
Auf dieser Seite wird Cloud Data Fusion: Studio vorgestellt. Dabei handelt es sich um eine visuelle Drag-and-drop-Oberfläche zum Erstellen von Datenpipelines aus einer Bibliothek mit vorgefertigten Plug-ins und eine Oberfläche, auf der Sie Ihre Pipelines konfigurieren, ausführen und verwalten können. Das Erstellen einer Pipeline im Studio folgt in der Regel diesem Prozess:
- Verbindung zu einer lokalen oder Cloud-Datenquelle herstellen.
- Daten vorbereiten und transformieren.
- Verbindung zum Ziel herstellen.
- Pipeline testen.
- Pipeline ausführen.
- Pipelines planen und auslösen.
Nachdem Sie die Pipeline entworfen und ausgeführt haben, können Sie Pipelines auf der Seite Pipeline Studio von Cloud Data Fusion verwalten:
- Pipelines wiederverwenden, indem Sie sie mit Einstellungen und Laufzeitargumenten parametrisieren.
- Pipelineausführung verwalten, indem Sie Compute-Profile anpassen, Ressourcen verwalten und die Pipelineleistung optimieren.
- Pipelinelebenszyklus verwalten, indem Sie Pipelines bearbeiten.
- Versionsverwaltung für Pipelines mit der Git-Integration verwalten.
Hinweis
- Aktivieren Sie die Cloud Data Fusion API.
- Erstellen Sie eine Cloud Data Fusion-Instanz.
- Informationen zur Zugriffssteuerung in Cloud Data Fusion.
- Informationen zu den wichtigsten Konzepten und Begriffen in Cloud Data Fusion.
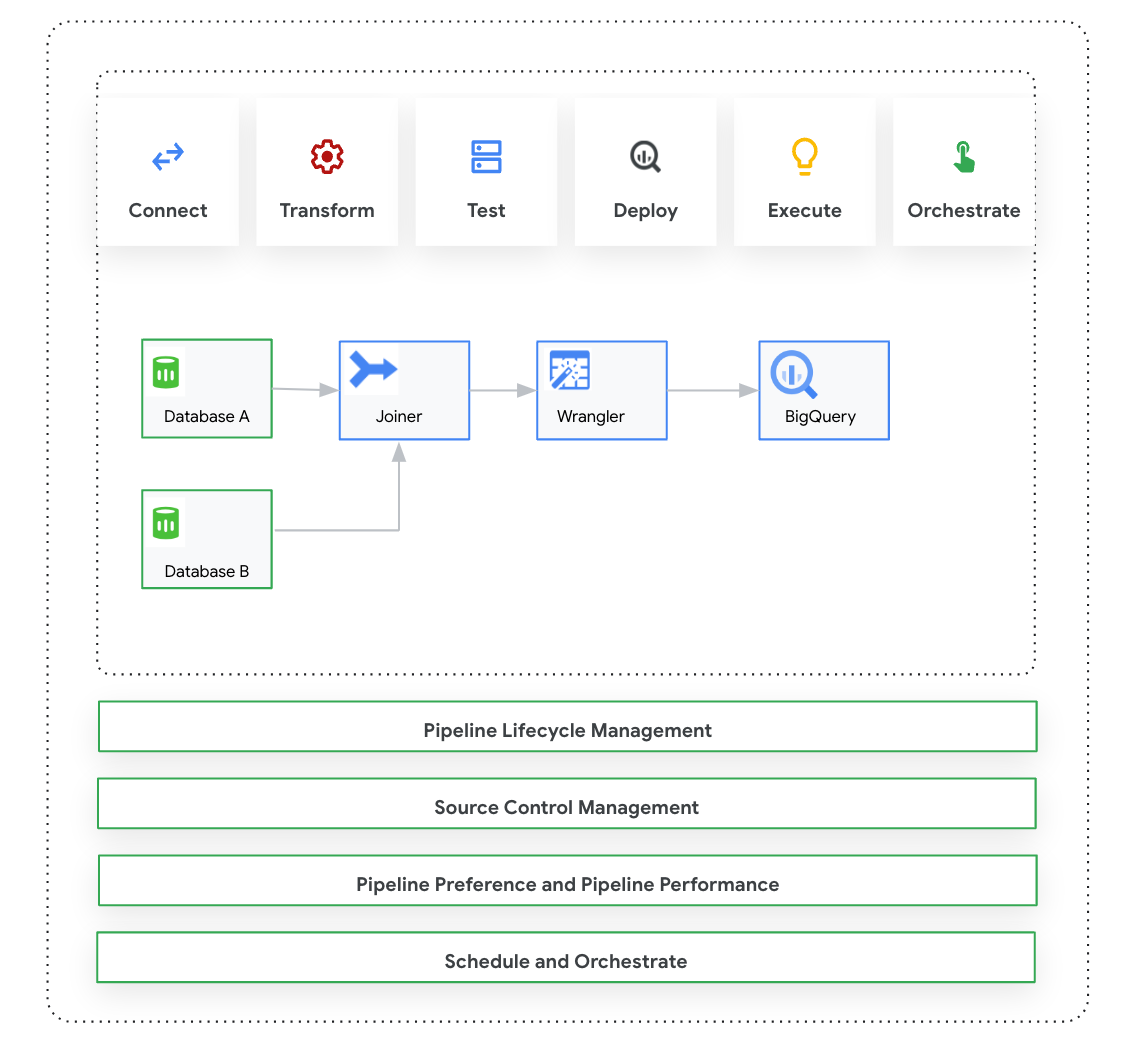
Übersicht über Cloud Data Fusion: Studio
Das Studio umfasst die folgenden Komponenten.
