
אם נתקלתם בבעיות בצינור או במשימה של Dataflow, בדף הזה מפורטות הודעות שגיאה שאתם עשויים לראות, ומוצעים פתרונות לכל שגיאה.
שגיאות בסוגי היומן dataflow.googleapis.com/worker-startup,
dataflow.googleapis.com/harness-startup ו-dataflow.googleapis.com/kubelet
מעידות על בעיות בהגדרת עבודה. הם יכולים גם להצביע על תנאים שמונעים את הפעולה של נתיב הרישום הרגיל.
יכול להיות שצינור הנתונים יזרוק חריגים במהלך עיבוד הנתונים. חלק מהשגיאות האלה הן זמניות, למשל כשקשה לגשת לשירות חיצוני באופן זמני. חלק מהשגיאות האלה הן קבועות, למשל שגיאות שנגרמות בגלל נתוני קלט פגומים או כאלה שלא ניתן לנתח, או בגלל מצביעים ריקים במהלך החישוב.
Dataflow מעבד רכיבים בחבילות שרירותיות ומנסה שוב לעבד את החבילה כולה אם מתקבלת שגיאה לגבי רכיב כלשהו בחבילה. כשמריצים במצב אצווה, המערכת מנסה שוב ארבע פעמים חבילות שכוללות פריט שנכשל. הצינור נכשל לחלוטין אם חבילה אחת נכשלת ארבע פעמים. כשמפעילים את הצינור במצב סטרימינג, המערכת מנסה שוב ושוב להפעיל חבילה שכוללת פריט שנכשל, מה שעלול לגרום לעצירה קבועה של הצינור.
חריגים בקוד המשתמש, למשל מופעי DoFn, מדווחים בממשק המעקב של Dataflow. אם מריצים את צינור הנתונים באמצעות BlockingDataflowPipelineRunner, הודעות השגיאה מודפסות גם במסוף או בחלון הטרמינל.
כדאי להוסיף לטיפול בשגיאות בקוד מטפלים בחריגים. לדוגמה, אם רוצים להשמיט רכיבים שלא עוברים אימות קלט מותאם אישית שמתבצע ב-ParDo, אפשר להשתמש בבלוק try/catch בתוך ParDo כדי לטפל בחריגה, לרשום אותה ביומן ולהשמיט את הרכיב. בעומסי עבודה של ייצור, כדאי להטמיע דפוס של הודעות לא מעובדות. כדי לעקוב אחרי מספר השגיאות, משתמשים בטרנספורמציות של צבירה.
חסרים קובצי יומן
אם לא מופיעים יומנים של המשרות, צריך להסיר את כל מסנני ההחרגה שמכילים את resource.type="dataflow_step" מכל יעד של Log Router ב-Cloud Logging.
לפרטים נוספים על הסרת החרגות מהיומנים, אפשר לעיין במדריך בנושא הסרת החרגות.
כפילויות בפלט
כשמריצים משימה ב-Dataflow, הפלט מכיל רשומות כפולות.
הבעיה הזו יכולה להתרחש כשעבודת Dataflow משתמשת במצב הסטרימינג של צינור הנתונים at-least-once. במצב הזה, המערכת מבטיחה שהרשומות יעברו עיבוד לפחות פעם אחת. עם זאת, יכול להיות שיהיו רשומות כפולות במצב הזה.
אם תהליך העבודה שלכם לא יכול להכיל רשומות כפולות, צריך להשתמש במצב סטרימינג של בדיוק פעם אחת. המצב הזה עוזר לוודא שהרשומות לא יימחקו או ישוכפלו בזמן שהנתונים עוברים דרך צינור הנתונים.
כדי לבדוק באיזה מצב סטרימינג נעשה שימוש בעבודה, אפשר לעיין במאמר בנושא הצגת מצב הסטרימינג של עבודה.
מידע נוסף על מצבי סטרימינג זמין במאמר בנושא הגדרת מצב הסטרימינג של צינור הנתונים.
שגיאות בצינור עיבוד הנתונים
בסעיפים הבאים מפורטות שגיאות נפוצות בצינורות להעברת נתונים שבהן אתם עשויים להיתקל, וגם שלבים לפתרון בעיות שקשורות לשגיאות האלה.
צריך להפעיל חלק מממשקי ה-API של Cloud
כשמנסים להריץ עבודת Dataflow, מופיעה השגיאה הבאה:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
הבעיה הזו מתרחשת כי חלק מממשקי ה-API הנדרשים לא מופעלים בפרויקט.
כדי לפתור את הבעיה ולהריץ עבודת Dataflow, צריך להפעיל את ממשקי ה-API הבאים בפרויקט:Google Cloud
- Compute Engine API (Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
הוראות מפורטות מופיעות בקטע תחילת העבודה בנושא הפעלת ממשקיGoogle Cloud API .
"@*" ו-"@N" הם מפרטי חלוקה למקטעים שמורים
כשמנסים להריץ עבודה, השגיאה הבאה מופיעה בקובצי היומן, והעבודה נכשלת:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
השגיאה הזו מתרחשת אם בשם הקובץ של הנתיב ב-Cloud Storage לקבצים זמניים (tempLocation או temp_location) מופיע הסימן @ ואחריו מספר או כוכבית (*).
כדי לפתור את הבעיה, צריך לשנות את שם הקובץ כך שאחרי התו @ יופיע תו נתמך.
בקשה פגומה
כשמריצים משימה ב-Dataflow, ביומני Cloud Monitoring מוצגת סדרה של אזהרות שדומות לאלה:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
אזהרות על בקשה לא תקינה מופיעות אם פרטי מצב העובד לא עדכניים או לא מסונכרנים בגלל עיכובים בעיבוד. לרוב, עבודת Dataflow מצליחה למרות אזהרות הבקשה השגויה. במקרה כזה, אפשר להתעלם מהאזהרות.
אי אפשר לקרוא ולכתוב במיקומים שונים
כשמריצים משימת Dataflow, יכול להיות שתופיע השגיאה הבאה בקובצי היומן:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
השגיאה הזו מתרחשת כשהמקור והיעד נמצאים באזורים שונים. זה יכול לקרות גם אם מיקום האחסון הזמני והיעד נמצאים באזורים שונים. לדוגמה, אם המשימה קוראת מ-Pub/Sub ואז כותבת לקטגוריה של Cloud Storage temp לפני הכתיבה לטבלה ב-BigQuery, הקטגוריה של Cloud Storage temp והטבלה ב-BigQuery צריכות להיות באותו אזור.
מיקומים מרובי-אזורים נחשבים שונים ממיקומים חד-אזוריים, גם אם האזור היחיד נמצא בתחום של המיקום מרובה-האזורים.
לדוגמה, us (multiple regions in the United States) ו-us-central1 הם אזורים שונים.
כדי לפתור את הבעיה, צריך לוודא שהיעד, המקור והמיקומים של אזור הביניים נמצאים באותו אזור. אי אפשר לשנות את המיקומים של קטגוריות של Cloud Storage, ולכן יכול להיות שתצטרכו ליצור קטגוריה חדשה של Cloud Storage באזור הנכון.
תם הזמן הקצוב לתפוגה של החיבור
כשמריצים משימת Dataflow, יכול להיות שתופיע השגיאה הבאה בקובצי היומן:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
הבעיה הזו מתרחשת כשעובדי Dataflow לא מצליחים ליצור או לשמור על חיבור למקור הנתונים או ליעד.
כדי לפתור את הבעיה, צריך לבצע את השלבים הבאים:
- מוודאים שמקור הנתונים פועל.
- מוודאים שהיעד פועל.
- בודקים את פרמטרי החיבור שמשמשים בהגדרת צינור עיבוד הנתונים ב-Dataflow.
- מוודאים שבעיות בביצועים לא משפיעות על המקור או על היעד.
- מוודאים שכללי חומת האש לא חוסמים את החיבור.
אין אובייקט כזה
כשמריצים משימות Dataflow, יכול להיות שתופיע השגיאה הבאה בקובצי היומן:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
השגיאות האלה מתרחשות בדרך כלל כשחלק מעבודות Dataflow שפועלות משתמשות באותו temp_location כדי לאחסן זמנית קבצים של עבודות שנוצרו בזמן הפעלת צינור הנתונים. כשכמה משימות מקבילות חולקות את אותו temp_location, יכול להיות שהמשימות האלה ידרסו את הנתונים הזמניים אחת של השנייה, ויתרחש מרוץ תהליכים. כדי למנוע את הבעיה הזו, מומלץ להשתמש ב-temp_location ייחודי לכל משימה.
Dataflow לא יכול לקבוע את ה-backlog
כשמריצים צינור עיבוד נתונים בסטרימינג מ-Pub/Sub, מוצגת האזהרה הבאה:
Dataflow is unable to determine the backlog for Pub/Sub subscription
כשצינור עיבוד נתונים של Dataflow שולף נתונים מ-Pub/Sub, Dataflow צריך לבקש מידע מ-Pub/Sub שוב ושוב. המידע הזה כולל את כמות הגיבויים בהרשמה ואת הגיל של ההודעה הכי ישנה שלא אושרה. לפעמים, ל-Dataflow אין אפשרות לאחזר את המידע הזה מ-Pub/Sub בגלל בעיות פנימיות במערכת, שיכולות לגרום להצטברות זמנית של עומס עבודה.
מידע נוסף זמין במאמר בנושא סטרימינג באמצעות Cloud Pub/Sub.
DEADLINE_EXCEEDED או שהשרת לא מגיב
כשמריצים את העבודות, יכול להיות שתיתקלו בחריגות של פסק זמן של RPC או באחת מהשגיאות הבאות:
DEADLINE_EXCEEDED
או:
Server Unresponsive
השגיאות האלה מתרחשות בדרך כלל בגלל אחת מהסיבות הבאות:
יכול להיות שחסר כלל חומת אש ברשת של הענן הווירטואלי הפרטי (VPC) שבה נעשה שימוש בעבודה. כלל חומת האש צריך לאפשר את כל תעבורת ה-TCP בין מכונות וירטואליות ברשת ה-VPC שציינתם באפשרויות הצינור. מידע נוסף על כללים של חומת אש ב-Dataflow
במקרים מסוימים, העובדים לא יכולים לתקשר ביניהם. כשמריצים עבודת Dataflow שלא משתמשת ב-Dataflow Shuffle או ב-Streaming Engine, העובדים צריכים לתקשר אחד עם השני באמצעות יציאות TCP
12345ו-12346ברשת ה-VPC. בתרחיש הזה, השגיאה כוללת את שם ה-worker harness ואת יציאת ה-TCP שחסומה. השגיאה תיראה כמו אחת מהדוגמאות הבאות:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)כדי לפתור את הבעיה, צריך להשתמש בדגל
gcloud compute firewall-rules createrules כדי לאפשר תעבורת רשת ליציאות12345ו-12346. בדוגמה הבאה מוצגת הפקודה של Google Cloud CLI:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346מחליפים את מה שכתוב בשדות הבאים:
-
FIREWALL_RULE_NAME: השם של כלל חומת האש -
NETWORK: השם של הרשת
-
העבודה שלך מוגבלת לערבוב.
כדי לפתור את הבעיה, מבצעים שינוי אחד או יותר מהשינויים הבאים.
Java
- אם העבודה לא משתמשת בערבוב מבוסס-שירות, צריך לעבור לשימוש בארגון נתונים של Dataflow מבוסס-שירות על ידי הגדרת
--experiments=shuffle_mode=service. לפרטים נוספים ולמידע על הזמינות, אפשר לעיין במאמר בנושא ארגון נתונים של Dataflow. - הוספת עובדים נסו להגדיר את
--numWorkersעם ערך גבוה יותר כשמריצים את צינור העיבוד. - הגדלת הגודל של הדיסק המצורף לעובדים. אפשר לנסות להגדיר את
--diskSizeGbעם ערך גבוה יותר כשמריצים את צינור הנתונים. - שימוש בדיסק מתמיד שמבוסס על SSD. אפשר לנסות להגדיר את הערך של
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"כשמריצים את צינור הנתונים.
Python
- אם העבודה לא משתמשת בערבוב מבוסס-שירות, צריך לעבור לשימוש בארגון נתונים של Dataflow מבוסס-שירות על ידי הגדרת
--experiments=shuffle_mode=service. לפרטים נוספים ולמידע על הזמינות, אפשר לעיין במאמר בנושא ארגון נתונים של Dataflow. - הוספת עובדים נסו להגדיר את
--num_workersעם ערך גבוה יותר כשמריצים את צינור העיבוד. - הגדלת הגודל של הדיסק המצורף לעובדים. אפשר לנסות להגדיר את
--disk_size_gbעם ערך גבוה יותר כשמריצים את צינור הנתונים. - שימוש בדיסק מתמיד שמבוסס על SSD. אפשר לנסות להגדיר את הערך של
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"כשמריצים את צינור הנתונים.
