Questa pagina illustra le metriche della GPU supportate in Dataflow. Puoi utilizzare queste metriche per monitorare l'integrità e l'utilizzo della GPU. La maggior parte delle metriche è supportata in tutti i job Dataflow, ma alcune metriche richiedono una configurazione aggiuntiva per molti modelli di GPU.
Prerequisiti
Le metriche della GPU vengono raccolte solo dai job Dataflow che hanno richiesto esplicitamente le GPU. Per saperne di più, consulta Supporto GPU.
Panoramica
Sebbene Dataflow riporti molte metriche della GPU, le principali sono la memoria totale e utilizzata, che sono equivalenti alle metriche della RAM, e l'attività e l'occupazione del multiprocessore streaming (SM), che sono gli equivalenti più vicini alle metriche della CPU di Dataflow. Altre metriche sono trattate in metriche comuni e metriche GPM.
Per impostazione predefinita, vengono segnalate la memoria totale e utilizzata di ogni dispositivo GPU nel job. Nell'interfaccia di monitoraggio di Dataflow, queste metriche vengono visualizzate in "Utilizzo GPU di base". Queste metriche non sono le stesse di "Percentuale di accesso alla memoria", che si trova anche nelle metriche GPU di base, ma riportano la percentuale di tempo in cui è stata eseguita l'accesso alla memoria del dispositivo GPU.
L'attività SM e l'occupazione SM sono metriche GPM. Queste metriche non sono supportate sui dispositivi P4 e P100 e sono supportate per impostazione predefinita sui dispositivi H100 e versioni successive. Per tutti gli altri dispositivi, come T4 e L4, è necessaria una configurazione aggiuntiva. Per i passaggi per abilitarle, consulta Raccolta GPM. Se raccolte nel job, queste metriche si trovano in "Utilizzo GPM GPU" nell'interfaccia di monitoraggio di Dataflow.
Nozioni di base sulle metriche della GPU di Dataflow
Tutte le metriche della GPU vengono inviate dai worker Dataflow a Cloud Monitoring. Le metriche per dispositivo sono disponibili in dataflow.googleapis.com/worker/accelerator/gpu. Tutte queste metriche sono raggruppate in categorie generali, come utilizzo o temperatura, e hanno tutte le seguenti etichette:
- device_uuid: identifica in modo univoco il dispositivo GPU indipendentemente dal worker o dalla pipeline.
- device_number: il numero assegnato al dispositivo nel worker nell' intervallo [0, N), dove N è il numero di dispositivi GPU nel worker.
- device_model: il modello della GPU, ad esempio "Tesla T4".
device_uuid e device_model sono indipendenti dal worker e sono sempre gli stessi per lo stesso dispositivo fisico. device_number è legato al modo in cui viene identificato nel worker.
Metriche della GPU comuni per Dataflow
Le metriche comuni vengono riportate da ogni job Dataflow con GPU. In Monitoring, utilizzano tutte il seguente formato:
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
La tabella seguente mostra ogni metrica e la relativa categoria, nome, unità e scopo.
| Metrica | Categoria | Nome | Unità | Descrizione |
|---|---|---|---|---|
| Percentuale di esecuzione del kernel | utilizzo | device_kernel_runtime | Percentuale | La percentuale di tempo in cui almeno un kernel è stato eseguito sulla GPU. Questo indica solo che la GPU è stata utilizzata, non se le sue risorse di elaborazione vengono utilizzate in modo efficiente. |
| Percentuale di accesso alla memoria | utilizzo | device_memory_access | Percentuale | La percentuale di tempo in cui è stata letta o scritta la memoria del dispositivo. Questo indica solo che è stata eseguita l'accesso alla memoria, non la percentuale di memoria in uso. |
