
本教程介绍如何构建可重复使用的流水线,以从 Cloud Storage 读取数据、执行数据质量检查以及将数据写入 Cloud Storage。
可重复使用的流水线具有常规流水线结构,但您可以根据 HTTP 服务器提供的配置更改每个流水线节点的配置。例如,静态流水线可能会从 Cloud Storage 读取数据、应用转换,并向 BigQuery 输出表写入数据。如果您希望转换和 BigQuery 输出表根据流水线读取的 Cloud Storage 文件发生更改,则需要创建可重复使用的流水线。
目标
- 使用 Cloud Storage Argument Setter 插件让流水线在每次运行时读取不同的输入。
- 使用 Cloud Storage Argument Setter 插件让流水线在每次运行时执行不同的质量检查。
- 将每次运行产生的输出数据写入 Cloud Storage。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
- Cloud Data Fusion
- Cloud Storage
如需根据您的预计使用情况来估算费用,请使用价格计算器。
准备工作
- 登录您的 Google Cloud 账号。如果您是 Google Cloud新手,请 创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
启用 Cloud Data Fusion、Cloud Storage、BigQuery 和 Dataproc API。
启用 API 所需的角色
如需启用 API,您需要拥有
serviceusage.services.enable权限。如果您创建了项目,则可能已经通过 Owner 角色 (roles/owner) 获得了此权限。否则,您可以通过 Service Usage Admin 角色 (roles/serviceusage.serviceUsageAdmin) 获得此权限。了解如何授予角色。- 创建 Cloud Data Fusion 实例。
前往 Cloud Data Fusion 网页界面
使用 Cloud Data Fusion 时,您将同时使用 Google Cloud 控制台和单独的 Cloud Data Fusion 网页界面。在 Google Cloud 控制台中,您可以创建 Google Cloud 控制台项目,以及创建和删除 Cloud Data Fusion 实例。在 Cloud Data Fusion 网页界面中,您可以通过各种页面(例如流水线 Studio 或 Wrangler)来使用 Cloud Data Fusion 功能。
在 Google Cloud 控制台中,打开实例页面。
在实例的操作列中,点击查看实例链接。Cloud Data Fusion 网页界面会在新的浏览器标签页中打开。
部署 Cloud Storage Argument Setter 插件
在 Cloud Data Fusion 网页界面中,前往 Studio 页面。
在操作菜单中,点击 GCS 实参设置器。
从 Cloud Storage 读取数据
- 在 Cloud Data Fusion 网页界面中,前往 Studio 页面。
- 点击 arrow_drop_down Source(来源),然后选择 Cloud Storage。Cloud Storage 来源的节点会显示在流水线中。
