Cette page couvre les métriques GPU compatibles avec Dataflow. Vous pouvez utiliser ces métriques pour surveiller l'état et l'utilisation du GPU. La plupart des métriques sont compatibles avec toutes les tâches Dataflow, mais certaines nécessitent une configuration supplémentaire pour de nombreux modèles de GPU.
Prérequis
Les métriques GPU ne sont collectées que par les tâches Dataflow qui ont explicitement demandé des GPU. Pour en savoir plus, consultez la section Compatibilité avec les GPU.
Présentation
Bien que Dataflow signale de nombreuses métriques GPU, les principales sont la mémoire totale et la mémoire utilisée, qui sont équivalentes aux métriques RAM, ainsi que l'activité et l'occupation du multiprocesseur de flux (SM), qui sont les équivalents les plus proches des métriques CPU Dataflow. D'autres métriques sont abordées dans les sections Métriques courantes et Métriques GPM.
La mémoire totale et la mémoire utilisée de chaque appareil GPU de la tâche sont signalées par défaut. Dans l'interface de surveillance Dataflow, elles apparaissent sous "Utilisation GPU de base". Ces métriques ne sont pas les mêmes que "Pourcentage d'accès à la mémoire", qui se trouve également sous les métriques GPU de base, mais qui indique le pourcentage de temps pendant lequel la mémoire de l'appareil GPU a été consultée.
L'activité et l'occupation du SM sont des métriques GPM. Ces métriques ne sont pas compatibles avec les appareils P4 et P100, mais le sont par défaut avec les appareils H100 et versions ultérieures. Pour tous les autres appareils, tels que les appareils T4 et L4, une configuration supplémentaire est nécessaire. Pour savoir comment les activer, consultez la section Collecte GPM. Si elles sont collectées sur la tâche, ces métriques se trouvent sous "Utilisation du GPM du GPU" dans l'interface de surveillance Dataflow.
Principes de base des métriques GPU Dataflow
Toutes les métriques GPU sont envoyées par les nœuds de calcul Dataflow à Cloud Monitoring. Les métriques par appareil se trouvent sous dataflow.googleapis.com/worker/accelerator/gpu. Toutes ces métriques sont regroupées dans des catégories générales, telles que l'utilisation ou la température, et elles comportent toutes les libellés suivants :
- device_uuid : identifie de manière unique l'appareil GPU, quel que soit le nœud de calcul ou le pipeline.
- device_number : numéro attribué à l'appareil sur le nœud de calcul dans la plage [0, N), où N est le nombre d'appareils GPU sur le nœud de calcul.
- device_model : modèle du GPU, tel que "Tesla T4".
device_uuid et device_model sont indépendants du nœud de calcul et sont toujours identiques pour le même appareil physique. device_number est lié à la façon dont il est identifié sur ce nœud de calcul.
Métriques GPU courantes pour Dataflow
Les métriques courantes sont signalées par chaque tâche Dataflow avec des GPU. Dans Monitoring, elles utilisent toutes le format suivant :
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
Le tableau suivant présente chaque métrique, ainsi que sa catégorie, son nom, son unité et son objectif.
| Métrique | Catégorie | Nom | Unité | Description |
|---|---|---|---|---|
| Pourcentage d'exécution du kernel | utilisation | device_kernel_runtime | Pourcentage | Pourcentage de temps pendant lequel au moins un kernel s'est exécuté sur le GPU. Cela indique uniquement que le GPU a été utilisé, et non si ses ressources de traitement sont utilisées efficacement. |
| Pourcentage d'accès à la mémoire | utilisation | device_memory_access | Pourcentage | Pourcentage de temps pendant lequel des données ont été lues ou écrites dans la mémoire de l'appareil. Cela indique uniquement que la mémoire a été consultée, et non le pourcentage de mémoire utilisée. |
