
אתם יכולים להשתמש בתשתית הרישום המובנית של Apache Beam SDK כדי לרשום מידע ביומן כשמריצים את צינור העיבוד. אתם יכולים להשתמש במסוףGoogle Cloud כדי לעקוב אחרי פרטי הרישום ביומן במהלך ההרצה של צינור עיבוד הנתונים ואחריה.
הוספת הודעות יומן לצנרת
Java
ב-Apache Beam SDK for Java מומלץ לרשום הודעות של תהליכי Worker באמצעות ספריית הקוד הפתוח Simple Logging Facade for Java (SLF4J). ה-SDK של Apache Beam ל-Java מטמיע את תשתית הרישום הנדרשת, כך שקוד ה-Java צריך רק לייבא את SLF4J API. לאחר מכן, הוא יוצר מופע של Logger כדי לאפשר רישום של הודעות ביומן בקוד של צינור העברת הנתונים.
במקרה של קוד או ספריות קיימים, Apache Beam SDK for Java מגדיר תשתית רישום נוספת. הודעות יומן שנוצרו על ידי ספריות הרישום הבאות עבור Java נלכדות:
Python
ערכת Apache Beam SDK ל-Python מספקת את חבילת הספרייה logging, שמאפשרת לעובדי צינור הנתונים להפיק הודעות יומן. כדי להשתמש בפונקציות של הספרייה, צריך לייבא את הספרייה:
import logging
המשך
Apache Beam SDK for Go מספק את חבילת הספרייה log, שמאפשרת לעובדי צינורות הנתונים להפיק הודעות יומן. כדי להשתמש בפונקציות של הספרייה, צריך לייבא את הספרייה:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
דוגמה לקוד של הודעת יומן של Worker
Java
בדוגמה הבאה נעשה שימוש ב-SLF4J לרישום ביומן של Dataflow. מידע נוסף על הגדרת SLF4J לרישום ביומן של Dataflow זמין במאמר טיפים ל-Java.
אפשר לשנות את הדוגמה WordCount של Apache Beam כדי להפיק הודעת יומן כשמוצאים את המילה love בשורה של הטקסט שעובר עיבוד. הקוד שנוסף מודגש במודגש בדוגמה הבאה (הקוד שמסביב כלול כדי לספק הקשר).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
אפשר לשנות את הדוגמה wordcount.py של Apache Beam כדי שהיא תפיק הודעת יומן כשהמילה love תימצא בשורה של הטקסט המעובד.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
המשך
אפשר לשנות את הדוגמה wordcount.go של Apache Beam כדי להפיק הודעת יומן כשנמצאת המילה love בשורה של הטקסט שעובר עיבוד.
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
אם מריצים את צינור עיבוד הנתונים WordCount ששונה באופן מקומי באמצעות DirectRunner שמוגדר כברירת מחדל, והפלט נשלח לקובץ מקומי (--output=./local-wordcounts), פלט המסוף כולל את הודעות היומן שנוספו:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
כברירת מחדל, רק שורות יומן שמסומנות ב-INFO ומעלה נשלחות אל Cloud Logging. כדי לשנות את ההתנהגות הזו, אפשר לעיין במאמר בנושא הגדרת רמות יומן של עובדי צינורות.
Python
אם מריצים את צינור עיבוד הנתונים WordCount ששונה באופן מקומי באמצעות DirectRunner שמוגדר כברירת מחדל, והפלט נשלח לקובץ מקומי (--output=./local-wordcounts), פלט המסוף כולל את הודעות היומן שנוספו:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
כברירת מחדל, רק שורות יומן שמסומנות בערך INFO ומעלה נשלחות אל Cloud Logging. כדי לשנות את ההתנהגות הזו, אפשר לעיין במאמר בנושא הגדרת רמות יומן של עובדי צינורות.
לא להחליף את הגדרת הרישום ביומן בפונקציות logging.config, כי זה עלול להשבית את רכיבי ה-handler של היומן שהוגדרו מראש ושמעבירים את יומני צינור עיבוד הנתונים אל Dataflow ואל Cloud Logging.
המשך
אם מריצים את צינור עיבוד הנתונים WordCount ששונה באופן מקומי באמצעות DirectRunner שמוגדר כברירת מחדל, והפלט נשלח לקובץ מקומי (--output=./local-wordcounts), פלט המסוף כולל את הודעות היומן שנוספו:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
כברירת מחדל, רק שורות יומן שמסומנות ב-INFO ומעלה נשלחות אל Cloud Logging.