在 Cloud Storage 节点上,点击属性。
在参考名称字段中,输入名称。
在路径字段中,输入
${input.path}。此宏用于控制将在不同流水线运行中使用的 Cloud Storage 输入路径。在右侧的“输出架构”面板中,通过点击偏移字段行中的垃圾桶图标,从输出架构中移除偏移字段。
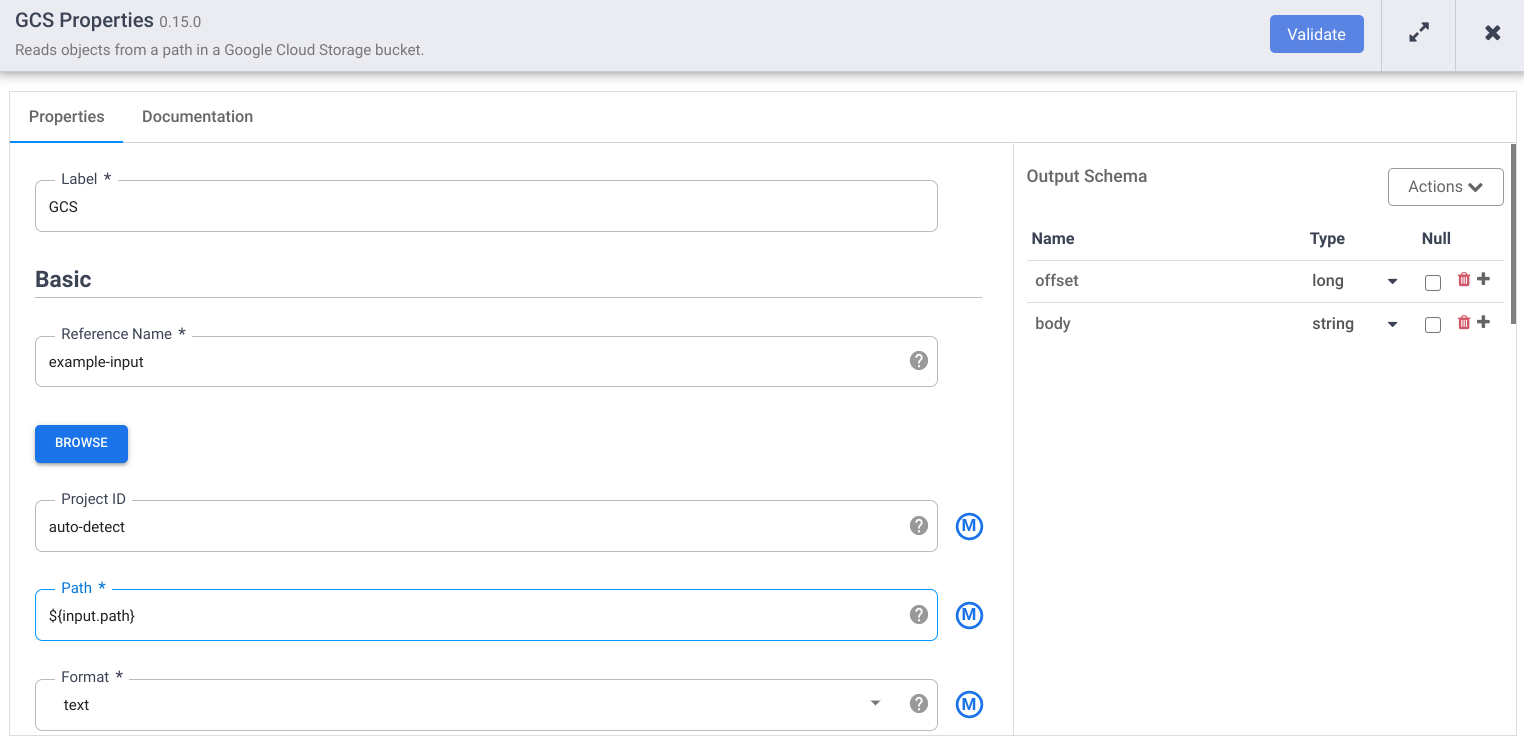
点击验证并解决所有错误。
点击 退出属性对话框。
转换数据
- 在 Cloud Data Fusion 网页界面中,前往 Studio 页面上的数据流水线。
- 在转换下拉菜单 arrow_drop_down 中,选择 Wrangler。
- 在“流水线 Studio”画布中,将箭头从 Cloud Storage 节点拖动到 Wrangler 节点。
- 前往流水线中的 Wrangler 节点,然后点击属性。
- 在输入字段名称中,输入
body。 - 在配方字段中,输入
${directives}。此宏用于控制将在不同流水线运行中使用的转换逻辑。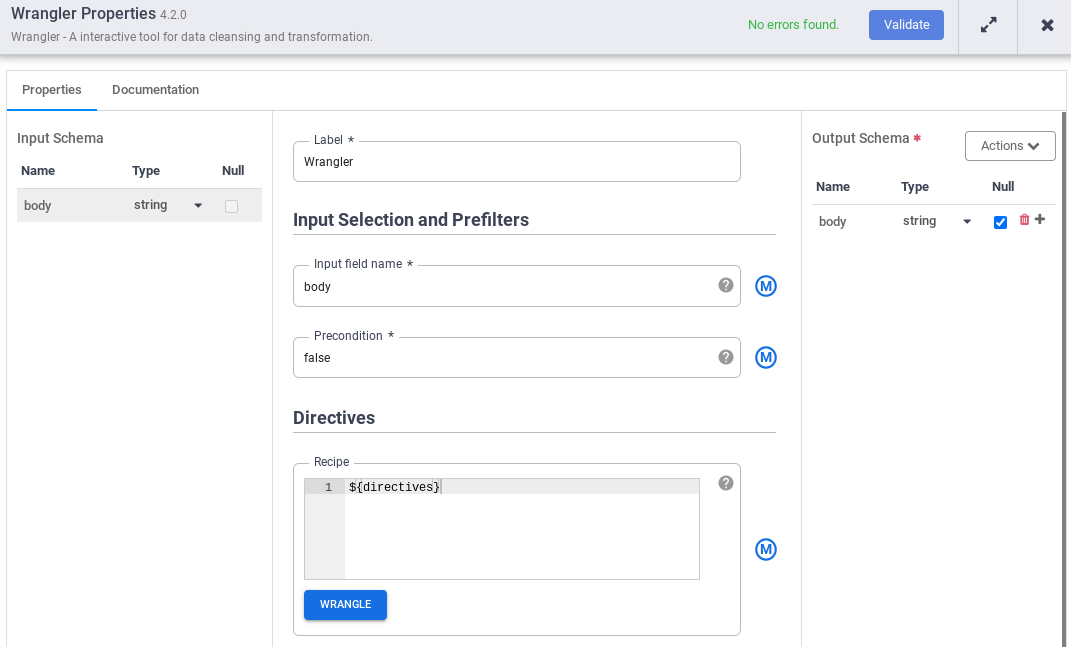
- 点击验证并解决所有错误。
- 点击 退出属性对话框。
写入 Cloud Storage
- 在 Cloud Data Fusion 网页界面中,前往 Studio 页面上的数据流水线。
- 在接收器下拉菜单 arrow_drop_down 中,选择 Cloud Storage。
- 在“流水线 Studio”画布中,将箭头从 Wrangler 节点拖动到您刚刚添加的 Cloud Storage 节点。
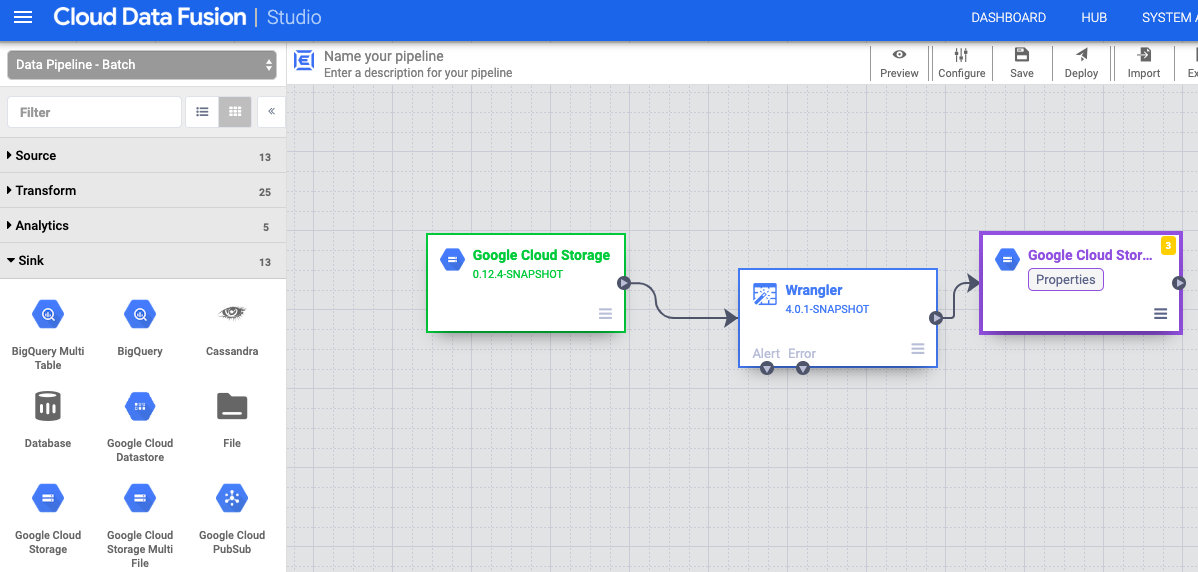