| Limite de mémoire | mémoire | device_limit | MiB | Quantité de mémoire disponible sur le GPU. |
| Utilisation de la mémoire | mémoire | device_usage | MiB | Quantité de mémoire utilisée par le GPU. Cela inclut à la fois la mémoire utilisée par la tâche Dataflow et la mémoire réservée au micrologiciel. Par conséquent, une certaine utilisation est attendue même si aucune mémoire n'a encore été transférée vers le GPU. |
| Erreurs ECC volatiles corrigibles | mémoire/ecc/volatile | device_correctable_total | Nombre | Nombre d'erreurs ECC corrigibles (à un bit) depuis le dernier rechargement du pilote. Pour Dataflow, le rechargement du pilote ne se produit qu'au démarrage du nœud de calcul. Cette valeur est donc équivalente aux erreurs survenues pendant la durée de vie du nœud de calcul. |
| Erreurs ECC volatiles non corrigibles | mémoire/ecc/volatile | device_uncorrectable_total | Nombre | Nombre d'erreurs ECC non corrigibles (à deux bits) depuis le dernier rechargement du pilote. Pour Dataflow, le rechargement du pilote ne se produit qu'au démarrage du nœud de calcul. Cette valeur est donc équivalente aux erreurs survenues pendant la durée de vie du nœud de calcul. |
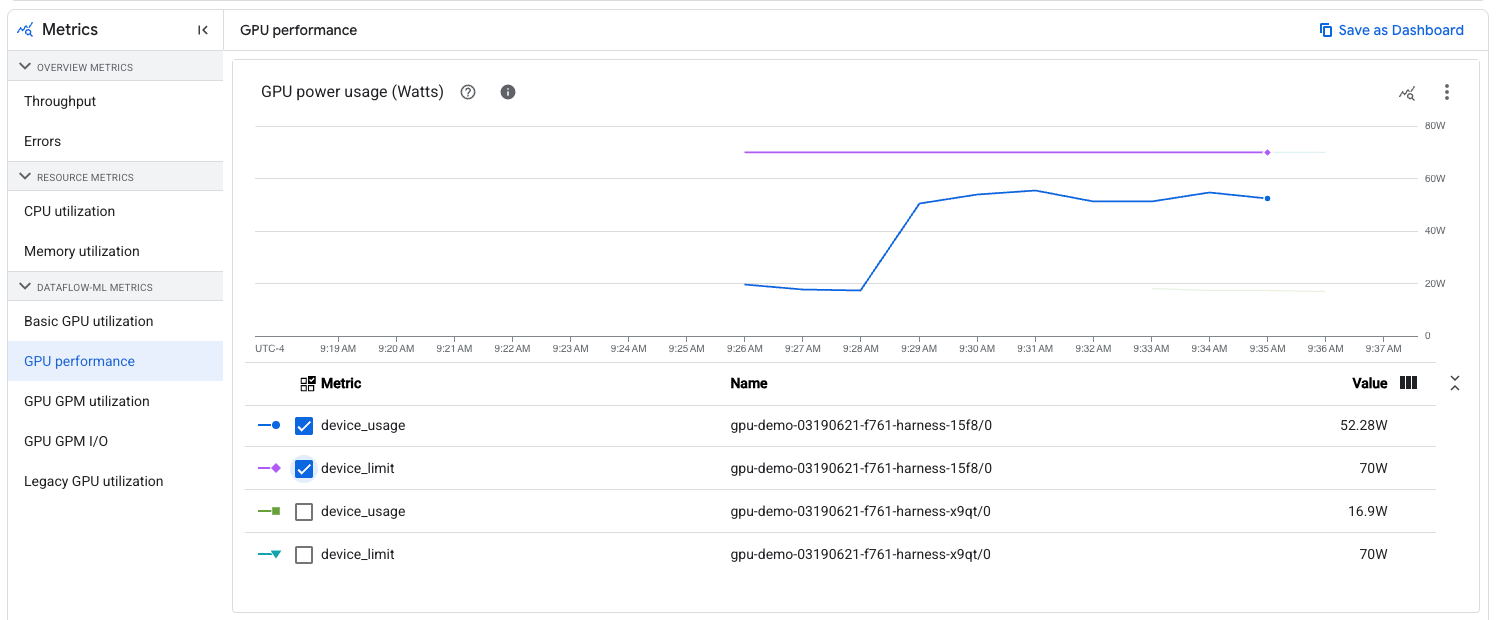
| Limite de puissance | power | device_limit | Watts | Quantité maximale d'énergie que l'appareil est configuré pour utiliser. Dataflow ne modifie pas la valeur par défaut. |
| Consommation électrique | power | device_usage | Watts | Quantité d'énergie utilisée par l'appareil. |
| Température actuelle | température | device_current | Celsius | Température actuelle du GPU. |
| Température maximale de fonctionnement | température | device_max_op | Celsius | Température à laquelle le GPU doit rester. Si la température actuelle dépasse cette valeur, les pilotes GPU tentent de refroidir le GPU jusqu'à ce qu'il soit en dessous de cette température. Dataflow ne contrôle pas cela. |
| Température de ralentissement | température | device_slowdown | Celsius | Température à laquelle le GPU commence à limiter la bande passante. Si la température actuelle dépasse cette valeur, vous devez vous attendre à une dégradation des performances jusqu'à ce qu'elle refroidisse. Dataflow ne contrôle pas cela. |
| Température d'arrêt | température | device_shutdown | Celsius | Température à laquelle le GPU s'éteint. Si la température actuelle dépasse cette valeur, l'appareil devient indisponible. Dataflow ne contrôle pas cette température et ne tente pas activement de récupérer les GPU qui se sont arrêtés en raison d'une température excessivement élevée. |
| Horloge SM actuelle | horloge | device_sm_current | MHz | Vitesse actuelle de l'horloge SM. Si la température dépasse le seuil de ralentissement, cette valeur peut diminuer dans le cadre de la limitation de la bande passante liée au refroidissement. |
| Horloge SM maximale | horloge | device_sm_max | MHz | Vitesse maximale de l'horloge SM. |
| Horloge mémoire actuelle | horloge | device_memory_current | MHz | Vitesse actuelle de l'horloge mémoire. Si la température dépasse le seuil de ralentissement, cette valeur peut diminuer dans le cadre de la limitation de la bande passante liée au refroidissement. |
| Horloge mémoire maximale | horloge | device_memory_max | MHz | Vitesse maximale de l'horloge mémoire. |
Métriques GPM pour Dataflow
Dataflow offre une certaine compatibilité avec les métriques GPM. Le niveau de compatibilité dépend du modèle de GPU et de la configuration de l'accélérateur. Par défaut, la plupart des tâches Dataflow avec des GPU nécessitent une configuration supplémentaire.
Les métriques GPM suivent les mêmes principes de base que les métriques courantes.
Métriques acceptées
