
Linaje de datos de Cloud Data Fusion
Puedes usar el linaje de datos de Cloud Data Fusion para hacer lo siguiente:
Detectar la causa principal de los eventos de datos incorrectos.
Realiza un análisis de impacto antes de hacer cambios en los datos.
Le recomendamos que utilice la integración del linaje de recursos en Dataplex Universal Catalog. Para obtener más información, consulta Ver el linaje en Dataplex Universal Catalog.
También puede ver el linaje a nivel de conjunto de datos y campo en Cloud Data Fusion Studio mediante la opción Metadatos, que muestra el linaje de un periodo seleccionado.
El linaje a nivel de conjunto de datos muestra la relación entre los conjuntos de datos y las canalizaciones.
El linaje a nivel de campo muestra las operaciones que se han realizado en un conjunto de campos del conjunto de datos de origen para producir un conjunto de campos diferente en el conjunto de datos de destino.
A partir de Cloud Data Fusion 6.9.2.4, si no monitorizas el linaje en Cloud Data Fusion, te recomendamos que desactives la emisión del linaje a nivel de campo en tu instancia mediante el método patch:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google CloudREGION: la ubicación del Google Cloud proyectoINSTANCE_ID: el ID de la instancia de Cloud Data Fusion
Situación del tutorial
En este tutorial, trabajarás con dos canalizaciones:
El flujo de procesamiento de datos
Shipment Data Cleansinglee datos de envíos sin procesar de un pequeño conjunto de datos de muestra y aplica transformaciones para limpiar los datos.A continuación, la
Delayed Shipments USAlee los datos de envío depurados, los analiza y busca los envíos dentro de EE. UU. que se hayan retrasado más de un umbral.
Estas canalizaciones del tutorial muestran un caso práctico habitual en el que los datos sin procesar se limpian y, a continuación, se envían para que se procesen. Este rastro de datos, desde los datos sin procesar hasta los datos de envío limpios y los resultados analíticos, se puede consultar con la función de linaje de Cloud Data Fusion.
Abrir la interfaz de usuario de Cloud Data Fusion
Cuando usas Cloud Data Fusion, utilizas tanto la Google Cloud consola como la interfaz de usuario independiente de Cloud Data Fusion. En la Google Cloud consola, puedes crear un Google Cloud proyecto de consola, así como crear y eliminar instancias de Cloud Data Fusion. En la interfaz de usuario de Cloud Data Fusion, puedes usar las distintas páginas, como Linaje, para acceder a las funciones de Cloud Data Fusion.
En la Google Cloud consola, abre la página Instancias.
En la columna Acciones de la instancia, haga clic en el enlace Ver instancia. La interfaz de usuario de Cloud Data Fusion se abre en una nueva pestaña del navegador.
En el panel Integrar, haga clic en Studio para abrir la página Studio de Cloud Data Fusion.
Desplegar y ejecutar flujos de procesamiento
Importe los datos de envío sin procesar. En la página Studio, haga clic en Importar o en + > Pipeline > Importar. A continuación, seleccione e importe la canalización de limpieza de datos de envíos que descargó en Antes de empezar.

Implementa el flujo de procesamiento. En la parte superior derecha de la página Studio, haz clic en Desplegar. Una vez implementado, se abre la página Pipeline (Procesamiento).
Ejecuta el flujo de procesamiento. En la parte superior central de la página Pipeline, haz clic en Ejecutar.
Importa, implementa y ejecuta los datos y la canalización de envíos retrasados. Cuando el estado de la limpieza de datos de envío sea Completado, siga los pasos anteriores con los datos de envíos retrasados de EE. UU. que descargó en la sección Antes de empezar. Vuelve a la página Studio para importar los datos. A continuación, implementa y ejecuta esta segunda canalización desde la página Pipeline. Una vez que se haya completado correctamente la segunda canalización, sigue los pasos restantes.