המשך
- אם העבודה לא משתמשת בערבוב מבוסס-שירות, צריך לעבור לשימוש בארגון נתונים של Dataflow מבוסס-שירות על ידי הגדרת
--experiments=shuffle_mode=service. לפרטים נוספים ולמידע על הזמינות, אפשר לעיין במאמר בנושא ארגון נתונים של Dataflow. - הוספת עובדים נסו להגדיר את
--num_workersעם ערך גבוה יותר כשמריצים את צינור העיבוד. - הגדלת הגודל של הדיסק המצורף לעובדים. אפשר לנסות להגדיר את
--disk_size_gbעם ערך גבוה יותר כשמריצים את צינור הנתונים. - שימוש בדיסק מתמיד שמבוסס על SSD. אפשר לנסות להגדיר את הערך של
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"כשמריצים את צינור הנתונים.
- אם העבודה לא משתמשת בערבוב מבוסס-שירות, צריך לעבור לשימוש בארגון נתונים של Dataflow מבוסס-שירות על ידי הגדרת
הוחזר פיצול ריק
כשמריצים משימה ב-Dataflow, יכולה להופיע ההודעה הבאה ביומני העובדים:
Continuing to process work-id WORK_ID without splitting. Reader split status was: INTERNAL: Empty split returned and SDK split status was: ...
אם העבודה פועלת בצורה תקינה, ההודעה הזו לא מזיקה ואפשר להתעלם ממנה. ההודעה הזו יכולה להופיע בגלל מרוץ תהליכים שבו השירות מנסה לפצל עבודה שכבר הושלמה.
שגיאות קידוד, IOExceptions או התנהגות לא צפויה בקוד המשתמש
ערכות ה-SDK של Apache Beam והתהליכים של Dataflow מסתמכים על רכיבים נפוצים של צד שלישי. הרכיבים האלה מייבאים תלות נוספת. התנגשויות בין גרסאות עלולות לגרום להתנהגות לא צפויה בשירות. בנוסף, חלק מהספריות לא תואמות קדימה. יכול להיות שתצטרכו להצמיד לגרסאות שמופיעות ברשימה ושנכללות בהיקף במהלך ההפעלה. SDK and Worker Dependencies מכיל רשימה של יחסי תלות והגרסאות הנדרשות שלהם.
סוג המכונה דורש סוג דיסק Hyperdisk Balanced
כשמנסים להריץ עבודת Dataflow, מופיעה השגיאה הבאה:
MACHINE_TYPE machine types require the Hyperdisk Balanced disk type.
הבעיה הזו מתרחשת כשמשתמשים בסוג מכונה שדורש דיסקים מסוג Hyperdisk Balanced, כמו C4A או N4, אבל מציינים סוג דיסק לא תואם, כמו pd-standard.
כדי לפתור את הבעיה, אם אתם משתמשים בסוג מכונה שנדרשים בו דיסקים מאוזנים של Hyperdisk, אל תציינו את אפשרות הצינור workerDiskType (worker_disk_type ל-Python, disk_type ל-Go) או תגדירו אותה ל-hyperdisk-balanced.
שגיאה בהפעלת LookupEffectiveGuestPolicies
כשמריצים משימת Dataflow, יכול להיות שתופיע השגיאה הבאה בקובצי היומן:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
השגיאה הזו מתרחשת אם האפשרות ניהול הגדרות מערכת ההפעלה מופעלת עבור כל הפרויקט.
כדי לפתור את הבעיה, צריך להשבית את המדיניות של VM Manager שחלה על הפרויקט כולו. אם אי אפשר להשבית את מדיניות VM Manager לכל הפרויקט, אפשר להתעלם מהשגיאה הזו ולסנן אותה מכלי מעקב אחר יומנים.
ההגבלה על גישה לפי כתובת IP חיצונית הופרה
כשמריצים או משכפלים משימת Dataflow, מופיעה השגיאה הבאה:
Constraint constraints/compute.vmExternalIpAccess violated for project PROJECT_ID.
השגיאה הזו מתרחשת כשהגבלת מדיניות הארגון אוסרת על מכונות וירטואליות להשתמש בכתובות IP חיצוניות, אבל עבודת Dataflow מוגדרת לשימוש בכתובות IP חיצוניות.
כדי לפתור את הבעיה, צריך להגדיר במפורש את העבודה כך שתשתמש רק בכתובות IP פנימיות:
- במסוף Google Cloud : ברשימה Worker IP Address Configuration בוחרים באפשרות Private.
- שימוש ב-SDK: מגדירים את
--usePublicIps=falsepipeline option.
מידע נוסף זמין במאמר בנושא השבתה של כתובות IP חיצוניות.
זוהתה שגיאה קריטית בסביבת זמן הריצה של Java
השגיאה הבאה מתרחשת במהלך הפעלת העובד:
A fatal error has been detected by the Java Runtime Environment
השגיאה הזו מתרחשת אם צינור הנתונים משתמש ב-Java Native Interface (JNI) כדי להריץ קוד שאינו קוד Java, והקוד הזה או הקישורים של JNI מכילים שגיאה.
שגיאה במפתח המאפיין googclient_deliveryattempt
משימת Dataflow נכשלת עם אחת מהשגיאות הבאות:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
או:
Invalid extensions name: googclient_deliveryattempt
השגיאה הזו מתרחשת כשעבודת Dataflow כוללת את המאפיינים הבאים:
- העבודה של Dataflow משתמשת במנוע סטרימינג.
- לצינור יש יעד Pub/Sub.
- צינור עיבוד הנתונים משתמש במינוי שליפה.
- צינור עיבוד הנתונים משתמש באחד מממשקי Pub/Sub service API כדי לפרסם הודעות, במקום להשתמש ב-Pub/Sub I/O sink המובנה.
- משתמשים ב-Pub/Sub בספריית הלקוח של Java או C# .
- למינוי Pub/Sub יש נושא של הודעות שלא נמסרו.
השגיאה הזו מתרחשת כי כשמשתמשים בספריית הלקוח Pub/Sub Java או C# ונושא להודעות ללא מוצא למינוי מופעל, ניסיונות המסירה נמצאים במאפיין ההודעה googclient_deliveryattempt במקום בשדה delivery_attempt. מידע נוסף זמין במאמר מעקב אחרי ניסיונות מסירה בדף בנושא טיפול בכשלים בהודעות.
כדי לעקוף את הבעיה, מבצעים שינוי אחד או יותר מהשינויים הבאים.
- השבתה של Streaming Engine
- במקום Pub/Sub service API, כדאי להשתמש במחבר
PubSubIOApache Beam המובנה. - להשתמש בסוג אחר של מינוי Pub/Sub.
- הסרת נושא של הודעות שלא ניתן להעביר
- אל תשתמשו בספריית הלקוח של Java או C# עם מינוי Pub/Sub pull. אפשרויות נוספות מופיעות במאמר דוגמאות קוד של ספריות לקוח.
- בקטע הקוד של צינור העיבוד, אם מפתחות המאפיינים מתחילים ב-
goog, צריך למחוק את מאפייני ההודעה לפני שמפרסמים את ההודעות.
זוהה מקש קיצור ...
השגיאה הבאה מתרחשת:
A hot key HOT_KEY_NAME was detected in...
השגיאות האלה מתרחשות אם הנתונים מכילים מקש קיצור. מילת מפתח חמה היא מילת מפתח עם מספיק רכיבים כדי להשפיע לרעה על ביצועי הצינור. המפתחות האלה מגבילים את היכולת של Dataflow לעבד רכיבים במקביל, מה שמאריך את זמן הביצוע.
כדי להדפיס את המפתח שניתן לקריאה על ידי בני אדם ביומנים כשמזוהה מקש קיצור בצינור, משתמשים באפשרות hot key pipeline.
כדי לפתור את הבעיה, צריך לוודא שהנתונים מפוזרים באופן שווה. אם למפתח יש מספר לא פרופורציונלי של ערכים, כדאי לבצע את הפעולות הבאות:
- הצפנה מחדש של הנתונים. מחילים טרנספורמציה
ParDoכדי ליצור צמדי מפתח/ערך חדשים. - במשימות Java, משתמשים בטרנספורמציה
Combine.PerKey.withHotKeyFanout. - במשימות Python, משתמשים בטרנספורמציה
CombinePerKey.with_hot_key_fanout. - מפעילים את האפשרות ארגון נתונים של Dataflow.
כדי לראות את מקשי הקיצור בממשק המעקב של Dataflow, אפשר לעיין במאמר בנושא פתרון בעיות של משימות ארוכות במשימות אצווה.
מפרט טבלה לא תקין בקטלוג הנתונים
כשמשתמשים ב-Dataflow SQL כדי ליצור משימות Dataflow SQL, יכול להיות שהמשימה תיכשל עם השגיאה הבאה בקובצי היומן:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
השגיאה הזו מתרחשת אם לחשבון השירות של Dataflow אין גישה ל-Data Catalog API.
כדי לפתור את הבעיה, צריך להפעיל את Data Catalog API ב Google Cloud פרויקט שבו אתם משתמשים כדי לכתוב ולהריץ שאילתות.
אפשרות אחרת היא להקצות את התפקיד roles/datacatalog.viewer ל
חשבון השירות של Dataflow.
הגרף של העבודה גדול מדי
יכול להיות שהעבודה תיכשל ותוצג השגיאה הבאה:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
השגיאה הזו מתרחשת אם גודל הגרף של העבודה חורג מ-10 MB. תנאים מסוימים בצינור העיבוד יכולים לגרום לגרף המשימות לחרוג מהמגבלה. דוגמאות לתנאים נפוצים:
- טרנספורמציה
Createשכוללת כמות גדולה של נתונים בזיכרון. - מכונת
DoFnגדולה שעוברת סריאליזציה כדי לשלוח אותה לעובדים מרוחקים. -
DoFnכמופע של מחלקה פנימית אנונימית ש (אולי בטעות) שולפת כמות גדולה של נתונים כדי לבצע סריאליזציה. - נעשה שימוש בגרף אציקלי מכוון (DAG) כחלק מלולאה פרוגרמטית שמבצעת ספירה של רשימה גדולה.
כדי להימנע מהמצבים האלה, כדאי לשקול לשנות את המבנה של צינור הנתונים.
התחייבות המפתח גדולה מדי
כשמריצים משימת סטרימינג, השגיאה הבאה מופיעה בקובצי היומן של העובד:
KeyCommitTooLargeException
השגיאה הזו מתרחשת בתרחישי סטרימינג אם מקבצים כמות גדולה מאוד של נתונים בלי להשתמש בטרנספורמציה Combine, או אם כמות גדולה של נתונים נוצרת מרכיב קלט יחיד.
כדי להקטין את הסיכוי להיתקל בשגיאה הזו, אפשר להשתמש באסטרטגיות הבאות:
- חשוב לוודא שעיבוד של רכיב יחיד לא יוביל לפלט או לשינויים במצב שיחרגו מהמגבלה.
- אם כמה רכיבים קובצו לפי מפתח, כדאי להגדיל את מרחב המפתחות כדי לצמצם את מספר הרכיבים שמקובצים לפי מפתח.
- אם פולטים אלמנטים של מפתח בתדירות גבוהה במשך זמן קצר, יכול להיות שיתקבלו הרבה גיגה-בייט של אירועים עבור המפתח הזה בחלונות. לשכתב את צינור העיבוד כדי לזהות מפתחות כאלה ולהפיק פלט רק אם המפתח הופיע לעיתים קרובות בחלון הזה.
- משתמשים בהמרות של מרחב תת-לינארי
Combineלפעולות קומוטטיביות ואסוציאטיביות. אל תשתמשו במחבר אם הוא לא חוסך מקום. לדוגמה, שילוב מחרוזות על ידי הוספה שלהן אחת לשנייה הוא פחות טוב מאשר לא להשתמש בשילוב מחרוזות בכלל.
דחיית הודעה מעל 7,168K
כשמריצים משימת Dataflow שנוצרה מתבנית, יכול להיות שהמשימה תיכשל עם השגיאה הבאה:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
השגיאה הזו מתרחשת כשההודעות שנכתבות לתור של הודעות שלא נמסרו חורגות ממגבלת הגודל של 7,168 K. כפתרון עקיף, אפשר להפעיל את Streaming Engine, שבו מגבלת הגודל גבוהה יותר. כדי להפעיל את Streaming Engine, משתמשים באפשרות הצינור הבאה.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
גוף הבקשה גדול מדי
כששולחים את העבודה, אחת מהשגיאות הבאות מופיעה במסוף או בחלון הטרמינל:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
אם נתקלתם בשגיאה לגבי מטען ה-JSON כששלחתם את העבודה, סימן שהייצוג ב-JSON של צינור העיבוד חורג מהגודל המקסימלי של הבקשה, שהוא 20 MB.
