
En este tutorial se muestra cómo crear una canalización reutilizable que lee datos de Cloud Storage, realiza comprobaciones de calidad de los datos y escribe en Cloud Storage.
Las canalizaciones reutilizables tienen una estructura de canalización normal, pero puedes cambiar la configuración de cada nodo de canalización en función de las configuraciones proporcionadas por un servidor HTTP. Por ejemplo, un flujo de procesamiento estático puede leer datos de Cloud Storage, aplicar transformaciones y escribir en una tabla de salida de BigQuery. Si quieres que la transformación y la tabla de salida de BigQuery cambien en función del archivo de Cloud Storage que lea el flujo de procesamiento, crea un flujo de procesamiento reutilizable.
Desplegar el complemento Configurador de argumentos de Cloud Storage
En la interfaz web de Cloud Data Fusion, vaya a la página Studio.
En el menú Acciones, haz clic en GCS Argument Setter.
Leer de Cloud Storage
- En la interfaz web de Cloud Data Fusion, vaya a la página Studio.
- Haga clic en arrow_drop_down Fuente y seleccione Cloud Storage. El nodo de la fuente de Cloud Storage aparece en la canalización.
En el nodo Cloud Storage, haga clic en Propiedades.
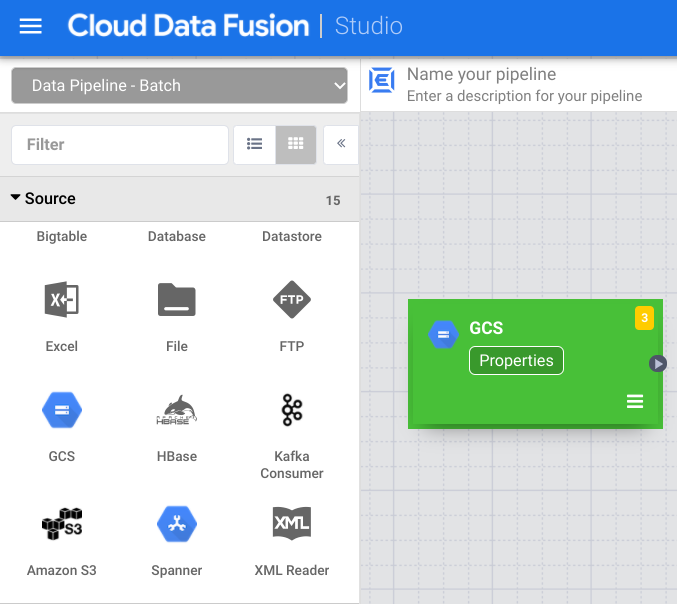
En el campo Nombre de referencia, introduce un nombre.
En el campo Ruta, introduce
${input.path}. Esta macro controla cuál será la ruta de entrada de Cloud Storage en las diferentes ejecuciones de la canalización.En el panel Esquema de salida de la derecha, elimina el campo offset del esquema de salida haciendo clic en el icono de papelera de la fila del campo offset.