הוספת הקשר מובנה וניתן לחיפוש ליומנים באמצעות MDC
אתם יכולים להשתמש ב-Mapped Diagnostic Context (MDC) כדי להוסיף צמדי מפתח/ערך מובנים ליומני Dataflow. כך קל יותר לשלוח שאילתות לגבי ההודעות ולנתח אותן ב-Cloud Logging.
התכונה Mapped Diagnostic Context (הקשר אבחוני ממופה, MDC) היא תכונה רגילה במסגרות רישום ב-Java, כמו SLF4J ו-Logback. הוא מאפשר לכם לשפר את הצהרות היומן באמצעות מידע הקשרי שמנוהל על בסיס כל שרשור. לדוגמה, אפשר להוסיף ליומנים מזהה עסקה, שם קובץ או מפתח ספציפי לעסק, כמו בדוגמה הבאה: "custom_data": { "transactionId": "xyz-123", "sourceFile":
"customers.csv" }.
שילוב של Dataflow עם MDC
כשמפעילים MDC בצינור Dataflow, רכיב ההפעלה של Dataflow מתעד באופן אוטומטי את הקשר של MDC בזמן שנוצרת הודעת יומן, ומעביר אותה ל-Logging. המאפיינים המותאמים אישית מופיעים במיפוי custom_data ב-jsonPayload של רשומת היומן ב-Logging. כך הם הופכים לשדות ברמה העליונה שאפשר לסנן.
דוגמה לרשומה ביומן עם נתונים מותאמים אישית מ-MDC:
{ "jsonPayload": { "custom_data": { "messageId": "232323232" }, "message": "LOG_MESSAGE", "pipelineName": "PIPELINE_NAME", [...] } }
דרישות מוקדמות
- צינור עיבוד נתונים של Dataflow באמצעות Apache Beam SDK for Java.
- ב-Dataflow Runner v1, צריך להשתמש ב-Apache Beam SDK בגרסה 2.69.0 ואילך.
- ב-Dataflow Runner v2, התכונה נתמכת כברירת מחדל.
- חזית רישום ביומן כמו SLF4J שהוגדרה בפרויקט.
הפעלה של MDC ושימוש בו
כדי להפעיל MDC, מוסיפים את אפשרות הצינור הבאה כשמפעילים את העבודה:
--logMdc=true
בדוגמת הקוד הבאה אפשר לראות איך משתמשים ב-MDC כדי להוסיף messageId ליומנים של משימת Dataflow שקוראת הודעות מ-Pub/Sub.
import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.gcp.pubsub.PubsubMessage; import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO; import org.apache.beam.sdk.options.Description; import org.apache.beam.sdk.options.PipelineOptionsFactory; import org.apache.beam.sdk.options.SdkHarnessOptions; import org.apache.beam.sdk.transforms.DoFn; import org.apache.beam.sdk.transforms.ParDo; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.slf4j.MDC; public class SimpleDataflowJobMDC { public interface SimpleDataflowJobOptions extends SdkHarnessOptions { @Description("The Pub/Sub subscription to read from.") String getInputSubscription(); void setInputSubscription(String value); } public static class MessageReaderFn extends DoFn<PubsubMessage, Void> { private transient Logger logger; @Setup public void setup() { logger = LoggerFactory.getLogger(MessageReaderFn.class); } @ProcessElement public void processElement(ProcessContext c) { PubsubMessage message = c.element(); String messageId = message.getMessageId(); try (MDC.MDCCloseable ignored = MDC.putCloseable("messageId", messageId)) { String payload = new String(message.getPayload()); logger.info("Received message with payload: " + payload); // This is the example task logger.info("Executing example task..."); } catch (Exception e) { logger.info("failure"); } } } public static void main(String[] args) { SimpleDataflowJobOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(SimpleDataflowJobOptions.class); // options.setRunner(DirectRunner.class); options.setLogMdc(true); Pipeline p = Pipeline.create(options); p.apply( "Read Messages from Pub/Sub", PubsubIO.readMessagesWithAttributes().fromSubscription(options.getInputSubscription())) .apply("Process Message", ParDo.of(new MessageReaderFn())); p.run(); } }
הפקודה mvn הבאה מראה איך להריץ את צינור העיבוד עם הארגומנט --logMdc=true:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=com.sample.SimpleDataflowJobMDC \ -Dexec.args=" \ [...] \ --logMdc=true \ [...]