הגודל של העבודה קשור לייצוג ה-JSON של צינור העיבוד. צינור גדול יותר מציין בקשה גדולה יותר. יש מגבלה ב-Dataflow שמגבילה את הבקשות ל-20 MB.
כדי להעריך את הגודל של בקשת ה-JSON של צינור הנתונים, מריצים את צינור הנתונים עם האפשרות הבאה:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
המשך
אין תמיכה בהוצאת הפלט של העבודה כ-JSON ב-Go.
הפקודה הזו כותבת ייצוג JSON של העבודה לקובץ. גודל הקובץ שעבר סריאליזציה הוא אומדן טוב לגודל הבקשה. הגודל בפועל גדול יותר בגלל מידע נוסף שנכלל בבקשה.
תנאים מסוימים בצינור העברת הנתונים יכולים לגרום לייצוג ה-JSON לחרוג מהמגבלה. דוגמאות לתנאים נפוצים:
- טרנספורמציה
Createשכוללת כמות גדולה של נתונים בזיכרון. - מכונת
DoFnגדולה שעוברת סריאליזציה כדי לשלוח אותה לעובדים מרוחקים. -
DoFnכמופע של מחלקה פנימית אנונימית ש (אולי בטעות) שולפת כמות גדולה של נתונים כדי לבצע סריאליזציה.
כדי להימנע מהמצבים האלה, כדאי לשקול לשנות את המבנה של צינור הנתונים.
אפשרויות צינור ה-SDK או רשימת הקבצים להעברה חורגות ממגבלת הגודל
כשמריצים צינור, מתרחשת אחת מהשגיאות הבאות:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
או:
Value for field 'resource.properties.metadata' is too large: maximum size
השגיאות האלה מתרחשות אם לא ניתן להפעיל את צינור הנתונים בגלל חריגה ממגבלות המטא-נתונים של Compute Engine. אי אפשר לשנות את המגבלות האלה. Dataflow משתמש במטא-נתונים של Compute Engine לאפשרויות של צינורות עיבוד נתונים. המגבלה מתועדת במגבלות של מטא-נתונים מותאמים אישית ב-Compute Engine.
התרחישים הבאים יכולים לגרום לכך שהייצוג של ה-JSON יחרוג מהמגבלה:
- יש יותר מדי קובצי JAR להעברה.
- השדה
sdkPipelineOptionsבבקשה גדול מדי.
כדי להעריך את הגודל של בקשת ה-JSON של צינור הנתונים, מריצים את צינור הנתונים עם האפשרות הבאה:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
המשך
אין תמיכה בהוצאת הפלט של העבודה כ-JSON ב-Go.
גודל קובץ הפלט של הפקודה הזו צריך להיות קטן מ-256 KB. הגודל של 512 KB בהודעת השגיאה מתייחס לגודל הכולל של קובץ הפלט ולאפשרויות המטא-נתונים המותאמים אישית של מכונת ה-VM ב-Compute Engine.
אתם יכולים לקבל אומדן גס של האפשרות של מטא-נתונים מותאמים אישית למכונה וירטואלית מהפעלת משימות Dataflow בפרויקט. בוחרים משימת Dataflow פעילה. בוחרים מכונת VM ועוברים לדף הפרטים שלה ב-Compute Engine כדי לבדוק אם יש קטע של מטא-נתונים מותאמים אישית. האורך הכולל של המטא-נתונים המותאמים אישית והקובץ צריך להיות קטן מ-512 KB. אי אפשר לתת הערכה מדויקת לגבי העבודה שנכשלה, כי המכונות הווירטואליות לא מופעלות עבור עבודות שנכשלו.
אם רשימת ה-JAR שלכם מתקרבת למגבלה של 256KB, כדאי לבדוק אותה ולהסיר קובצי JAR מיותרים. אם הוא עדיין גדול מדי, נסו להריץ את משימת Dataflow באמצעות קובץ uber JAR. דוגמה שמראה איך ליצור ולהשתמש ב-uber JAR מופיעה במאמר Build and deploy an Uber JAR.
אם השדה sdkPipelineOptions בבקשה גדול מדי, צריך לכלול את האפשרות הבאה כשמפעילים את צינור העיבוד. אפשרות הצינור זהה ל-Java, Python ו-Go.
--experiments=no_display_data_on_gce_metadata
מפתח הערבוב גדול מדי
השגיאה הבאה מופיעה בקובצי היומן של העובד:
Shuffle key too large
השגיאה הזו מתרחשת אם המפתח שעבר סריאליזציה שמועבר ל-GroupByKey מסוים גדול מדי אחרי שמחילים עליו את הקידוד המתאים. ל-Dataflow יש מגבלה על מפתחות ערבול (shuffle) שעברו סריאליזציה.
כדי לפתור את הבעיה, צריך להקטין את הגודל של המפתחות או להשתמש בשיטות קידוד יעילות יותר.
מידע נוסף זמין במאמר בנושא מגבלות ייצור ב-Dataflow.
שמירה במטמון של קלט לא פעיל בחלון גלובלי
כשמריצים צינור נתונים של סטרימינג באמצעות Apache Beam SDK ל-Python, יכול להיות שיהיו עיכובים בלתי צפויים בעדכונים של side inputs בחלון הגלובלי. יכול להיות שעובדים ישמרו ערכים ישנים של קלט צדדי לתקופות ארוכות, במיוחד כשמעבדים נתונים רציפים של קלט ראשי. הבעיה הזו משפיעה בדרך כלל על צינורות (pipelines) שמשתמשים ב-Pub/Sub כקלט ראשי וגם כקלט צדדי.
כדי לפתור את הבעיה, אם אתם משתמשים ב-Apache Beam SDK בגרסה 2.56.0 ואילך, צריך להפעיל את דגל הניסוי disable_global_windowed_args_caching:
--experiments=disable_global_windowed_args_caching
המספר הכולל של אובייקטים מסוג BoundedSource ... גדול מהמגבלה המותרת
יכול להיות שתיתקלו באחת מהשגיאות הבאות כשמריצים משימות באמצעות Java:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
או:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
השגיאה הזו עשויה להתרחש אם קוראים מספר גדול מאוד של קבצים באמצעות TextIO, AvroIO, BigQueryIO דרך EXPORT, או מקור אחר שמבוסס על קבצים. המגבלה הספציפית תלויה בפרטים של המקור, אבל היא בסדר גודל של עשרות אלפי קבצים בצינור אחד. לדוגמה, הטמעת סכימה ב-AvroIO.Read מאפשרת להשתמש בפחות קבצים.
השגיאה הזו עשויה להתרחש גם אם יצרתם מקור נתונים בהתאמה אישית לצינור העיבוד, והשיטה של המקור החזירה רשימה של אובייקטים של BoundedSourcesplitIntoBundles שתופסת יותר מ-20 MB כשמבצעים סריאליזציה.
המגבלה המותרת לגודל הכולל של אובייקטים BoundedSource שנוצרו על ידי פעולת splitIntoBundles() של המקור המותאם אישית היא 20 MB.
כדי לעקוף את ההגבלה הזו, אפשר לבצע אחד מהשינויים הבאים:
מפעילים את Runner V2. Runner v2 ממיר מקורות ל-DoFn שניתן לפצל ולא חלה עליהם מגבלת הפיצול הזו.
צריך לשנות את מחלקת המשנה המותאמת אישית
BoundedSourceכך שהגודל הכולל של אובייקטיBoundedSourceשנוצרו יהיה קטן מהמגבלה של 20MB. לדוגמה, יכול להיות שהמקור שלכם ייצור בהתחלה פחות פיצולים, ויסתמך על חלוקה דינמית מחדש של עומס העבודה כדי לפצל עוד יותר את הקלט לפי דרישה.
גודל המטען הייעודי (payload) של הבקשה חורג מהמגבלה: 20,971,520 בייטים
כשמריצים צינור, יכול להיות שהמשימה תיכשל עם השגיאה הבאה:
com.google.api.client.googleapis.json.GoogleJsonResponseException: 400 Bad Request
POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/workItems:reportStatus
{
"code": 400,
"errors": [
{
"domain": "global",
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"reason": "badRequest"
}
],
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"status": "INVALID_ARGUMENT"
}
השגיאה הזו יכולה להתרחש כשמריצים עבודה באמצעות Dataflow runner ויש גרף עבודה גדול מאוד. גרף גדול של עבודות יכול ליצור מספר גדול של מדדים שצריך לדווח עליהם בחזרה לשירות Dataflow. אם הגודל של המדדים האלה חורג ממגבלת הבקשה של 20 MB ב-API, העבודה נכשלת.
כדי לפתור את הבעיה, צריך להעביר את צינור עיבוד הנתונים לשימוש ב-Dataflow Runner v2. גרסה 2 של Runner משתמשת בשיטה יעילה יותר לדיווח על מדדים, ואין בה את המגבלה של 20 MB.
ModuleNotFoundError: No module named 'pkg_resources'
כשמריצים משימת Dataflow, השגיאה הבאה מתרחשת במהלך הפעלת העובד או התקנת התלות:
ModuleNotFoundError: No module named 'pkg_resources'
הבעיה הזו מתרחשת כי החל מגרסה 82.0.0 של setuptools (שפורסמה ב-8 בפברואר 2026), המודול pkg_resources הוסר. המודול הזה הוצא משימוש והוחלף במודולים importlib.resources ו-importlib.metadata.
כדי לפתור את הבעיה, אפשר להשתמש באחת מהשיטות הבאות:
הצמדה של
setuptools: אם התלות שלכם דורשת גרסה שלsetuptoolsשתואמת לאחור כדי שהבנייה תצליח, אתם יכולים להגדיר דרישה לגרסה ספציפית באמצעות הארגומנטsetup_requiresבקובץsetup.py. לדוגמה:import setuptools setuptools.setup( name='PACKAGE-NAME', version='PACKAGE-VERSION', # Pin to a version prior to 82.0.0 setup_requires=['setuptools<82.0.0'], install_requires=['incompatible-package', ...], packages=setuptools.find_packages() )עדכון יחסי תלות: בודקים את הדרישות של הספרייה ויחסי התלות כדי לעדכן לגרסאות חדשות יותר שתואמות לגרסה העדכנית של
setuptoolsולא מסתמכות עלpkg_resources.הסרת ספריות מיותרות: מסירים מהדרישות או מקובץ ההגדרה את כל הספריות שלא נדרשות לעבודה. לדוגמה, זוהו כמה גרסאות קודמות של
cx_Oracleשגורמות לבעיה הזו במהלך תהליך build.
NameError
כשמריצים את צינור הנתונים באמצעות שירות Dataflow, מתרחשת השגיאה הבאה:
NameError
השגיאה הזו לא מתרחשת כשמבצעים את הפקודה באופן מקומי, למשל כשמבצעים אותה באמצעות DirectRunner.
השגיאה הזו מתרחשת אם DoFn משתמשים בערכים במרחב השמות הגלובלי שלא זמינים בתהליך העבודה של Dataflow.
כברירת מחדל, ייבוא גלובלי, פונקציות ומשתנים שמוגדרים בסשן הראשי לא נשמרים במהלך הסריאליזציה של משימת Dataflow.
כדי לפתור את הבעיה, אפשר להשתמש באחת מהשיטות הבאות. אם DoFn מוגדרים בקובץ הראשי ומתייחסים לייבוא ולפונקציות במרחב השמות הגלובלי, צריך להגדיר את האפשרות --save_main_session של צינור הנתונים ל-True. השינוי הזה מבצע סריאליזציה של מצב מרחב השמות הגלובלי ומטעין אותו לעובד Dataflow.
אם יש לכם אובייקטים במרחב השמות הגלובלי שלא ניתן להמיר לפורמט pickle, תתרחש שגיאת המרה. אם השגיאה קשורה למודול שאמור להיות זמין בהפצת Python, צריך לייבא את המודול באופן מקומי, במקום שבו הוא נמצא בשימוש.
לדוגמה, במקום:
import re … def myfunc(): # use re module
שימוש:
def myfunc(): import re # use re module
לחלופין, אם DoFns שלכם משתרעים על פני כמה קבצים, אתם יכולים להשתמש בגישה אחרת לאריזת תהליך העבודה ולניהול תלות.
