
セキュリティに関する推奨事項
強固なセキュリティ境界や隔離が必要なワークロードについては、以下を検討してください。
厳格な隔離を適用するには、セキュリティ重視のワークロードを別の プロジェクトに配置します。 Google Cloud
特定のリソースへのアクセスを管理するには、Cloud Data Fusion インスタンスで ロールベース アクセス制御を有効にします。
インスタンスを一般公開せず、機密データの流出のリスクを軽減するには、インスタンスで内部 IP アドレスと VPC Service Controls(VPC-SC)を有効にします。
認証
Cloud Data Fusion ウェブ UI は、 コンソールでサポートされる認証メカニズムを備えており、Identity and Access Management を介してアクセス権が制御されます。 Google Cloud
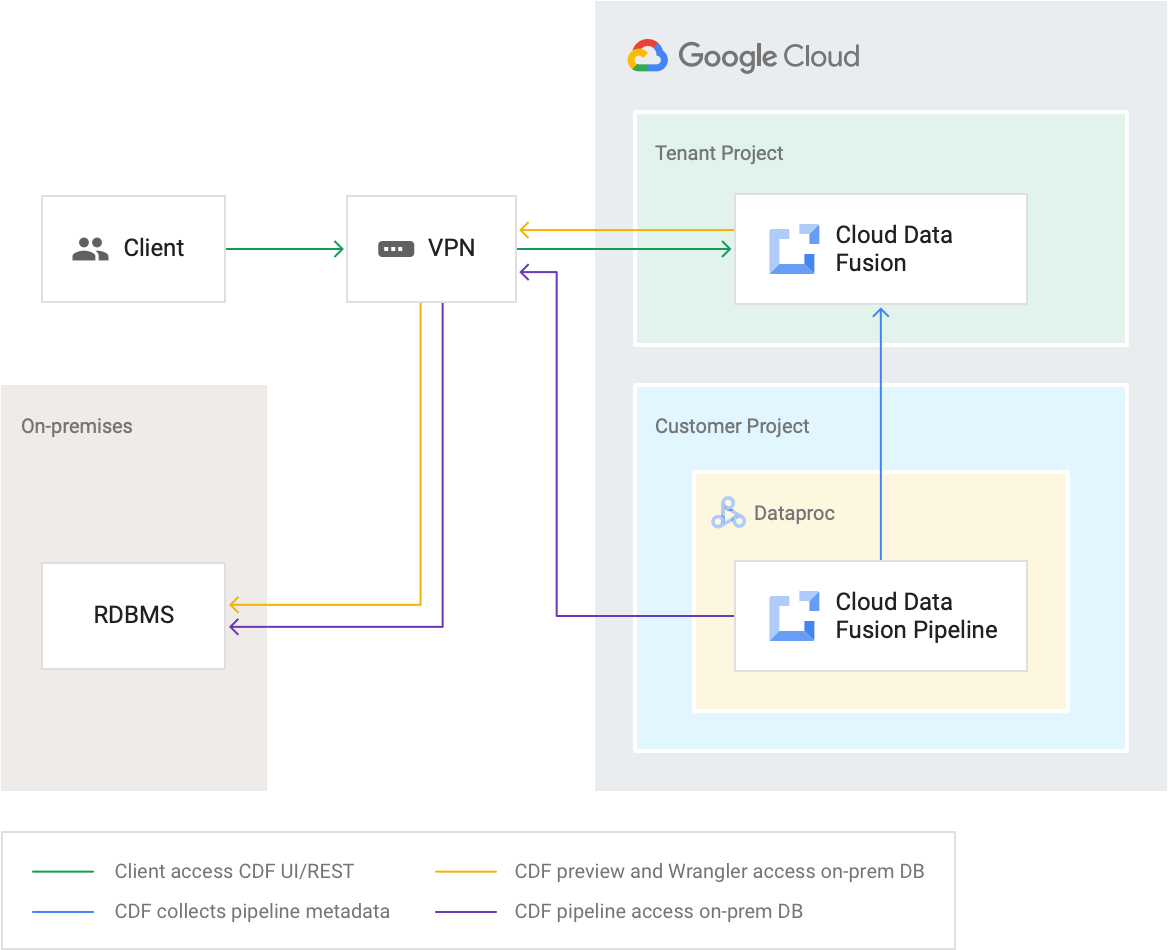
ネットワーキングの制御
プライベート Cloud Data Fusion インスタンスを作成できます。このインスタンスは、VPC ピアリングまたは Private Service Connect を介して VPC ネットワークに接続できます。プライベート Cloud Data Fusion インスタンスは内部 IP アドレスを持ち、公共のインターネットには公開されません。VPC Service Controls を使用して、Cloud Data Fusion プライベート インスタンスの周囲にセキュリティ境界を確立する、追加的なセキュリティ対策も利用できます。
詳細については、 Cloud Data Fusion ネットワーキングの概要をご覧ください。
事前作成された内部 IP Managed Service for Apache Spark クラスタでのパイプライン実行
プライベート Cloud Data Fusion インスタンスは、 リモート Hadoop プロビジョナーで使用できます。 Managed Service for Apache Spark クラスタは、 Cloud Data Fusion でピアリングされた VPC ネットワークになければなりません。リモート Hadoop プロビジョナーは、Managed Service for Apache Spark クラスタのマスターノードの内部 IP アドレスで構成します。
アクセス制御
Cloud Data Fusion インスタンスへのアクセスの管理: RBAC が有効なインスタンスでは、Identity and Access Management を使用して名前空間レベルでアクセスを管理できます。RBAC が無効なインスタンスでは、インスタンス レベルでのアクセス管理のみがサポートされます。インスタンスにアクセスできれば、そのインスタンス内のすべてのパイプラインとメタデータにアクセスできます。