| Limite di memoria | memoria | device_limit | MiB | La quantità di memoria disponibile sulla GPU. |
| Utilizzo memoria | memoria | device_usage | MiB | La quantità di memoria utilizzata dalla GPU. Sono inclusi sia la memoria utilizzata dal job Dataflow sia la memoria riservata per il firmware, quindi è previsto un certo utilizzo anche se non è ancora stata trasferita memoria alla GPU. |
| Errori ECC volatili correggibili | memory/ecc/volatile | device_correctable_total | Conteggio | Il numero di errori ECC correggibili (a bit singolo) dall'ultimo ricaricamento del driver. Per Dataflow, il ricaricamento del driver avviene solo all'avvio del worker, quindi è equivalente agli errori durante il ciclo di vita del worker. |
| Errori ECC volatili non correggibili | memory/ecc/volatile | device_uncorrectable_total | Conteggio | Il numero di errori ECC non correggibili (a doppio bit) dall'ultimo ricaricamento del driver. Per Dataflow, il ricaricamento del driver avviene solo all'avvio del worker, quindi è equivalente agli errori durante il ciclo di vita del worker. |
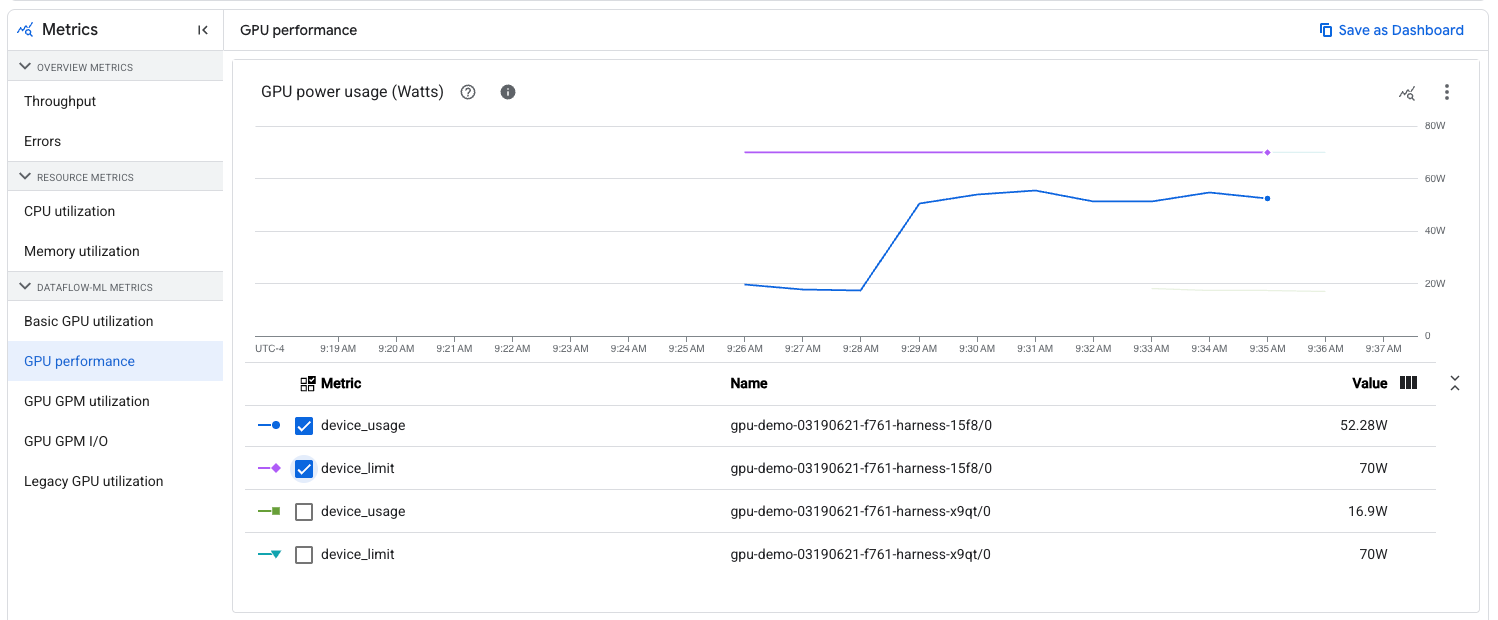
| Limite di alimentazione | alimentazione | device_limit | Watt | La quantità massima di energia che il dispositivo è impostato per utilizzare. Dataflow non modifica questo valore rispetto a quello predefinito. |
| Utilizzo avanzato | alimentazione | device_usage | Watt | La quantità di energia utilizzata dal dispositivo. |
| Temperatura attuale | temperatura | device_current | Celsius | La temperatura attuale della GPU. |
| Temperatura di funzionamento massima | temperatura | device_max_op | Celsius | La temperatura al di sotto della quale deve rimanere la GPU. Se la temperatura attuale supera questo valore, i driver della GPU tenteranno di raffreddare la GPU fino a quando non sarà al di sotto di questa temperatura. Dataflow non controlla questo valore. |
| Temperatura di rallentamento | temperatura | device_slowdown | Celsius | La temperatura alla quale la GPU inizierà a limitare la frequenza. Se la temperatura attuale supera questo valore, dovresti prevedere un calo delle prestazioni fino a quando non si raffredda. Dataflow non controlla questo valore. |
| Temperatura di spegnimento | temperatura | device_shutdown | Celsius | La temperatura alla quale la GPU si spegnerà. Se la temperatura attuale supera questo valore, il dispositivo non sarà più disponibile. Dataflow non controlla questa temperatura e non tenta attivamente di recuperare le GPU che si sono arrestate a causa di una temperatura eccessivamente elevata. |
| Clock SM attuale | clock | device_sm_current | MHz | La velocità attuale del clock SM. Se la temperatura supera la soglia di rallentamento, questo valore potrebbe diminuire nell'ambito della limitazione della frequenza relativa al raffreddamento. |
| Clock SM massimo | clock | device_sm_max | MHz | La velocità massima del clock SM. |
| Clock di memoria attuale | clock | device_memory_current | MHz | La velocità attuale del clock di memoria. Se la temperatura supera la soglia di rallentamento, questo valore potrebbe diminuire nell'ambito della limitazione della frequenza relativa al raffreddamento. |
| Clock di memoria massimo | clock | device_memory_max | MHz | La velocità massima del clock di memoria. |
Metriche GPM per Dataflow
Dataflow offre un certo supporto per le metriche GPM. Il livello di supporto dipende dal modello della GPU e dalla configurazione dell'acceleratore. Per impostazione predefinita, la maggior parte dei job Dataflow con GPU richiede una configurazione aggiuntiva.
