
La fonctionnalité d'adaptation des ressources utilise des optimisations de ressources Apache Beam pour personnaliser les ressources de nœuds de calcul d'un pipeline. La possibilité de cibler plusieurs ressources différentes par étapes de pipeline spécifiques offre au pipeline une flexibilité et une capacité supplémentaires, ainsi que des économies potentielles. Vous pouvez appliquer des ressources plus coûteuses aux étapes de pipeline qui les nécessitent, et des ressources moins coûteuses à d'autres étapes du pipeline. Utilisez l'ajustement approprié pour spécifier les besoins en ressources d'un pipeline entier ou d'étapes de pipeline spécifiques.
Compatibilité et limites
- Les optimisations de ressources sont compatibles avec les SDK Java et Python Apache Beam versions 2.31.0 et ultérieures.
- L'adaptation des ressources est possible avec les pipelines de traitement par lot.
L'adaptation des ressources est possible avec les pipelines de streaming pour lesquels l'autoscaling horizontal est activé.
- Vous pouvez l'activer en définissant l'option de pipeline
--experiments=enable_streaming_rightfitting.
- Vous pouvez l'activer en définissant l'option de pipeline
L'adaptation des ressources est compatible avec Dataflow Prime.
L'adaptation des ressources n'est pas compatible avec FlexRS.
Lorsque vous utilisez l'adaptation des ressources, n'utilisez pas l'option de
worker_acceleratorservice.Lorsque vous utilisez Dataflow Prime, la sélection automatique de VM n'est pas compatible.
Activer l'adaptation des ressources
Pour activer l'adaptation des ressources, utilisez une ou plusieurs des optimisations de ressources disponibles dans votre pipeline. Lorsque vous utilisez une optimisation de ressource dans votre pipeline, l'adaptation des ressources est automatiquement activée. Pour en savoir plus, consultez la section Utiliser les optimisations de ressources de ce document.
Optimisations de ressources disponibles
Les optimisations de ressources suivantes sont disponibles.
| Optimisation de ressource | Description |
|---|---|
min_ram |
Quantité minimale de mémoire RAM en gigaoctets à allouer aux nœuds de calcul. Dataflow utilise cette valeur comme limite inférieure lors de l'allocation de mémoire à de nouveaux nœuds de calcul (scaling horizontal) ou à des nœuds de calcul existants (scaling vertical). Exemple : min_ram=NUMBERGB
|
cpu_count |
Nombre de processeurs virtuels à allouer par nœud de calcul. Lorsque vous utilisez cette optimisation de ressource, Dataflow sélectionne les types de machines qui disposent du nombre spécifié de processeurs virtuels et qui répondent aux exigences de mémoire. Exemple : cpu_count=NUMBER
|
accelerator |
Allocation de GPU fournie par l'utilisateur qui vous permet de contrôler l'utilisation et le coût des GPU dans votre pipeline et ses étapes. Spécifiez le type et le nombre de GPU à associer aux nœuds de calcul Dataflow en tant que paramètres de l'option. Exemple : accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Pour en savoir plus sur l'utilisation des GPU, consultez la page GPU avec Dataflow. |
Sélection automatique de VM pour les types de machines de nœuds de calcul
Lorsque vous utilisez les optimisation de ressources min_ram ou cpu_count pour les étapes de pipeline qui
ne nécessitent pas d'accélérateurs,
la flexibilité des instances (sélection automatique de VM)
est activée automatiquement. Avec la sélection automatique de VM, les nœuds de calcul sont provisionnés à partir d'une sélection de types de machines qui répondent à vos exigences en matière de RAM et de processeur.
La sélection automatique de VM optimise la sélection de VM principalement pour la fiabilité et non pour les performances. Cela signifie que vous pouvez constater une baisse des performances lorsque vous utilisez la sélection automatique de VM pour améliorer la fiabilité de certaines de vos tâches hautement optimisées. Nous vous recommandons de tester la sélection automatique de VM sur un sous-ensemble de vos tâches existantes avant de les déployer progressivement à plus grande échelle.
Si vous utilisez des réservations Compute Engine avec la sélection automatique de VM, tenez compte des points suivants :
- Si vous disposez de réservations qui sont consommées automatiquement, elles peuvent être utilisées si Compute Engine provisionne des VM d'un type de machine correspondant.
- La sélection automatique de VM n'est pas compatible avec la consommation d'instances à partir d'une réservation spécifique.
- La sélection automatique de VM n'est pas compatible avec Dataflow Prime.
Pour en savoir plus, consultez la section Flexibilité des instances et réservations.