Comme pour les métriques courantes, les chemins des métriques GPM ont le format suivant :
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
Certaines de ces métriques appartiennent à la même catégorie que certaines métriques courantes.
| Métrique | Catégorie | Nom | Unité | Description |
|---|---|---|---|---|
| Activité du SM | utilisation | device_sm_activity | Pourcentage | Pourcentage de temps pendant lequel un warp a été actif sur le SM (moyenne pour l'ensemble des SM de l'appareil). Cette valeur est semblable au pourcentage d'exécution du kernel, mais elle offre une image plus précise qui indique mieux si les ressources du GPU sont utilisées efficacement. NVIDIA définit une utilisation efficace comme étant égale ou supérieure à 80 %, et une utilisation inefficace comme étant égale ou inférieure à 50 %. |
| Occupation du SM | utilisation | device_sm_occupancy | Pourcentage | Pourcentage de warps actifs sur l'appareil par rapport au nombre maximal. Les tâches limitées par la mémoire doivent avoir une occupation plus élevée que les tâches limitées par le calcul. La métrique "Pourcentage d'accès à la mémoire" peut fournir des informations à ce sujet. Pour en savoir plus, consultez la documentation NVIDIA sur l'occupation atteinte. |
| Activité du chemin de transfert Tensor | utilisation | device_tensor_pipe_activity | Pourcentage | Pourcentage de temps pendant lequel le chemin de transfert Tensor Core a été utilisé. Des valeurs plus élevées indiquent une plus grande utilisation des Tensor Cores du GPU, qui sont importants pour les opérations matricielles. |
| Activité du chemin de transfert FP64 | utilisation | device_fp64_pipe_activity | Pourcentage | Pourcentage de temps pendant lequel le chemin de transfert FP64 Core a été utilisé. Des valeurs plus élevées indiquent une plus grande utilisation des FP64 Cores du GPU, qui gèrent les opérations scalaires de valeurs à virgule flottante de 64 bits. |
| Activité du chemin de transfert FP32 | utilisation | device_fp32_pipe_activity | Pourcentage | Pourcentage de temps pendant lequel le chemin de transfert FP32 Core a été utilisé. Des valeurs plus élevées indiquent une plus grande utilisation des FP32 Cores du GPU, qui gèrent les opérations scalaires de valeurs à virgule flottante de 32 bits. |
| Activité du chemin de transfert FP16 | utilisation | device_fp16_pipe_activity | Pourcentage | Pourcentage de temps pendant lequel le chemin de transfert FP16 a été utilisé. Contrairement à FP64 et FP32, qui sont associés respectivement aux cœurs CUDA de 64 bits et de 32 bits, FP16 est associé à l'utilisation des capacités de demi-précision des Tensor Cores. |
| Lecture PCIe | pcie | device_read | Mio/s | Débit de données lues par le GPU à partir de la VM hôte via PCIe. |
| Transfert PCIe | pcie | device_transfer | Mio/s | Débit de transfert de données du GPU vers la VM hôte via PCIe. |
| Lecture NVLink | nvlink | device_read | Mio/s | Débit de données lues par le GPU via NVLink. Étant donné que NVLink ne couvre que la communication entre les GPU, cela n'est pas pertinent si chaque nœud de calcul ne dispose que d'un seul GPU. |
| Transfert NVLink | nvlink | device_transfer | Mio/s | Débit de transfert de données du GPU via NVLink. Étant donné que NVLink ne couvre que la communication entre les GPU, cela n'est pas pertinent si chaque nœud de calcul ne dispose que d'un seul GPU. |
Collecte des métriques GPM
Toutes les tâches Dataflow avec des GPU utilisant l'architecture Hopper ou une version ultérieure (par exemple, H100, H100 Mega) collectent les métriques GPM par défaut. Aucune configuration supplémentaire n'est donc nécessaire. Toutefois, les tâches utilisant l'architecture Pascal ou une version antérieure (telles que P4 et P100) ne sont pas compatibles avec ces métriques.
