui le istruzioni.
Passaggi successivi
- Scopri di più sulla creazione di job utilizzando la panoramica dell'interfaccia utente di creazione dei job nella console Google Cloud .
- Scopri di più sui job personalizzati del builder dedicato in Creare un job personalizzato con il builder dedicato.
- Leggi la panoramica dell'API Beam YAML.
- Visualizza altri esempi di YAML Beam.