Optimisation imbriquée de ressources
Les optimisations de ressources sont appliquées à la hiérarchie des transformations du pipeline comme suit :
min_ram: la valeur d'une transformation est évaluée comme la plus grande valeur d'optimisationmin_ramparmi les valeurs définies sur la transformation elle-même et tous ses parents dans la hiérarchie de la transformation.- Exemple : Si une optimisation de transformation interne définit
min_ramsur 16 Go et que l'optimisation de transformation externe dans la hiérarchie définitmin_ramsur 32 Go, une optimisation de 32 Go sera utilisée pour toutes les étapes de la transformation complète. - Exemple : Si une optimisation de la transformation interne définit
min_ramsur 16 Go et que l'optimisation de transformation externe dans la hiérarchie définitmin_ramsur 8 Go, une optimisation de 8 Go sera utilisée pour toutes les étapes de la transformation externe qui ne se trouvent pas dans la transformation interne, et une optimisation de 16 Go sera utilisée pour toutes les étapes de la transformation interne.
- Exemple : Si une optimisation de transformation interne définit
accelerator: la valeur la plus profonde de la hiérarchie de la transformation est prioritaire.- Exemple : Si l'optimisation de transformation
acceleratord'une transformation interne est différente de celle d'une transformation externeacceleratordans une hiérarchie, l'optimisation de transformation interneacceleratorsera utilisée pour la transformation interne.
- Exemple : Si l'optimisation de transformation
Les indicateurs définis pour l'ensemble du pipeline sont traités comme s'ils étaient définis sur une transformation externe.
Utiliser les optimisations de ressources
Vous pouvez définir des optimisations de ressources sur l'ensemble du pipeline ou sur les étapes du pipeline.
Optimisations de ressources de pipeline
Vous pouvez définir des optimisations de ressources sur l'ensemble du pipeline lorsque vous l'exécutez à partir de la ligne de commande.
Pour configurer votre environnement Python, consultez le tutoriel Python.
Exemple :
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Optimisations de ressources d'une étape de pipeline
Vous pouvez définir des optimisations de ressources pour les étapes du pipeline (transformations) par programmation.
Java
Pour installer le SDK Apache Beam pour Java, consultez la page Installer le SDK Apache Beam.
Vous pouvez définir des optimisations de ressources par programmation sur les transformations de pipeline à l'aide de la classe ResourceHints.
L'exemple suivant montre comment définir des optimisations de ressources par programmation sur des transformations de pipeline.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
Pour définir de manière automatisée des optimisations de ressources sur l'ensemble du pipeline, utilisez l'interface ResourceHintsOptions.
Python
Pour installer le SDK Apache Beam pour Python, consultez la page Installer le SDK Apache Beam.
Vous pouvez définir des optimisations de ressources par programmation sur les transformations de pipeline à l'aide de la classe PTransforms.with_resource_hints.
Pour en savoir plus, consultez la section concernant la classe ResourceHint.
L'exemple suivant montre comment définir des optimisations de ressources par programmation sur des transformations de pipeline.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
Pour définir des optimisations de ressources sur l'ensemble du pipeline, utilisez l'option de pipeline --resource_hints lorsque vous exécutez votre pipeline. Pour obtenir un exemple, consultez la section Optimisations de ressources du pipeline.
Go
Les optimisations de ressources ne sont pas compatibles avec Go.
Compatibilité avec plusieurs accélérateurs
Dans un pipeline, différentes transformations peuvent avoir des configurations d'accélérateur différentes. Cela inclut les configurations qui nécessitent différents types de machines. Ces configurations d'accélérateur au niveau de la transformation sont prioritaires par rapport à la configuration au niveau du pipeline, le cas échéant.
Adaptation des ressources et fusion
Dans certains cas, les transformations définies avec différentes optimisations de ressources peuvent être exécutées sur des nœuds de calcul situés dans le même pool de nœuds de calcul, dans le cadre du processus d'optimisation de la fusion. Lorsque les transformations sont fusionnées, Dataflow les exécute dans un environnement qui satisfait à l'union des optimisations de ressources définies sur les transformations. Dans certains cas, cela inclut l'ensemble du pipeline.
Lorsqu'il est impossible de fusionner les optimisations de ressources, la fusion n'a pas lieu. Par exemple, les optimisations de ressources pour différents GPU ne peuvent pas être fusionnées. Ces transformations ne sont donc pas fusionnées.