האובייקט כפוף למדיניות שמירת הנתונים של הקטגוריה
אם יש לכם משימת Dataflow שכותבת לקטגוריה של Cloud Storage, המשימה נכשלת עם השגיאה הבאה:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
יכול להיות שתופיע גם השגיאה הבאה:
Unable to rename "gs://BUCKET"
השגיאה הראשונה מתרחשת כששמירת אובייקטים מופעלת בקטגוריה של Cloud Storage שהעבודה של Dataflow כותבת אליה. מידע נוסף זמין במאמר בנושא הפעלה ושימוש בהגדרות של שמירת אובייקטים.
כדי לפתור את הבעיה, אפשר לנסות אחד מהפתרונות הבאים:
כתיבה לקטגוריה של Cloud Storage שאין בה מדיניות שמירת נתונים בתיקייה
temp.מסירים את מדיניות שמירת הנתונים מהקטגוריה שהעבודה כותבת אליה. מידע נוסף מופיע במאמר הגדרת מדיניות שמירת נתונים לאובייקט.
השגיאה השנייה יכולה להצביע על כך ששמירת האובייקט מופעלת בקטגוריה של Cloud Storage, או שהיא יכולה להצביע על כך שלחשבון השירות של העובד (worker) ב-Dataflow אין הרשאה לכתוב בקטגוריה של Cloud Storage.
אם מופיעה השגיאה השנייה והשמירה של האובייקט מופעלת בקטגוריה של Cloud Storage, נסו את הפתרונות העקיפים שמתוארים למעלה. אם שמירת האובייקטים לא מופעלת בקטגוריה של Cloud Storage, צריך לוודא שלחשבון שירות של עובד Dataflow יש הרשאת כתיבה בקטגוריה של Cloud Storage. מידע נוסף זמין במאמר בנושא גישה לדליים ב-Cloud Storage.
העיבוד נתקע או שהפעולה נמשכת
אם Dataflow מבלה יותר זמן בהרצת DoFn מהזמן שצוין ב-TIME_INTERVAL בלי להחזיר ערך, מוצגת ההודעה הבאה.
Java
אחת משתי הודעות היומן הבאות, בהתאם לגרסה:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
המשך
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
יש שתי סיבות אפשריות להתנהגות הזו:
- הקוד
DoFnאיטי, או שהוא נמצא בהמתנה להשלמת פעולה חיצונית איטית. - יכול להיות שהקוד
DoFnנתקע, נכנס למצב של נעילה הדדית או שמשלים את העיבוד לאט באופן חריג.
כדי לדעת מה קורה, מרחיבים את הרשומה ביומן של Cloud Monitoring כדי לראות את דוח קריסות. מחפשים הודעות שמציינות שהקוד DoFn נתקע או שנתקל בבעיות אחרות. אם לא מופיעות הודעות, יכול להיות שהבעיה היא מהירות הביצוע של קוד DoFn. כדאי להשתמש ב-Cloud Profiler או בכלי אחר כדי לבדוק את הביצועים של הקוד.
אם צינור הנתונים מבוסס על Java VM (באמצעות Java או Scala), אפשר לבדוק את הסיבה לכך שהקוד נתקע. כדי ליצור dump מלא של השרשור של כל ה-JVM (ולא רק של השרשור התקוע), פועלים לפי השלבים הבאים:
- רושמים את שם העובד מתוך רשומת היומן.
- בקטע Compute Engine במסוף Google Cloud , מחפשים את מופע Compute Engine עם שם העובד שרשמתם.
- משתמשים ב-SSH כדי להתחבר למכונה עם השם הזה.
מריצים את הפקודה הבאה:
curl http://localhost:8081/threadz
הפעולה מתבצעת בחבילה
כשמריצים צינור קריאה מ-JdbcIO, הקריאות המחיצות מ-JdbcIO איטיות, וההודעה הבאה מופיעה בקובצי היומן של העובד:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
כדי לפתור את הבעיה, מבצעים שינוי אחד או יותר בצינור:
משתמשים במחיצות כדי להגדיל את המקביליות של העבודה. קריאה עם מחיצות קטנות יותר כדי לשפר את ההתאמה לגודל.
בודקים אם עמודת החלוקה היא עמודת אינדקס או עמודת חלוקה אמיתית במקור. כדי להשיג את הביצועים הטובים ביותר, מומלץ להפעיל יצירת אינדקסים וחלוקה למחיצות בעמודה הזו במסד הנתונים של המקור.
משתמשים בפרמטרים
lowerBoundו-upperBoundכדי לדלג על מציאת הגבולות.
שגיאות במכסה של Pub/Sub
כשמריצים צינור עיבוד נתונים בסטרימינג מ-Pub/Sub, מתרחשות השגיאות הבאות:
429 (rateLimitExceeded)
או:
Request was throttled due to user QPS limit being reached
השגיאות האלה מתרחשות אם בפרויקט שלכם אין מספיק מכסת Pub/Sub.
כדי לבדוק אם הפרויקט שלכם חורג מהמכסה, פועלים לפי השלבים הבאים כדי לבדוק אם יש שגיאות בצד הלקוח:
- עוברים אל Google Cloud המסוף.
- בתפריט הימני, לוחצים על ממשקי API ושירותים.
- בתיבת החיפוש, מחפשים את Cloud Pub/Sub.
- לוחצים על הכרטיסייה שימוש.
- בודקים את קודי התגובה ומחפשים קודי שגיאה של לקוח
(4xx).
הבקשה אסורה לפי מדיניות הארגון
כשמריצים צינור, מופיעה השגיאה הבאה:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
השגיאה הזו מתרחשת אם קטגוריה של Cloud Storage נמצאת מחוץ לגבולות השירות.
כדי לפתור את הבעיה, צריך ליצור כלל ליציאת נתונים שמאפשר גישה לדלי מחוץ לגבולות הגזרה של השירות.
לא ניתן לגשת לחבילה שהועברה להמתנה…
יכול להיות שעבודות שהצליחו בעבר ייכשלו עם השגיאה הבאה:
Staged package...is inaccessible
כדי לפתור את הבעיה:
- מוודאים שבקטגוריית Cloud Storage שמשמשת לאחסון זמני אין הגדרות TTL שגורמות למחיקה של חבילות שאוחסנו זמנית.
מוודאים שלחשבון השירות של ה-worker בפרויקט Dataflow יש הרשאה לגשת לקטגוריה של Cloud Storage שמשמשת לאחסון זמני. יכולות להיות כמה סיבות לכך שיש פערים בהרשאות:
- קטגוריה של Cloud Storage שמשמשת לאחסון זמני נמצאת בפרויקט אחר.
- הקטגוריה של Cloud Storage שמשמשת לאחסון זמני הועברה מגישה עם הרשאות מפורטות לגישה אחידה ברמת הקטגוריה. בגלל חוסר העקביות בין כללי מדיניות של IAM ו-ACL, העברה של קטגוריית הביניים לגישה אחידה ברמת הקטגוריה לא מאפשרת שימוש ברשימות ACL למשאבי Cloud Storage. רשימות ACL כוללות את ההרשאות שמוחזקות על ידי חשבון השירות של העובד בפרויקט Dataflow בקטגוריית הביניים.
מידע נוסף מופיע במאמר גישה לקטגוריות של Cloud Storage בפרויקטים שונים.Google Cloud
פריט עבודה נכשל 4 פעמים
השגיאה הבאה מתרחשת כשמשימת אצווה נכשלת:
The job failed because a work item has failed 4 times.
השגיאה הזו מתרחשת אם פעולה יחידה במשימת אצווה גורמת לקוד של העובד להיכשל ארבע פעמים. העבודה נכשלת ב-Dataflow וההודעה הזו מוצגת.
כשמפעילים את הצינור במצב סטרימינג, מתבצע ניסיון חוזר לצרף חבילה שכוללת פריט שנכשל, ללא הגבלה, מה שעלול לגרום לעצירה קבועה של הצינור.
אי אפשר להגדיר את סף הכשל הזה. פרטים נוספים זמינים במאמר בנושא טיפול בשגיאות ובחריגים בצינורות.
כדי לפתור את הבעיה, צריך לעיין ביומנים של Cloud Monitoring של המשימה כדי לזהות את ארבעת הכשלים הספציפיים. בלוגים של העובדים, מחפשים רשומות של Error-level או Fatal-level שמופיעות בהן חריגות או שגיאות. החריגה או השגיאה צריכות להופיע לפחות ארבע פעמים. אם היומנים מכילים רק שגיאות כלליות של פסק זמן שקשורות לגישה למשאבים חיצוניים, כמו MongoDB, צריך לוודא שלחשבון השירות של העובד יש הרשאה לגשת לרשת המשנה של המשאב.
פג הזמן הקצוב לקובץ תוצאות הסקר
מידע מלא על פתרון בעיות שקשורות לשגיאה 'Timeout in polling result file' זמין במאמר פתרון בעיות בתבניות Flex.
הפעולה Write Correct File/Write/WriteImpl/PreFinalize נכשלה
כשמריצים משימה, היא נכשלת לסירוגין ומופיעה השגיאה הבאה:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
השגיאה הזו מתרחשת כשמשתמשים באותה תיקיית משנה כמקום אחסון זמני לכמה משימות שמופעלות בו-זמנית.
כדי לפתור את הבעיה, אל תשתמשו באותה תיקיית משנה כמקום אחסון זמני לכמה צינורות. לכל צינור צריך לספק תיקיית משנה ייחודית שתשמש כמיקום אחסון זמני.
האלמנט חורג מהגודל המקסימלי של הודעת protobuf
כשמריצים משימות Dataflow ולפייפליין יש רכיבים גדולים, יכול להיות שיופיעו שגיאות שדומות לדוגמאות הבאות:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
או:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
או:
Output element size exceeds the allowed limit. (... > 83886080) See https://cloud.google.com/dataflow/quotas#limits for more details.
יכול להיות שתופיע גם אזהרה שדומה לדוגמה הבאה:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
השגיאות האלה מתרחשות כשהצנרת מכילה רכיבים גדולים.
כדי לפתור את הבעיה הזו, אם אתם משתמשים ב-Python SDK, צריך לשדרג ל-Apache Beam גרסה 2.57.0 ואילך. בגרסאות 2.57.0 ואילך של Python SDK השתפר העיבוד של רכיבים גדולים ונוספו יומני רישום רלוונטיים.
אם השגיאות נמשכות אחרי השדרוג או אם אתם לא משתמשים ב-Python SDK, צריך לזהות את השלב בעבודה שבו השגיאה מתרחשת ולנסות להקטין את הגודל של הרכיבים בשלב הזה.
כש-PCollection אובייקטים בצינור שלך מכילים רכיבים גדולים, דרישות ה-RAM של הצינור גדלות. אלמנטים גדולים יכולים גם לגרום לשגיאות בזמן הריצה, במיוחד כשהם חוצים את הגבולות של שלבים ממוזגים.
רכיבים גדולים יכולים להופיע כשצינור מעבד בטעות איטרבל גדול. לדוגמה, צינור עיבוד נתונים שמעביר את הפלט של פעולת GroupByKey לפעולת Reshuffle מיותרת, יוצר רשימות כרכיבים בודדים. יכול להיות שברשימות האלה יהיו הרבה ערכים לכל מפתח.
אם השגיאה מתרחשת בשלב שמשתמש בקלט צדדי, חשוב לדעת שהשימוש בקלט צדדי עלול ליצור מחסום לאיחוד. בודקים אם הטרנספורמציה שיוצרת רכיב גדול והטרנספורמציה שמשתמשת בו שייכות לאותו שלב.
כשמקימים את צינור הנתונים, מומלץ לפעול לפי השיטות המומלצות הבאות:
- ב-
PCollections, כדאי להשתמש בכמה רכיבים קטנים במקום ברכיב גדול אחד. - אחסון של כתובות Blob גדולות במערכות אחסון חיצוניות. אפשר להשתמש ב-
PCollectionsכדי להעביר את המטא-נתונים שלהם, או להשתמש בקודן מותאם אישית שמקטין את הגודל של הרכיב. - אם אתם חייבים להעביר PCollection שיכול לחרוג מ-2GB כקלט צדדי, אתם יכולים להשתמש בתצוגות איטרטיביות, כמו
AsIterableו-AsMultiMap.
הגודל המקסימלי של רכיב יחיד בעבודת Dataflow מוגבל ל-2 GB (או ל-80 MB ב-Streaming Engine). מידע נוסף זמין במאמר מכסות ומגבלות.
Dataflow לא יכול לעבד טרנספורמציות מנוהלות...
יכול להיות שצינורות שמשתמשים ב-Managed I/O ייכשלו עם השגיאה הזו אם Dataflow לא יכול לשדרג באופן אוטומטי את הטרנספורמציות של ה-I/O לגרסה העדכנית ביותר שנתמכת. ה-URN ושמות השלבים שמופיעים בשגיאה צריכים לציין אילו טרנספורמציות בדיוק לא הצליחו לשדרג ב-Dataflow.
