
En esta página, se describe cómo administrar el control de acceso cuando implementas y ejecutas una canalización que usa clústeres de Managed Service para Apache Spark en otro proyecto de Google Cloud .
Situación
De forma predeterminada, cuando se inicia una instancia de Cloud Data Fusion en un proyecto deGoogle Cloud , se implementan y ejecutan canalizaciones con clústeres de Managed Service para Apache Spark dentro del mismo proyecto. Sin embargo, es posible que tu organización te exija usar clústeres en otro proyecto. En este caso de uso, debes administrar el acceso entre los proyectos. En la siguiente página, se describe cómo puedes cambiar la configuración de referencia (predeterminada) y aplicar los controles de acceso adecuados.
Antes de comenzar
Para comprender las soluciones de este caso de uso, necesitas el siguiente contexto:
- Conocimiento de los conceptos básicos de Cloud Data Fusion
- Conocimiento de Identity and Access Management (IAM) para Cloud Data Fusion
- Conocimientos sobre las herramientas de redes de Cloud Data Fusion
Suposiciones y alcance
Este caso de uso tiene los siguientes requisitos:
- Una instancia privada de Cloud Data Fusion Por motivos de seguridad, una organización puede requerir que uses este tipo de instancia.
- Es una fuente y un receptor de BigQuery.
- Control de acceso con IAM, no con control de acceso basado en roles (RBAC).
Solución
Esta solución compara la arquitectura y la configuración de referencia con las específicas del caso de uso.
Arquitectura
En los siguientes diagramas, se compara la arquitectura del proyecto para crear una instancia de Cloud Data Fusion y ejecutar canalizaciones cuando usas clústeres en el mismo proyecto (referencia) y en un proyecto diferente a través de la VPC del proyecto de usuario.
Arquitectura de referencia
En este diagrama, se muestra la arquitectura de referencia de los proyectos:
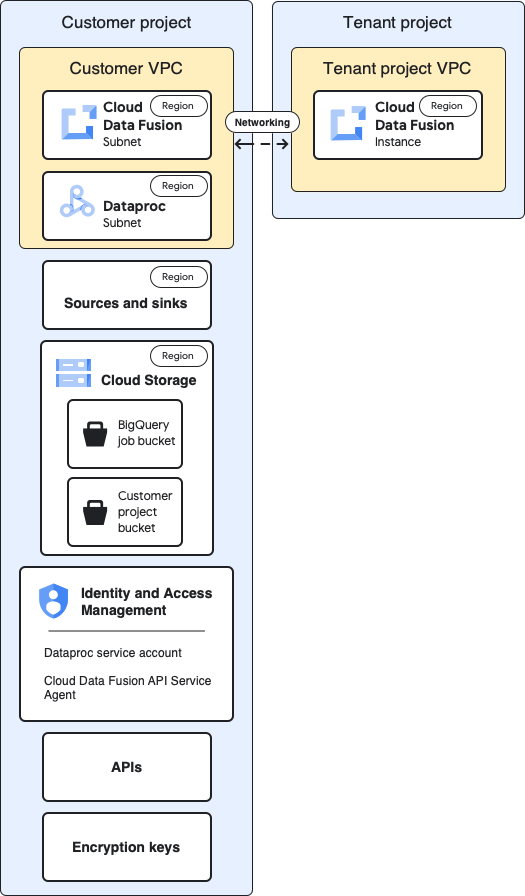
Para la configuración de referencia, crearás una instancia privada de Cloud Data Fusion y ejecutarás una canalización sin personalización adicional:
- Usas uno de los perfiles de procesamiento integrados.
- El origen y el receptor están en el mismo proyecto que la instancia.
- No se otorgaron roles adicionales a ninguna de las cuentas de servicio.
Para obtener más información sobre los proyectos de usuario y de cliente, consulta Redes.
Arquitectura de casos de uso
En este diagrama, se muestra la arquitectura del proyecto cuando usas clústeres en otro proyecto:

Parámetros de configuración
En las siguientes secciones, se comparan las configuraciones de referencia con las configuraciones específicas del caso de uso para utilizar clústeres de Managed Service for Apache Spark en un proyecto diferente a través de la VPC predeterminada del proyecto de inquilino.
En las siguientes descripciones de casos de uso, el proyecto del cliente es donde se ejecuta la instancia de Cloud Data Fusion y el proyecto del servicio administrado para Apache Spark es donde se inicia el clúster del servicio administrado para Apache Spark.