Pour tous les autres modèles, la collecte de ces métriques nécessite d'ajouter install-gke-dcgm-exporter à la configuration de l'accélérateur du nœud de calcul. Exemple :
--experiment="worker_accelerator=type:TYPE;count:COUNT;install-nvidia-driver;install-gke-dcgm-exporter"
Cet indicateur installe un équivalent géré par GKE de l' exportateur DCGM NVIDIA. Les types suivants sont compatibles avec cette option :
- nvidia-l4
- nvidia-tesla-a100
- nvidia-a100-80gb
- nvidia-tesla-t4
- nvidia-tesla-v100
Si un autre type est fourni, le service Dataflow renvoie une erreur lors de la création de la tâche. Cette vérification vous permet d'éviter d'exécuter le conteneur sur des tâches où il n'aide pas à la collecte de métriques.
Anciennes métriques
Dans Monitoring, vous pouvez voir deux métriques nommées dataflow.googleapis.com/job/gpu_utilization et dataflow.googleapis.com/job/gpu_memory_utilization. Ces métriques sont semblables
à pourcentage d'exécution du kernel et pourcentage d'accès à la mémoire
respectivement, mais les nœuds de calcul les signalent en calculant la moyenne des GPU sur le nœud de calcul. Nous vous recommandons d'utiliser les équivalents par appareil, en particulier si les nœuds de calcul sont configurés pour avoir plusieurs GPU.
UI Dataflow
Si la tâche Dataflow comporte des GPU associés à ses nœuds de calcul, les métriques doivent s'afficher dans l'onglet "Métriques de la tâche" de la page de la tâche, sous la catégorie "Dataflow ML". Cette catégorie n'apparaît pas sur les tâches sans GPU et prend quelques secondes à charger, car elle vérifie d'abord que les métriques sont pertinentes pour la tâche.
Les sous-catégories suivantes s'affichent sous "Dataflow ML" :
| Sous-catégorie | Métriques | Conditions |
|---|---|---|
| Utilisation GPU de base | Pourcentage d'exécution du kernel Pourcentage d'accès à la mémoire Mémoire totale/utilisée |
Toutes les tâches GPU |
| Performances du GPU | Consommation/limite de puissance Lecture/limites de température Horloge SM actuelle/maximale Horloge mémoire actuelle/maximale Erreurs ECC volatiles corrigibles/non corrigibles |
Toutes les tâches GPU |
| Utilisation du GPM du GPU | Activité du SM Occupation du SM Activité du chemin de transfert CUDA/Tensor |
Métriques GPM activées |
| E/S du GPM du GPU | Lecture/transfert PCIe Lecture/transfert NVLink |
Métriques GPM activées |
| Utilisation de l'ancien GPU | Anciennes métriques | Toutes les tâches GPU |
Lorsque vous affichez des métriques non héritées, vous pouvez filtrer les graphiques en fonction d'un nom de nœud de calcul et d'un numéro d'appareil GPU spécifiques. Le nom du nœud de calcul est le même que celui de la VM s'il est affiché sous Compute Engine. Le numéro de l'appareil GPU est le même que celui des libellés de métriques. Vous pouvez utiliser ce filtrage pour vérifier les métriques sur un appareil GPU spécifique, par exemple pour voir à quel point sa consommation électrique est proche de sa limite :