פרטים נוספים על השגיאה הזו זמינים ב-Logs Explorer בקטע Dataflow log names managed-transforms-worker ו-managed-transforms-worker-startup.
אם Logs Explorer לא מספק מידע מספיק לפתרון הבעיה, אפשר לפנות אל Cloud Customer Care.
שגיאות בהעברה לארכיון
בקטעים הבאים מפורטות שגיאות נפוצות שאפשר להיתקל בהן כשמנסים לארכב משימת Dataflow באמצעות ה-API.
לא צוין ערך
כשמנסים להעביר לארכיון משימת Dataflow באמצעות ה-API, יכול להיות שתופיע השגיאה הבאה:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
השגיאה הזו מתרחשת בגלל אחת מהסיבות הבאות:
הנתיב שצוין לשדה
updateMaskלא תואם לפורמט הנכון. הבעיה הזו יכולה לקרות בגלל טעויות הקלדה.הערך
JobMetadataלא צוין בצורה נכונה. בשדהJobMetadata, עבורuserDisplayProperties, משתמשים בצמד מפתח/ערך"archived":"true".
כדי לפתור את השגיאה הזו, צריך לוודא שהפקודה שמעבירים ל-API תואמת לפורמט הנדרש. פרטים נוספים זמינים במאמר בנושא העברת משרה לארכיון.
ממשק ה-API לא מזהה את הערך
כשמנסים להעביר לארכיון משימת Dataflow באמצעות ה-API, יכול להיות שתופיע השגיאה הבאה:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
השגיאה הזו מתרחשת כשהערך שצוין בצמד מפתח/ערך של משימות הארכיון אינו ערך נתמך. הערכים הנתמכים של זוג הערכים של משימות הארכיון הם "archived":"true" ו-"archived":"false".
כדי לפתור את השגיאה הזו, צריך לוודא שהפקודה שמעבירים ל-API תואמת לפורמט הנדרש. פרטים נוספים זמינים במאמר בנושא העברת משרה לארכיון.
אי אפשר לעדכן גם את המצב וגם את המסכה
כשמנסים להעביר לארכיון משימת Dataflow באמצעות ה-API, יכול להיות שתופיע השגיאה הבאה:
Cannot update both state and mask.
השגיאה הזו מתרחשת כשמנסים לעדכן גם את מצב המשימה וגם את סטטוס הארכיון באותה קריאה ל-API. אי אפשר לעדכן את סטטוס המשימה ואת פרמטר השאילתה updateMask באותה קריאה ל-API.
כדי לפתור את השגיאה הזו, צריך לעדכן את מצב העבודה בקריאה נפרדת ל-API. לפני שמעדכנים את סטטוס הארכיון של המשימה, צריך לעדכן את מצב המשימה.
שינוי תהליך העבודה נכשל
כשמנסים להעביר לארכיון משימת Dataflow באמצעות ה-API, יכול להיות שתופיע השגיאה הבאה:
Workflow modification failed.
השגיאה הזו מתרחשת בדרך כלל כשמנסים להעביר לארכיון משימה שפועלת.
כדי לפתור את השגיאה הזו, צריך להמתין עד שהעבודה תושלם לפני שמעבירים אותה לארכיון. למשימות שהושלמו יש אחד מהמצבים הבאים:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
מידע נוסף זמין במאמר זיהוי השלמה של משימת Dataflow.
שגיאות בקובץ אימג' של קונטיינר
בקטעים הבאים מפורטות שגיאות נפוצות שאולי תיתקלו בהן במהלך השימוש במאגרי תגים בהתאמה אישית, וגם שלבים לפתרון בעיות או לפתרון השגיאות. בדרך כלל, הודעות השגיאה מתחילות בהודעה הבאה:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
ההרשאה containeranalysis.occurrences.list נדחתה
השגיאה הבאה מופיעה בקובצי היומן:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
Container Analysis API לא מופעל. במקרים מסוימים, נדרש Container Analysis API לסריקת פגיעויות.
API.
מידע נוסף זמין במאמרים סקירה כללית של סריקת מערכת הפעלה והגדרת בקרת גישה במסמכי התיעוד של Artifact Analysis.
שגיאה בסנכרון של ה-pod ... נכשל ב-StartContainer
השגיאה הבאה מתרחשת במהלך הפעלת העובד:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Pod הוא קבוצה של קונטיינרים ב-Docker שמופעלים במקביל על עובד של Dataflow. השגיאה הזו מתרחשת כשאחד ממאגרי Docker בתרמיל לא מצליח להתחיל לפעול. אם אי אפשר לשחזר את הכשל, עובד Dataflow לא יכול להתחיל, ועבודות אצווה של Dataflow נכשלות בסופו של דבר עם שגיאות כמו השגיאות הבאות:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
השגיאה הזו מתרחשת בדרך כלל כשאחד מהמאגרים קורס באופן רציף במהלך ההפעלה.
כדי להבין את שורש הבעיה, צריך לחפש את היומנים שנרשמו מיד לפני הכשל. כדי לנתח את היומנים, משתמשים ב-Logs Explorer. ב-Logs Explorer, מגבילים את קובצי היומן לרשומות ביומן שנוצרו על ידי העובד עם שגיאות בהפעלת המאגר. כדי להגביל את הרשומות ביומן, מבצעים את השלבים הבאים:
- בכלי Logs Explorer, מאתרים את רשומת היומן
Error syncing pod. - כדי לראות את התוויות שמשויכות לרשומה ביומן, מרחיבים את הרשומה.
- לוחצים על התווית שמשויכת ל-
resource_nameואז על הצגת הערכים התואמים.
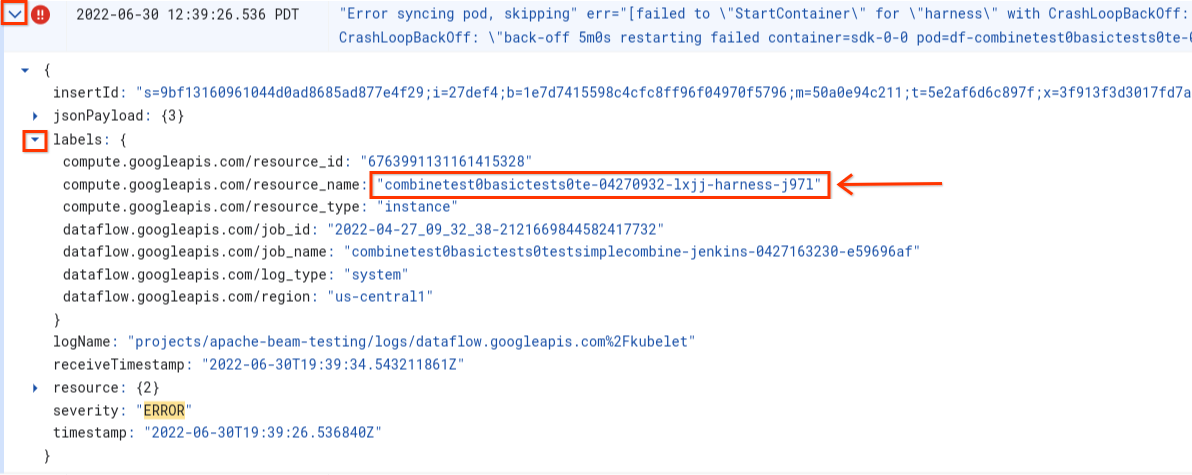
ב-Logs Explorer, היומנים של Dataflow מאורגנים בכמה מקורות נתונים. ההודעה Error syncing pod מופיעה ביומן שנקרא kubelet. עם זאת, יכול להיות שהיומנים מהמאגר שנכשל נמצאים בזרם יומנים אחר. לכל מאגר יש שם. אפשר להיעזר בטבלה הבאה כדי לזהות את זרם היומן שעשוי להכיל יומנים שרלוונטיים לקונטיינר שנכשל.
| שם הקונטיינר | שמות של יומני רישום |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 ודומים | docker |
| רתמה | harness, harness-startup |
| python, java-batch, java-streaming | worker-startup, worker |
| פריט מידע שנוצר בתהליך | פריט מידע שנוצר בתהליך |
כששולחים שאילתה ל-Logs Explorer, מוודאים שהשאילתה כוללת את שמות היומנים הרלוונטיים בממשק של כלי ליצירת שאילתות או שאין הגבלות על שם היומן.
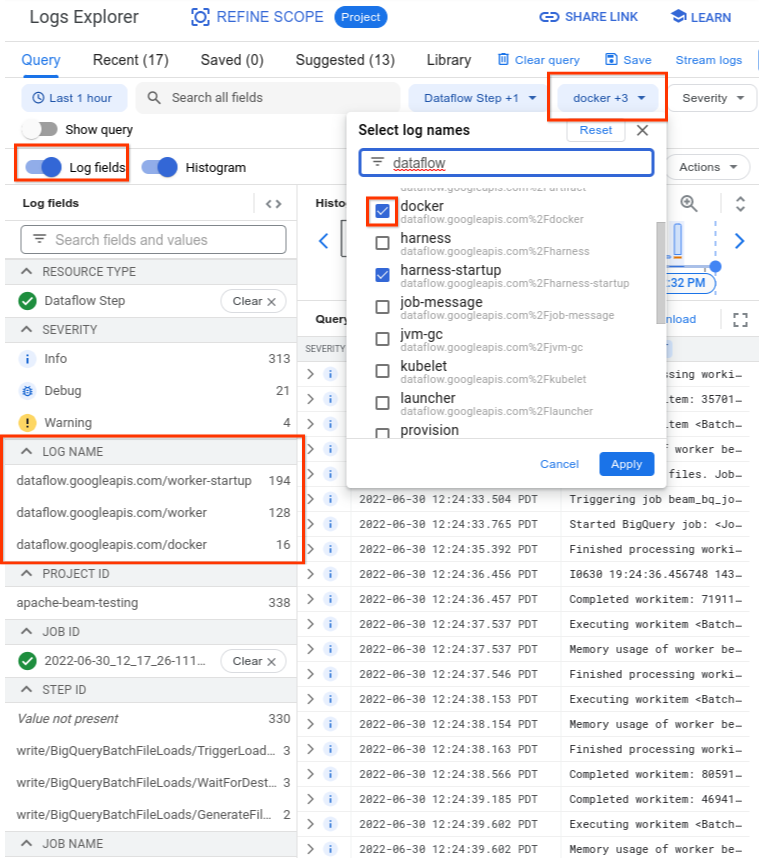
אחרי שבוחרים את היומנים הרלוונטיים, תוצאת השאילתה עשויה להיראות כמו בדוגמה הבאה:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
לפעמים, היומנים שמדווחים על הסימפטום של כשל במאגר מדווחים כ-INFO, לכן כדאי לכלול בבדיקה יומנים של INFO.
הסיבות הנפוצות לכישלון של קונטיינרים הן:
- לצינור Python יש יחסי תלות נוספים שמותקנים בזמן הריצה, וההתקנה נכשלת. יכול להיות שיוצגו שגיאות כמו
pip install failed with error. הבעיה הזו יכולה לקרות בגלל דרישות סותרות, או בגלל הגדרת רשת מוגבלת שמונעת מעובד Dataflow למשוך תלות חיצונית ממאגר ציבורי באינטרנט. תהליך worker נכשל באמצע ההרצה של צינור עיבוד הנתונים בגלל שגיאת חוסר זיכרון. יכול להיות שתופיע אחת מהודעות השגיאה הבאות:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
כדי לנפות באגים בבעיה של חוסר זיכרון, אפשר לעיין במאמר פתרון בעיות של חוסר זיכרון ב-Dataflow.
ל-Dataflow אין אפשרות לשלוף את קובץ אימג' של קונטיינר. מידע נוסף זמין במאמר בקשת משיכת תמונה נכשלה עם שגיאה.
הקונטיינר שבו נעשה שימוש לא תואם לארכיטקטורת ה-CPU של מכונת ה-VM של העובד. ביומני ההפעלה של ה-harness, יכול להיות שתראו שגיאה כמו:
exec /opt/apache/beam/boot: exec format error. כדי לבדוק את הארכיטקטורה של תמונת הקונטיינר, מריצים את הפקודהdocker image inspect $IMAGE:$TAGומחפשים את מילת המפתחArchitecture. אם מופיעError: No such image: $IMAGE:$TAG, יכול להיות שתצטרכו לשלוף את התמונה קודם על ידי הפעלתdocker pull $IMAGE:$TAG. מידע על יצירת קובצי אימג' עם כמה ארכיטקטורות זמין במאמר יצירת קובץ אימג' של קונטיינר עם כמה ארכיטקטורות.