Vous pouvez empêcher la fusion en ajoutant à votre pipeline une opération qui oblige Dataflow à matérialiser une PCollection intermédiaire. Cela est particulièrement utile lorsque vous essayez d'isoler des ressources coûteuses telles que des GPU ou des machines à mémoire élevée des étapes lentes ou coûteuses en calcul qui n'ont pas besoin de ces ressources spéciales. Dans ce cas, il peut être utile de forcer une rupture de fusion entre les étapes lentes liées au processeur et les étapes qui nécessitent des GPU coûteux ou des machines à mémoire élevée, et de payer le coût de la matérialisation associé à la rupture de fusion. Pour en savoir plus, consultez la section
Empêcher la fusion.
Adaptation des ressources en streaming
Pour les tâches de streaming, vous pouvez activer l'adaptation des ressources en définissant l'option de pipeline --experiments=enable_streaming_rightfitting.
L'adaptation des ressources peut améliorer les performances de votre pipeline s'il comporte des étapes avec des besoins en ressources différents.
Exemple : pipeline avec une étape nécessitant beaucoup de processeur et une étape nécessitant un GPU
Un exemple de pipeline qui peut bénéficier de l'adaptation des ressources est celui qui exécute une étape nécessitant beaucoup de processeur, suivie d'une étape nécessitant un GPU. Sans adaptation des ressources, un seul pool de nœuds de calcul GPU devra être configuré pour exécuter toutes les étapes du pipeline, y compris l'étape nécessitant beaucoup de processeur. Cela peut entraîner une sous-utilisation des ressources GPU lorsque le pool de nœuds de calcul exécute l'étape nécessitant beaucoup de processeur.
Si l'adaptation des ressources est activée et qu'une optimisation de ressource est appliquée à l'étape nécessitant un GPU, le pipeline crée deux pools distincts, de sorte que l'étape nécessitant beaucoup de processeur est exécutée par le pool de nœuds de calcul de processeur, et l'étape nécessitant un GPU est exécutée par le pool de nœuds de calcul GPU.
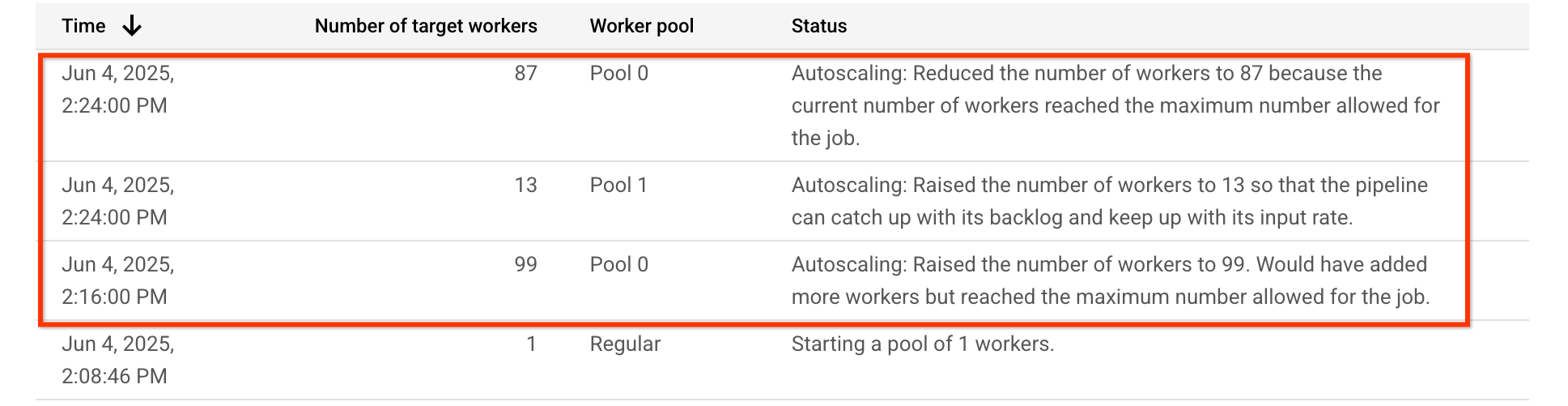
Pour cet exemple de pipeline, le tableau d'autoscaling montre que le pool de nœuds de calcul exécutant l'étape nécessitant beaucoup de processeur, Pool 0, est initialement mis à l'échelle à 99 nœuds de calcul, puis réduit à 87 nœuds de calcul. Le pool de nœuds de calcul exécutant l'étape nécessitant un GPU, Pool 1, est mis à l'échelle à 13 nœuds de calcul :
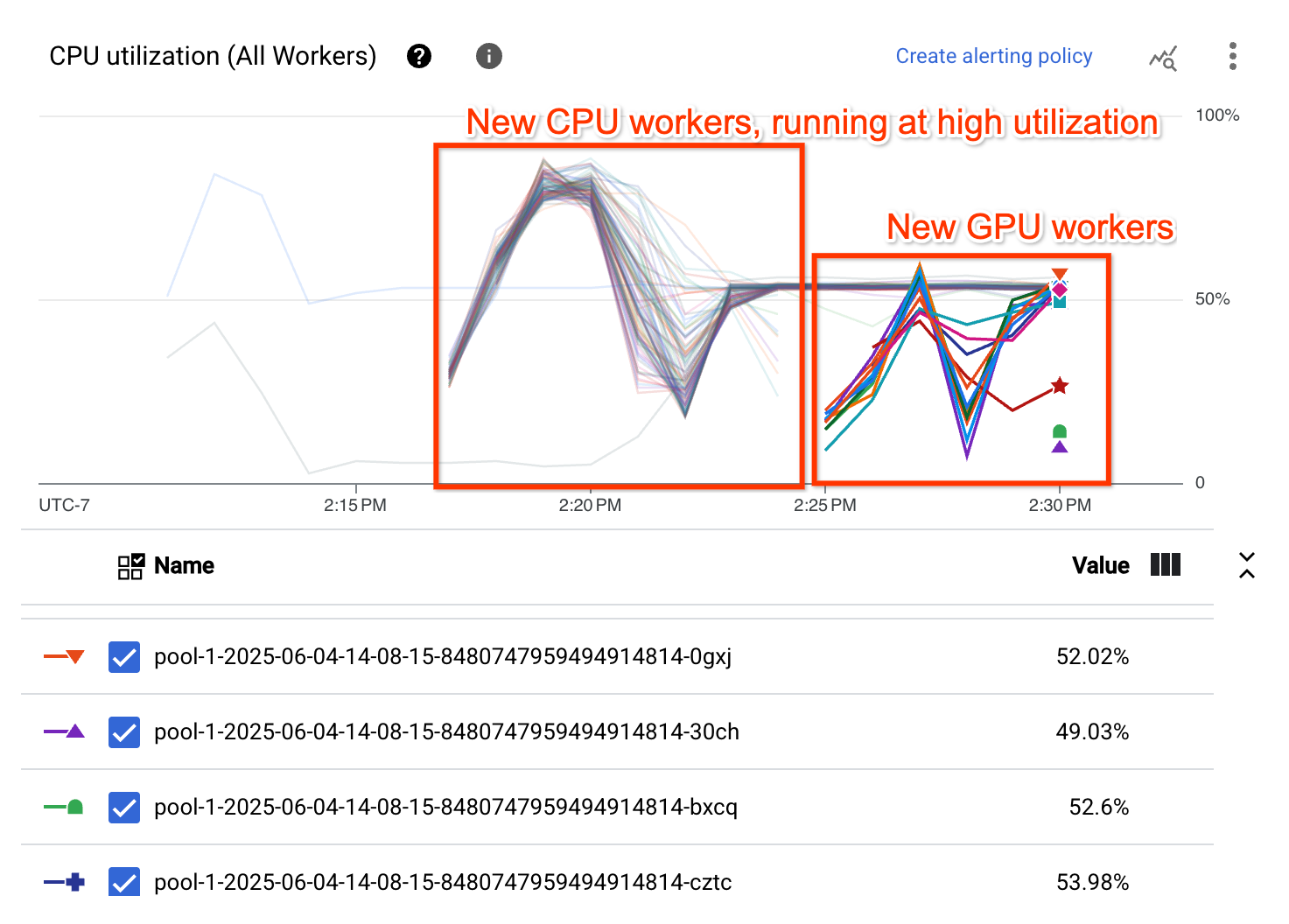
Le graphique d'utilisation du processeur montre que les nœuds de calcul des deux pools de nœuds de calcul présentent une utilisation globale élevée du processeur :
Résoudre les problèmes liés à l'adaptation des ressources
Cette section fournit des instructions permettant de résoudre les problèmes courants liés à l'adaptation des ressources.
Configuration non valide
Lorsque vous essayez d'utiliser l'adaptation des ressources, l'erreur suivante se produit :
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Cette erreur se produit lorsque le type de GPU sélectionné n'est pas compatible avec le type de machine sélectionné. Pour résoudre cette erreur, sélectionnez un type de GPU et un type de machine compatibles. Pour en savoir plus sur la compatibilité, consultez la page Plates-formes de GPU.