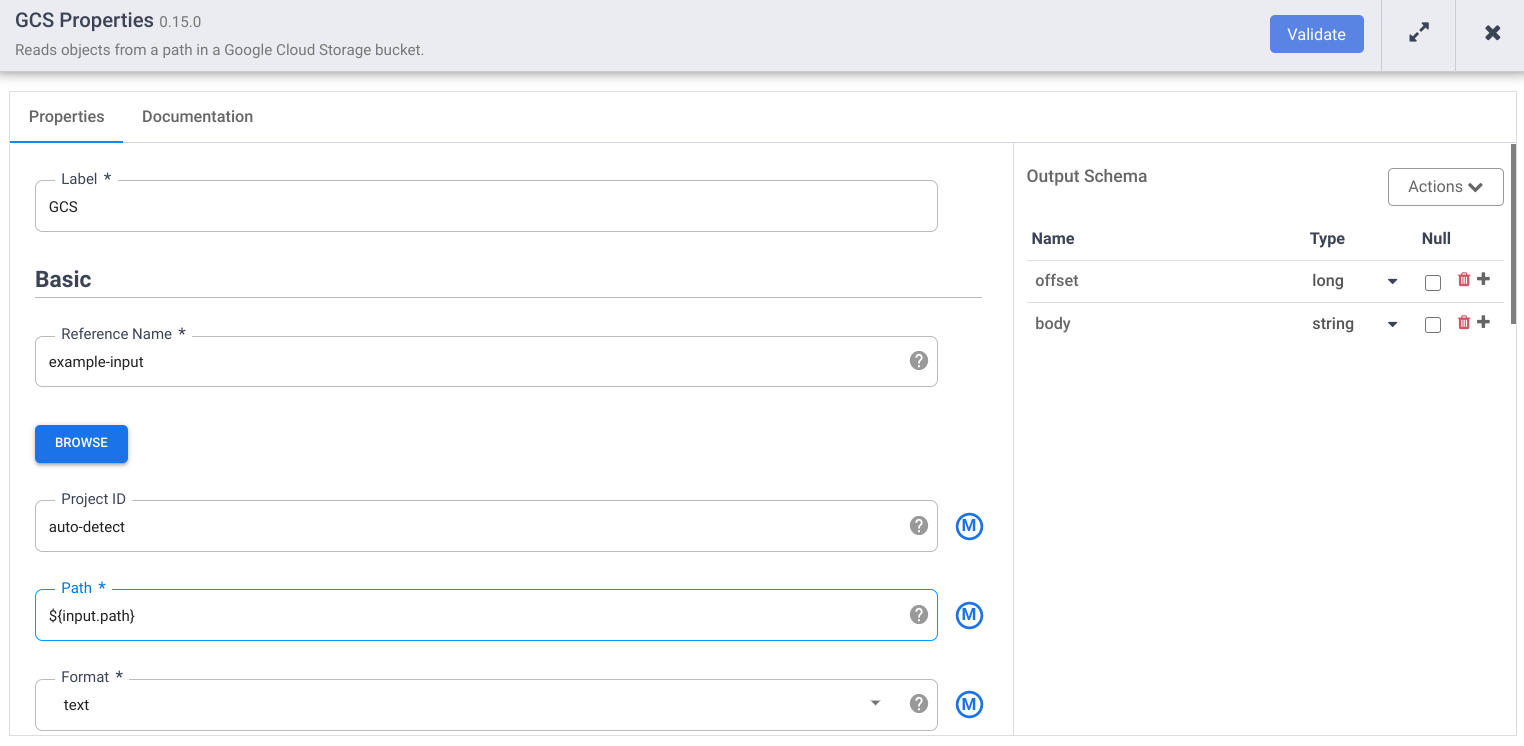
Haga clic en Validar y corrija los errores.
Haz clic en para cerrar el cuadro de diálogo Propiedades.
Transforma los datos
- En la interfaz web de Cloud Data Fusion, vaya a su flujo de procesamiento de datos en la página Studio.
- En el menú desplegable Transformar arrow_drop_down, selecciona Wrangler.
- En el lienzo de Pipeline Studio, arrastra una flecha desde el nodo Cloud Storage hasta el nodo Wrangler.
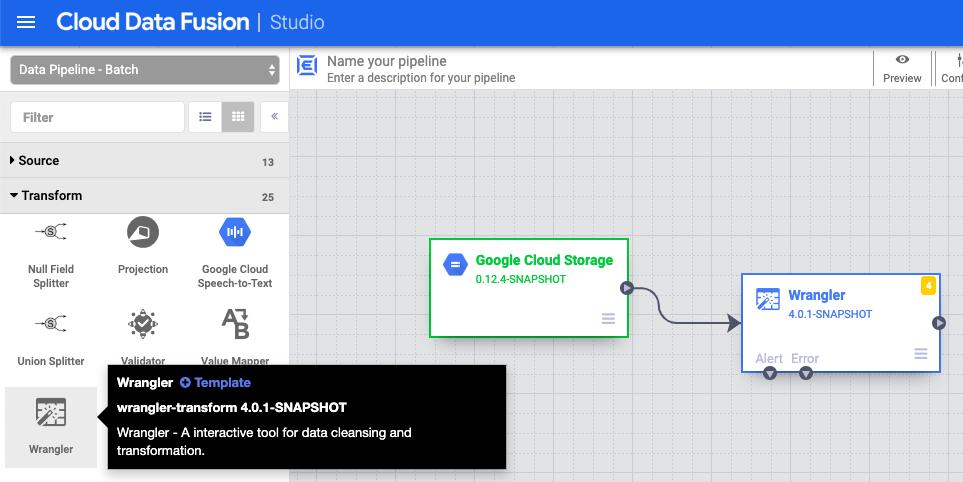
- Ve al nodo Wrangler de tu canalización y haz clic en Properties (Propiedades).