Le metriche GPM seguono le stesse nozioni di base delle metriche comuni.
Metriche supportate
Analogamente alle metriche comuni, i percorsi delle metriche GPM hanno il seguente formato:
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
Alcune di queste metriche rientrano nella stessa categoria di alcune metriche comuni.
| Metrica | Categoria | Nome | Unità | Descrizione |
|---|---|---|---|---|
| Attività SM | utilizzo | device_sm_activity | Percentuale | La percentuale di tempo in cui un warp è stato attivo su un SM, calcolata in media in tutti gli SM del dispositivo. È simile alla percentuale di esecuzione del kernel, ma offre un'immagine più granulare che mostra meglio se le risorse della GPU vengono utilizzate in modo efficiente. NVIDIA definisce l'utilizzo efficace come 80% o più, mentre 50% o meno è un utilizzo inefficace. |
| Occupazione SM | utilizzo | device_sm_occupancy | Percentuale | La percentuale di warp attivi sul dispositivo rispetto al massimo. I job con limiti di memoria dovrebbero avere un'occupazione maggiore rispetto ai job con limiti di calcolo e la metrica Percentuale di accesso alla memoria può fornire informazioni in merito. Ulteriori dettagli sono disponibili nella documentazione NVIDIA sull'occupazione raggiunta. |
| Attività pipe Tensor | utilizzo | device_tensor_pipe_activity | Percentuale | La percentuale di tempo in cui è stata utilizzata la pipe Tensor Core. Valori più elevati indicano un maggiore utilizzo dei Tensor Core della GPU, che sono importanti per le operazioni con matrici. |
| Attività pipe FP64 | utilizzo | device_fp64_pipe_activity | Percentuale | La percentuale di tempo in cui è stata utilizzata la pipe FP64 Core. Valori più elevati indicano un maggiore utilizzo dei Core FP64 della GPU, che gestiscono le operazioni scalari di valori a virgola mobile a 64 bit. |
| Attività pipe FP32 | utilizzo | device_fp32_pipe_activity | Percentuale | La percentuale di tempo in cui è stata utilizzata la pipe FP32 Core. Valori più elevati indicano un maggiore utilizzo dei Core FP32 della GPU, che gestiscono le operazioni scalari di valori a virgola mobile a 32 bit. |
| Attività pipe FP16 | utilizzo | device_fp16_pipe_activity | Percentuale | La percentuale di tempo in cui è stata utilizzata la pipe FP16. A differenza di FP64 e FP32, che sono associati rispettivamente ai Core CUDA a 64 bit e 32 bit, FP16 è associato all'utilizzo delle funzionalità di precisione a metà dei Tensor Core. |
| Lettura PCIe | pcie | device_read | MiB/s | La velocità di lettura dei dati dalla GPU dalla VM host tramite PCIe. |
| Trasferimento PCIe | pcie | device_transfer | MiB/s | La velocità di trasferimento dei dati dalla GPU alla VM host tramite PCIe. |
| Lettura NVLink | nvlink | device_read | MiB/s | La velocità di lettura dei dati dalla GPU tramite NVLink. Poiché NVLink copre solo la comunicazione GPU-GPU, questa metrica non è pertinente se ogni worker ha una sola GPU. |
| Trasferimento NVLink | nvlink | device_transfer | MiB/s | La velocità di trasferimento dei dati dalla GPU tramite NVLink. Poiché NVLink copre solo la comunicazione GPU-GPU, questa metrica non è pertinente se ogni worker ha una sola GPU. |
Raccolta delle metriche GPM
Per impostazione predefinita, tutti i job Dataflow con GPU che utilizzano l'architettura Hopper o versioni successive (ad es. H100, H100 Mega) raccolgono le metriche GPM, quindi non è necessaria alcuna configurazione aggiuntiva. Tuttavia, i job che utilizzano l'architettura Pascal o versioni precedenti (come P4 e P100) non supportano queste metriche.