שליטה בנפח היומן
אפשר גם להפחית את נפח היומנים שנוצרים על ידי שינוי רמות היומן של צינור עיבוד הנתונים. אם לא רוצים להמשיך להטמיע חלק מיומני Dataflow או את כולם, צריך להוסיף החרגה של רישום ביומן כדי להחריג יומני Dataflow. אחר כך מייצאים את היומנים ליעד אחר, כמו BigQuery, Cloud Storage או Pub/Sub. מידע נוסף זמין במאמר בנושא שליטה בהעברה של יומנים ב-Dataflow.
הגבלת קצב יצירת בקשות או ויסות של נתוני בקשות
ההודעות ביומן של העובד מוגבלות ל-15,000 הודעות בכל 30 שניות, לכל עובד. אם מגיעים למגבלה הזו, מתווספת הודעת יומן של עובד יחיד שאומרת שהרישום ביומן מוגבל:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
לא מתבצעת רישום של הודעות נוספות עד שחלפו 30 שניות. המגבלה הזו חלה על הודעות יומן שנוצרות על ידי Apache Beam SDK וקוד משתמש.
אחסון ושימור של יומנים
יומנים תפעוליים מאוחסנים בקטגוריית היומנים _Default. שם השירות של Logging API הוא dataflow.googleapis.com. מידע נוסף על סוגי המשאבים במעקב ועל השירותים שבהם נעשה שימוש ב-Cloud Logging זמין במאמר משאבים ושירותים במעקב. Google Cloud
לפרטים על משך הזמן לשמירת רשומות ביומן על ידי Logging, ראו את המידע על השמירה במאמר מכסות ומגבלות: תקופות שמירה של יומנים.
מידע על צפייה ביומנים תפעוליים מופיע במאמר מעקב אחרי יומנים של צינורות נתונים וצפייה בהם.
מעקב אחרי יומני צינורות עיבוד נתונים והצגתם
כשמריצים את צינור הנתונים בשירות Dataflow, אפשר להשתמש בממשק המעקב של Dataflow כדי לראות את היומנים שנוצרו על ידי צינור הנתונים.
דוגמה ליומן של עובד ב-Dataflow
אפשר להריץ את צינור עיבוד הנתונים WordCount ששונה בענן עם האפשרויות הבאות:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
המשך
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
צפייה ביומנים
בגלל שצינור עיבוד הנתונים של WordCount משתמש בהרצה חוסמת, הודעות המסוף מופקות במהלך ההרצה של צינור עיבוד הנתונים. אחרי שהעבודה מתחילה, קישור לדף במסוףGoogle Cloud מוצג במסוף, ואחריו מזהה העבודה של צינור הנתונים:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
כתובת ה-URL של המסוף מובילה אל ממשק המעקב של Dataflow עם דף סיכום של העבודה שנשלחה. בצד ימין מוצג תרשים דינמי של ההפעלה, ובצד שמאל מוצג סיכום של המידע. לוחצים על keyboard_capslock בחלונית התחתונה כדי להרחיב את חלונית היומנים.
כברירת מחדל, בחלונית היומנים מוצגים יומני משימות שמדווחים על הסטטוס של המשימה כמכלול. כדי לסנן את ההודעות שמופיעות בחלונית היומנים, לוחצים על מידעarrow_drop_down ואז על filter_listסינון היומנים.
בחירה בשלב של צינור העברת נתונים בתרשים משנה את התצוגה ליומני שלבים שנוצרו על ידי הקוד שלכם, והקוד שנוצר פועל בשלב של צינור העברת הנתונים.
כדי לחזור אל Job Logs, מבטלים את הבחירה בשלב על ידי לחיצה מחוץ לגרף או באמצעות הלחצן Deselect step בחלונית הצדדית השמאלית.
ניווט אל Logs Explorer
כדי לפתוח את Logs Explorer ולבחור סוגים שונים של יומנים, בחלונית היומנים לוחצים על View in Logs Explorer (הלחצן של הקישור החיצוני).
בכלי Logs Explorer, כדי לראות את החלונית עם סוגים שונים של יומנים, לוחצים על המתג Log fields (שדות יומן).