データへのパイプライン アクセス: データへのパイプライン アクセスは、サービス アカウントへのアクセス権を付与することによって実現できます。ユーザーはカスタムのサービス アカウントをこのアカウントとして指定できます。
ファイアウォール ルール
パイプラインの実行については、パイプラインが実行されるお客様の VPC に適切なファイアウォール ルールを設定することで、上り(内向き)と下り(外向き)を制御します。
詳細については、ファイアウォール ルールをご覧ください。
キーの保管
パスワード、鍵、その他のデータは Cloud Data Fusion に安全に保存され、Cloud Key Management Service に保存されている鍵を使用して暗号化されます。実行時には、Cloud Data Fusion が Cloud Key Management Service を呼び出して、復号に使用される鍵を取得します。
暗号化
データはデフォルトで、保存時には Google-owned and Google-managed encryption keysを使用して暗号化され、転 101}送時には TLS v1.2 を使用して暗号化されます。Dataproc クラスタ メタデータと Cloud Storage、BigQuery、Pub/Sub データソース、シンクなど、Cloud Data Fusion パイプラインによって書き込まれるデータを制御するには、 顧客管理の暗号鍵(CMEK) を使用します。
サービス アカウント
Cloud Data Fusion パイプラインはお客様のプロジェクトの Managed Service for Apache Spark クラスタで実行されますが、お客様指定の(カスタム)サービス アカウントを使用して実行されるよう構成できます。カスタム サービス アカウントには、 サービス アカウント ユーザー のロールを付与する必要があります。
プロジェクト
Cloud Data Fusion サービスは、ユーザーがアクセスできない Google 管理のテナント プロジェクトに作成されます。Cloud Data Fusion パイプラインは、お客様のプロジェクト内の Managed Service for Apache Spark クラスタで実行されます。お客様は、クラスタにその有効期間中アクセスできます。
監査ログ
Cloud Data Fusion 監査ログは Logging から利用できます。
プラグインとアーティファクト
信頼できないプラグインやアーティファクトをインストールすると、セキュリティ リスクが生じる可能性があるため、オペレーターや管理者は注意が必要です。
Workforce Identity 連携
Workforce Identity 連携ユーザーは、インスタンスの作成、削除、アップグレード、一覧表示など、Cloud Data Fusion でのオペレーションを実行できます。制限事項の詳細については、Workforce Identity 連携: サポート対象のプロダクトと制限事項をご覧ください。