Vérifier l'adaptation des ressources
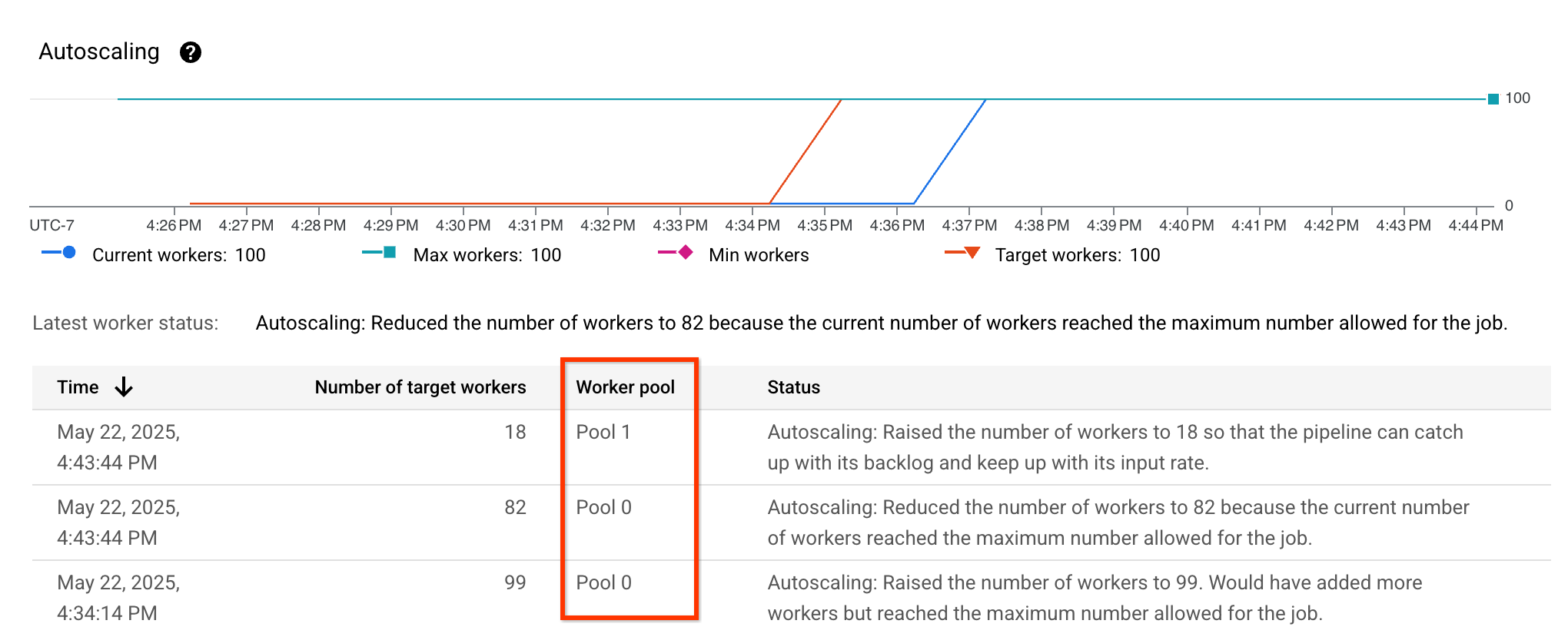
Vous pouvez vérifier que l'adaptation des ressources est activée en affichant les métriques d'autoscaling et en vérifiant que la colonne Worker pool est visible et répertorie différents pools :
Performances de l'adaptation des ressources en streaming
Les pipelines de streaming pour lesquels l'adaptation des ressources est activée ne sont pas toujours plus performants que les pipelines pour lesquels l'adaptation des ressources n'est pas activée. Exemple :
- Le pipeline utilise plus de nœuds de calcul.
- La latence du système est plus élevée ou le débit est plus faible.
- La taille des pools de nœuds de calcul change plus fréquemment ou ne se stabilise pas.
Si vous constatez ce problème pour votre pipeline, vous pouvez désactiver l'adaptation des ressources en supprimant l'option de pipeline --experiments=enable_streaming_rightfitting. De plus, les pipelines de streaming pour lesquels l'adaptation des ressources est activée à l'aide d'optimisations de ressources d'accélérateur peuvent utiliser plus d'accélérateurs que souhaité. Si vous constatez ce problème pour votre pipeline, vous pouvez configurer un nombre maximal d'accélérateurs utilisés par le pipeline en définissant l'--experiments=max_num_accelerators=NUM option de pipeline.