- En Nombre del campo de entrada, introduce
body. - En el campo Recipe (Receta), introduce
${directives}. Esta macro controla la lógica de transformación que se aplicará en las diferentes ejecuciones de la canalización.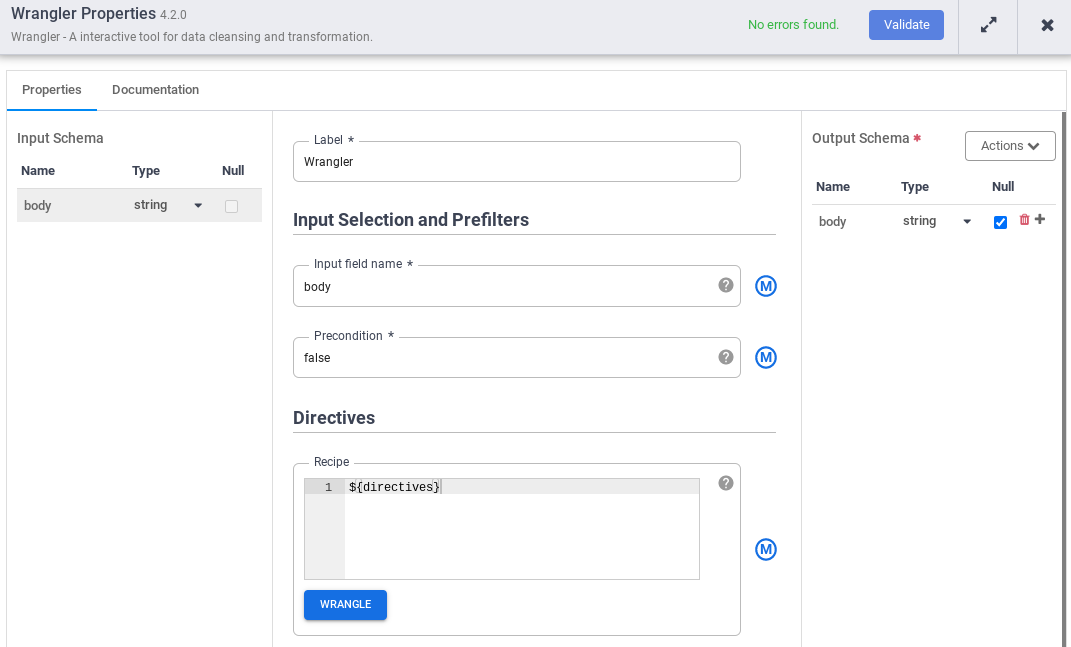
- Haga clic en Validar y corrija los errores.
- Haz clic en para cerrar el cuadro de diálogo Propiedades.
Escribir en Cloud Storage
- En la interfaz web de Cloud Data Fusion, vaya a su flujo de procesamiento de datos en la página Studio.
- En el menú desplegable Receptor arrow_drop_down, selecciona Cloud Storage.
- En el lienzo de Pipeline Studio, arrastra una flecha desde el nodo Wrangler hasta el nodo Cloud Storage que acabas de añadir.