- 前往流水线中的 Cloud Storage 接收器节点,然后点击属性。
- 在参考名称字段中,输入名称。
- 在路径字段中,输入您项目中的 Cloud Storage 存储桶的路径,流水线可在其中写入输出文件。如果您没有 Cloud Storage 存储桶,请创建一个。
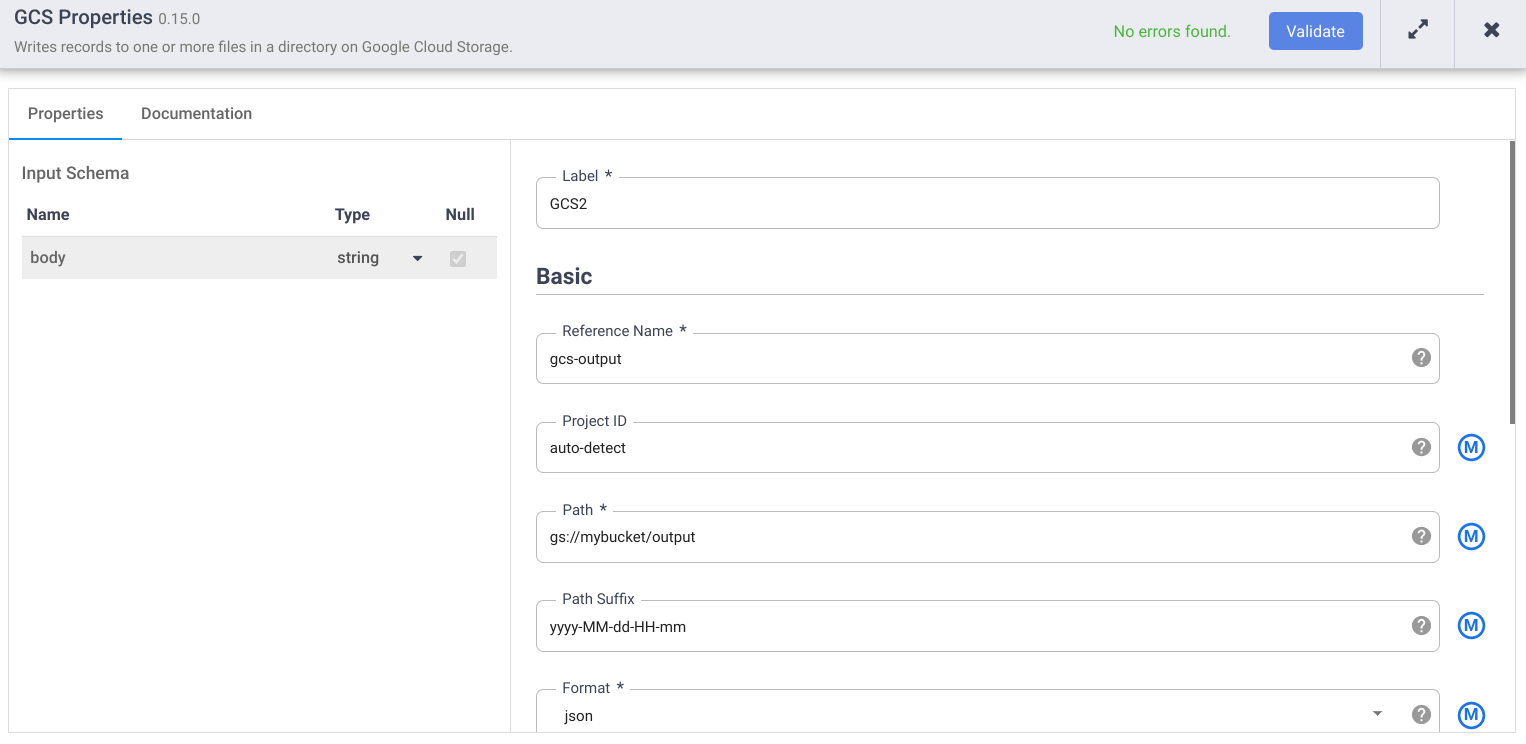
- 点击验证并解决所有错误。
- 点击 退出属性对话框。
设置宏参数
- 在 Cloud Data Fusion 网页界面中,前往 Studio 页面上的数据流水线。
- 在arrow_drop_down 条件和操作下拉菜单中,点击 GCS Argument Setter。
- 在“流水线 Studio”画布中,将箭头从 Cloud Storage Argument Setter 节点拖动到 Cloud Storage 来源节点。
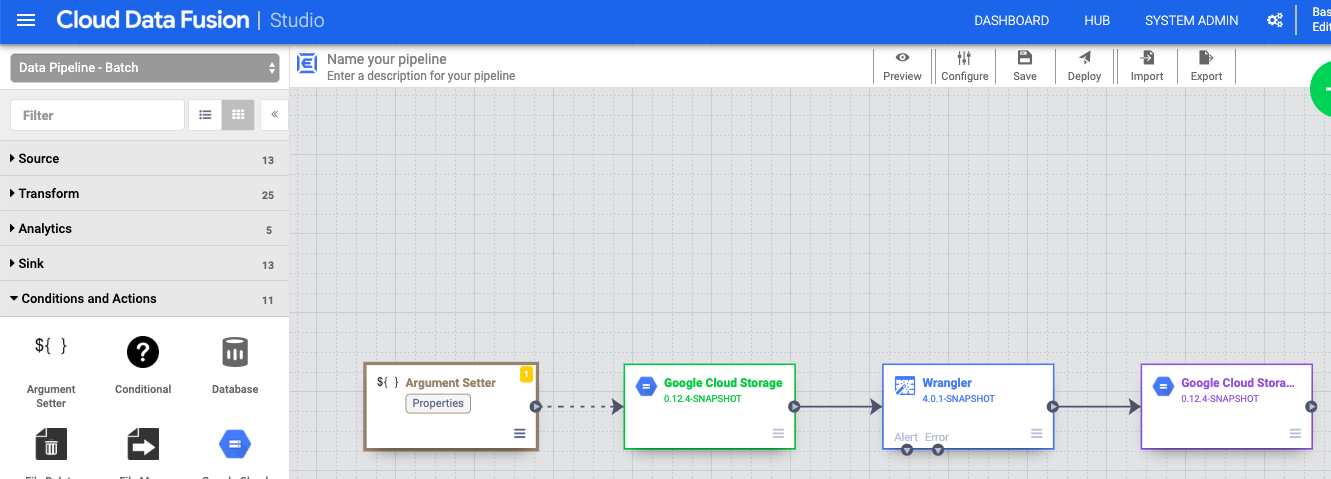
- 前往流水线中的 Cloud Storage Argument Setter 节点,然后点击属性。
在网址字段中,输入以下网址:
gs://reusable-pipeline-tutorial/args.json该网址对应于 Cloud Storage 中可公开访问的对象,对象包含以下内容:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }两个参数中的第一个是