בדף Logs Explorer, יכול להיות שהשאילתה תסנן את היומנים לפי שלב במשימה או לפי סוג היומן. כדי להסיר מסננים, לוחצים על המתג הצגת השאילתה ועורכים את השאילתה.
כדי לראות את כל היומנים שזמינים לעבודה, צריך לבצע את השלבים הבאים:
בשדה Query, מזינים את השאילתה הבאה:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"מחליפים את JOB_ID במזהה המשימה.
לוחצים על Run query.
אם אתם משתמשים בשאילתה הזו ולא רואים יומנים של העבודה, לוחצים על עריכת הזמן.
משנים את שעת ההתחלה ואת שעת הסיום ולוחצים על אישור.
סוגי יומנים
כלי Logs Explorer כולל גם יומני תשתית של צינור הנתונים. להשתמש ביומני שגיאות ואזהרות כדי לאבחן בעיות בצינור עיבוד הנתונים. שגיאות ואזהרות ביומני התשתית שלא קשורות לבעיה בצינור לא בהכרח מצביעות על בעיה.
אלה סוגי היומנים השונים שאפשר לראות בדף Logs Explorer:
- יומני job-message מכילים הודעות ברמת המשימה שנוצרות על ידי רכיבים שונים של Dataflow. דוגמאות: הגדרת התאמה אוטומטית לעומס, מתי ה-workers מתחילים או מפסיקים לעבוד, ההתקדמות בשלב העבודה ושגיאות בעבודה. שגיאות ברמת העובד שמקורן בקוד משתמש שקורס, ושמופיעות ביומני העובד, מועברות גם ליומני הודעות העבודה.
- יומני worker נוצרים על ידי עובדי Dataflow. העובדים מבצעים את רוב העבודה בצינור (לדוגמה, החלת
ParDoעל נתונים). יומני Worker מכילים הודעות שנרשמו ביומן על ידי הקוד ו-Dataflow. - יומני worker-startup קיימים ברוב משימות Dataflow ויכולים לתעד הודעות שקשורות לתהליך ההפעלה. תהליך ההפעלה כולל הורדה של קובצי ה-jar של המשימה מ-Cloud Storage, ואז הפעלה של העובדים. אם יש בעיה בהפעלת העובדים, כדאי לבדוק את היומנים האלה.
- יומני harness מכילים הודעות מ-Runner v2 runner harness.
- יומני shuffler מכילים הודעות מעובדים שמבצעים איחוד של התוצאות של פעולות מקבילות בצינור.
- יומני system מכילים הודעות ממערכות ההפעלה המארחות של מכונות וירטואליות של עובדים. בתרחישים מסוימים, הם עשויים לתעד קריסות של תהליכים או אירועים של חוסר זיכרון (OOM).
- היומנים של docker ושל kubelet מכילים הודעות שקשורות לטכנולוגיות הציבוריות האלה, שמשמשות את העובדים של Dataflow.
- היומנים של nvidia-mps מכילים הודעות לגבי פעולות של NVIDIA Multi-Process Service (MPS).
הגדרת רמות יומן של עובדי צינור עיבוד הנתונים
Java
רמת הרישום ביומן ברירת המחדל של SLF4J שמוגדרת ב-workers על ידי Apache Beam SDK for Java היא
INFO. כל הודעות היומן ברמה INFO ומעלה (INFO,
WARN, ERROR) יופקו. אפשר להגדיר רמת יומן רישום שונה כברירת מחדל כדי לתמוך ברמות נמוכות יותר של רישום ביומן SLF4J (TRACE או DEBUG), או להגדיר רמות שונות של יומן רישום לחבילות שונות של מחלקות בקוד.