אחרי שמזהים את השגיאה שגורמת לכשל במאגר התגים, מנסים לפתור את השגיאה ושולחים מחדש את צינור הנתונים.
הפעלת התבנית נכשלה עם השגיאה
במהלך ההפעלה של תבנית Flex, השגיאה הבאה מופיעה ביומני העבודות:
Error: Template launch failed: exit status 13
Error occurred in the launcher container: Template launch failed. See console logs.
יומני Worker מכילים stacktrace שדומה ליומני המעקב הבאים:
TypeError: canonicalize_version() got an unexpected keyword argument 'strip_trailing_zero'
ERROR:absl:Internal Error Type : RuntimeError
ERROR:absl:Error Message : Full trace: Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/apache_beam/utils/processes.py", line 89, in check_output
out = subprocess.check_output(*args, **kwargs)
IFile "/usr/local/lib/python3.9/subprocess.py", line 424, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/usr/local/lib/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['/usr/local/bin/python', 'setup.py', 'sdist', '--dist-dir', '/tmp/tmp196n6g8d']' returned non-zero exit status 1.
השגיאות האלה מתרחשות אם מפעיל התבנית מוצא תלויות סותרות במהלך ההגדרה, במיוחד כשחבילת setuptools מתעדכנת לגרסה שגבוהה מ-71.0 או שווה לה. בודקים את יחסי התלות של הצינור לעיבוד נתונים ומוודאים שיחסי התלות של האריזה גבוהים מ-25.0 או שווים לה.
בקשת משיכת התמונה נכשלה עם השגיאה
במהלך הפעלת העובד, אחת מהשגיאות הבאות מופיעה ביומני העובד או המשימה:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
השגיאות האלה מתרחשות אם worker לא מצליח להתחיל לפעול כי הוא לא יכול למשוך קובץ אימג' של קונטיינר של Docker. הבעיה הזו מתרחשת בתרחישים הבאים:
- כתובת ה-URL של קובץ אימג' של קונטיינר של ה-SDK בהתאמה אישית שגויה
- לעובד חסרים אישורים או גישה לרשת כדי לגשת לתמונה המרוחקת
כדי לפתור את הבעיה:
- אם אתם משתמשים בקובץ אימג' של קונטיינר מותאם אישית בעבודה שלכם, אתם צריכים לוודא שכתובת ה-URL של התמונה נכונה ושיש לה תג או תקציר תקפים. לעובדי Dataflow צריכה להיות גם גישה לתמונה.
- כדי לוודא שאפשר לשלוף תמונות ציבוריות באופן מקומי, מריצים את הפקודה
docker pull $imageממחשב לא מאומת.
לתמונות פרטיות או לעובדים פרטיים:
- אם אתם משתמשים ב-Container Registry כדי לארח את קובץ אימג' של קונטיינר, מומלץ להשתמש במקום זאת ב-Artifact Registry. החל מ-15 במאי 2023, Container Registry הוצא משימוש. אם אתם משתמשים ב-Container Registry, אתם יכולים לעבור אל Artifact Registry. אם התמונות נמצאות בפרויקט אחר מזה שמשמש להרצת העבודהGoogle Cloud , צריך להגדיר בקרת גישה לחשבון השירותGoogle Cloud שמוגדר כברירת מחדל.
- אם משתמשים בענן וירטואלי פרטי (VPC) משותף, צריך לוודא שלעובדים יש גישה למארח של מאגר המכולות המותאם אישית.
- משתמשים ב-
sshכדי להתחבר למכונה וירטואלית של עובד פעיל של משימה ומריצים את הפקודהdocker pull $imageכדי לוודא שהעובד מוגדר בצורה תקינה.
אם העובדים נכשלים כמה פעמים ברציפות בגלל השגיאה הזו והעבודה התחילה במשימה, המשימה יכולה להיכשל עם שגיאה שדומה להודעה הבאה:
Job appears to be stuck.
אם תסירו את הגישה לתמונה בזמן שהעבודה פועלת, על ידי הסרת התמונה עצמה או ביטול ההרשאה של חשבון השירות של Dataflow worker או הגישה לאינטרנט כדי לגשת לתמונות, Dataflow יתעד רק שגיאות. העבודה לא נכשלת ב-Dataflow. בנוסף, כדי למנוע אובדן של מצב הפייפליין, Dataflow לא מפסיק פייפליינים של סטרימינג שפועלים לאורך זמן.
יכולות להיות שגיאות אחרות שנובעות מבעיות במכסת המאגר או מהפסקות זמניות בשירות. אם נתקלתם בבעיות שקשורות לחריגה מהמכסה של Docker Hub לשליפת תמונות ציבוריות או להפסקות כלליות במאגרים של צד שלישי, כדאי להשתמש ב- Artifact Registry כמאגר התמונות.
SystemError: unknown opcode
יכול להיות שצינור עיבוד הנתונים של קונטיינר מותאם אישית של Python ייכשל עם השגיאה הבאה מיד אחרי שליחת העבודה:
SystemError: unknown opcode
בנוסף, דוח הקריסות עשוי לכלול
apache_beam/internal/pickler.py
כדי לפתור את הבעיה, צריך לוודא שגרסת Python שבה אתם משתמשים באופן מקומי זהה לגרסה בקובץ האימג' של הקונטיינר, עד לגרסה הראשית ולגרסת המשנה. ההבדל בגרסת התיקון, למשל 3.6.7 לעומת 3.6.8, לא יוצר בעיות תאימות. הבדל בגרסה המשנית, למשל 3.6.8 לעומת 3.8.2, יכול לגרום לכשלים בצינור.
שגיאות בשדרוג של צינור העיבוד של נתונים בזמן אמת
במאמר פתרון בעיות בשדרוג צינורות להעברת נתונים בסטרימינג מוסבר איך לפתור שגיאות בשדרוג צינורות להעברת נתונים בסטרימינג באמצעות תכונות כמו הפעלת עבודת החלפה מקבילה.
עדכון של Runner v2 harness
הודעת המידע הבאה מופיעה ביומני המשימות של משימה ב-Runner v2
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
המשמעות היא שהגרסה של תהליך runner harness תתעדכן אוטומטית בשלב מסוים 7 ימים אחרי המסירה הראשונית של ההודעה, וכתוצאה מכך תהיה הפסקה קצרה בעיבוד. אם רוצים לשלוט במועד ההשהיה, אפשר לעיין במאמר בנושא עדכון צינור קיים כדי להתחיל עבודת החלפה שתכלול את הגרסה העדכנית ביותר של ה-runner harness.
שגיאות של עובדים
בקטעים הבאים מפורטות שגיאות נפוצות שקשורות לעובדים, ומוסבר איך לפתור אותן או לבצע פתרון בעיות.
הפעלה מ-Java worker harness אל Python DoFn נכשלת עם שגיאה
אם שיחה מ-Java worker harness אל Python DoFn נכשלת, מוצגת הודעת שגיאה רלוונטית.
כדי לבדוק את השגיאה, מרחיבים את הערך ביומן השגיאות של Cloud Monitoring ומסתכלים על הודעת השגיאה ועל מעקב אחר השגיאה. הוא מראה לכם איזה קוד נכשל כדי שתוכלו לתקן אותו אם צריך. אם לדעתכם השגיאה היא באג ב-Apache Beam או ב-Dataflow, דווחו על הבאג.
EOFError: marshal data too short
השגיאה הבאה מופיעה ביומני העובדים:
EOFError: marshal data too short
השגיאה הזו מתרחשת לפעמים כשנפח האחסון של תהליכי העבודה של צינורות Python נגמר.
כדי לפתור את הבעיה, אפשר לעיין במאמר בנושא אין יותר מקום במכשיר.
הצירוף של הדיסק נכשל
כשמנסים להפעיל עבודת Dataflow שמשתמשת במכונות וירטואליות C3 עם דיסק מתמשך, העבודה נכשלת עם אחת מהשגיאות הבאות או עם שתיהן:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
השגיאות האלה מתרחשות כשמשתמשים במכונות וירטואליות מסוג C3 עם סוג של דיסק מתמשך שלא נתמך. מידע נוסף זמין במאמר בנושא סוגי דיסקים נתמכים עבור C3.
כדי להשתמש במכונות וירטואליות מסוג C3 עם משימת Dataflow, בוחרים את pd-ssd סוג דיסק העובד. מידע נוסף מופיע במאמר בנושא אפשרויות ברמת העובד.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
המשך
disk_type=pd-ssd
אין מקום פנוי במכשיר
כשנגמר נפח האחסון של משימה, יכול להיות שתופיע השגיאה הבאה ביומני העובדים:
No space left on device
השגיאה הזו יכולה להופיע מהסיבות הבאות:
- נגמר המקום הפנוי באחסון המתמיד של העובד. זה יכול לקרות בגלל אחת מהסיבות הבאות:
- עבודת אימון מורידה תלויות גדולות בזמן הריצה
- עבודה משתמשת במאגרי תגים גדולים בהתאמה אישית
- משימה כותבת הרבה נתונים זמניים לדיסק מקומי
- כשמשתמשים בארגון נתונים של Dataflow, המערכת מגדירה גודל דיסק נמוך יותר כברירת מחדל. כתוצאה מכך, השגיאה הזו עשויה להתרחש במשימות שעוברות משינוי סדר נתונים שמבוסס על עובדים.
- דיסק האתחול של העובד מתמלא כי הוא רושם יותר מ-50 רשומות בשנייה.
כדי לפתור את הבעיה, מבצעים את השלבים הבאים לפתרון בעיות:
כדי לראות משאבי דיסק שמשויכים לעובד יחיד, מחפשים את פרטי מכונת ה-VM של מכונות העובד שמשויכות לעבודה. חלק מנפח הדיסק נצרך על ידי מערכת ההפעלה, קבצים בינאריים, יומנים ומאגרי נתונים.
כדי להגדיל את הנפח של דיסק מתמשך או של דיסק אתחול, משנים את הגדרת גודל הדיסק.
אפשר לעקוב אחרי השימוש בשטח האחסון במכונות הווירטואליות של העובדים באמצעות Cloud Monitoring. הוראות להגדרה מופיעות במאמר בנושא קבלת מדדים של worker VM מסוכן Monitoring.
כדי לחפש בעיות במקום בדיסק האתחול, מעיינים בפלט של היציאה הטורית במכונות הווירטואליות של העובדים ומחפשים הודעות כמו:
Failed to open system journal: No space left on device
אם יש לכם הרבה worker VM, אתם יכולים ליצור סקריפט להרצת gcloud
compute instances get-serial-port-output על כולן בבת אחת. במקום זאת, אפשר לבדוק את התוצאה הזו.
צינור Python נכשל אחרי שעה של חוסר פעילות של העובד
כשמשתמשים ב-Apache Beam SDK ל-Python עם Dataflow Runner V2 במכונות עובד עם הרבה ליבות CPU, צריך להשתמש ב-Apache Beam SDK 2.35.0 או בגרסה מתקדמת יותר. אם העבודה שלכם משתמשת בקונטיינר בהתאמה אישית, צריך להשתמש ב-Apache Beam SDK 2.46.0 או בגרסה מתקדמת יותר.
מומלץ ליצור מראש את מאגר התגים של Python. השלב הזה יכול לשפר את זמני ההפעלה של המכונות הווירטואליות ואת הביצועים של שינוי הגודל האוטומטי האופקי. כדי להשתמש בתכונה הזו, צריך להפעיל את Cloud Build API בפרויקט ולשלוח את צינור העיבוד עם הפרמטר הבא:
‑‑prebuild_sdk_container_engine=cloud_build.
מידע נוסף זמין במאמר בנושא Dataflow Runner V2.
אפשר גם להשתמש בתמונה מותאמת אישית של מאגר תגים עם כל התלות שהותקנו מראש.
RESOURCE_POOL_EXHAUSTED או IP_SPACE_EXHAUSTED_WITH_DETAILS
כשיוצרים Google Cloud משאב, יכול להיות שתיתקלו באחת מהשגיאות הבאות שקשורות ליצירת מאגר עובדים.
השם של המכונה הווירטואלית INSTANCE_NAME מייצג את השם של מכונת ה-VM של העובד. מכונות וירטואליות של Worker הן מכונות וירטואליות ב-Compute Engine שמנוהלות באופן מלא ומבצעות את המשימות של צינור עיבוד הנתונים.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
השגיאה הזו מתרחשת בגלל חוסר זמינות זמני של סוג ה-worker VM המבוקש. כברירת מחדל, Dataflow בוחר את סוג המכונה למכונות ה-VM של העובדים שמריצות את העבודה, וגם את הגודל והסוג של דיסק האחסון המתמיד.
כדי לפתור את הבעיה, אפשר לנסות אחת מהאסטרטגיות הבאות:
- מעדכנים את ה-worker VM לסוג מכונה אחר ומנסים שוב להריץ את העבודה.