input.path的值。路径gs://reusable-pipeline-tutorial/user-emails.txt是 Cloud Storage 中可公开访问的对象,对象包含以下测试数据:alice@example.com bob@example.com craig@invalid@example.com第二个参数是
directives的值。值send-to-error !dq:isEmail(body)会配置 Wrangler,以滤除不是有效电子邮件地址的所有行。例如,craig@invalid@example.com已被滤除。点击验证以确保没有任何错误。
点击 退出属性对话框。
部署并运行流水线
在流水线 Studio 页面的顶部栏中,点击为流水线命名。 为流水线命名,然后点击保存。
点击部署。
如需打开运行时参数并查看宏(运行时)
input.path和directives参数,请点击运行旁边的下拉菜单 arrow_drop_down。请将值字段留空,以通知 Cloud Data Fusion 流水线中的 Cloud Storage Argument Setter 节点将在运行时期间设置这些实参的值。
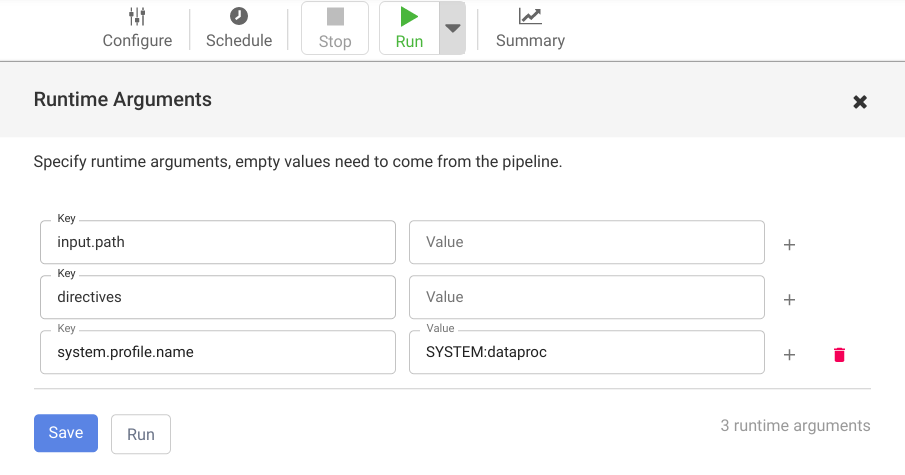
点击运行。
清除数据
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
完成本教程后,请清理在Google Cloud 上创建的资源,以免这些资源占用配额,日后产生费用。以下部分介绍如何删除或关闭这些资源。
删除 Cloud Data Fusion 实例
删除项目
为了避免产生费用,最简单的方法是删除您为本教程创建的项目。
要删除项目,请执行以下操作:
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。