
Ce tutoriel vous explique comment utiliser la syntaxe Apache Beam YAML pour créer des pipelines de traitement de données Dataflow. Vous apprendrez à lire des données à partir d'un fichier, à appliquer des transformations et à écrire les résultats dans un autre fichier à l'aide de l'interface utilisateur du générateur de jobs dans la console Google Cloud . Ce tutoriel s'adresse aux développeurs qui débutent avec Apache Beam ou qui souhaitent apprendre à utiliser l'API YAML pour créer des pipelines.
Le tableau suivant présente un graphique de pipeline dans la console Google Cloud et sa spécification YAML correspondante.
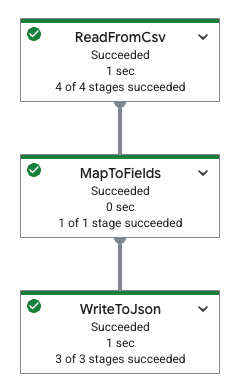
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
Objectifs
Dans ce tutoriel, vous allez apprendre à effectuer les opérations suivantes :
- Créez des pipelines Beam YAML qui lisent, écrivent et transforment des données.
- Filtrer les données en fonction du contenu.
- Mappez les champs à l'aide d'expressions Python.
- Utiliser SQL pour interroger et agréger des données
- Créez et exécutez des pipelines Beam YAML à l'aide du formulaire du générateur dans l'UI du générateur de jobs de la console Google Cloud .
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
Effectuez les étapes suivantes avant d'exécuter votre pipeline.
Configurer votre projet
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
Créer un bucket Cloud Storage
Avant de pouvoir exécuter un pipeline, vous devez créer un bucket Cloud Storage.
Créez un bucket Cloud Storage :
- Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
- Pour Nommer votre bucket, saisissez un nom unique. N'incluez aucune information sensible dans le nom des buckets, car leur espace de noms est global et visible par tous.
-
Dans la section Choisir l'emplacement de stockage de vos données, procédez comme suit :
- Sélectionnez un type d'emplacement.
- Choisissez un emplacement où les données de votre bucket seront stockées de manière permanente dans le menu déroulant Type d'emplacement.
- Si vous sélectionnez le type d'emplacement birégional, vous pouvez également choisir d'activer la réplication turbo à l'aide de la case à cocher correspondante.
- Pour configurer la réplication entre buckets, sélectionnez Ajouter une réplication entre buckets via le service de transfert de stockage et suivez ces étapes :
Configurer la réplication entre buckets
- Dans le menu Bucket, sélectionnez un bucket.
Dans la section Paramètres de réplication, cliquez sur Configurer pour configurer les paramètres du job de réplication.
Le volet Configurer la réplication entre buckets s'affiche.
- Pour filtrer les objets à répliquer en fonction du préfixe de leur nom, saisissez le préfixe avec lequel vous souhaitez inclure ou exclure des objets, puis cliquez sur Ajouter un préfixe.
- Pour définir une classe de stockage pour les objets répliqués, sélectionnez-en une dans le menu Classe de stockage. Si vous ignorez cette étape, les objets répliqués utiliseront la classe de stockage par défaut du bucket de destination.
- Cliquez sur OK.
-
Dans la section Choisir comment stocker vos données, procédez comme suit :
- Dans la section Définir une classe par défaut, sélectionnez Standard.
- Pour activer l'espace de noms hiérarchique, dans la section Optimiser l'espace de stockage pour les charges de travail utilisant beaucoup de données, sélectionnez Activer l'espace de noms hiérarchique sur ce bucket.
- Dans la section Choisir comment contrôler l'accès aux objets, indiquez si votre bucket applique ou non la protection contre l'accès public et sélectionnez une méthode de contrôle des accès pour les objets de votre bucket.
-
Dans la section Choisir comment protéger les données d'objet, procédez comme suit :
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Pour activer la suppression réversible, cochez la case Règle de suppression réversible (pour la récupération de données), puis spécifiez le nombre de jours pendant lesquels vous souhaitez conserver les objets après leur suppression.