VPC y instancia del proyecto de usuario
| Modelo de referencia | Caso de uso |
|---|---|
En el diagrama de arquitectura de referencia anterior, el proyecto del arrendatario
contiene los siguientes componentes:
|
No se requiere ninguna configuración adicional para este caso de uso. |
Proyecto del cliente
| Modelo de referencia | Caso de uso |
|---|---|
| Tu proyecto Google Cloud es donde implementas y ejecutas canalizaciones. De forma predeterminada, los clústeres de Managed Service for Apache Spark se inician en este proyecto cuando ejecutas tus canalizaciones. | En este caso de uso, administrarás dos proyectos. En esta página, el proyecto del cliente hace referencia al lugar donde se ejecuta la instancia de Cloud Data Fusion. El proyecto de Managed Service para Apache Spark hace referencia al lugar donde se inician los clústeres de Managed Service para Apache Spark. |
VPC del cliente
| Modelo de referencia | Caso de uso |
|---|---|
Desde tu perspectiva (la del cliente), la VPC del cliente es donde se encuentra lógicamente Cloud Data Fusion. Puntos clave: Puedes encontrar los detalles de la VPC del cliente en la página de redes de VPC de tu proyecto. |
No se requiere ninguna configuración adicional para este caso de uso. |
Subred de Cloud Data Fusion
| Modelo de referencia | Caso de uso |
|---|---|
Desde tu perspectiva (la del cliente), esta subred es donde se ubica lógicamente Cloud Data Fusion. Punto clave: La región de esta subred es la misma que la ubicación de la instancia de Cloud Data Fusion en el proyecto de usuario. |
No se requiere ninguna configuración adicional para este caso de uso. |
Subred de Managed Service para Apache Spark
| Modelo de referencia | Caso de uso |
|---|---|
Es la subred en la que se inician los clústeres de Managed Service for Apache Spark cuando ejecutas una canalización. Conclusiones principales:
|
Esta es una subred nueva en la que se inician los clústeres de Managed Service for Apache Spark cuando ejecutas una canalización. Conclusiones principales:
|
Fuentes y receptores
| Modelo de referencia | Caso de uso |
|---|---|
Las fuentes desde las que se extraen los datos y los receptores en los que se cargan, como las fuentes y los receptores de BigQuery. Conclusión clave:
|
Las configuraciones de control de acceso específicas del caso de uso que se describen en esta página son para las fuentes y los receptores de BigQuery. |
Cloud Storage
| Modelo de referencia | Caso de uso |
|---|---|
Es el bucket de almacenamiento en el proyecto del cliente que ayuda a transferir archivos entre Cloud Data Fusion y Managed Service for Apache Spark. Conclusiones principales:
|
No se requiere ninguna configuración adicional para este caso de uso. |
Buckets temporales que usan la fuente y el receptor
| Modelo de referencia | Caso de uso |
|---|---|
Son los buckets temporales que crean los complementos para tus fuentes y receptores, como los trabajos de carga que inicia el complemento BigQuery Sink. Conclusiones principales:
|
Para este caso de uso, el bucket se puede crear en cualquier proyecto. |
Son buckets que son fuentes o receptores de datos para complementos.
| Modelo de referencia | Caso de uso |
|---|---|
| Buckets del cliente, que se especifican en las configuraciones de los complementos, como el complemento de Cloud Storage y el complemento de FTP a Cloud Storage | No se requiere ninguna configuración adicional para este caso de uso. |
IAM: Agente de servicios de la API de Cloud Data Fusion
| Modelo de referencia | Caso de uso |
|---|---|
Cuando se habilita la API de Cloud Data Fusion, el rol de agente de servicio de la API de Cloud Data Fusion ( Conclusiones principales:
|
Para este caso de uso, otorga el rol de agente de servicio de la API de Cloud Data Fusion a la cuenta de servicio en el proyecto de Managed Service for Apache Spark. Luego, otorga los siguientes roles en ese proyecto:
|
IAM: Cuenta de servicio de Managed Service para Apache Spark
| Modelo de referencia | Caso de uso |
|---|---|
Es la cuenta de servicio que se usa para ejecutar la canalización como un trabajo dentro del clúster de Managed Service para Apache Spark. De forma predeterminada, es la cuenta de servicio de Compute Engine. Opcional: En la configuración de referencia, puedes cambiar la cuenta de servicio predeterminada por otra cuenta de servicio del mismo proyecto. Otorga los siguientes roles de IAM a la nueva cuenta de servicio:
|
En este ejemplo de caso de uso, se supone que usas la cuenta de servicio predeterminada de Compute Engine ( Otorga los siguientes roles a la cuenta de servicio predeterminada de Compute Engine en el proyecto de Managed Service for Apache Spark.
Otorga el rol de usuario de cuenta de servicio a la cuenta de servicio de Cloud Data Fusion en la cuenta de servicio predeterminada de Compute Engine del proyecto de Managed Service for Apache Spark. Esta acción se debe realizar en el proyecto del servicio administrado para Apache Spark. Agrega la cuenta de servicio predeterminada de Compute Engine del proyecto de Managed Service for Apache Spark al proyecto de Cloud Data Fusion. También otorga los siguientes roles:
|
API
| Modelo de referencia | Caso de uso |
|---|---|
Cuando habilitas la API de Cloud Data Fusion, también se habilitan las siguientes APIs. Para obtener más información sobre estas APIs, ve a la página APIs y servicios de tu proyecto.
Cuando habilitas la API de Cloud Data Fusion, las siguientes cuentas de servicio se agregan automáticamente a tu proyecto:
|
Para este caso de uso, habilita las siguientes APIs en el proyecto que contiene el proyecto del servicio administrado para Apache Spark:
|
Claves de encriptación
| Modelo de referencia | Caso de uso |
|---|---|
En la configuración de referencia, las claves de encriptación pueden ser administradas por Google o CMEK. Conclusiones principales: Si usas CMEK, tu configuración de referencia requiere lo siguiente:
Según los servicios que se usen en tu canalización, como BigQuery o Cloud Storage, también se debe otorgar a las cuentas de servicio el rol de Encriptador/Desencriptador de CryptoKey de Cloud KMS:
|
Si no usas CMEK, no se necesitan cambios adicionales para este caso de uso. Si usas CMEK, se debe proporcionar el rol de Encriptador/Desencriptador de CryptoKey de Cloud KMS a la siguiente cuenta de servicio a nivel de la clave en el proyecto en el que se crea:
Según los servicios que se usen en tu canalización, como BigQuery o Cloud Storage, también se debe otorgar a otras cuentas de servicio el rol de Encriptador/Desencriptador de CryptoKey de Cloud KMS a nivel de la clave. Por ejemplo:
|
Después de realizar estas configuraciones específicas del caso de uso, tu canalización de datos puede comenzar a ejecutarse en clústeres de otro proyecto.
¿Qué sigue?
- Obtén más información sobre las herramientas de redes en Cloud Data Fusion.
- Consulta la referencia de roles básicos y predefinidos de IAM.