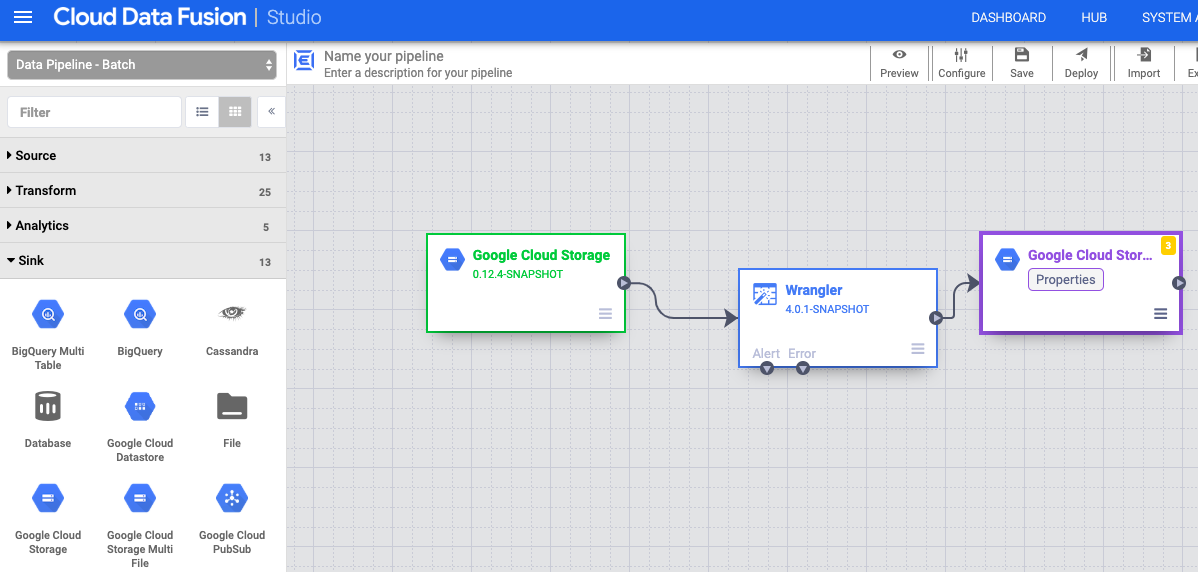
- Ve al nodo de receptor de Cloud Storage de tu canalización y haz clic en Propiedades.
- En el campo Nombre de referencia, introduce un nombre.
- En el campo Ruta, introduce la ruta de un segmento de Cloud Storage de tu proyecto en el que tu canalización pueda escribir los archivos de salida. Si no tienes ningún segmento de Cloud Storage, crea uno.
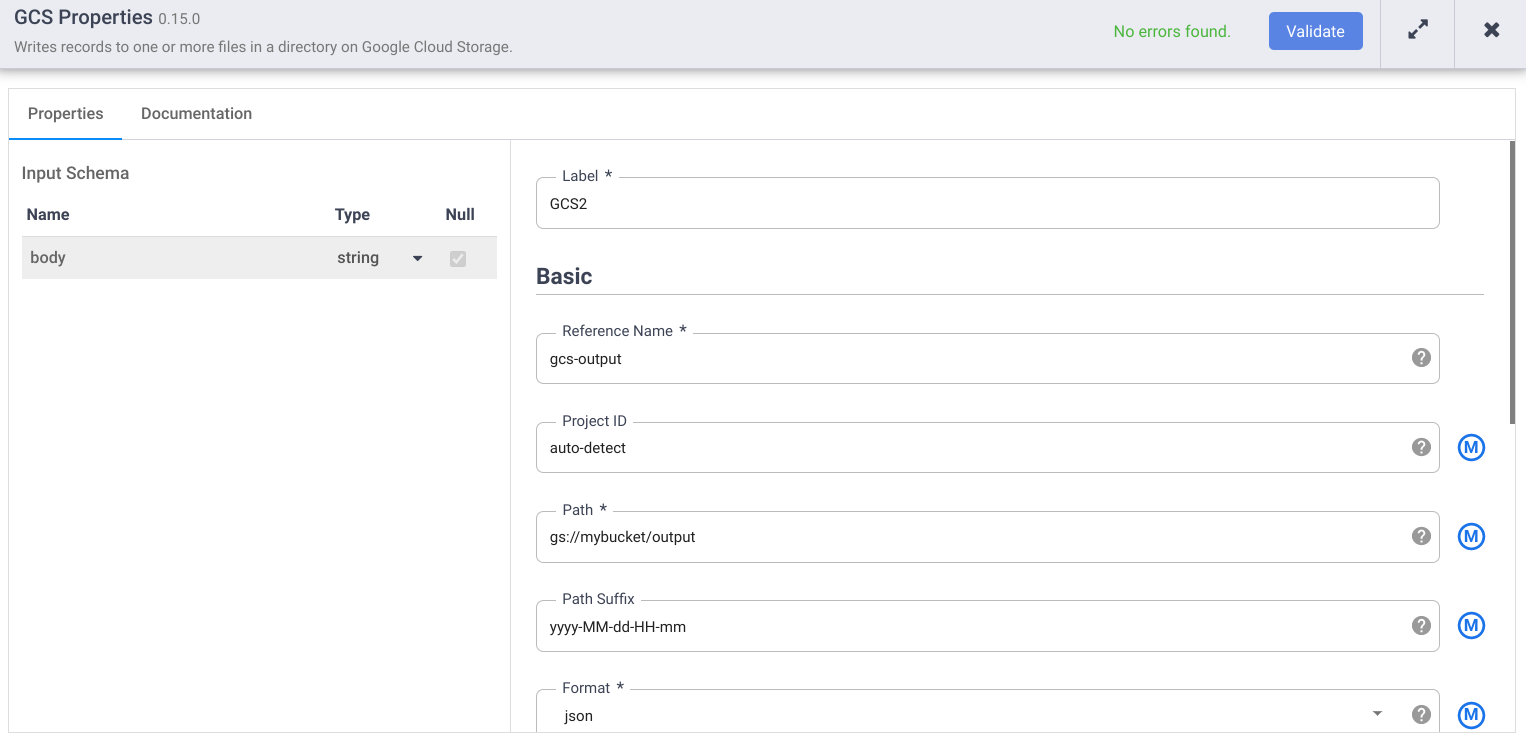
- Haga clic en Validar y corrija los errores.
- Haz clic en para cerrar el cuadro de diálogo Propiedades.