- Pour configurer la gestion des versions d'objets, cochez la case Gestion des versions des objets (pour le contrôle des versions), puis spécifiez le nombre maximal de versions par objet et le nombre de jours après lesquels les versions obsolètes expirent.
- Pour activer la règle de conservation sur les objets et les buckets, cochez la case Conservation (pour la conformité), puis procédez comme suit :
- Pour activer le verrou de conservation des objets, cochez la case Activer la conservation des objets.
- Pour activer le verrou de bucket, cochez la case Définir une règle de conservation du bucket, puis choisissez une unité de temps et une durée pour votre période de conservation.
- Pour choisir comment vos données d'objet seront chiffrées, développez la section Chiffrement des données (), puis sélectionnez une méthode de chiffrement des données.
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Cliquez sur Créer.
Copiez les éléments suivants, car vous en aurez besoin dans une section ultérieure :
- Le nom de votre bucket Cloud Storage.
- ID de votre projet Google Cloud .
Pour trouver cet ID, consultez Identifier des projets.
Réseau VPC
Par défaut, chaque nouveau projet démarre avec un réseau par défaut. Si le réseau par défaut de votre projet est désactivé ou a été supprimé, vous devez disposer d'un réseau dans votre projet pour lequel votre compte utilisateur dispose du rôle Utilisateur de réseau Compute (roles/compute.networkUser).
Lire, écrire et transformer des données
Cette section explique comment utiliser la syntaxe Beam YAML avec Dataflow pour lire, écrire et filtrer des données à l'aide des éléments suivants :
- Développement axé sur l'interface utilisateur pour créer et exécuter des jobs dans l'interface utilisateur du générateur de jobs de la console Google Cloud . Plus précisément, vous utiliserez le formulaire de générateur dans l'UI du générateur de jobs. Vous n'aurez donc pas besoin de créer manuellement les fichiers YAML.
Données de fichier CSV stockées dans un bucket Cloud Storage accessible au public. Ces données contiennent des données fictives de menus de restaurants et se présentent comme suit :
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
Lire et filtrer des données
L'exemple suivant montre comment lire des données à partir d'un fichier CSV, les filtrer pour obtenir des informations spécifiques et écrire les données filtrées dans un fichier JSON.
Cet exemple utilise la transformation Filter, qui vous permet de conserver de manière sélective les données qui répondent à certains critères. L'exemple suivant filtre un ensemble de données pour ne conserver que les enregistrements où Price est supérieur ou égal à 20.00.
Pour lire les données CSV et générer du contenu JSON filtré, procédez comme suit :
Dans la console Google Cloud , accédez à la page Tâches Dataflow.
Cliquez sur Créer un job dans le générateur.
Dans l'onglet Générateur de jobs, laissez l'option Formulaire du générateur sélectionnée.
Dans le champ Nom du job, saisissez
filter-python-job.Pour Type de job, laissez l'option Lot sélectionnée.
Dans la section Sources :
Dans le champ Nom de la source du panneau Nouvelle source, remplacez le nom par
ReadCsv.Dans la liste Type de source, sélectionnez CSV depuis Cloud Storage.
Dans le champ Emplacement du fichier CSV, saisissez :
cloud-samples-data/dataflow/tutorials/restaurant-data.csvCliquez sur OK.
Dans la section Transformations :
Cliquez sur Ajouter une transformation.
Dans le champ Nom de la transformation, saisissez
FilterPrice.Dans la liste Type de transformation, sélectionnez Filtrer (Python).
Dans le champ Expression de filtre Python, saisissez
Price >= 20.00.Dans la liste Étape d'entrée pour la transformation, laissez
ReadCsvsélectionné.Cliquez sur OK.
Dans la section Destinations :
Dans le champ Nom du récepteur, remplacez le nom par
WriteJson.Dans la liste Type de récepteur, sélectionnez Fichiers JSON dans Cloud Storage.