- להפעיל את משימת Dataflow מאזור אחר.
מפעילים את הבחירה האוטומטית של מכונות וירטואליות באמצעות רמזים למשאבים
min_ramאוcpu_count. התכונה 'בחירה אוטומטית של מכונות וירטואליות' מאפשרת להקצות משאבים לעובדים מתוך רשימה שנבחרה בקפידה של סוגי מכונות שעומדים בדרישות ה-RAM וה-CPU שלכם. כך אפשר למנוע בעיות של מיצוי משאבים במאגר המשאבים.הערה: כשהאפשרות 'בחירה אוטומטית של מכונה וירטואלית' מופעלת, המערכת מתעלמת מכל סוג מכונה שצוין באפשרויות של צינור העיבוד.
כדי ליצור טיפול בשגיאות לתרחיש מהסוג הזה, אפשר גם ליצור לולאת ניסיון חוזר לעבודות. אם מתרחשת שגיאה של מיצוי משאבים, המשימה מנסה שוב באופן אוטומטי עד שהמשאבים יהיו זמינים. כדי ליצור לולאת ניסיון חוזר, פועלים לפי תהליך העבודה הבא:
- יוצרים משימת Dataflow ומקבלים את מזהה המשימה.
- בודקים את סטטוס העבודה עד שהוא
RUNNINGאוFAILED.- אם סטטוס העבודה הוא
RUNNING, יוצאים מהלולאה של הניסיון החוזר. - אם סטטוס העבודה הוא
FAILED, משתמשים ב-Cloud Logging API כדי לשלוח שאילתה ליומני העבודה ולחפש את המחרוזתZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS. מידע נוסף זמין במאמר בנושא עבודה עם יומני צינורות.- אם היומנים לא מכילים את המחרוזת, יוצאים מלולאת הניסיון החוזר.
- אם היומנים מכילים את המחרוזת, צריך ליצור משימת Dataflow, לקבל את מזהה המשימה ולהפעיל מחדש את לולאת הניסיון החוזר.
- אם סטטוס העבודה הוא
לבסוף, מומלץ לפעול לפי השיטה המומלצת של הפצת המשאבים בין אזורים ואזורי זמינות שונים כדי למנוע שיבושים.
IP_SPACE_EXHAUSTED_WITH_DETAILS
Startup of the worker pool in REGION_NAME failed to bring up any of the desired NUMBER workers. ... IP_SPACE_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: IP space of 'projects/PROJECT_ID/regions/REGION_NAME/subnetworks/SUBNETWORK_NAME' is exhausted. Insufficient free IP addresses in the IP range 'IP_RANGE'. Consider expanding the current IP range or selecting an alternative IP range. If this is a secondary range, consider adding an additional secondary range.
השגיאה הזו מתרחשת כשלרשת המשנה שהוקצתה לעבודת Dataflow אין מספיק כתובות IP פנויות כדי להקצות את מספר מכונות ה-VM של העובדים שנדרש.
כדי לפתור את הבעיה, אפשר לנסות אחת מהאסטרטגיות הבאות:
- מרחיבים את טווח כתובות ה-IP הראשי של רשת המשנה.
- אם אתם משתמשים בטווח משני, מוסיפים טווח משני נוסף.
- בוחרים תת-רשת חלופית או טווח כתובות IP עם מספיק כתובות IP זמינות.
שגיאות תלות בזמן ריצה
כשמריצים משימת Dataflow שמשתמשת ב-Apache Beam SDK for Python עם טרנספורמציות חוצות-שפות, יכול להיות שהמשימה תיכשל עם שגיאה HTTP Error
403: Forbidden כשמורידים קובצי JAR מ-Maven Central.
הבעיה הזו נגרמת בגלל שינוי בספק ה-CDN של Maven Central, שחוסם בקשות מהספרייה urllib של Python שמשמשת את Apache Beam SDK.
כדי לפתור את הבעיה, צריך לשדרג לגרסה 2.69.0 ואילך של Apache Beam. אם אין לך אפשרות לשדרג, אפשר לנסות את הפתרונות לעקיפת הבעיה שמופיעים בקטע הזה.
תיקונים ב-Apache Beam 2.69.0 ואילך
גרסה Apache Beam 2.69.0 ואילך כוללת את התיקונים הבאים:
כתובת URL מותאמת אישית של מאגר Maven: אפשר לציין מאגר Maven מותאם אישית באמצעות אפשרות הצינור
--maven_repository_url. לדוגמה:--maven_repository_url https://maven-central.storage-download.googleapis.com/maven2/זיהוי סוכן משתמש: Apache Beam SDK שולח כותרת
User-Agentספציפית כדי למנוע חסימה של בקשות.
פתרונות עקיפים לגרסאות ישנות יותר של SDK
אם אתם לא יכולים לשדרג ל-Apache Beam 2.69.0 ואילך, אתם יכולים להשתמש באחד מהפתרונות הבאים:
- אריזה מראש של קובצי JAR במאגר מותאם אישית (מומלץ): אורזים מראש את קובצי ה-JAR הנדרשים בתמונת מאגר מותאם אישית. ממקמים את קובצי ה-JAR בספריית המטמון של Apache Beam (
/root/.apache_beam/cache/jars/) כדי למנוע את ההורדה שלהם על ידי ה-SDK בזמן הריצה. שימוש ברפליקציה של Maven של Google: משתמשים באפשרות הצינור
--expansion_serviceכדי להנחות את Apache Beam SDK להוריד את קובצי ה-JAR הנדרשים מהרפליקציה של Google של Maven Central. לדוגמה:--expansion_service https://maven-central.storage-download.googleapis.com/maven2/org/apache/beam/beam-sdks-java-extensions-schemaio-expansion-service/BEAM_VERSION/beam-sdks-java-extensions-schemaio-expansion-service-BEAM_VERSION.jarהעברת קובצי JAR ל-Cloud Storage: מורידים את קובצי ה-JAR הנדרשים, מאחסנים אותם במחסן ביניים (Stage) בקטגוריה של Cloud Storage ומזינים את הנתיב של קובץ ה-JAR ב-Cloud Storage לאפשרות
--expansion_serviceשל הפייפליין.
מופעים עם מאיצי אורחים לא תומכים במיגרציה פעילה
צינור Dataflow נכשל בשלב שליחת המשימה עם השגיאה הבאה:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
השגיאה הזו עשויה להתרחש כשמבקשים סוג מכונה של Worker שיש לה מאיצי חומרה, אבל לא מגדירים את Dataflow להשתמש במאיצים.
כדי לבקש מאיצי חומרה, משתמשים ב--worker_accelerator Dataflow
service option או בaccelerator
resource hint.
אם אתם משתמשים בתבניות Flex, אתם יכולים להשתמש באפשרות --additionalExperiments כדי לספק אפשרויות לשירות Dataflow. אם הפעולה בוצעה בצורה נכונה, האפשרות worker_accelerator תופיע בחלונית פרטי המשרה של המשרה במסוףGoogle Cloud .
מכסת הפרויקט… או כללי מדיניות של בקרת גישה שמונעים את הפעולה
השגיאה הבאה מתרחשת:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
השגיאה הזו מתרחשת בגלל אחת מהסיבות הבאות:
- חריגה מאחת המכסות של Compute Engine שעליהן מסתמכת יצירת העובדים של Dataflow.
- בארגון שלכם מוגדרים אילוצים שאוסרים על היבט מסוים בתהליך יצירת מכונת ה-VM, כמו החשבון שבו נעשה שימוש או האזור שמכוון.
כדי לפתור את הבעיה, מבצעים את השלבים הבאים לפתרון בעיות:
בדיקת היומן של מופע מכונת ה-VM
- עוברים אל כלי הצפייה ב-Cloud Logging
- בתפריט הנפתח Audited Resource, בוחרים באפשרות VM Instance.
- ברשימה הנפתחת All logs, בוחרים באפשרות compute.googleapis.com/activity_log.
- סורקים את היומן כדי למצוא רשומות שקשורות לכשל ביצירת מכונת VM.
בדיקת השימוש במכסות של Compute Engine
כדי לראות את השימוש במשאבי Compute Engine בהשוואה למכסות של Dataflow באזור היעד, מריצים את הפקודה הבאה:
gcloud compute regions describe [REGION]כדאי לבדוק את התוצאות של מקורות המידע הבאים כדי לראות אם יש חריגה מהמכסה:
- מעבדים (CPU)
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
במקרה הצורך, מבקשים לשנות את המכסה.
בדיקת המגבלות שקשורות למדיניות הארגון
- עוברים אל הדף 'מדיניות ארגונית'.
- בודקים את האילוצים שעשויים להגביל את יצירת המכונות הווירטואליות בחשבון שבו אתם משתמשים (כברירת מחדל, חשבון השירות של Dataflow) או באזור הטירגוט.
- אם יש לכם מדיניות שמגבילה את השימוש בכתובות IP חיצוניות, צריך להשבית את כתובות ה-IP החיצוניות עבור העבודה הזו. מידע נוסף על השבתה של כתובות IP חיצוניות זמין במאמר בנושא הגדרת גישה לאינטרנט וכללים של חומת אש.
תם פרק הזמן שהוקצב להמתנה לעדכון מהתהליך
כשמשימת Dataflow נכשלת, מופיעה השגיאה הבאה:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
יש כמה סיבות אפשריות לשגיאה הזו, כולל:
עומס יתר על העובדים
לפעמים מתרחשת שגיאת זמן קצוב לתפוגה כשהזיכרון או מרחב ההחלפה של העובד נגמרים. כדי לפתור את הבעיה, כדאי קודם לנסות להריץ את העבודה שוב. אם העבודה עדיין נכשלת ומופיעה אותה השגיאה, נסו להשתמש בעובד עם יותר זיכרון ומקום בדיסק. לדוגמה, מוסיפים את אפשרות ההפעלה הבאה של צינור העיבוד:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
שינוי סוג העובד עשוי להשפיע על העלות לחיוב. מידע נוסף זמין במאמר פתרון בעיות של שגיאות חוסר זיכרון ב-Dataflow.
השגיאה הזו יכולה להופיע גם אם הנתונים מכילים מקש קיצור. בתרחיש הזה, ניצול המעבד (CPU) גבוה בחלק מהעובדים במהלך רוב משך העבודה. עם זאת, מספר העובדים לא מגיע למספר המקסימלי המותר. מידע נוסף על מקשי קיצור ופתרונות אפשריים מופיע במאמר כתיבת צינורות Dataflow עם יכולת הרחבה.
פתרונות נוספים לבעיה הזו מפורטים במאמר זוהה מקש קיצור ....
Python: Global Interpreter Lock (GIL)
אם קוד Python שלכם קורא לקוד C/C++ באמצעות מנגנון התוסף של Python, כדאי לבדוק אם קוד התוסף משחרר את Python Global Interpreter Lock (GIL) בחלקים עתירי חישוב של הקוד שלא ניגשים למצב Python. אם ה-GIL לא משוחרר למשך זמן ממושך, יכול להיות שיוצגו הודעות שגיאה כמו: Unable to retrieve status info from SDK harness <...> within allowed time ו-SDK worker appears to be permanently unresponsive. Aborting the SDK.
הספריות שמסייעות באינטראקציות עם תוספים כמו Cython ו-PyBind כוללות פרימיטיבים לשליטה בסטטוס של GIL. אפשר גם לשחרר את ה-GIL באופן ידני ולהשיג אותו מחדש לפני החזרת השליטה למתורגמן Python באמצעות פקודות המאקרו Py_BEGIN_ALLOW_THREADS ו-Py_END_ALLOW_THREADS. מידע נוסף זמין במאמר Thread State and the Global Interpreter Lock במסמכי התיעוד של Python.
יכול להיות שאפשר לאחזר את ה-stacktrace של שרשור שמחזיק ב-GIL ב-worker של Dataflow שפועל באופן הבא:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
בצינורות עיבוד נתונים של Python, בהגדרת ברירת המחדל, מערכת Dataflow מניחה שכל תהליך Python שפועל על העובדים משתמש ביעילות בליבת vCPU אחת. אם קוד צינור הנתונים עוקף את המגבלות של GIL, למשל באמצעות ספריות שמיושמות ב-C++, יכול להיות שרכיבי העיבוד ישתמשו במשאבים מיותר מליבת vCPU אחת, ולעובדים לא יהיו מספיק משאבי CPU. כדי לפתור את הבעיה, צריך לצמצם את מספר השרשורים בעובדים.