Definir los argumentos de la macro
- En la interfaz web de Cloud Data Fusion, vaya a su flujo de procesamiento de datos en la página Studio.
- En el menú desplegable arrow_drop_down Condiciones y acciones, haz clic en Definidor de argumentos de GCS.
- En el lienzo de Pipeline Studio, arrastra una flecha desde el nodo Configurador de argumentos de Cloud Storage hasta el nodo fuente de Cloud Storage.
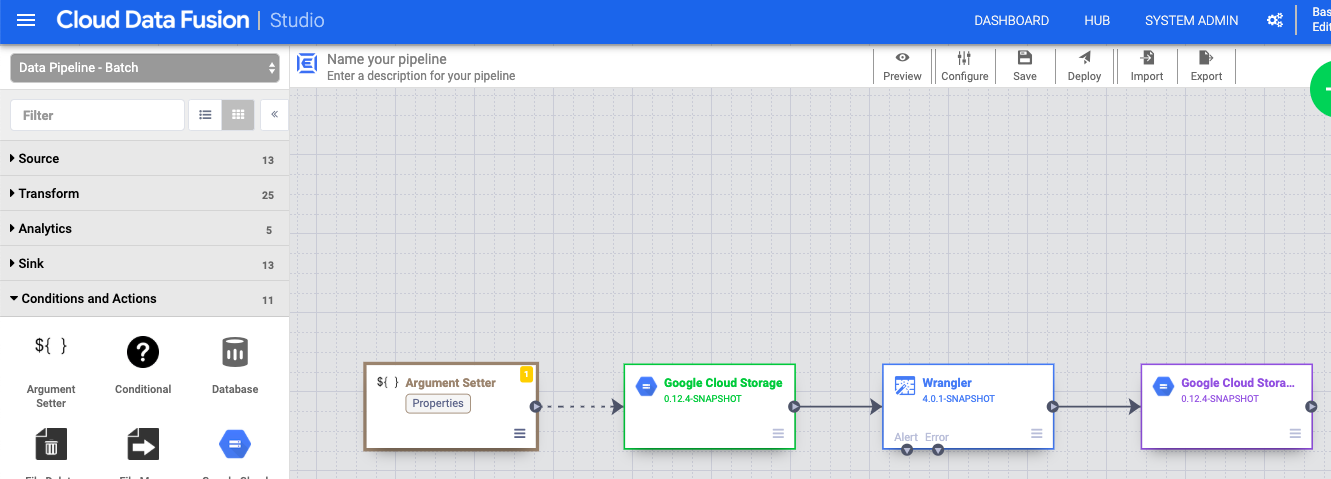
- Ve al nodo Configurador de argumentos de Cloud Storage de tu flujo de procesamiento y haz clic en Propiedades.