Dans le champ Emplacement du fichier JSON, saisissez :
BUCKET_NAME/output/restaurant-data_filtered.jsonRemplacez
BUCKET_NAMEpar le nom de votre bucket Cloud Storage.Dans la liste Étape d'entrée du récepteur, laissez
FilterPricesélectionné.Cliquez sur OK.
Dans la section Options Dataflow, cliquez sur Exécuter le job.
Examiner le résultat du job
Une fois le job terminé, procédez comme suit pour afficher la sortie du pipeline :
Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
Dans la liste des buckets, cliquez sur le nom du bucket que vous avez créé dans Créer un bucket Cloud Storage.
Cliquez sur le fichier nommé
restaurant-data_filtered.json-00000-of-00001.Sur la page Détails de l'objet, cliquez sur l'URL authentifiée pour afficher la sortie du pipeline.
Le résultat doit ressembler à ce qui suit :
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Mapper des champs à l'aide de Python
La transformation MapToFields vous permet de créer des champs à partir de ceux qui existent déjà. L'exemple suivant crée une version en minuscules d'un élément de menu, calcule un prix total et ajoute les valeurs après les valeurs existantes.
Accédez à la page Tâches Dataflow dans la consoleGoogle Cloud .
Cliquez sur Créer un job à partir du générateur.
Dans l'onglet Générateur de jobs, laissez l'option Formulaire du générateur sélectionnée.
Dans le champ Nom du job, saisissez
map-python-job.Pour Type de job, laissez l'option Lot sélectionnée.
Dans la section Sources :
Dans le champ Nom de la source du panneau Nouvelle source, remplacez le nom par
ReadFromCsvPy.Dans la liste Type de source, sélectionnez CSV depuis Cloud Storage.
Dans le champ Emplacement du fichier CSV, saisissez :
cloud-samples-data/dataflow/tutorials/restaurant-data.csvCliquez sur OK.
Dans la section Transformations :
Cliquez sur Ajouter une transformation.
Dans le champ Nom de la transformation, saisissez
MapToFieldsPy.Dans la liste Type de transformation, sélectionnez Mapper les champs (Python).
Laissez l'option Conserver les champs existants sélectionnée.
Dans la section Champs mappés, cliquez sur Ajouter un champ.
Dans le panneau Nouveau champ qui s'ouvre, saisissez
Lowercase_menu_itemcomme Nom du champ.Dans le champ Expression Python, saisissez
Item.lower().Cliquez sur OK.
Dans la même section Champs mappés, cliquez à nouveau sur Ajouter un champ.
Dans le panneau Nouveau champ qui s'ouvre, saisissez
Total_pricecomme Nom du champ.Dans le champ Expression Python, saisissez
Price + Tax.Dans le panneau Nouveau champ, cliquez sur Terminé.
Dans le panneau Nouvelle transformation, cliquez sur Terminé.
Dans la section Destinations :
Dans le champ Nom du récepteur, remplacez le nom par
WriteToJsonPy.Dans la liste Type de récepteur, sélectionnez Fichiers JSON dans Cloud Storage.
Dans le champ Emplacement du fichier JSON, saisissez :
BUCKET_NAME/output/restaurant-data_map-fields.jsonRemplacez
BUCKET_NAMEpar le nom de votre bucket Cloud Storage.Dans la liste Étape d'entrée du récepteur, laissez
MapToFieldsPysélectionné.Cliquez sur OK.
Dans la section Options Dataflow, cliquez sur Exécuter le job.
Examiner le résultat du job
Une fois le job terminé, procédez comme suit pour afficher la sortie du pipeline :
Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
Dans la liste des buckets, cliquez sur le nom du bucket que vous avez créé dans Créer un bucket Cloud Storage.
Cliquez sur le fichier nommé
restaurant-data_map-fields.json-00000-of-00001.Sur la page Détails de l'objet, cliquez sur l'URL authentifiée pour afficher la sortie du pipeline.
Le résultat doit ressembler à ce qui suit :
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
Transformer les données en utilisant SQL
La transformation Sql vous permet d'exécuter des requêtes SQL sur vos données. L'exemple suivant regroupe les éléments de menu par catégorie (par exemple, Entree, Beverage ou Dessert) et ajoute une colonne avec le nombre d'éléments dans chaque catégorie.