אלה אפשרויות הצינור שזמינות לכם כדי להגדיר את רמות היומן של העובדים משורת הפקודה או באופן פרוגרמטי:
-
--defaultSdkHarnessLogLevel=<level>: משתמשים באפשרות הזו כדי להגדיר את כל רכיבי ה-logger ברמת ברירת המחדל שצוינה. לדוגמה, אפשרות שורת הפקודה הבאה תבטל את ברירת המחדל של רמת היומןINFOב-Dataflow ותגדיר אותה ל-DEBUG:
--defaultSdkHarnessLogLevel=DEBUG -
--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: משתמשים באפשרות הזו כדי להגדיר את רמת הרישום ביומן לחבילות או למחלקות שצוינו. לדוגמה, כדי לשנות את רמת ברירת המחדל של יומן הצינור לחבילהorg.apache.beam.runners.dataflowולהגדיר אותה ל-TRACE:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
כדי לבצע כמה שינויים, צריך לספק מפת JSON:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}). - אפשרויות הצינור
defaultSdkHarnessLogLevelו-sdkHarnessLogLevelOverridesלא נתמכות בצינורות שמשתמשים בגרסאות Apache Beam SDK 2.50.0 ואילך ללא Runner v2. במקרה כזה, משתמשים באפשרויות הצינור--defaultWorkerLogLevel=<level>ו---workerLogLevelOverrides={"<package or class>":"<level>"}. כדי לבצע כמה שינויים, צריך לספק מפת JSON:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
בדוגמה הבאה, האפשרויות של רישום ביומן של צינורות מוגדרות באופן פרוגרמטי עם ערכי ברירת מחדל שאפשר לשנות משורת הפקודה:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
רמת ברירת המחדל של הרישום ביומן שמוגדרת ב-workers על ידי Apache Beam SDK for Python היא
INFO. כל הודעות היומן ברמה INFO ומעלה (INFO,
WARNING, ERROR, CRITICAL) יופקו.
אפשר להגדיר רמת ברירת מחדל שונה של יומן כדי לתמוך ברמות נמוכות יותר של יומן (DEBUG)
או להגדיר רמות שונות של יומן למודולים שונים בקוד.
יש שתי אפשרויות לפייפליין שמאפשרות להגדיר את רמות היומן של העובדים משורת הפקודה או באופן פרוגרמטי:
-
--default_sdk_harness_log_level=<level>: משתמשים באפשרות הזו כדי להגדיר את כל רכיבי ה-logger ברמת ברירת המחדל שצוינה. לדוגמה, אפשרות שורת הפקודה הבאה מבטלת את רמת ברירת המחדל של היומןINFOב-Dataflow ומגדירה אותה ל-DEBUG:
--default_sdk_harness_log_level=DEBUG -
--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: משתמשים באפשרות הזו כדי להגדיר את רמת הרישום ביומן למודולים שצוינו. לדוגמה, כדי לשנות את רמת היומן של צינור ברירת המחדל עבור המודולapache_beam.runners.dataflowולהגדיר אותה ל-DEBUG:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
כדי לבצע כמה שינויים, צריך לספק מפת JSON:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
בדוגמה הבאה השתמשנו במחלקה WorkerOptions כדי להגדיר באופן פרוגרמטי את אפשרויות רישום היומן של צינור עיבוד הנתונים, שאפשר לשנות משורת הפקודה:
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט -
JOB_NAME: השם של המשימה -
STORAGE_BUCKET: השם של Cloud Storage -
DATAFLOW_REGION: האזור שבו רוצים לפרוס את משימת Dataflowהדגל
--regionמבטל את האזור שמוגדר כברירת מחדל בשרת המטא-נתונים, בלקוח המקומי או במשתני הסביבה.
המשך
התכונה הזו לא זמינה ב-Apache Beam SDK for Go.
צפייה ביומן של משימות שהופעלו ב-BigQuery
כשמשתמשים ב-BigQuery בצינור Dataflow, מופעלים תפקידים ב-BigQuery כדי לבצע פעולות שונות בשמכם. הפעולות האלה יכולות לכלול טעינת נתונים, ייצוא נתונים ומשימות דומות אחרות. למטרות פתרון בעיות ומעקב, בממשק המעקב של Dataflow יש מידע נוסף על משימות BigQuery האלה, שזמין בחלונית Logs.
המידע על המשימות ב-BigQuery שמוצג בחלונית Logs (יומנים) מאוחסן ונטען מטבלת מערכת של BigQuery. עלות החיוב נוצרת כשמריצים שאילתה בטבלת BigQuery הבסיסית.
צפייה בפרטי המשימה ב-BigQuery
כדי לראות את פרטי העבודות ב-BigQuery, הצינור צריך להשתמש ב-Apache Beam 2.24.0 ואילך.
כדי לראות את רשימת המשימות של BigQuery, פותחים את הכרטיסייה BigQuery Jobs ובוחרים את המיקום של המשימות ב-BigQuery. לאחר מכן, לוחצים על Load BigQuery Jobs (טעינת משימות BigQuery) ומאשרים את תיבת הדו-שיח. אחרי שהשאילתה מסתיימת, מוצגת רשימת המשימות.