Descubrir conjuntos de datos
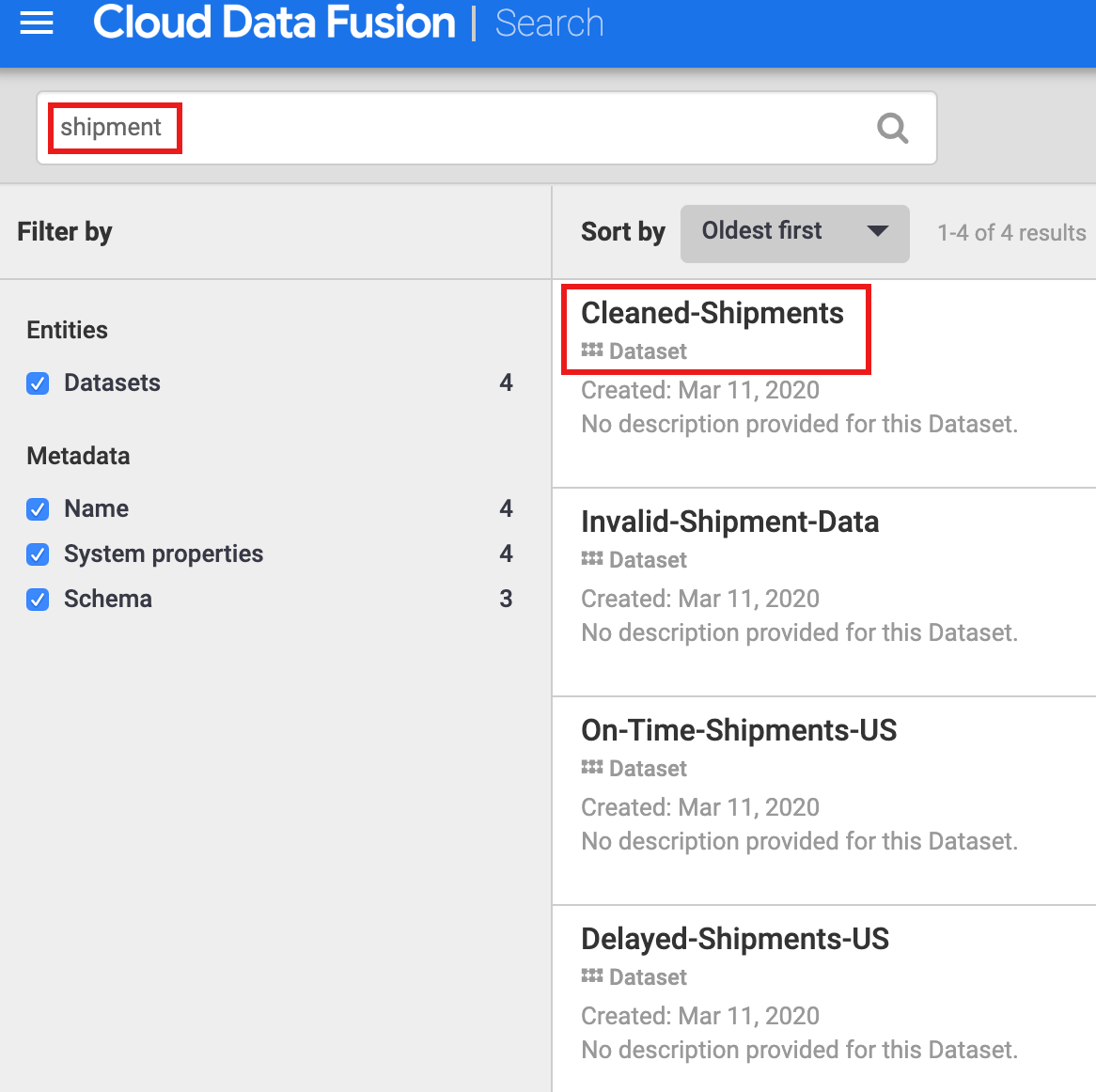
Debes descubrir un conjunto de datos antes de explorar su linaje. Selecciona Metadatos en el panel de navegación de la izquierda de la interfaz de usuario de Cloud Data Fusion para abrir la página Búsqueda de metadatos. Como el conjunto de datos Limpieza de datos de envíos ha especificado Cleaned-Shipments como conjunto de datos de referencia, inserta shipment en el cuadro de búsqueda. Los resultados de búsqueda incluyen este conjunto de datos.
Usar etiquetas para descubrir conjuntos de datos
Una búsqueda de metadatos descubre conjuntos de datos que han sido consumidos, procesados o generados por flujos de procesamiento de Cloud Data Fusion. Los flujos de procesamiento se ejecutan en un marco estructurado que genera y recoge metadatos técnicos y operativos. Los metadatos técnicos incluyen el nombre, el tipo, el esquema, los campos, la hora de creación y la información de procesamiento del conjunto de datos. Esta información técnica la usan las funciones de búsqueda de metadatos y linaje de Cloud Data Fusion.
Cloud Data Fusion también admite la anotación de conjuntos de datos con metadatos empresariales, como etiquetas y propiedades de pares clave-valor, que se pueden usar como criterios de búsqueda. Por ejemplo, para añadir y buscar una anotación de etiqueta de empresa en el conjunto de datos Datos de envío sin procesar, siga estos pasos:
Haga clic en el botón Propiedades del nodo Datos de envío sin procesar en la página Pipeline de limpieza de datos de envío para abrir la página Propiedades de Cloud Storage.
Haz clic en Ver metadatos para abrir la página Búsqueda.
En Etiquetas de empresa, haz clic en + e inserta un nombre de etiqueta (se permiten caracteres alfanuméricos y guiones bajos) y pulsa Intro.

Explorar linaje
Linaje a nivel de conjunto de datos
Haz clic en el nombre del conjunto de datos Cleaned-Shipments que aparece en la página de búsqueda (en Descubrir conjuntos de datos) y, a continuación, en la pestaña Linaje. El gráfico de linaje muestra que este conjunto de datos se ha generado a partir del flujo de procesamiento Shipments-Data-Cleansing, que había usado el conjunto de datos Raw_Shipping_Data.
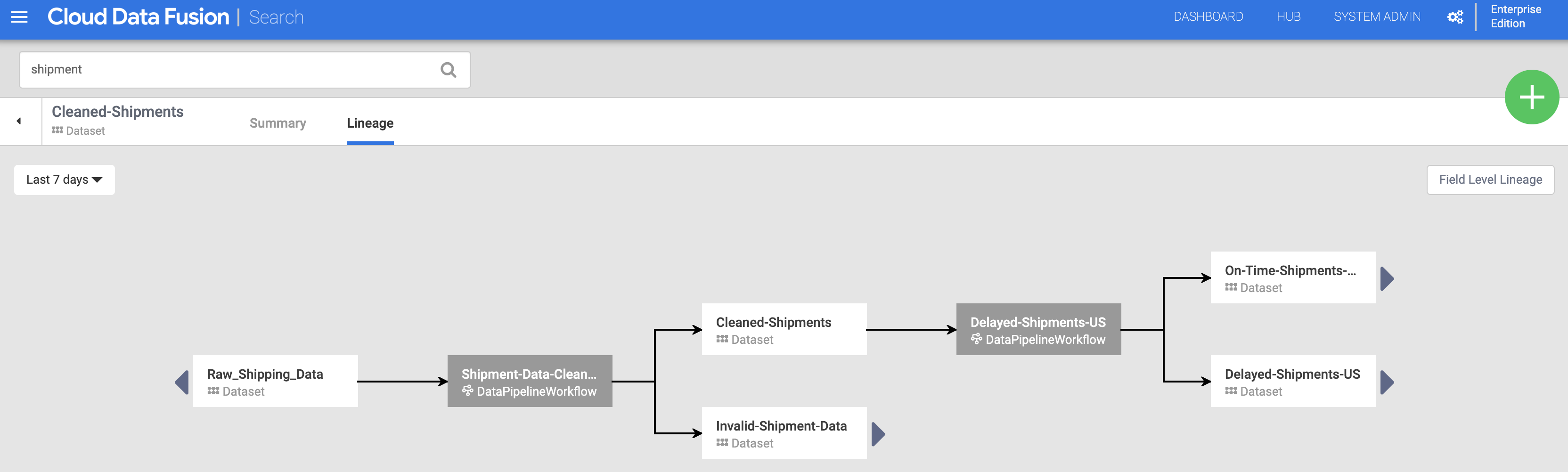
Las flechas hacia la izquierda y hacia la derecha te permiten desplazarte hacia atrás y hacia adelante por cualquier linaje de conjunto de datos anterior o posterior. En este ejemplo, el gráfico muestra el linaje completo del conjunto de datos Cleaned-Shipments.
Linaje a nivel de campo
El linaje a nivel de campo de Cloud Data Fusion muestra la relación entre los campos de un conjunto de datos y las transformaciones que se han realizado en un conjunto de campos para generar otro conjunto de campos. Al igual que el linaje a nivel de conjunto de datos, el linaje a nivel de campo está limitado por el tiempo y sus resultados cambian con el tiempo.
Siguiendo con el paso Linaje a nivel de conjunto de datos, haga clic en el botón Linaje a nivel de campo, situado en la parte superior derecha del gráfico de linaje a nivel de conjunto de datos Cleaned Shipments, para mostrar su gráfico de linaje a nivel de campo.
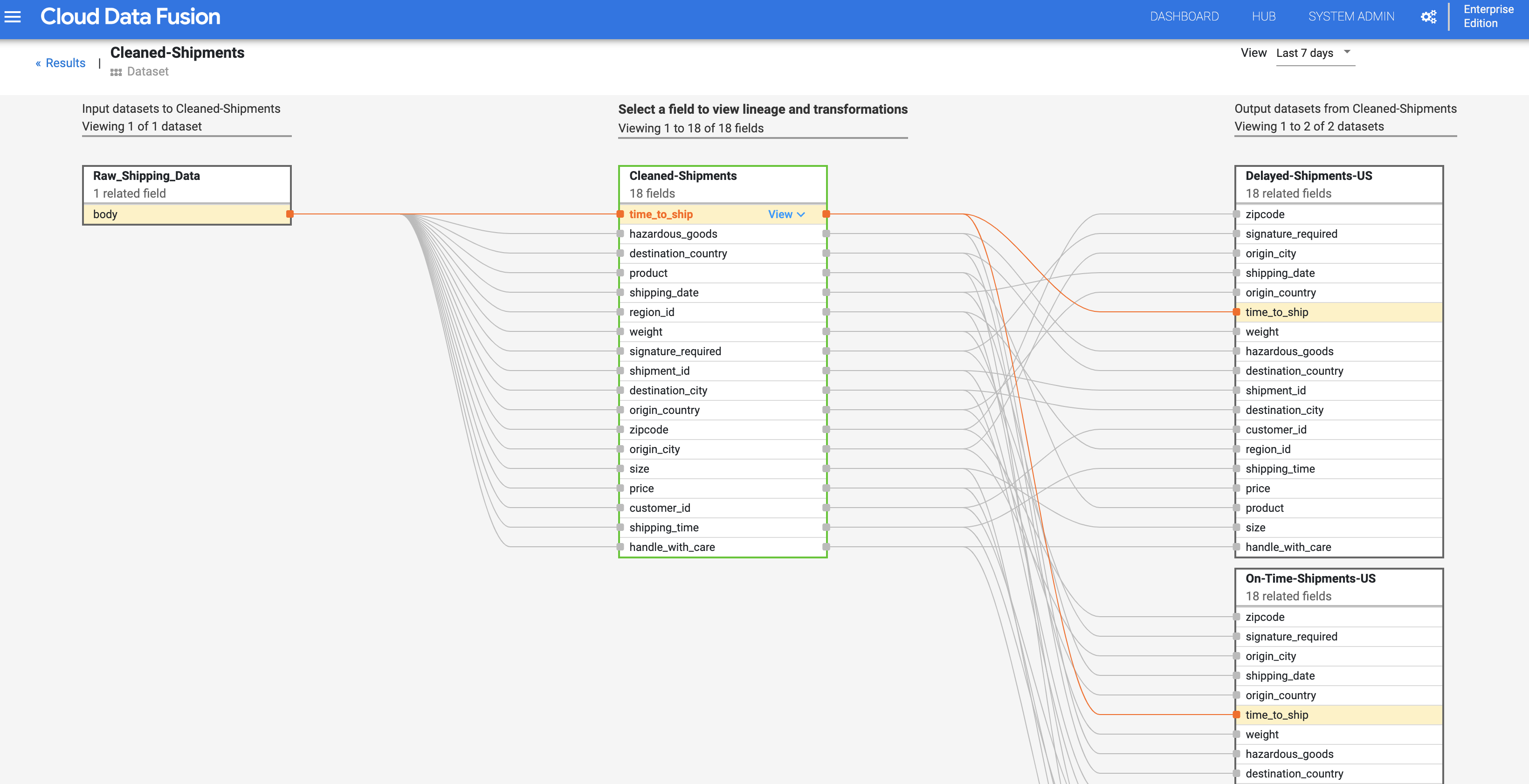
El gráfico de linaje a nivel de campo muestra las conexiones entre los campos. Puedes seleccionar un campo para ver su linaje. Selecciona Ver > Anclar campo para ver solo el linaje de ese campo.
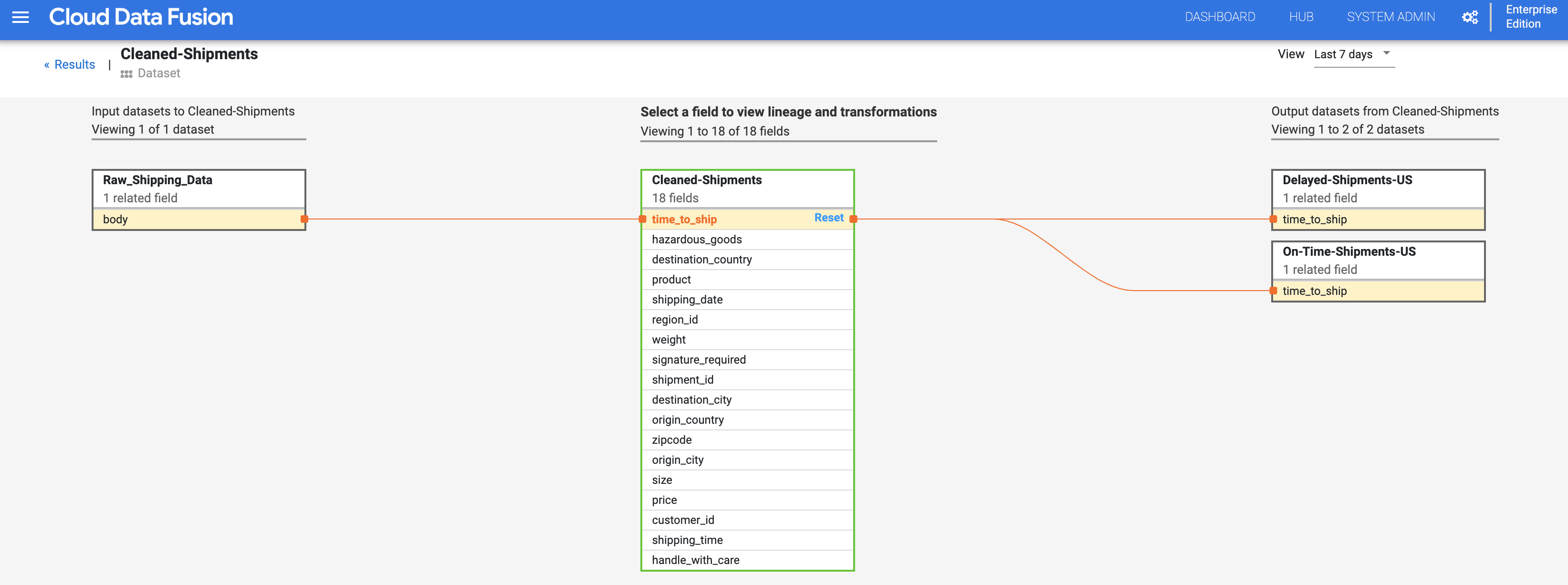
Selecciona Ver > Ver impacto para hacer un análisis del impacto.
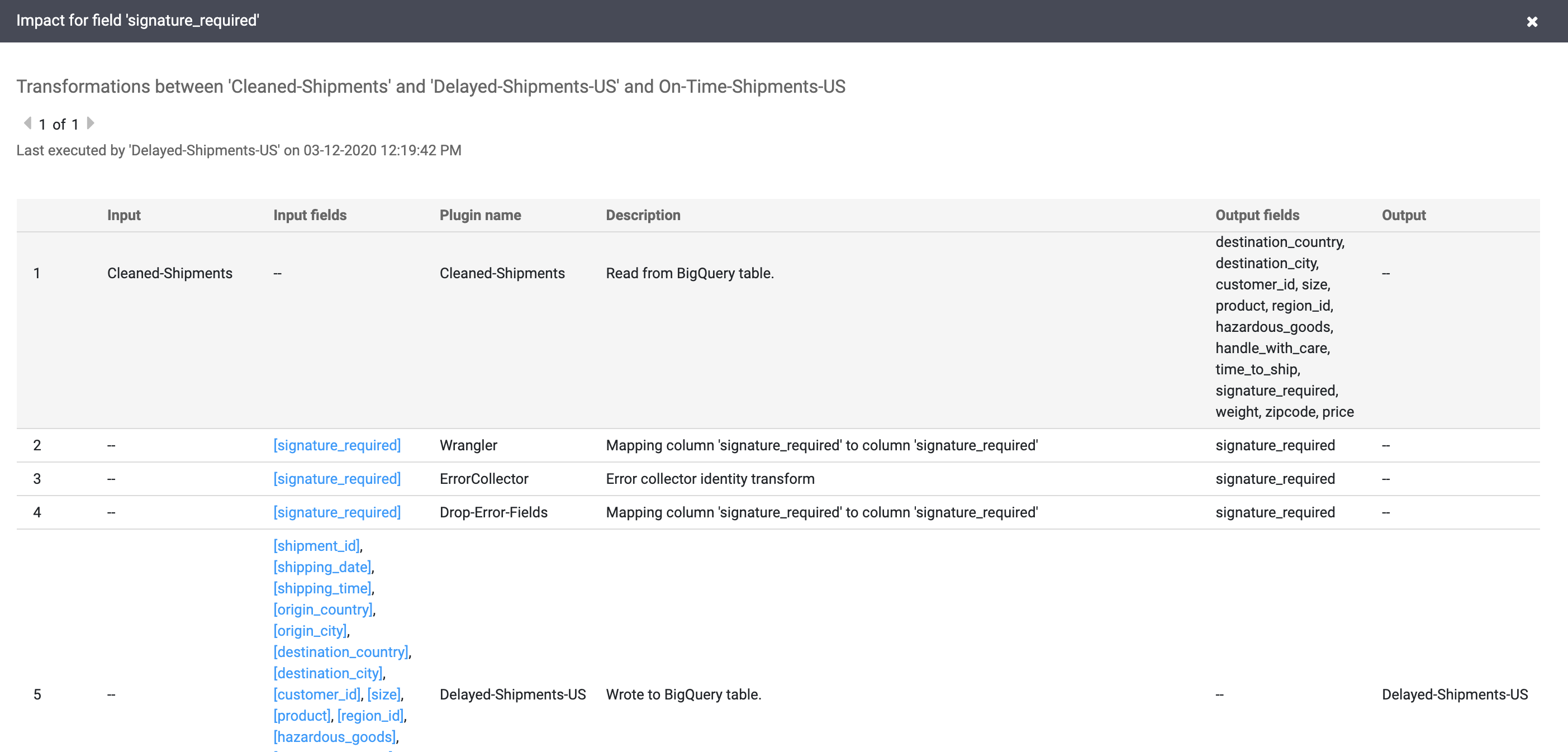
Los enlaces de causa e impacto muestran las transformaciones realizadas en ambos lados de un campo en un formato de registro legible por humanos. Esta información puede ser esencial para la elaboración de informes y la gobernanza.