Pour créer votre pipeline à l'aide de l'interface utilisateur du générateur de tâches, procédez comme suit :
Accédez à la page Tâches Dataflow dans la console Google Cloud .
Cliquez sur Créer un job à partir du générateur.
Dans l'onglet Job builder (Créateur de jobs), dans le champ Job name (Nom du job), saisissez
sql-transform-job.Pour Type de job, laissez l'option Lot sélectionnée.
Dans la section Sources :
Dans le champ Nom de la source, remplacez le nom par
SqlTransformSource.Dans l'onglet Nouvelle source, sélectionnez CSV depuis Cloud Storage pour Type de source. Le champ Emplacement du fichier CSV s'ouvre.
Dans le champ Emplacement du fichier CSV, saisissez :
cloud-samples-data/dataflow/tutorials/restaurant-data.csvCliquez sur OK.
Dans la section Transformations :
Cliquez sur Ajouter une transformation.
Dans le champ Nom de la transformation, remplacez le nom par
SqlTransform.Pour Type de transformation, sélectionnez Transformation SQL. Les options de transformation SQL s'ouvrent.
Dans le champ Expression SQL, saisissez :
select Category, count(*) as category_count from PCOLLECTION group by CategoryCliquez sur OK.
Dans la section Destinations :
Dans le champ Nom du récepteur, saisissez
SqlTransformSink.Pour Type de destination, sélectionnez Fichiers JSON dans Cloud Storage. Les options Écrire dans des fichiers JSON sur Cloud Storage s'ouvrent.
Dans le champ Emplacement JSON, saisissez :
BUCKET_NAME/output/restaurant-data_transform-sql.jsonRemplacez
BUCKET_NAMEpar le nom de votre bucket Cloud Storage.Cliquez sur OK.
Facultatif : Affichez la définition YAML générée pour ce pipeline.
Accédez au haut de l'onglet "Job builder" (Créateur de tâches).
Sélectionnez Éditeur YAML. La définition YAML devrait s'afficher. Le résultat doit ressembler à ceci :
Spécification YAML générée
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
Dans la section Options Dataflow, cliquez sur Exécuter le job.
Examiner le résultat du job
Une fois le job terminé, procédez comme suit pour afficher la sortie du pipeline :
Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
Dans la liste des buckets, cliquez sur le nom du bucket que vous avez créé dans Créer un bucket Cloud Storage.
Cliquez sur le fichier nommé
restaurant-data_transform-sql.json-00000-of-00001.Sur la page Détails de l'objet, cliquez sur l'URL authentifiée pour afficher la sortie du pipeline.
Le résultat doit ressembler à ce qui suit :
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer les ressources individuelles
Si vous souhaitez réutiliser le projet ultérieurement, vous pouvez le conserver, mais supprimez les ressources que vous avez créées au cours du tutoriel.
Arrêter le pipeline Dataflow
Dans la console Google Cloud , accédez à la page Tâches Dataflow.
Cliquez sur la tâche que vous souhaitez arrêter.
Pour arrêter une tâche, son état doit être en cours d'exécution.
Sur la page des détails de la tâche, cliquez sur Arrêter.
Cliquez sur Annuler.
Pour confirmer votre choix, cliquez sur Arrêter la tâche.
Supprimer votre bucket Cloud Storage
- Dans la console Google Cloud , accédez à la page Buckets de Cloud Storage.
- Cochez la case correspondant au bucket que vous souhaitez supprimer.
- Pour supprimer le bucket, cliquez sur Supprimer , puis suivez les instructions.
Étapes suivantes
- Découvrez comment créer des jobs à l'aide de la présentation de l'UI du générateur de jobs dans la console Google Cloud .
- Pour en savoir plus sur les jobs personnalisés du générateur de jobs, consultez Créer un job personnalisé avec le générateur de jobs.
- Consultez la présentation de l'API YAML Beam.
- Consultez d'autres exemples de fichiers YAML Beam.