מוצג מידע בסיסי על כל עבודה, כולל מזהה העבודה, הסוג, משך הזמן ופרטים נוספים.
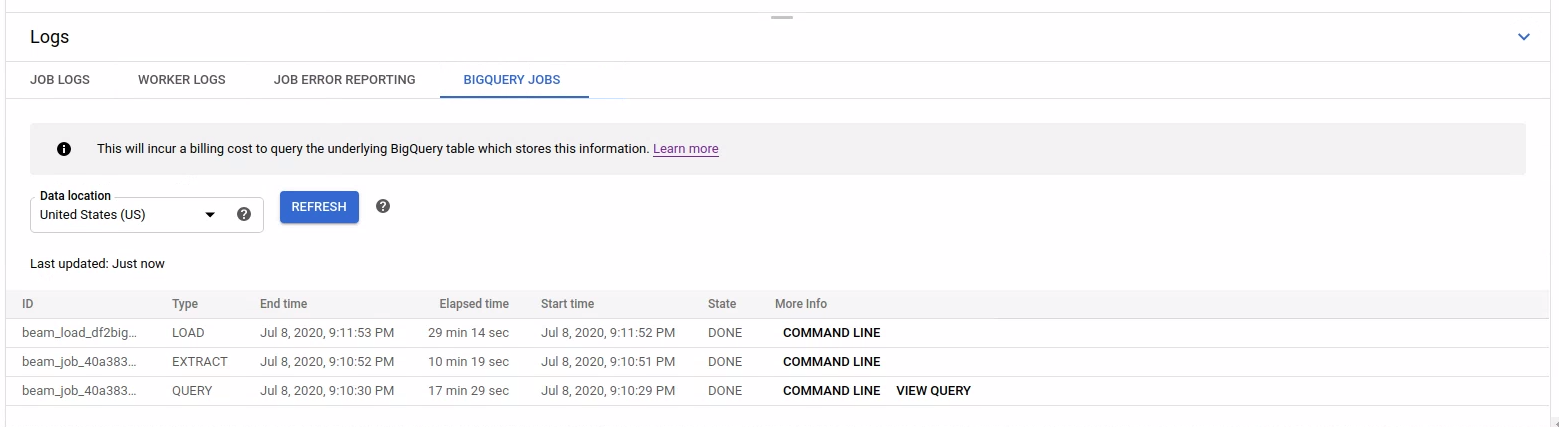
כדי לקבל מידע מפורט יותר על עבודה ספציפית, לוחצים על Command line (שורת פקודה) בעמודה More Info (מידע נוסף).
בחלון המודאלי של שורת הפקודה, מעתיקים את הפקודה bq jobs describe ומפעילים פתרונות חכמים באופן מקומי או ב-Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
הפקודה bq jobs describe מחזירה את JobStatistics, שמספק פרטים נוספים שימושיים לאבחון של עבודת BigQuery איטית או תקועה.
לחלופין, כשמשתמשים ב-BigQueryIO עם שאילתת SQL, מופעלת משימת שאילתה. כדי לראות את שאילתת ה-SQL שבה נעשה שימוש בעבודה, לוחצים על הצגת השאילתה בעמודה מידע נוסף.
צפייה באבחון
בכרטיסייה אבחון בחלונית יומנים נאספים ומוצגים רשומות יומן מסוימות שנוצרו בצינורות שלכם. הערכים האלה כוללים הודעות שמצביעות על בעיה אפשרית בצינור, והודעות שגיאה עם דוחות של קריסות. רשומות היומן שנאספו עוברות ביטול כפילויות ומשולבות בקבוצות שגיאות.