En el campo URL, introduce la siguiente URL:
gs://reusable-pipeline-tutorial/args.jsonLa URL corresponde a un objeto de acceso público en Cloud Storage que contiene el siguiente contenido:
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }El primero de los dos argumentos es el valor de
input.path. La rutags://reusable-pipeline-tutorial/user-emails.txtes un objeto de acceso público en Cloud Storage que contiene los siguientes datos de prueba:alice@example.com bob@example.com craig@invalid@example.comEl segundo argumento es el valor de
directives. El valorsend-to-error !dq:isEmail(body)configura Wrangler para filtrar las líneas que no sean una dirección de correo válida. Por ejemplo,craig@invalid@example.comse excluye.Haga clic en Validar para comprobar que no haya errores.
Haz clic en para cerrar el cuadro de diálogo Propiedades.
Implementar y ejecutar un flujo de procesamiento
En la barra superior de la página Pipeline Studio, haz clic en Asigna un nombre a tu canalización. Asigna un nombre a la canalización y haz clic en Guardar.
Haz clic en Desplegar.
Para abrir los argumentos de tiempo de ejecución y ver los argumentos de macro (tiempo de ejecución)
input.pathydirectives, haz clic en el desplegable arrow_drop_down junto a Ejecutar.Deje en blanco los campos de valor para indicar a Cloud Data Fusion que el nodo Argument Setter de Cloud Storage de la canalización definirá los valores de estos argumentos durante el tiempo de ejecución.
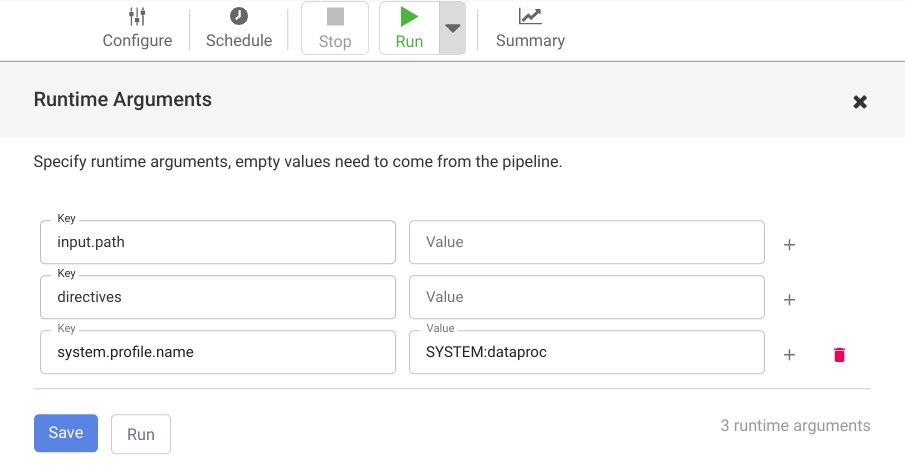
Haz clic en Ejecutar.