Verwaltung
In Cloud Data Fusion können Sie in jeder Instanz mehrere Namespaces verwenden. Im Studio können Administratoren alle Namespaces zentral oder jeden Namespace einzeln verwalten.
Das Studio bietet die folgenden Administratorkontrollen:
- Systemverwaltung
- Mit dem Modul Systemadministrator im Studio können Sie neue Namespaces erstellen und die zentralen Compute-Profil-Konfigurationen auf Systemebene definieren, die für jeden Namespace in dieser Instanz gelten. Weitere Informationen finden Sie unter Studioverwaltung verwalten.
- Namespace-Verwaltung
- Mit dem Modul Namespace-Administrator im Studio können Sie die Konfigurationen für den jeweiligen Namespace verwalten. Für jeden Namespace können Sie Compute-Profile, Laufzeiteinstellungen, Treiber, Dienstkonten und Git-Konfigurationen definieren. Weitere Informationen finden Sie unter Studioverwaltung verwalten.
Pipeline Design Studio
Sie entwerfen und führen Pipelines im Pipeline Design Studio in der Cloud Data Fusion-Weboberfläche aus. Das Entwerfen und Ausführen von Datenpipelines umfasst die folgenden Schritte:
- Verbindung zu einer Quelle herstellen: Cloud Data Fusion ermöglicht Verbindungen zu lokalen und Cloud-Datenquellen. Die Studio-Oberfläche enthält standardmäßige System-Plug-ins, die im Studio vorinstalliert sind. Sie können zusätzliche Plug-ins aus einem Plug-in-Repository herunterladen, dem sogenannten Hub. Weitere Informationen finden Sie unter Plug-in-Übersicht.
- Datenvorbereitung: Mit Cloud Data Fusion können Sie Ihre Daten mit dem leistungsstarken Datenvorbereitungs-Plug-in Wrangler vorbereiten. Mit Wrangler können Sie eine kleine Stichprobe Ihrer Daten an einem Ort ansehen, untersuchen und transformieren, bevor Sie die Logik im Studio auf das gesamte Dataset anwenden. So können Sie schnell Transformationen anwenden, um zu sehen, wie sie sich auf das gesamte Dataset auswirken. Sie können mehrere Transformationen erstellen und sie einem Rezept hinzufügen. Weitere Informationen finden Sie unter der Wrangler-Übersicht.
- Transformieren: Mit Transformations-Plug-ins werden Daten geändert, nachdem sie aus einer Quelle geladen wurden. Sie können beispielsweise einen Datensatz klonen, das Dateiformat in JSON ändern oder mit dem JavaScript-Plug-in eine benutzerdefinierte Transformation erstellen. Weitere Informationen finden Sie unter Plug-in-Übersicht.
- Verbindung zu einem Ziel herstellen: Nachdem Sie die Daten vorbereitet und Transformationen angewendet haben, können Sie eine Verbindung zu dem Ziel herstellen, in das Sie die Daten laden möchten. Cloud Data Fusion unterstützt Verbindungen zu mehreren Zielen. Weitere Informationen finden Sie unter Plug-in-Übersicht.
- Vorschau: Nachdem Sie die Pipeline entworfen haben, führen Sie einen Vorschaujob aus, um Probleme zu beheben, bevor Sie eine Pipeline bereitstellen und ausführen. Wenn Fehler auftreten, können Sie sie im Modus Entwurf beheben. Im Studio werden die ersten 100 Zeilen Ihres Quelldatasets verwendet, um die Vorschau zu generieren. Im Studio werden der Status und die Dauer des Vorschaujobs angezeigt. Sie können den Job jederzeit beenden. Sie können auch die Logereignisse während der Ausführung des Vorschaujobs beobachten. Weitere Informationen finden Sie unter Vorschau von Daten.
Pipelinekonfigurationen verwalten: Nachdem Sie eine Vorschau der Daten angezeigt haben, können Sie die Pipeline bereitstellen und die folgenden Pipelinekonfigurationen verwalten:
- Compute-Konfiguration: Sie können das Compute-Profil ändern, mit dem die Pipeline ausgeführt wird. Sie können die Pipeline beispielsweise für einen benutzerdefinierten Managed Service for Apache Spark-Cluster anstelle des standardmäßigen Managed Service for Apache Spark-Clusters ausführen.