Per tutti gli altri modelli, la raccolta di queste metriche richiede l'aggiunta di install-gke-dcgm-exporter alla configurazione dell'acceleratore worker. Ad esempio:
--experiment="worker_accelerator=type:TYPE;count:COUNT;install-nvidia-driver;install-gke-dcgm-exporter"
Questo flag installa un equivalente gestito da GKE di NVIDIA DCGM-exporter. I seguenti tipi supportano questa opzione:
- nvidia-l4
- nvidia-tesla-a100
- nvidia-a100-80gb
- nvidia-tesla-t4
- nvidia-tesla-v100
Se viene fornito un altro tipo, il servizio Dataflow restituisce un errore durante la creazione del job. Questo controllo ti aiuta a evitare di eseguire il container sui job in cui non è utile per la raccolta delle metriche.
Metriche legacy
In Monitoring, potresti vedere due metriche denominate dataflow.googleapis.com/job/gpu_utilization e dataflow.googleapis.com/job/gpu_memory_utilization. Queste metriche sono simili
a percentuale di esecuzione del kernel e percentuale di accesso alla memoria
rispettivamente, ma i worker le riportano calcolando la media delle GPU nel worker. Ti consigliamo di utilizzare gli equivalenti per dispositivo, soprattutto se i worker sono configurati per avere più di una GPU.
UI di Dataflow
Se il job Dataflow ha GPU collegate ai worker, le metriche dovrebbero essere visualizzate nella scheda "Metriche job" della pagina del job, nella categoria "Dataflow ML". Questa categoria non viene visualizzata nei job senza GPU e richiede alcuni secondi per il caricamento, perché verifica innanzitutto che le metriche siano pertinenti al job.
Le seguenti sottocategorie vengono visualizzate in "Dataflow ML":
| Sottocategoria | Metriche | Condizioni |
|---|---|---|
| Utilizzo GPU di base | Percentuale di esecuzione del kernel Percentuale di accesso alla memoria Memoria totale/utilizzata |
Tutti i job GPU |
| Prestazioni GPU | Assorbimento/limite di potenza Lettura/limiti di temperatura Clock SM attuale/massimo Clock di memoria attuale/massimo Errori ECC volatili correggibili/non correggibili |
Tutti i job GPU |
| Utilizzo GPM GPU | Attività SM Occupazione SM Attività pipe CUDA/Tensor |
Metriche GPM abilitate |
| I/O GPM GPU | Lettura/trasferimento PCIe Lettura/trasferimento NVLink |
Metriche GPM abilitate |
| Utilizzo GPU legacy | Metriche legacy | Tutti i job GPU |
Quando visualizzi le metriche non legacy, puoi filtrare i grafici in base a un nome worker e a un numero di dispositivo GPU specifici. Il nome del worker è lo stesso della VM se visualizzato in Compute Engine. Il numero del dispositivo GPU è lo stesso delle etichette delle metriche. Puoi utilizzare questo filtro per controllare le metriche su un dispositivo GPU specifico, ad esempio per vedere quanto è vicino il suo utilizzo di energia rispetto al limite: