
Auf dieser Seite wird beschrieben, wie Sie die Image-Version von Managed Service for Apache Spark ändern, die von Ihrer Cloud Data Fusion-Instanz verwendet wird. Sie können das Image auf Instanz-, Namespace- oder Pipelineebene ändern.
Hinweis
Beenden Sie alle Echtzeitpipelines und Replikationsjobs in der Cloud Data Fusion-Instanz. Wenn eine Echtzeitpipeline oder Replikation ausgeführt wird, während Sie die Image-Version von Managed Service for Apache Spark ändern, werden die Änderungen nicht auf die Pipelineausführung angewendet.
Bei Echtzeitpipelines führt das Beenden der Pipelines nicht zu Datenverlusten, wenn Checkpointing aktiviert ist. Bei Replikationsjobs führt das Beenden und Starten des Replikationsjobs nicht zu Datenverlusten, solange die Datenbanklogs verfügbar sind.
Console
Rufen Sie die Seite Instanzen von Cloud Data Fusion auf und öffnen Sie die Instanz, in der Sie eine Pipeline beenden müssen.
Öffnen Sie jede Echtzeitpipeline in Pipeline Studio und klicken Sie auf Beenden.
Öffnen Sie jeden Replikationsjob auf der Seite Replizieren und klicken Sie auf Beenden.
REST API
Verwenden Sie den folgenden REST API-Aufruf, um alle Pipelines abzurufen:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps"Ersetzen Sie
NAMESPACE_IDdurch den Namen Ihres Namespace.Verwenden Sie den folgenden REST API-Aufruf, um eine Echtzeitpipeline zu beenden:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/PIPELINE_NAME/spark/DataStreamsSparkStreaming/stop"Ersetzen Sie NAMESPACE_ID durch den Namen Ihres Namespace und PIPELINE_NAME durch den Namen der Echtzeitpipeline.
Verwenden Sie den folgenden REST API-Aufruf, um einen Replikationsjob zu beenden:
POST -H "Authorization: Bearer ${AUTH_TOKEN}" \ "${CDAP_ENDPOINT}/v3/namespaces/NAMESPACE_ID/apps/REPLICATION_JOB_NAME/workers/DeltaWorker/stop"Ersetzen Sie NAMESPACE_ID durch den Namen Ihres Namespace und REPLICATION_JOB_NAME durch den Namen des Replikationsjobs.
Weitere Informationen finden Sie unter Echtzeitpipelines beenden und Replikationsjobs beenden.
Standardversion von Managed Service for Apache Spark in Cloud Data Fusion prüfen und überschreiben
Klicken Sie auf Systemadministrator > Konfiguration > Systemeinstellungen.
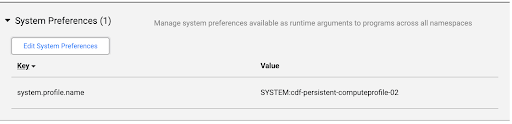
Wenn in den Systemeinstellungen kein Managed Service for Apache Spark-Image angegeben ist oder Sie die Einstellung ändern möchten, klicken Sie auf Systemeinstellungen bearbeiten.
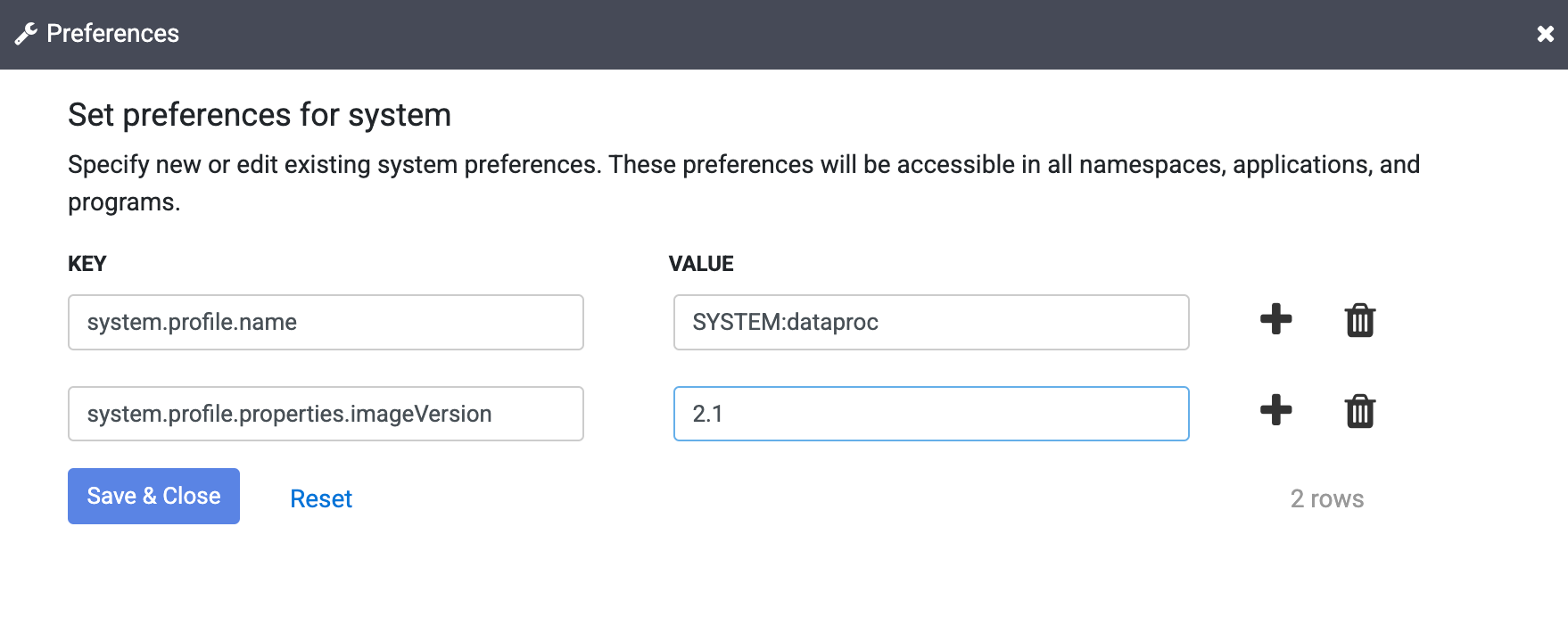
Geben Sie im Feld Schlüssel den folgenden Text ein:
system.profile.properties.imageVersionGeben Sie das ausgewählte Managed Service for Apache Spark-Image im Feld Wert, z. B.
2.1ein.Klicken Sie auf Speichern &schließen.
Diese Änderung wirkt sich auf die gesamte Cloud Data Fusion-Instanz aus, einschließlich aller Namespaces und Pipelineausführungen, es sei denn, die Image-Versionseigenschaft wird in einem Namespace, einer Pipeline oder einem Laufzeitargument in Ihrer Instanz überschrieben.
Image-Version von Managed Service for Apache Spark ändern
Die Image-Version kann in der Web-UI von Cloud Data Fusion in den Compute-Konfigurationen, Namespace-Einstellungen oder Pipeline-Laufzeitargumenten festgelegt werden.
Image in den Namespace-Einstellungen ändern
Wenn Sie die Image-Version in den Namespace-Eigenschaften überschrieben haben, gehen Sie so vor:
Klicken Sie auf Systemadministrator > Konfiguration > Namespaces.
Öffnen Sie jeden Namespace und klicken Sie auf Einstellungen.
Prüfen Sie, ob keine Überschreibung mit dem Schlüssel
system.profile.properties.imageVersionmit einem falschen Wert für die Image-Version vorhanden ist.Klicken Sie auf Beenden.
Image in den System-Compute-Profilen ändern
Klicken Sie auf Systemadministrator > Konfiguration.
Klicken Sie auf Compute-Profile > Neues Profil erstellen.
Wählen Sie den Bereitsteller Managed Service for Apache Spark aus.
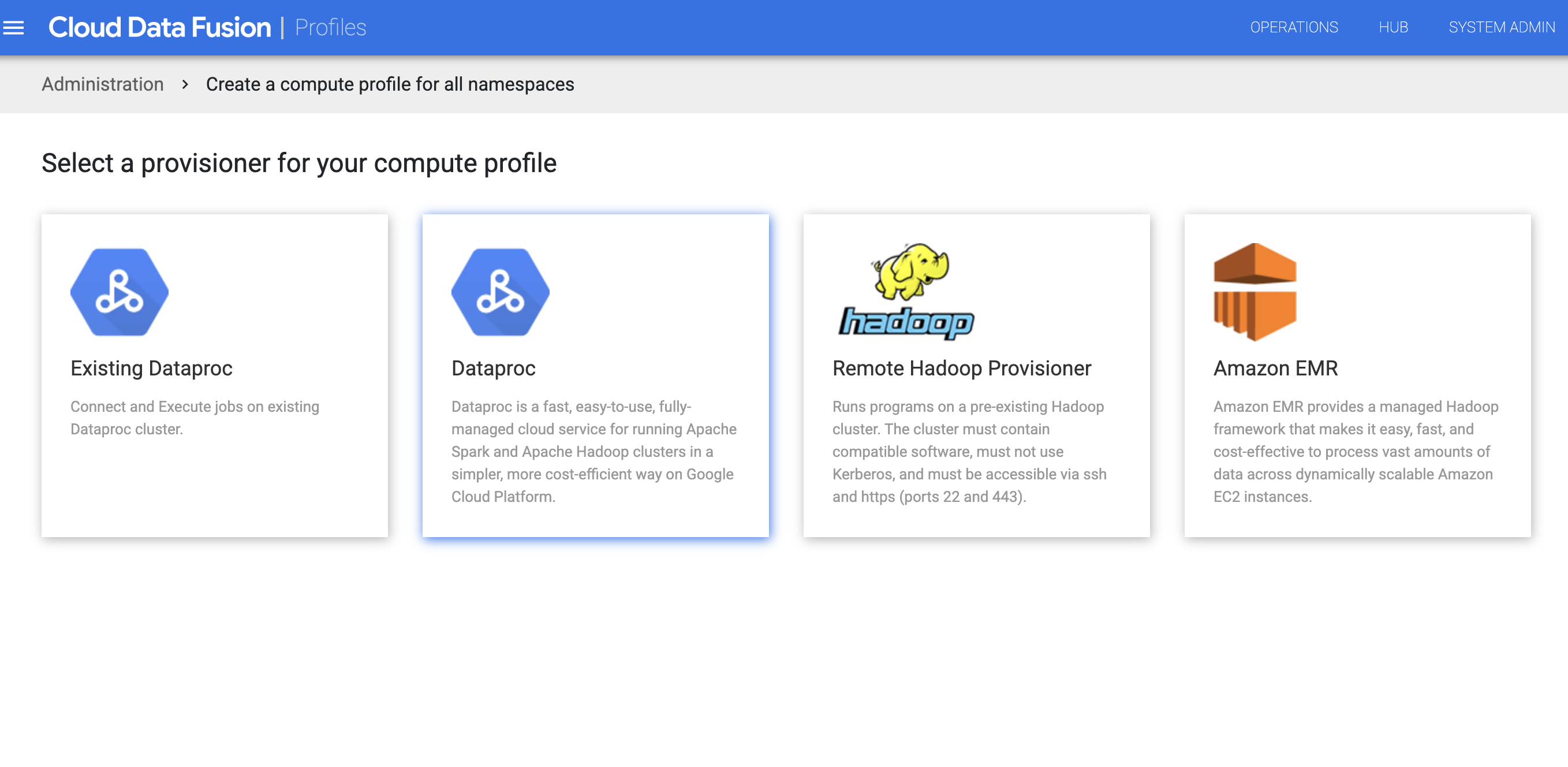
Erstellen Sie das Profil für Managed Service for Apache Spark. Geben Sie im Feld Image-Version eine Image-Version von Managed Service for Apache Spark ein.
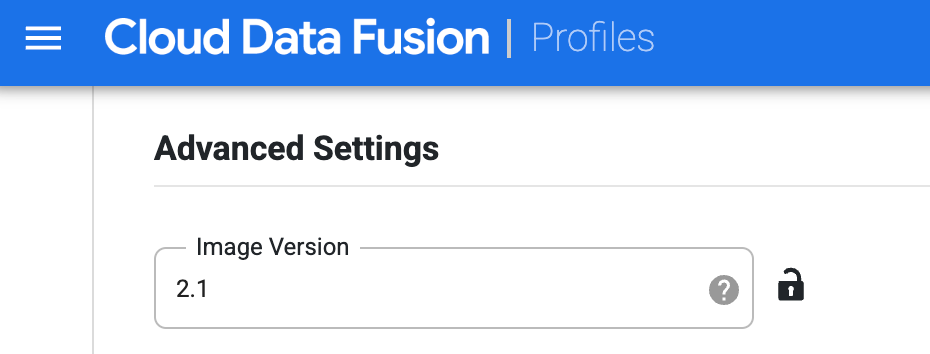
Wählen Sie dieses Compute-Profil aus, während Sie die Pipeline auf der Seite Studio ausführen. Klicken Sie auf der Seite der Pipelineausführung auf Konfigurieren > Compute Konfiguration und wählen Sie dieses Profil aus.
Wählen Sie das Managed Service for Apache Spark-Profil aus und klicken Sie auf Speichern.
Klicken Sie auf Beenden.
Image in den Pipeline-Laufzeitargumenten ändern
Wenn Sie die Image-Version mit einer Eigenschaft in den Laufzeitargumenten Ihrer Pipeline überschrieben haben, gehen Sie so vor:
Klicken Sie auf das Menü Menü > Liste.
Wählen Sie auf der Seite Liste die Pipeline aus, die Sie aktualisieren möchten.
Die Pipeline wird auf der Seite Studio geöffnet.
Klicken Sie auf den Pfeil , um die Optionen unter Ausführen zu maximieren.
Das Fenster Laufzeitargumente wird geöffnet.
Prüfen Sie, ob keine Überschreibung mit dem Schlüssel
system.profile.properties.imageVersionmit einer falschen Image-Version als Wert vorhanden ist.Klicken Sie auf Speichern.

Statische Managed Service for Apache Spark-Cluster, die von Cloud Data Fusion verwendet werden, mit der ausgewählten Image-Version neu erstellen
Wenn Sie vorhandene Managed Service for Apache Spark-Cluster mit Cloud Data Fusion verwenden, folgen Sie der Anleitung für Managed Service for Apache Spark, um die Cluster mit der ausgewählten Managed Service for Apache Spark-Image-Version für Ihre Cloud Data Fusion Version neu zu erstellen.
Alternativ können Sie einen neuen Managed Service for Apache Spark-Cluster mit der ausgewählten Managed Service for Apache Spark-Image-Version erstellen und das Compute-Profil in Cloud Data Fusion mit demselben Compute-Profilnamen und dem aktualisierten Namen des Managed Service for Apache Spark-Clusters löschen und neu erstellen. Auf diese Weise können Batchpipelines die Ausführung auf dem vorhandenen Cluster abschließen und nachfolgende Pipelineausführungen erfolgen auf dem neuen Managed Service for Apache Spark-Cluster. Sie können den alten Managed Service for Apache Spark-Cluster löschen, nachdem Sie bestätigt haben, dass alle Pipelineausführungen abgeschlossen sind.
Prüfen, ob die Image-Version von Managed Service for Apache Spark aktualisiert wurde
Console
Rufen Sie in der Google Cloud Console die Seite Cluster von Managed Service for Apache Spark auf.
Öffnen Sie die Seite Clusterdetails für den neuen Cluster, der von Cloud Data Fusion erstellt wurde, als Sie die neue Version angegeben haben.
Das Feld Image-Version enthält den neuen Wert, den Sie in Cloud Data Fusion angegeben haben.
REST API
Rufen Sie die Liste der Cluster mit ihren Metadaten ab:
GET -H "Authorization: Bearer ${AUTH_TOKEN}" \ https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION_ID/clustersErsetzen Sie Folgendes:
PROJECT_IDdurch den Namen Ihres NamespaceREGION_IDdurch den Namen der Region, in der sich Ihre Cluster befinden
Suchen Sie nach dem Namen Ihrer Pipeline (Clustername).
Unter diesem JSON-Objekt finden Sie das Image unter
config > softwareConfig > imageVersion.
Image von Managed Service for Apache Spark auf Version 2.1 oder höher ändern
Cloud Data Fusion-Versionen 6.9.1 und höher unterstützen das Managed Service for Apache Spark-Image 2.1 Compute Engine, das in Java 11 ausgeführt wird. In den Versionen 6.10.0 und höher ist Image 2.1 die Standardeinstellung.
Wenn Sie von einem früheren Image zu Image 2.1 oder höher wechseln, müssen die JDBC-Treiber, die von den Datenbank-Plug-ins in diesen Instanzen verwendet werden, mit Java 11 kompatibel sein, damit Ihre Batchpipelines und Replikationsjobs erfolgreich ausgeführt werden können.
Für die Managed Service for Apache Spark-Images 2.2 und 2.1 gelten in Cloud Data Fusion die folgenden Einschränkungen:
- MapReduce-Jobs werden nicht unterstützt.