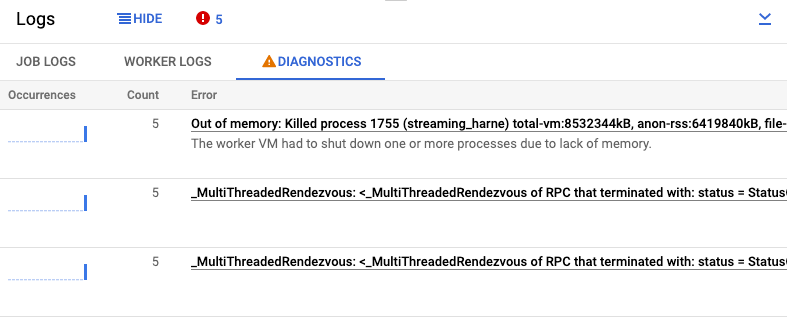
דוח השגיאות כולל את הפרטים הבאים:
- רשימת שגיאות עם הודעות שגיאה
- מספר הפעמים שכל שגיאה התרחשה
- היסטוגרמה שמציינת מתי כל שגיאה התרחשה
- המועד שבו השגיאה התרחשה לאחרונה
- השעה שבה השגיאה התרחשה בפעם הראשונה
- הסטטוס של השגיאה
כדי לראות את דוח השגיאות של שגיאה ספציפית, לוחצים על התיאור בעמודה שגיאות. מוצג הדף דיווח על שגיאות. אם השגיאה היא שגיאת שירות, מוצג קישור למדריך לפתרון בעיות.
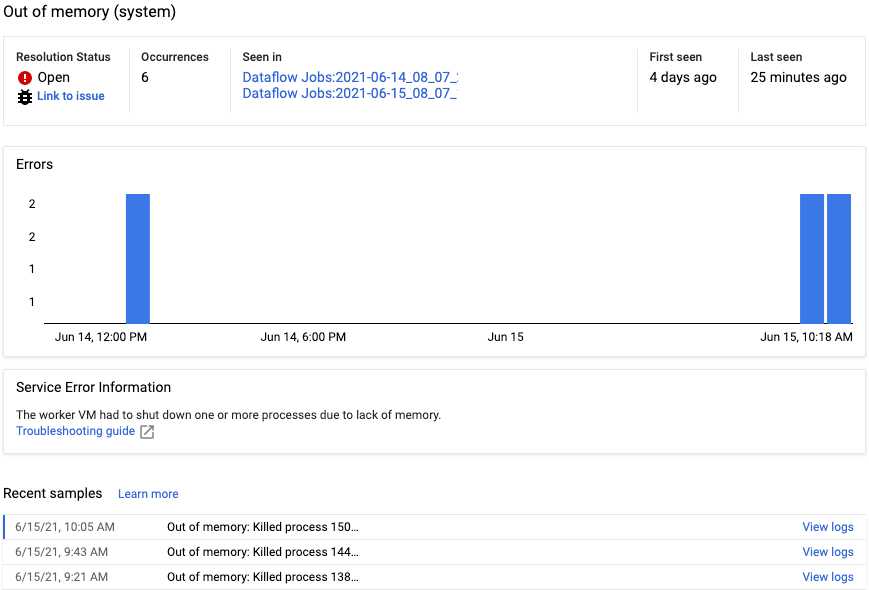
מידע נוסף על הדף זמין במאמר הצגה וסינון של שגיאות.
השתקת שגיאה
כדי להשתיק הודעת שגיאה:
- פותחים את הכרטיסייה אבחון.
- לוחצים על השגיאה שרוצים להשתיק.
- פותחים את התפריט של סטטוס הפתרון. הסטטוסים מסומנים בתוויות הבאות: פתוח, אושר, נפתר או הושתק.
- לוחצים על השתקה.
שימוש בספק רישום ביומן אחר של SLF4J
כברירת מחדל, ה-SDK של Apache Beam ל-Java משתמש ב-java.util.logging כספק הרישום של SLF4J. כשצינור מתחיל, Dataflow מוסיף באופן אוטומטי את קובצי ה-JAR הדרושים לנתיב המחלקה של Java כדי להגדיר את סביבת הרישום הזו.
כדי להשתמש בספק אחר של רישום ביומן SLF4J, כמו Reload4J או Logback, צריך למנוע את הוספת קובצי ה-JAR שמוגדרים כברירת מחדל לנתיב המחלקה, כי SLF4J תומך רק בספק אחד של רישום ביומן בזמן הריצה. מוסיפים את הניסוי הבא לאפשרויות של צינור העיבוד:
--experiments=use_custom_logging_libraries. האפשרות הזו זמינה רק בצינורות (pipelines) שמשתמשים ב-Runner V2 מאז Apache Beam SDK 2.63.0.
כשמפעילים את הניסוי הזה, אפשר לארוז את ספק הרישום המועדף של SLF4J עם קובצי ה-JAR של צינור הנתונים.