הגדרה של DoFn שפועל לאורך זמן
אם אתם לא משתמשים ב-Runner v2, שיחה ארוכה אל DoFn.Setup עלולה להוביל לשגיאה הבאה:
Timed out waiting for an update from the worker
באופן כללי, מומלץ להימנע מפעולות שגוזלות זמן בתוך DoFn.Setup.
שגיאות חולפות בפרסום בנושא
כשעבודת הסטרימינג משתמשת במצב סטרימינג מסוג 'לפחות פעם אחת' ומפרסמת ב-Pub/Sub sink, השגיאה הבאה מופיעה ביומני העבודה:
There were transient errors publishing to topic
אם העבודה פועלת בצורה תקינה, השגיאה הזו לא מזיקה ואפשר להתעלם ממנה. Dataflow מנסה לשלוח מחדש את ההודעות ב-Pub/Sub באופן אוטומטי עם השהיה הולכת וגדלה.
אי אפשר לאחזר נתונים בגלל חוסר התאמה בין טוקנים למפתח
השגיאה הבאה מציינת שפריט העבודה שעובר עיבוד הוקצה מחדש לעובד אחר:
Unable to fetch data due to token mismatch for key
הבעיה הזו מתרחשת בדרך כלל במהלך התאמה אוטומטית לעומס (automatic scaling), אבל היא יכולה לקרות בכל שלב. המערכת תנסה לבצע שוב את כל הפעולות שהושפעו מהבעיה. אפשר להתעלם מהשגיאה הזו.
בעיות בתלות ב-Java
שיעורים וספריות לא תואמים עלולים לגרום לבעיות בתלות ב-Java. אם יש בעיות בתלות של Java בצינור, יכול להיות שתיתקלו באחת מהשגיאות הבאות:
-
NoClassDefFoundError: השגיאה הזו מתרחשת כשמחלקה שלמה לא זמינה במהלך זמן הריצה. הסיבה יכולה להיות בעיות בהגדרה הכללית או חוסר תאימות בין גרסת ה-protobuf של Beam לבין פרוטוקולי ה-proto שנוצרו על ידי לקוח (לדוגמה, הבעיה הזו).-
NoSuchMethodError: השגיאה הזו מתרחשת כשהמחלקה בנתיב המחלקה משתמשת בגרסה שלא מכילה את השיטה הנכונה, או כשחתימת השיטה השתנתה.
-
-
NoSuchFieldError: השגיאה הזו מתרחשת כשהמחלקה בנתיב המחלקה משתמשת בגרסה שאין בה שדה שנדרש במהלך זמן הריצה. -
FATAL ERROR in native method: השגיאה הזו מתרחשת כשאי אפשר לטעון תלות מובנית כמו שצריך. כשמשתמשים ב-uber JAR (מוצלל), לא כוללים ספריות שמשתמשות בחתימות (כמו Conscrypt) באותו JAR.
אם צינור הנתונים מכיל קוד והגדרות ספציפיים למשתמש, הקוד לא יכול להכיל גרסאות מעורבות של ספריות. אם אתם משתמשים בספרייה לניהול תלות, מומלץ להשתמש ב-Google Cloud Libraries BOM.
אם אתם משתמשים ב-Apache Beam SDK, כדי לייבא את ספריות ה-BOM הנכונות, צריך להשתמש ב-beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
מידע נוסף זמין במאמר ניהול יחסי תלות בצינורות ב-Dataflow.
InaccessibleObjectException ב-JDK 17 ואילך
כשמריצים צינורות עם Java Platform, Standard Edition Development Kit (JDK) מגרסה 17 ואילך, יכול להיות שתופיע השגיאה הבאה בקובצי היומן של העובד:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
הבעיה הזו מתרחשת כי החל מגרסה 9 של Java, נדרשות אפשרויות של מכונה וירטואלית (JVM) של Java עם מודול פתוח כדי לגשת לנתונים פנימיים של JDK. בגרסה Java 16 ואילך, תמיד נדרשות אפשרויות מודול JVM פתוחות כדי לגשת לנתונים פנימיים של JDK.
כדי לפתור את הבעיה, כשמעבירים מודולים לצינור עיבוד הנתונים של Dataflow כדי לפתוח אותו, צריך להשתמש בפורמט MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* עם אפשרות הצינור jdkAddOpenModules. הפורמט הזה מאפשר גישה לספרייה הנדרשת.
לדוגמה, אם השגיאה היא module java.base does not "opens java.lang" to
unnamed module @..., צריך לכלול את אפשרות צינור העיבוד הבאה כשמריצים את צינור העיבוד:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
מידע נוסף זמין במאמרי העזרה בנושא המחלקה DataflowPipelineOptions.
התקדמות בפריט עבודה של דיווח על שגיאות
בצינורות Java, אם אתם לא משתמשים ב-Runner V2, יכול להיות שתופיע השגיאה הבאה:
Error reporting workitem progress update to Dataflow service: ...
השגיאה הזו נגרמת בגלל חריגה שלא טופלה במהלך עדכון ההתקדמות של פריט עבודה, למשל במהלך פיצול של מקור. ברוב המקרים, אם קוד משתמש של Apache Beam
מייצר חריגה שלא טופלה, פריט העבודה נכשל, מה שגורם לצינור להכשל.עם זאת, חריגות ב-Source.split מדוכאות, כי החלק הזה של הקוד נמצא מחוץ לפריט עבודה. כתוצאה מכך, רק יומן שגיאות
נרשם.
השגיאה הזו בדרך כלל לא מזיקה אם היא מתרחשת רק לסירוגין. עם זאת,
מומלץ לטפל בחריגים בצורה מסודרת בתוך קוד Source.split.
שגיאות במחבר BigQuery
בקטעים הבאים מפורטות שגיאות נפוצות במחבר BigQuery, ומוסבר איך לפתור אותן או לבצע בהן פתרון בעיות.
quotaExceeded
כשמשתמשים במחבר BigQuery כדי לכתוב ל-BigQuery באמצעות הזנת זרם נתונים, תפוקת הכתיבה נמוכה מהצפוי, והשגיאה הבאה עשויה להתרחש:
quotaExceeded
יכול להיות שהתפוקה הנמוכה נובעת מכך שצינור הנתונים חורג ממכסת הזנת זרם הנתונים הזמינה של BigQuery. אם כן, הודעות שגיאה שקשורות למכסה מ-BigQuery יופיעו ביומני העובדים של Dataflow (צריך לחפש שגיאות quotaExceeded).
אם מופיעות שגיאות quotaExceeded, כדי לפתור את הבעיה:
- כשמשתמשים ב-Apache Beam SDK ל-Java, מגדירים את האפשרות
ignoreInsertIds()של BigQuery sink. - כשמשתמשים ב-Apache Beam SDK ל-Python, צריך להשתמש באפשרות
ignore_insert_ids.
ההגדרות האלה מאפשרות לכם להשתמש בנפח נתונים של עד 1GB לשנייה, לכל פרויקט, להזנת זרם נתונים ב-BigQuery. מידע נוסף על מגבלות שקשורות לביטול כפילויות אוטומטי של הודעות זמין במאמרי העזרה של BigQuery. כדי להגדיל את מכסת הזנת זרם הנתונים ב-BigQuery מעל 1GBps, שולחים בקשה דרך מסוףGoogle Cloud .
אם לא מופיעות שגיאות שקשורות למכסה ביומני העובדים, יכול להיות שהבעיה היא שהפרמטרים שקשורים לאיגוד או לאיגום ברירת המחדל לא מספקים מספיק מקביליות כדי שהצינור יתרחב. אפשר לשנות כמה הגדרות שקשורות למחבר Dataflow BigQuery כדי להשיג את הביצועים הרצויים כשכותבים ל-BigQuery באמצעות הוספות של נתונים בזמן אמת. לדוגמה, ב-Apache Beam SDK for Java, צריך לשנות את הערך של numStreamingKeys כך שיתאים למספר המקסימלי של העובדים, ולשקול להגדיל את הערך של insertBundleParallelism כדי להגדיר את המחבר של BigQuery כך שיכתוב ל-BigQuery באמצעות יותר שרשורים מקבילים.
למידע על ההגדרות שזמינות ב-Apache Beam SDK ל-Java, אפשר לעיין ב-BigQueryPipelineOptions. למידע על ההגדרות שזמינות ב-Apache Beam SDK ל-Python, אפשר לעיין ב-WriteToBigQuery transform.
rateLimitExceeded
כשמשתמשים במחבר BigQuery, מוצגת השגיאה הבאה:
rateLimitExceeded
השגיאה הזו מתרחשת אם נשלחות יותר מדי בקשות ל-API של BigQuery בפרק זמן קצר. ל-BigQuery יש מגבלות על מכסת השימוש לטווח קצר. יכול להיות שצינור עיבוד הנתונים של Dataflow יחרוג זמנית מהמכסה הזו. במקרה כזה, יכול להיות שבקשות API מצינור הנתונים של Dataflow אל BigQuery ייכשלו, וזה עלול לגרום לשגיאות rateLimitExceeded ביומני העובדים.
מערכת Dataflow מנסה שוב לבצע פעולות שנכשלו, כך שאפשר להתעלם מהשגיאות האלה. אם לדעתכם צינור הנתונים מושפע משגיאות, פנו אל Cloud Customer Care.rateLimitExceeded
שגיאות שונות
בקטעים הבאים מפורטות שגיאות שונות שאולי תיתקלו בהן, וגם שלבים לפתרון בעיות או לפתרון השגיאות.
לא ניתן להקצות sha384
העבודה פועלת בצורה תקינה, אבל השגיאה הבאה מופיעה ביומני העבודה:
ima: Can not allocate sha384 (reason: -2)
אם העבודה פועלת בצורה תקינה, השגיאה הזו לא מזיקה ואפשר להתעלם ממנה. לפעמים מתקבלת ההודעה הזו מקובצי הבסיס של worker VM. Dataflow מגיב באופן אוטומטי לבעיה הבסיסית ומטפל בה.
קיימת בקשה לשינוי רמת ההודעה הזו מ-WARN ל-INFO. מידע נוסף זמין במאמר הורדת רמת היומן של שגיאות ההפעלה של מערכת Dataflow ל-WARN או ל-INFO.
שגיאה בהפעלת הכלי לבדיקת פלאגינים דינמיים
העבודה פועלת בצורה תקינה, אבל השגיאה הבאה מופיעה ביומני העבודה:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
אם העבודה פועלת בצורה תקינה, השגיאה הזו לא מזיקה ואפשר להתעלם ממנה. השגיאה הזו מתרחשת כשעבודת Dataflow מנסה ליצור ספרייה ללא הרשאות הכתיבה הנדרשות, והמשימה נכשלת. אם העבודה מצליחה, יכול להיות שלא היה צורך בספרייה, או ש-Dataflow טיפל בבעיה הבסיסית.
קיימת בקשה לשינוי רמת ההודעה הזו מ-WARN ל-INFO. מידע נוסף זמין במאמר הורדת רמת היומן של שגיאות ההפעלה של מערכת Dataflow ל-WARN או ל-INFO.
אין אובייקט כזה: pipeline.pb
כשמפרסמים משרות באמצעות האפשרות JOB_VIEW_ALL, מופיעה השגיאה הבאה:
No such object: BUCKET_NAME/PATH/pipeline.pb
השגיאה הזו יכולה להתרחש אם מוחקים את הקובץ pipeline.pb מקבצי ההכנה של העבודה.
דילוג על סנכרון של פוד
העבודה פועלת בצורה תקינה, אבל אחת מהשגיאות הבאות מופיעה ביומני העבודה:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
או:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
אם העבודה שלכם פועלת בצורה תקינה, השגיאות האלה לא מזיקות ואפשר להתעלם מהן.
ההודעה container runtime status check may not have completed yet מופיעה כש-kubelet של Kubernetes מדלג על הסנכרון של הפודים כי הוא ממתין לאתחול של זמן הריצה של הקונטיינר. התרחיש הזה קורה מסיבות שונות, למשל כשהזמן הקצוב לתהליך של מארח הקונטיינר הסתיים לאחרונה או כשהוא מופעל מחדש.
אם ההודעה כוללת את PLEG is not healthy: pleg has yet to be
successful, kubelet מחכה שרכיב יוצר אירועים במחזור חיים של ה-Pod (PLEG) יהיה תקין לפני שהוא מסנכרן את ה-Pods. ה-PLEG אחראי ליצירת אירועים שמשמשים את kubelet למעקב אחרי מצב הפודים.
קיימת בקשה לשינוי רמת ההודעה הזו מ-WARN ל-INFO. מידע נוסף זמין במאמר הורדת רמת היומן של שגיאות ההפעלה של מערכת Dataflow ל-WARN או ל-INFO.
המלצות
הנחיות לגבי המלצות שנוצרות על ידי Dataflow Insights זמינות במאמר תובנות.