- Pipelinekonfiguration: Für jede Pipeline können Sie die Instrumentierung aktivieren oder deaktivieren, z. B. Zeitmessungen. Standardmäßig ist die Instrumentierung aktiviert.
- Engine-Konfiguration: Spark ist die Standard-Ausführungs-Engine. Sie können benutzerdefinierte Parameter für Spark übergeben.
- Ressourcen: Sie können den Arbeitsspeicher und die Anzahl der CPUs für den Spark-Treiber und -Executor angeben. Der Treiber orchestriert den Spark-Job. Der Executor verarbeitet die Daten in Spark.
- Pipelinebenachrichtigung: Sie können die Pipeline so konfigurieren, dass Benachrichtigungen gesendet und Nachbearbeitungsaufgaben gestartet werden, nachdem die Pipelineausführung abgeschlossen ist. Sie erstellen Pipelinebenachrichtigungen, wenn Sie die Pipeline entwerfen. Nachdem Sie die Pipeline bereitgestellt haben, können Sie die Benachrichtigungen ansehen. Wenn Sie die Benachrichtigungseinstellungen ändern möchten, können Sie die Pipeline bearbeiten.
- Transformations-Push-down: Sie können das Transformations-Push-down aktivieren, wenn eine Pipeline bestimmte Transformationen in BigQuery ausführen soll.
Weitere Informationen finden Sie unter Pipelinekonfigurationen verwalten.
Pipelines mit Makros, Einstellungen und Laufzeitargumenten wiederverwenden: Mit Cloud Data Fusion können Sie Datenpipelines wiederverwenden. Mit wiederverwendbaren Datenpipelines können Sie eine einzelne Pipeline verwenden, mit der ein Datenintegrationsmuster auf eine Vielzahl von Anwendungsfällen und Datasets angewendet werden kann. Wiederverwendbare Pipelines lassen sich besser verwalten. Sie können die meisten Konfigurationen einer Pipeline zur Ausführungszeit festlegen, anstatt sie zur Entwurfszeit fest zu codieren. Im Pipeline Design Studio können Sie Makros verwenden, um Plug-in-Konfigurationen Variablen hinzuzufügen, damit Sie die Variablensubstitutionen zur Laufzeit angeben können. Weitere Informationen finden Sie unter Makros, Einstellungen und Laufzeitargumente verwalten.
Ausführen: Nachdem Sie die Pipelinekonfigurationen überprüft haben, können Sie die Pipelineausführung starten. Sie können die Statusänderung während der Phasen der Pipelineausführung sehen, z. B. Bereitstellung, Start, Ausführung und Erfolg.
Planen und orchestrieren: Batch-Datenpipelines können so eingerichtet werden, dass sie nach einem bestimmten Zeitplan und mit einer bestimmten Häufigkeit ausgeführt werden. Nachdem Sie eine Pipeline erstellt und bereitgestellt haben, können Sie einen Zeitplan erstellen. Im Pipeline Design Studio können Sie Pipelines orchestrieren, indem Sie einen Trigger für eine Batch-Datenpipeline erstellen, damit sie ausgeführt wird, wenn eine oder mehrere Pipelineausführungen abgeschlossen sind. Diese werden als nachgelagerte und vorgelagerte Pipelines bezeichnet. Sie erstellen einen Trigger für die nachgelagerte Pipeline, damit sie basierend auf dem Abschluss einer oder mehrerer vorgelagerter Pipelines ausgeführt wird.
Empfehlung: Sie können auch Composer verwenden, um Pipelines in Cloud Data Fusion zu orchestrieren. Weitere Informationen finden Sie unter Pipelines planen und Pipelines orchestrieren.
Pipelines bearbeiten: Mit Cloud Data Fusion können Sie eine bereitgestellte Pipeline bearbeiten. Wenn Sie eine bereitgestellte Pipeline bearbeiten, wird eine neue Version der Pipeline mit demselben Namen erstellt und als neueste Version gekennzeichnet. So können Sie Pipelines iterativ entwickeln, anstatt sie zu duplizieren, wodurch eine neue Pipeline mit einem anderen Namen erstellt wird. Weitere Informationen finden Sie unter Pipelines bearbeiten.
Versionsverwaltung: Mit Cloud Data Fusion können Sie Pipelines zwischen Entwicklung und Produktion besser verwalten, indem Sie die Versionsverwaltung der Pipelines mit GitHub verwenden.
Logging und Monitoring: Wenn Sie Pipelinemesswerte und -logs überwachen möchten, empfehlen wir, den Stackdriver Logging-Dienst zu aktivieren, um Cloud Logging mit Ihrer Cloud Data Fusion-Pipeline zu verwenden.
Nächste Schritte
- Weitere Informationen zum Verwalten der Studioverwaltung.