- Die in den Datenbank-Plug-ins in Ihrer Instanz verwendeten JDBC-Treiberversionen müssen aktualisiert werden, um Java 11 zu unterstützen. In der folgenden Tabelle finden Sie die Treiberversionen, die mit Managed Service for Apache Spark 2.2, 2.1 und Java 11 funktionieren:
| JDBC-Treiber | Ältere Versionen, die aus Cloud Data Fusion 6.9.1 entfernt wurden | Von Java 8 und Java 11 unterstützte Versionen, die mit Managed Service for Apache Spark 2.2, 2.1 oder 2.0 funktionieren |
|---|---|---|
| JDBC-Treiber für Cloud SQL for MySQL | - | 1.0.16 |
| JDBC-Treiber für Cloud SQL for PostgreSQL | - | 1.0.16 |
| JDBC-Treiber für Microsoft SQL Server | Microsoft JDBC-Treiber 6.0 | Microsoft JDBC-Treiber 9.4 |
| JDBC-Treiber für MySQL | 5.0.8, 5.1.39 | 8.0.25 |
| JDBC-Treiber für PostgreSQL | 9.4.1211.jre7, 9.4.1211.jre8 | 42.6.0.jre8 |
| JDBC-Treiber für Oracle | ojdbc7 | ojdbc8 (12c und höher) |
Arbeitsspeichernutzung bei Verwendung von Managed Service for Apache Spark 2.1 oder höher
Die Arbeitsspeichernutzung kann bei Pipelines, die Managed Service for Apache Spark 2.1 oder höher verwenden, steigen. Wenn Sie Ihre Instanz auf Version 6.10 oder höher aktualisieren und frühere Pipelines aufgrund von Speicherproblemen fehlschlagen, erhöhen Sie den Treiber- und Executorspeicher in der Konfiguration Resources für die Pipeline auf 2048 MB.
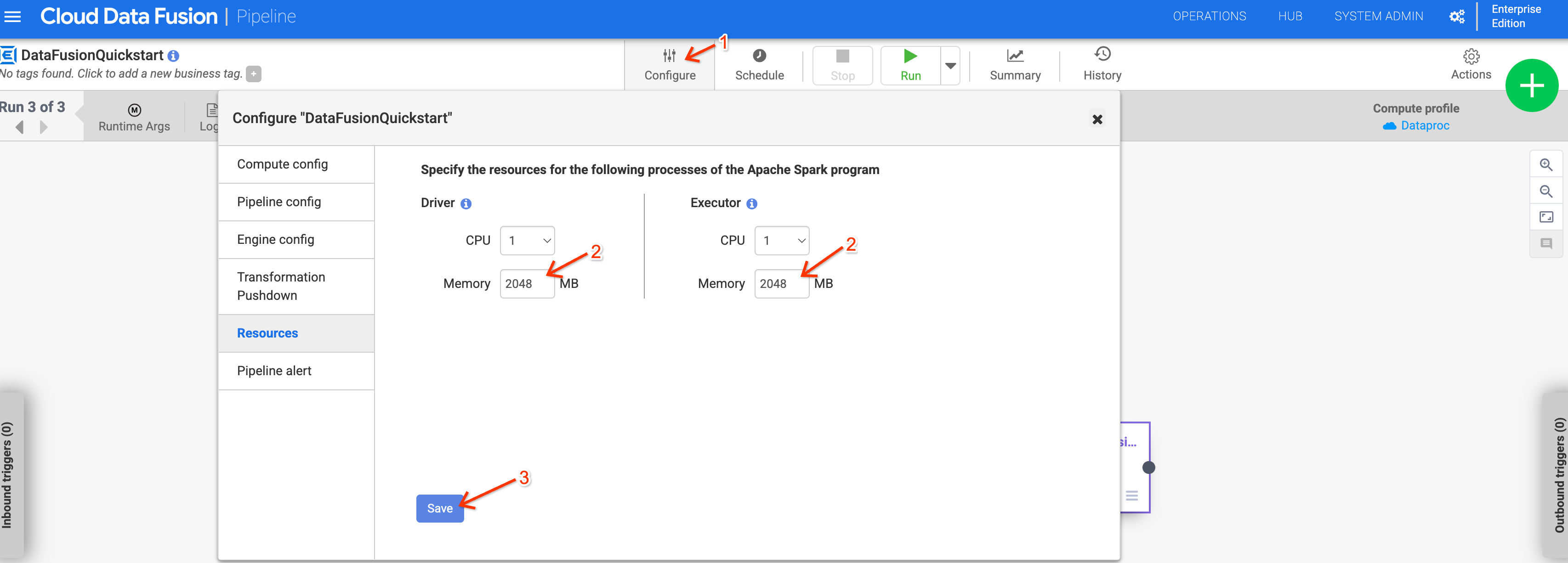
Alternativ können Sie die Managed Service for Apache Spark-Version überschreiben, indem Sie das Laufzeitargument system.profile.properties.imageVersion auf 2.0-debian10 setzen.